| Fast interpolation of multivariate
polynomials with sparse exponents   |
|
| December 29, 2024 |
|
 . This work has
been partly supported by the French ANR-22-CE48-0016
NODE project.
. This work has
been partly supported by the French ANR-22-CE48-0016
NODE project.
 . This article has
been written using GNU TeXmacs [24].
. This article has
been written using GNU TeXmacs [24].
Consider a sparse multivariate polynomial |
Consider a multivariate integer polynomial 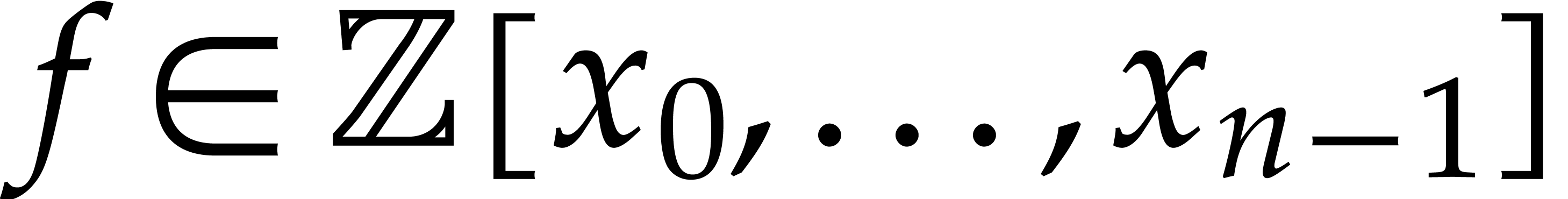 .
Then
.
Then 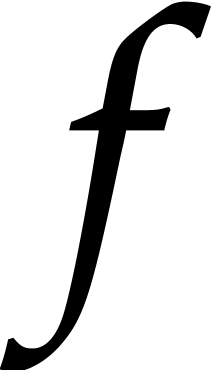 can uniquely be written as a sum
can uniquely be written as a sum
 |
(1.1) |
where 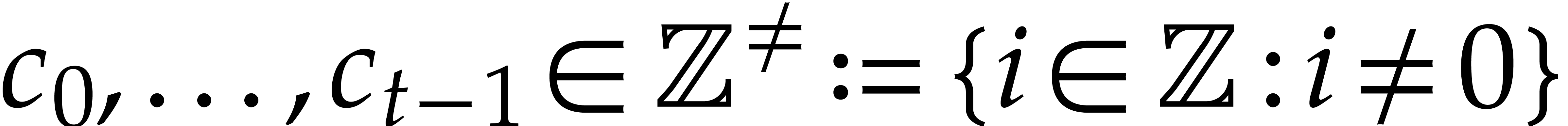 and
and 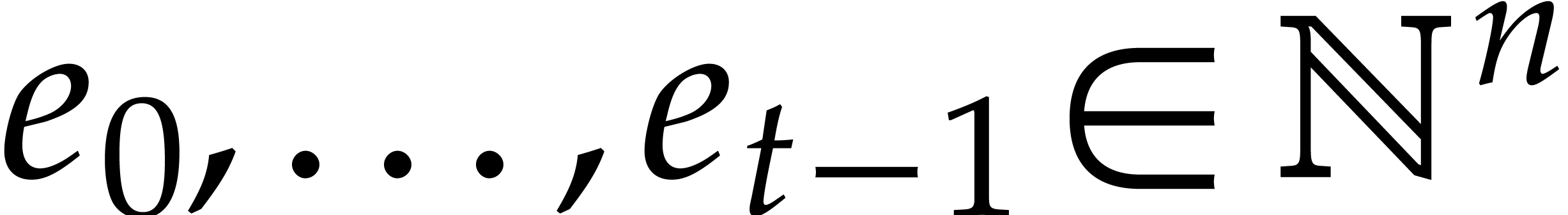 are pairwise
distinct. Here we understand that
are pairwise
distinct. Here we understand that 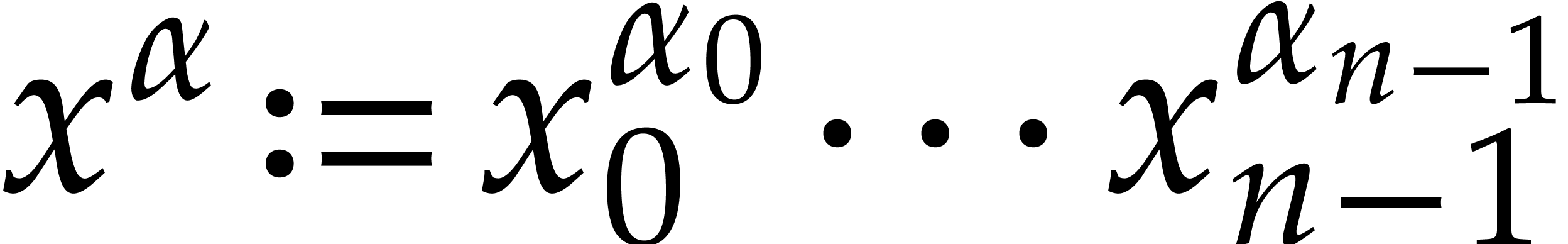 for any
for any 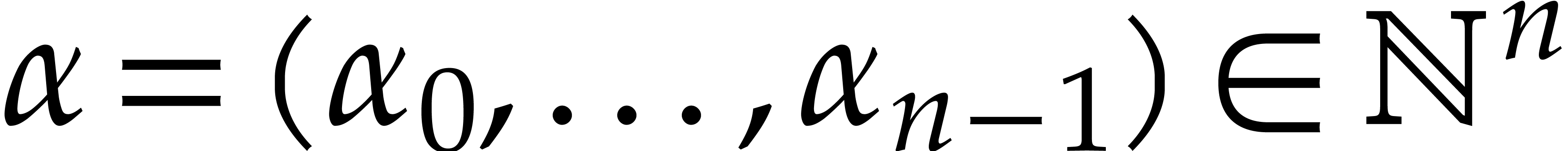 . We call (1.1) the
sparse representation of .
. We call (1.1) the
sparse representation of .
In this paper, we assume that is not
explicitly given through its sparse representation and that we only have
a program for evaluating .
The goal of sparse interpolation is to recover the sparse
representation of .
Theoretically speaking, we could simply evaluate
at a single point  with
with 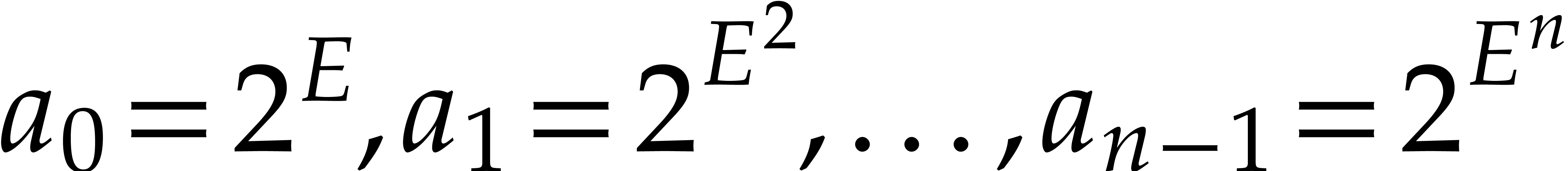 for some sufficiently large positive integer
for some sufficiently large positive integer  . Then the sparse representation of
can directly be read off from the binary digits of
. Then the sparse representation of
can directly be read off from the binary digits of  . However, the bit-complexity of this method is
terrible, since the bit-size of typically
becomes huge.
. However, the bit-complexity of this method is
terrible, since the bit-size of typically
becomes huge.
In order to get a better grip on the bit-complexity to evaluate and then
interpolate , we will assume
that we actually have a program to evaluate
modulo 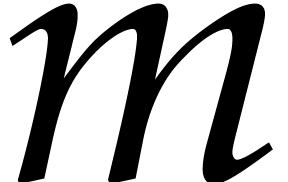 for any positive integer modulus . We denote by
for any positive integer modulus . We denote by 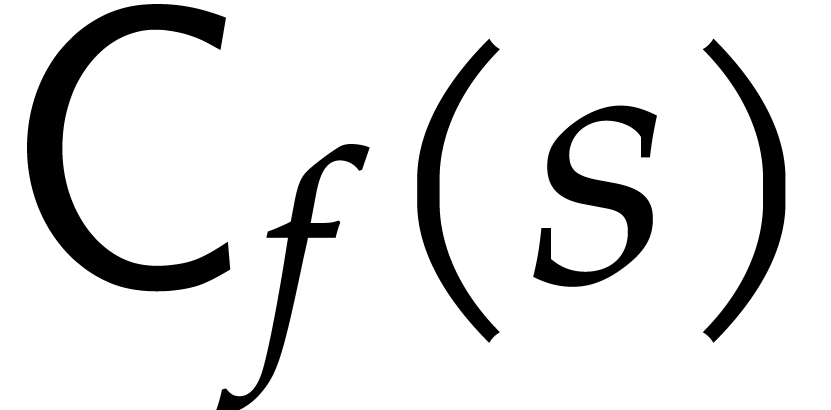 the cost to evaluate for a modulus with
the cost to evaluate for a modulus with 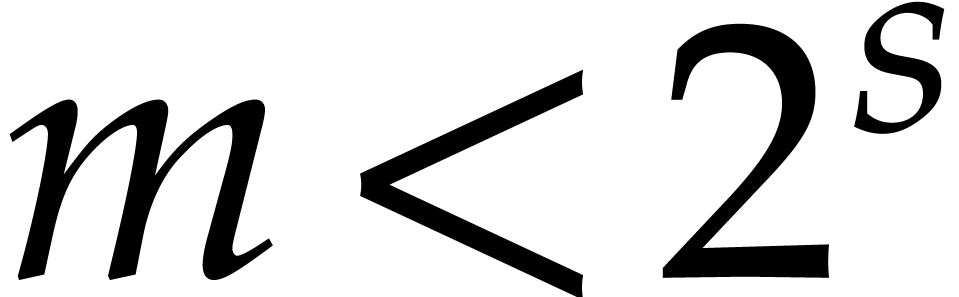 and we assume that the average cost per bit
and we assume that the average cost per bit
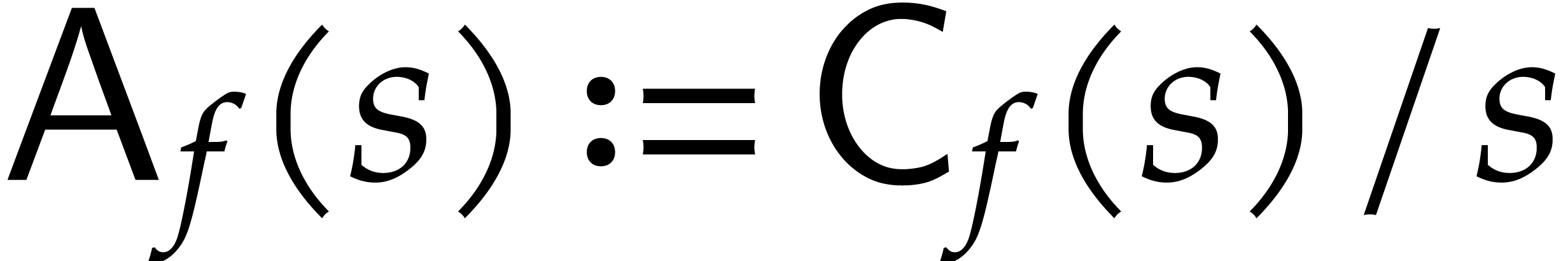 is a non-decreasing function that grows not too
fast as a function of
is a non-decreasing function that grows not too
fast as a function of 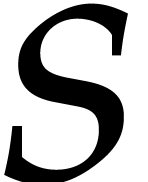 .
Roughly speaking, when using fast integer arithmetic,
.
Roughly speaking, when using fast integer arithmetic, 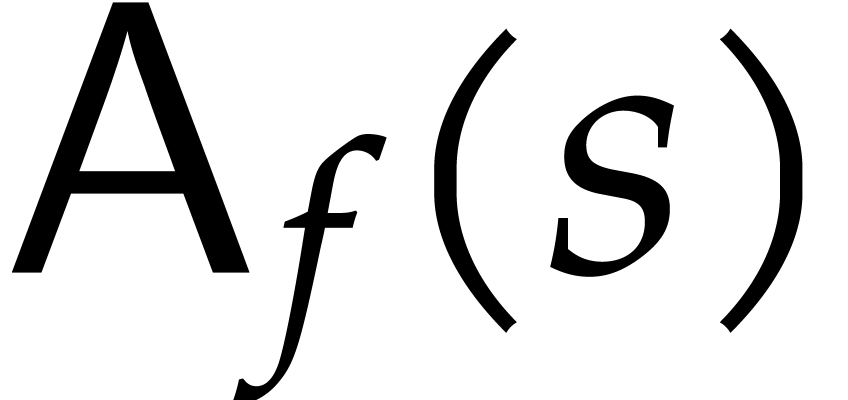 is essentially the number of arithmetic operations needed to evaluate
, up to logarithmic factors
in . More generally, this
notation is useful for practice in order to distinguish the cost of the
evaluation of from the cost of the actual
interpolation, independently of the underlying integer arithmetic.
is essentially the number of arithmetic operations needed to evaluate
, up to logarithmic factors
in . More generally, this
notation is useful for practice in order to distinguish the cost of the
evaluation of from the cost of the actual
interpolation, independently of the underlying integer arithmetic.
As in [15], for complexity estimates we use a random
memory access (RAM) machine over a finite alphabet along with the
soft-Oh notation: 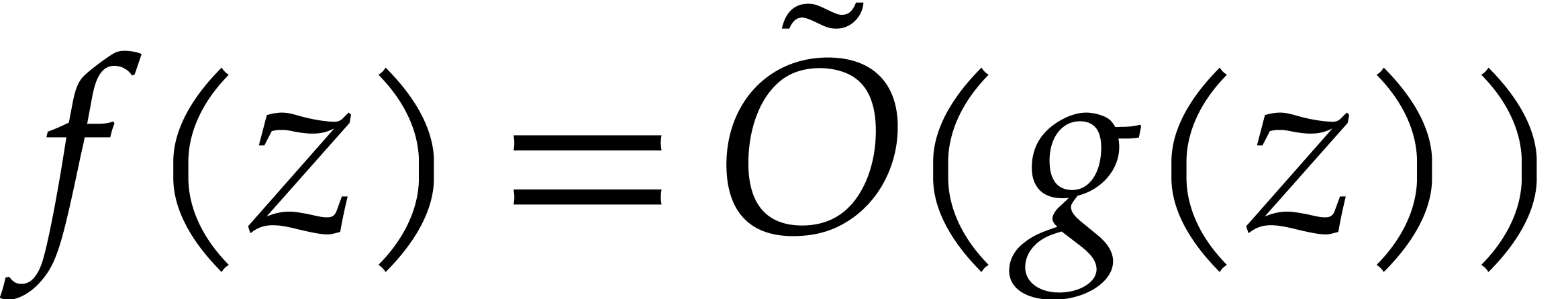 means that
means that 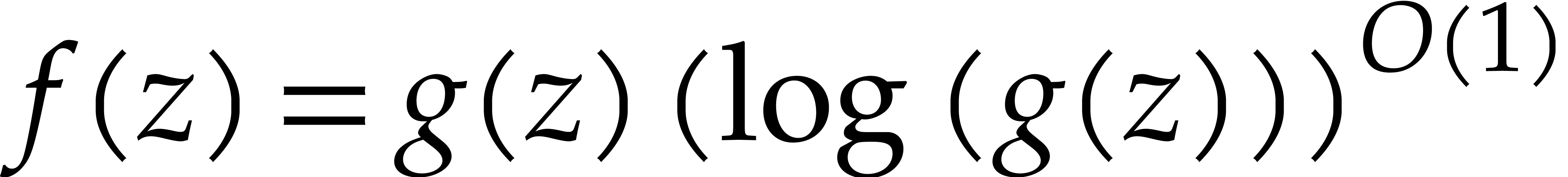 . The machine is expected to have
an instruction for generating a random bit in constant time (see section
2 for the precise computational model and hypotheses that
we use). Assuming that we are given a bound
. The machine is expected to have
an instruction for generating a random bit in constant time (see section
2 for the precise computational model and hypotheses that
we use). Assuming that we are given a bound  for
the number of terms of and a number
for
the number of terms of and a number  such that each term of has
bit-size
such that each term of has
bit-size  , the main result of
this paper is the following:
, the main result of
this paper is the following:
of  terms, each of bit-size
terms, each of bit-size  , as input and that interpolates
, as input and that interpolates  in time
in time 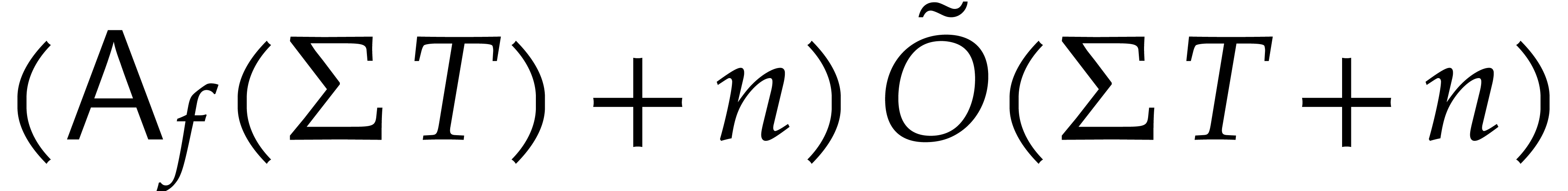 with a probability of success at least
with a probability of success at least
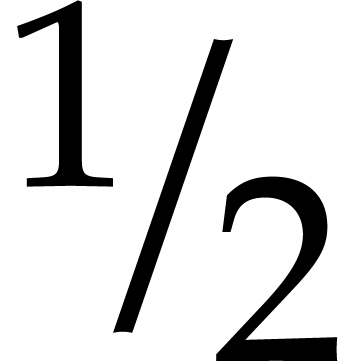 .
.
If the 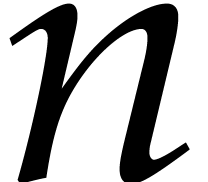 variables all appear in the sparse
representation of , then
variables all appear in the sparse
representation of , then 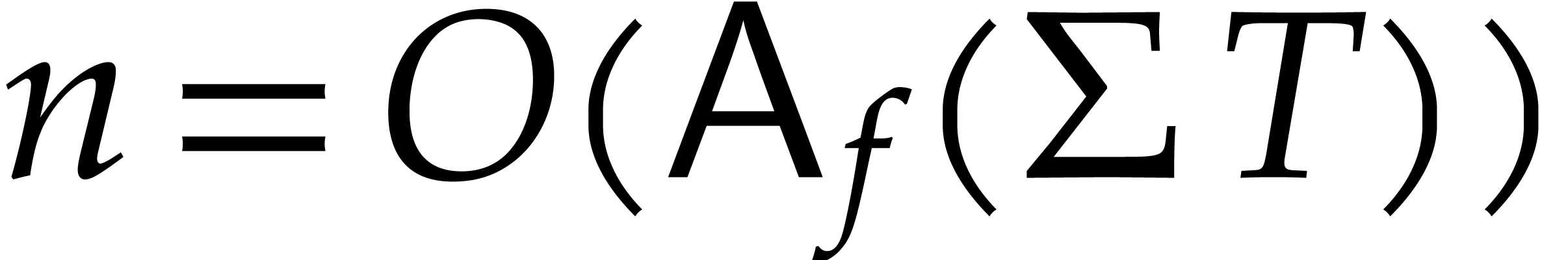 and
and 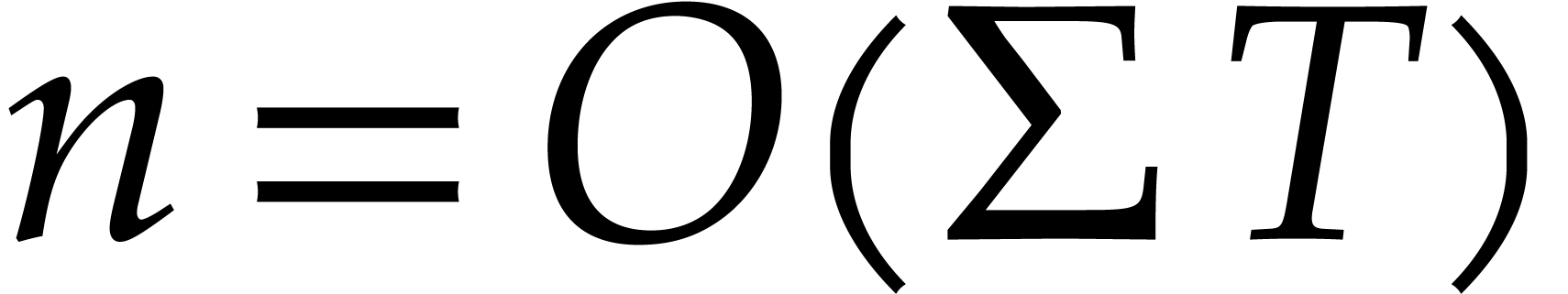 , so
the bound further simplifies into
, so
the bound further simplifies into 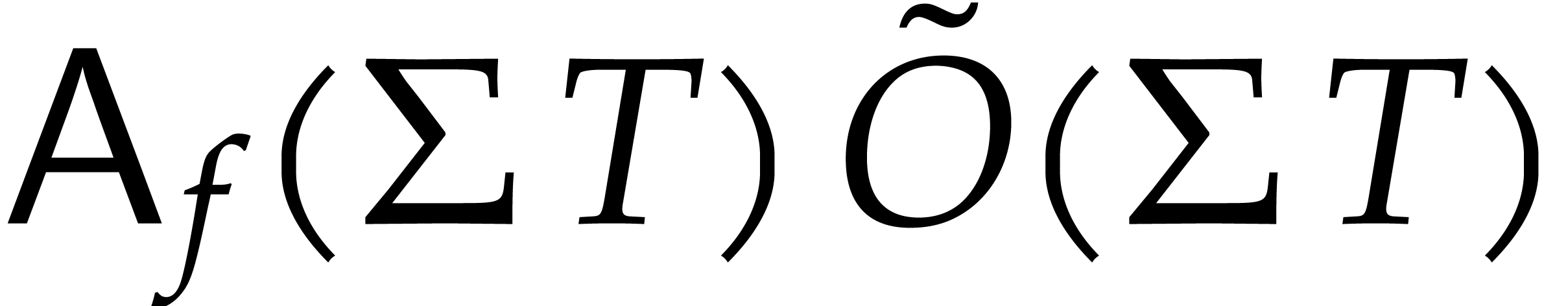 .
When using fast integer arithmetic to evaluate , the latter bound simplifies to
.
When using fast integer arithmetic to evaluate , the latter bound simplifies to 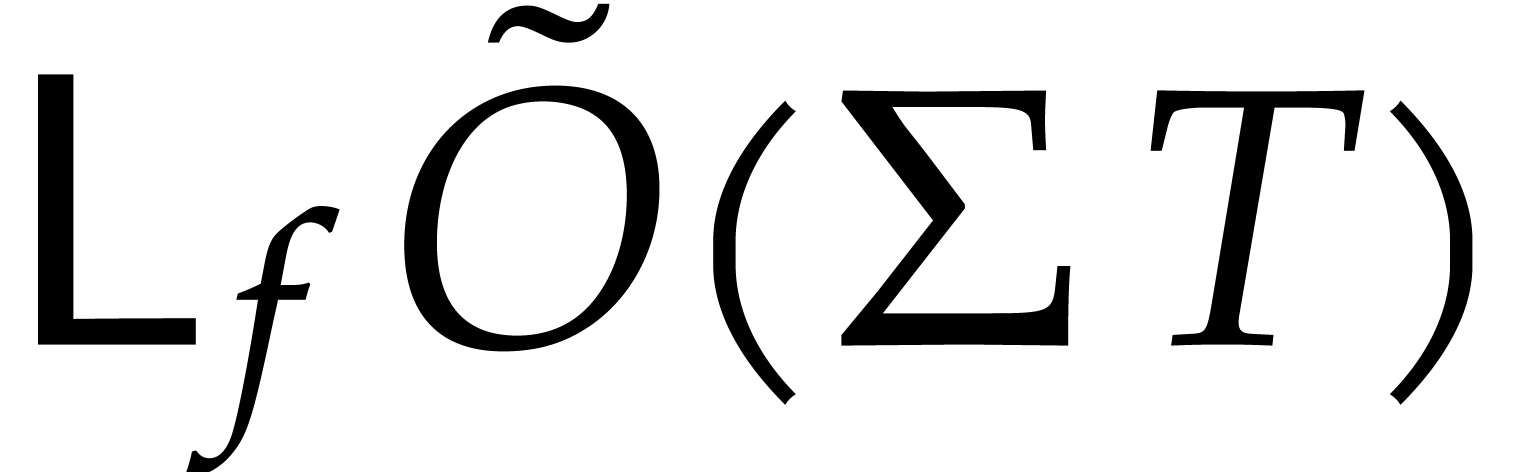 , where
, where  stands for the
number of arithmetic operations needed to evaluate . In addition, detecting useless variables can
be done fast, e.g. using the heuristic method from [28, section 7.4].
stands for the
number of arithmetic operations needed to evaluate . In addition, detecting useless variables can
be done fast, e.g. using the heuristic method from [28, section 7.4].
The problem of sparse interpolation has a long history and goes back to work by Prony in the 18th century [41]. The first modern fast algorithm is due to Ben-Or and Tiwari [6]. Their work spawned a new area of research in computer algebra together with early implementations [11, 13, 20, 31, 34, 35, 38, 45]. We refer to [42] and [40, section 3] for nice surveys.
Modern research on sparse interpolation has developed in two directions. The first theoretical line of research has focused on rigorous and general complexity bounds [2–4, 14, 17, 32]. The second direction concerns implementations, practical efficiency, and applications of sparse interpolation [5, 19, 21, 23, 26, 28, 30, 33, 36, 37].
The present paper mainly falls in the first line of research, although we will briefly discuss practical aspects in section 5. The proof of our main theorem relies on some number theoretical facts about prime numbers that will be recalled in section 2.3. There is actually a big discrepancy between empirical observations about prime numbers and hard theorems that one is able to prove. Because of this, our algorithms involve constant factors that are far more pessimistic than the ones that can be used in practice. Our algorithms also involve a few technical complications in order to cover all possible cases, including very large exponents that are unlikely to occur in practice.
Our paper borrows many techniques from [17, 40]
that deal with the particular case when is a
univariate polynomial, and that achieves a quasi-optimal complexity
bound for when the bit-sizes of the terms of are
well-balanced. In principle, the multivariate case can be reduced to the
univariate case: setting 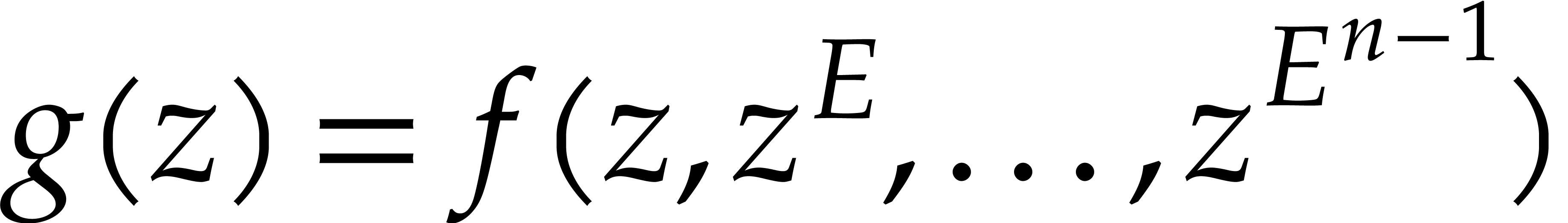 for a sufficiently
large
for a sufficiently
large  , the interpolation of
reduces to the interpolation of
, the interpolation of
reduces to the interpolation of  . However, this reduction is optimal only if
the entries of the vector exponents
. However, this reduction is optimal only if
the entries of the vector exponents 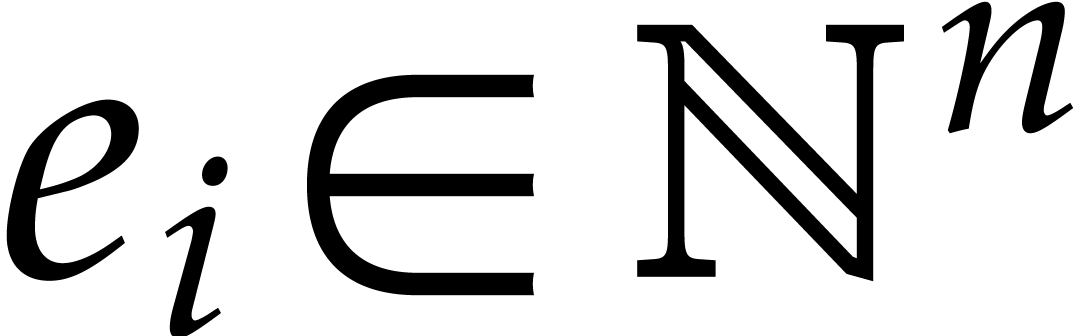 are all
approximately of the same bit-size. One interesting case that is not
well covered by this reduction is when the number of variables is large and when the exponent vectors
are all
approximately of the same bit-size. One interesting case that is not
well covered by this reduction is when the number of variables is large and when the exponent vectors  are themselves sparse in the sense that only a few entries are non-zero.
The main contribution of the present paper is the introduction of a
quasi-optimal technique to address this problem.
are themselves sparse in the sense that only a few entries are non-zero.
The main contribution of the present paper is the introduction of a
quasi-optimal technique to address this problem.
Another case that is not well covered by [17, 40]
is when the bit-sizes of the coefficients or exponents vary wildly.
Recent progress on this issue has been made in [18] and it
is plausible that these improvements can be extended to our multivariate
setting (see also Remark 4.11). Theorem 4.9
also provides a quasi-optimal solution for an approximation of the
sparse interpolation problem: for a fixed constant 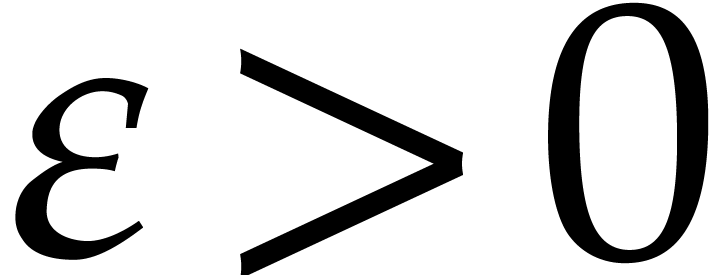 , we only require the determination of at least
, we only require the determination of at least
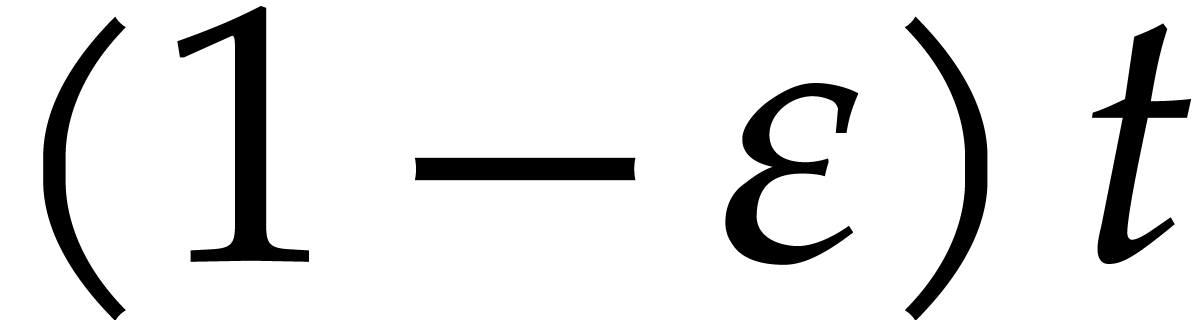 correct terms of (1.1).
correct terms of (1.1).
In order to cover sparse exponent vectors in a more efficient way, we will introduce a new technique in section 3. The idea is to compress such exponent vectors using random projections. With high probability, it will be possible to reconstruct the actual exponent vectors from their projections. We regard this section as the central technical contribution of our paper. Let us further mention that random projections of the exponents were previously implemented in [4] in order to reduce the multivariate case to the univariate one: monomial collisions were avoided in this way but the reconstruction of the exponents needed linear algebra and could not really catch sparse or unbalanced exponents. The proof of Theorem 1.1 will be completed at the end of section 4. Section 5 will address the practical aspects of our new method. An important inspiration behind the techniques from section 3 and its practical variants is the mystery ball game from [23]; this connection will also be discussed in section 5.
Our paper focuses on the case when has integer
coefficients, but our algorithm can be easily adapted to rational
coefficients as well, essentially by appealing to rational
reconstruction [15, Chapter 5, section 5.10] during the
proof of Lemma 4.8. However when
has rational coefficients, its blackbox might include divisions and
therefore raise “division by zero” errors occasionally. This
makes the probability analysis and the worst case complexity bounds more
difficult to analyze, so we preferred to postpone this study to another
paper.
Our algorithm should also be applicable to various other coefficient rings of characteristic zero. However it remains an open challenge to develop similar algorithms for coefficient rings of small positive characteristic.
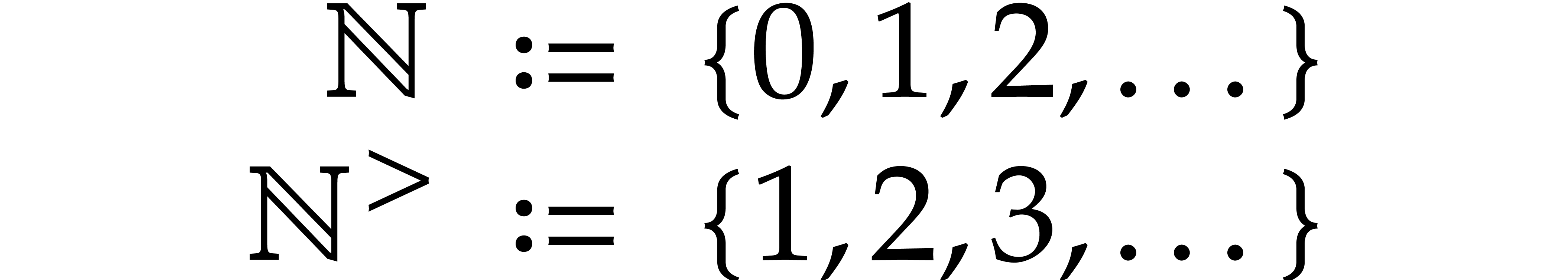
For any 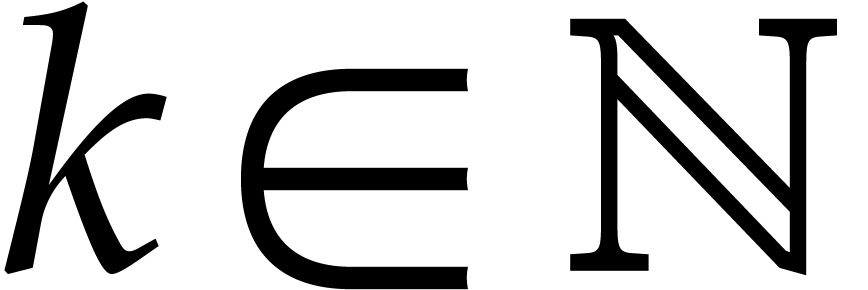 , we also define
, we also define
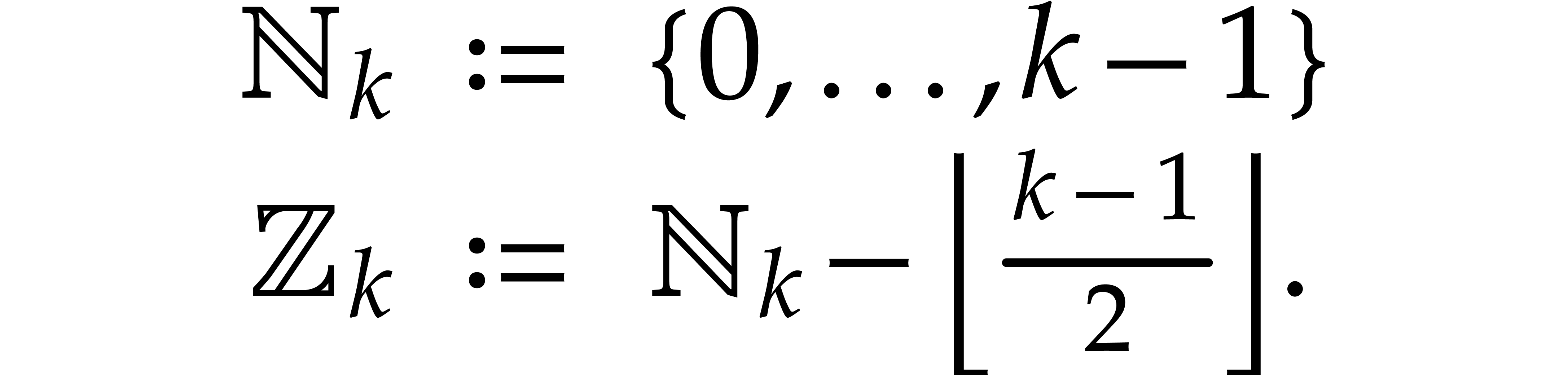
We may use both 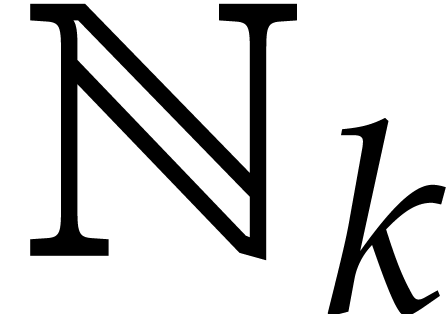 and
and 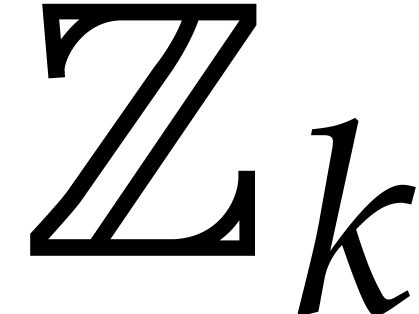 as
sets of canonical representatives modulo
as
sets of canonical representatives modulo 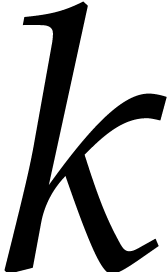 .
Given
.
Given 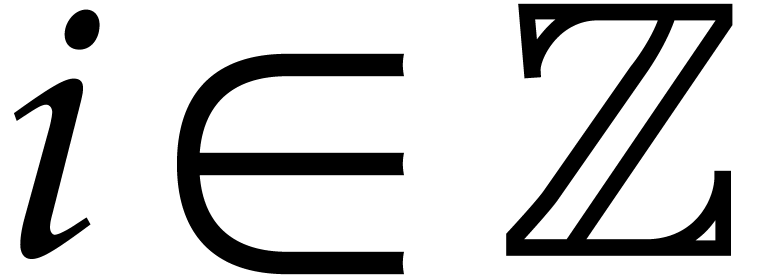 and depending on the context, we write
and depending on the context, we write
 for the unique
for the unique 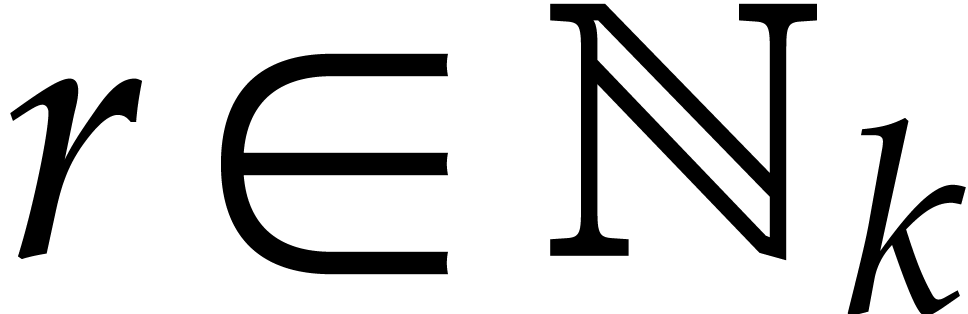 or
or 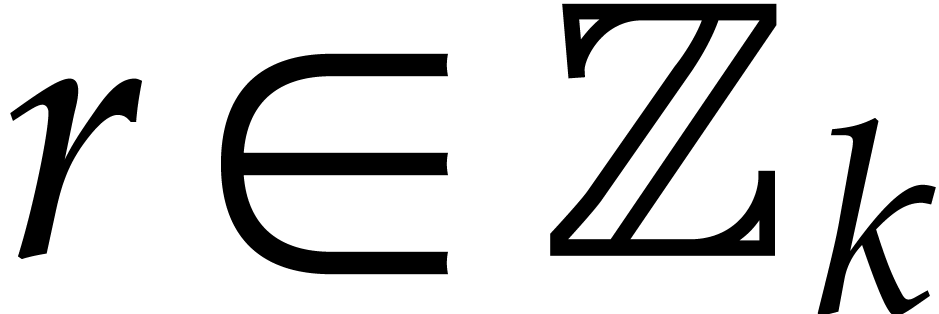 with
with  .
.
This section presents sparse data structures, computational models, and quantitative results about prime distributions. At the end, an elementary fast algorithm is presented for testing the divisibility of several integers by several prime numbers.
We order  lexicographically by
lexicographically by  . Given formal indeterminates
. Given formal indeterminates  and an exponent
and an exponent 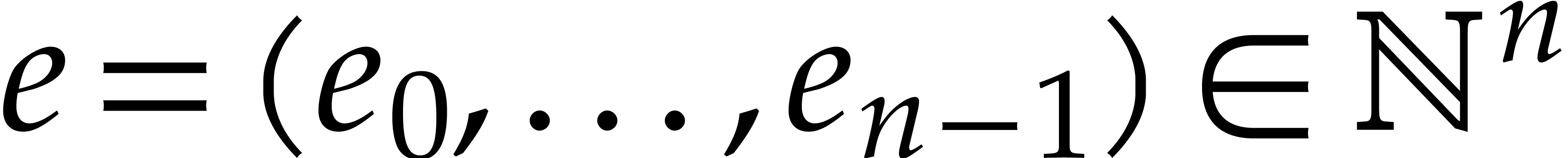 , we
define
, we
define 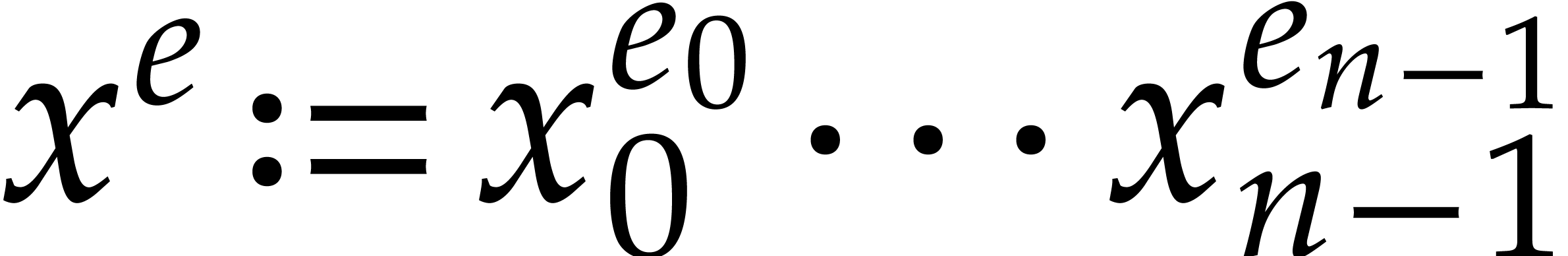 . We define the
bit-size of an integer
. We define the
bit-size of an integer  as
as  . In particular,
. In particular, 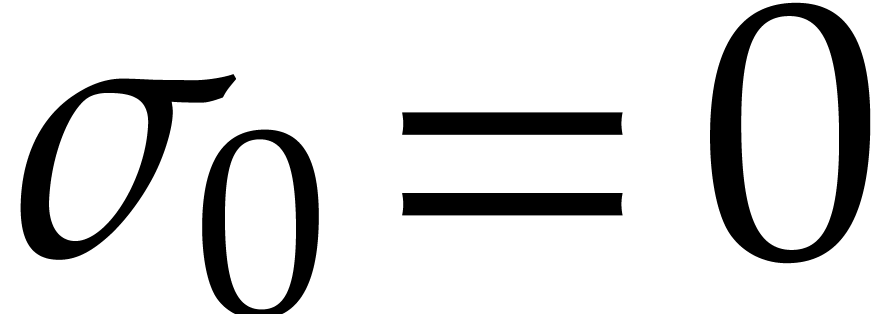 ,
,
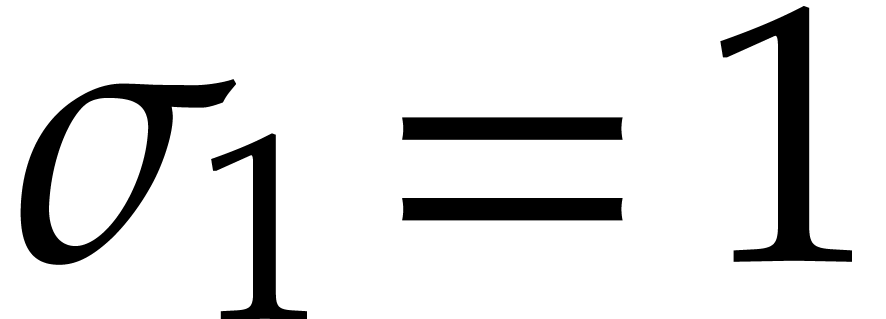 ,
, 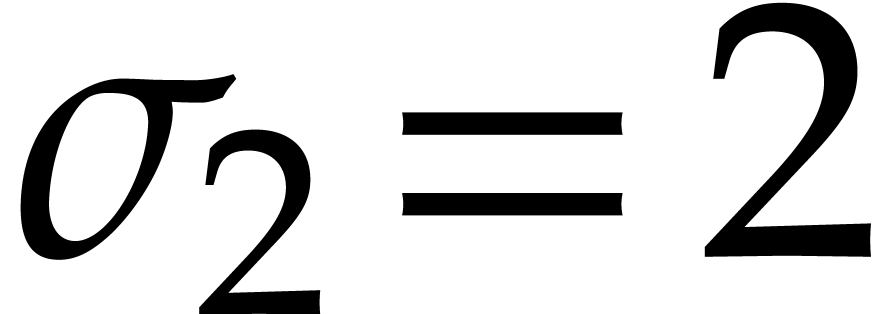 , etc. We define the bit-size of an
exponent tuple
, etc. We define the bit-size of an
exponent tuple 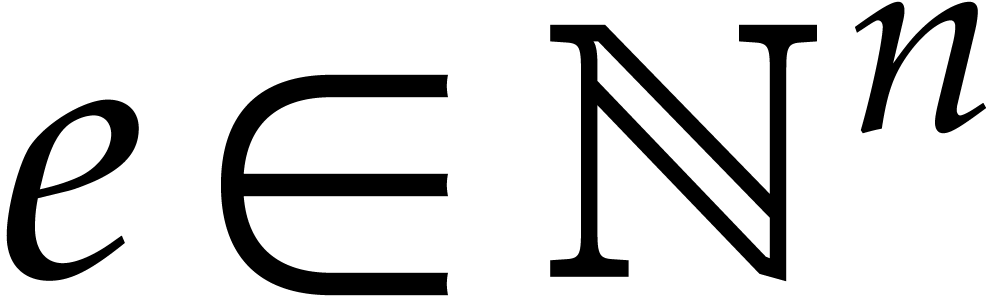 by
by 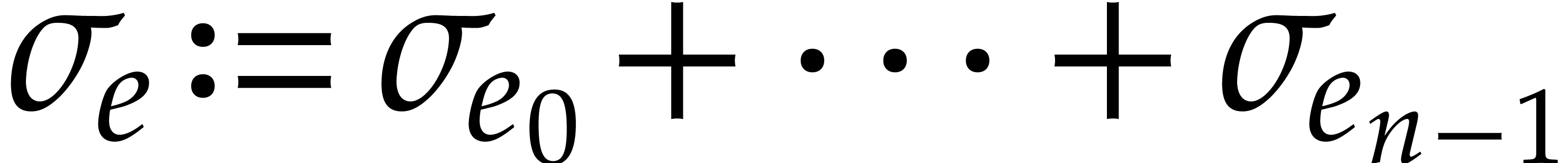 .
We extend these definitions to the cases when
and
.
We extend these definitions to the cases when
and 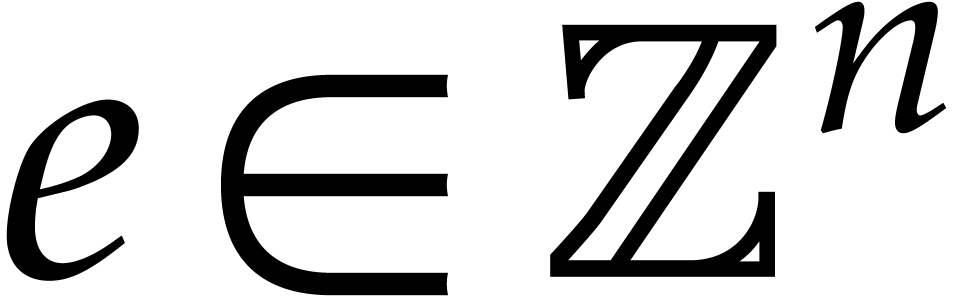 by setting
by setting 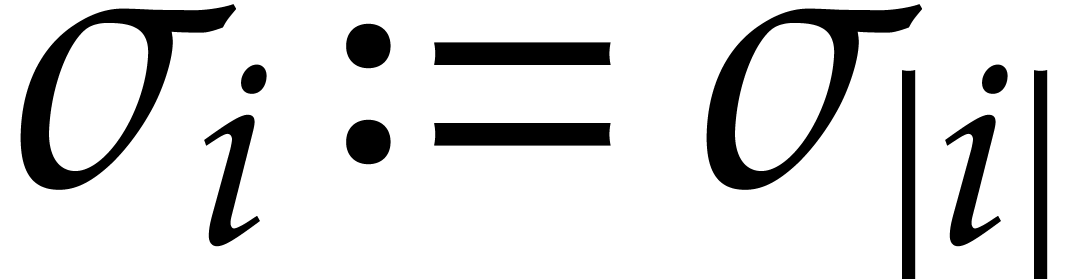 and
and 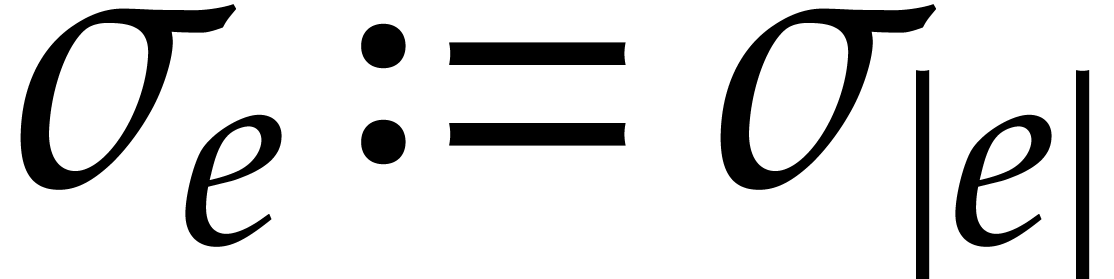 , where
, where  .
.
Now consider a multivariate polynomial .
Then can uniquely be written as a sum

where 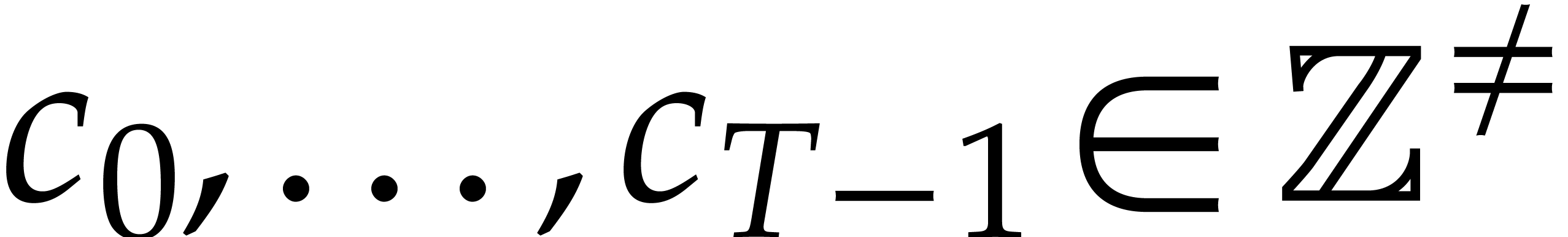 and
and 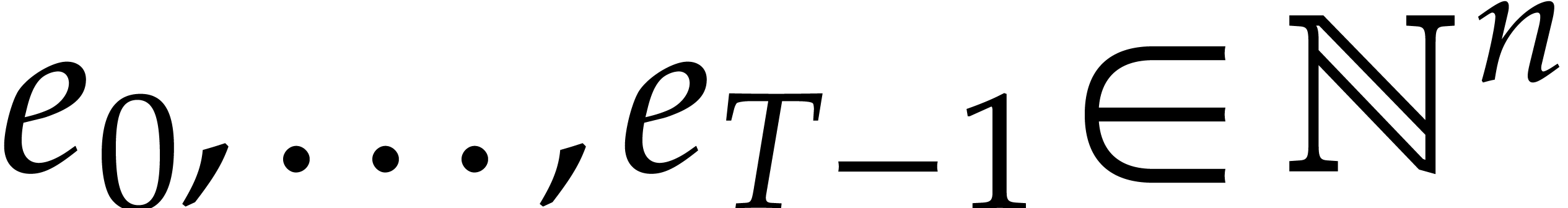 are such that
are such that
 . We call this the sparse
representation of . We
call
. We call this the sparse
representation of . We
call  the exponents of
and
the exponents of
and  the corresponding coefficients. We
also say that
the corresponding coefficients. We
also say that 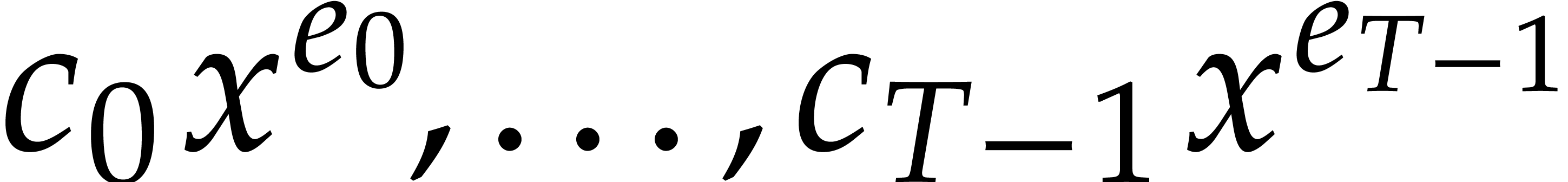 are the terms of and we call
are the terms of and we call 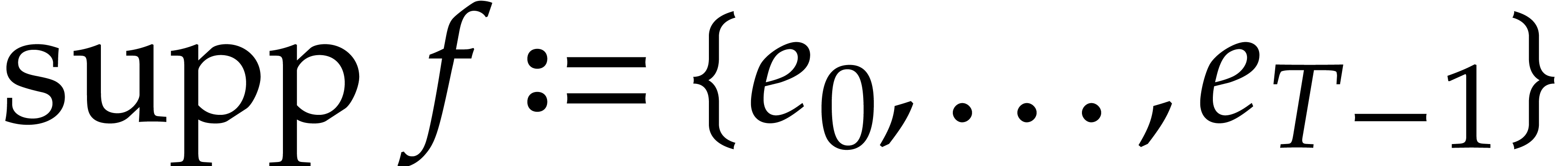 the
support of . Any
non-zero
the
support of . Any
non-zero  with
with  and
and 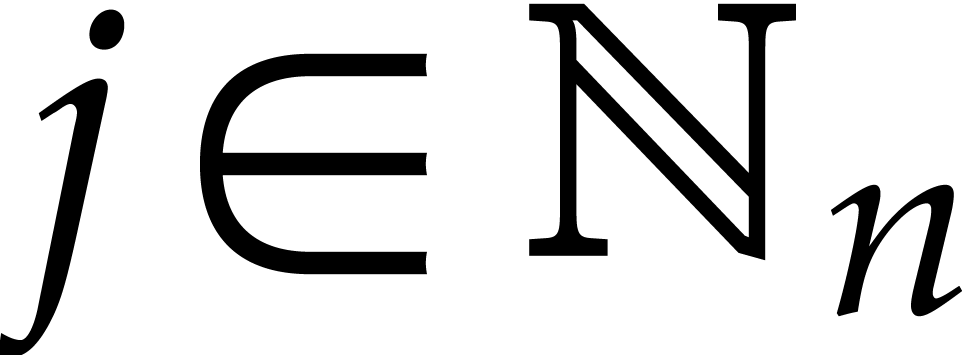 is called an individual exponent of . We define
is called an individual exponent of . We define  to be the bit-size of .
to be the bit-size of .
Remark  then becomes
then becomes 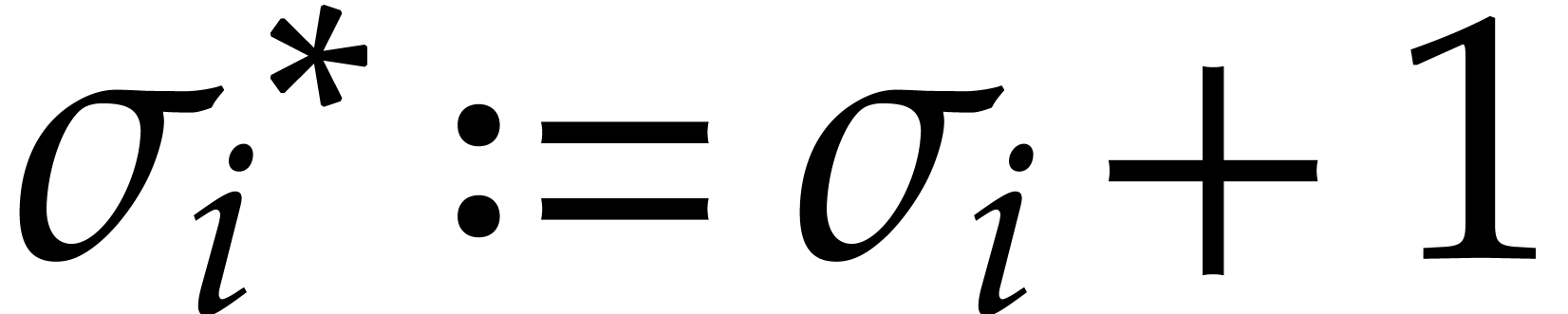 . For
. For 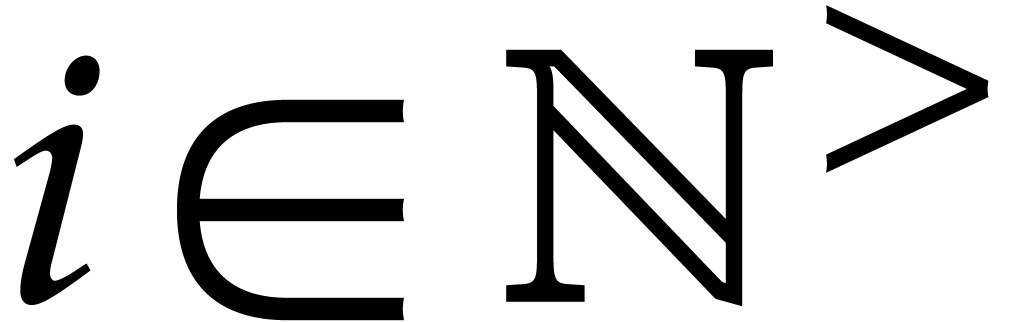 ,
we also define
,
we also define  . Exponents
. Exponents
 can be stored by appending the representations
of
can be stored by appending the representations
of  , but this is suboptimal
in the case when only a few entries of
, but this is suboptimal
in the case when only a few entries of 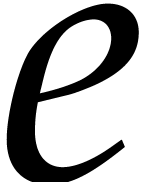 are
non-zero. For such “sparse exponents”, one prefers to store
the pairs
are
non-zero. For such “sparse exponents”, one prefers to store
the pairs 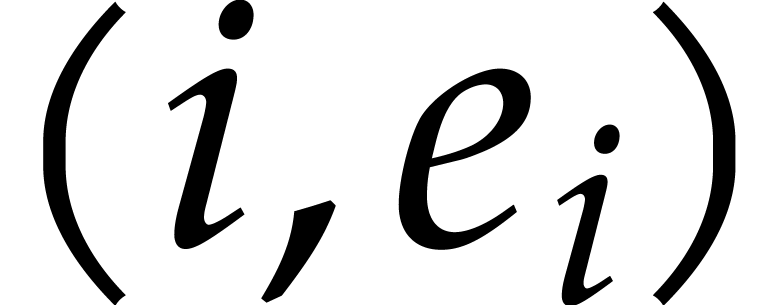 for which
for which 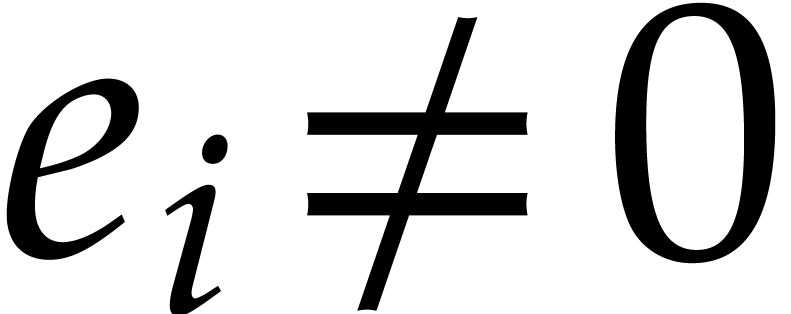 , again using suitable markers. For this reason, the
Turing bit-size of becomes
, again using suitable markers. For this reason, the
Turing bit-size of becomes 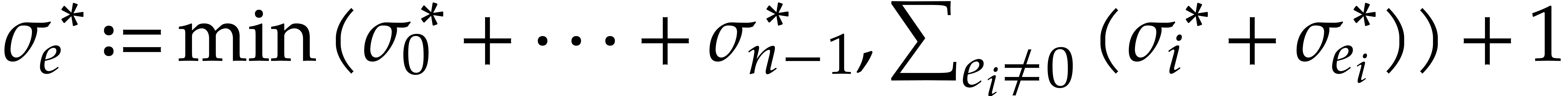 .
.
Throughout this paper, we will analyze bit complexities in the RAM model
as in [15]. In this model, it is known [22]
that two -bit integers can be
multiplied in time 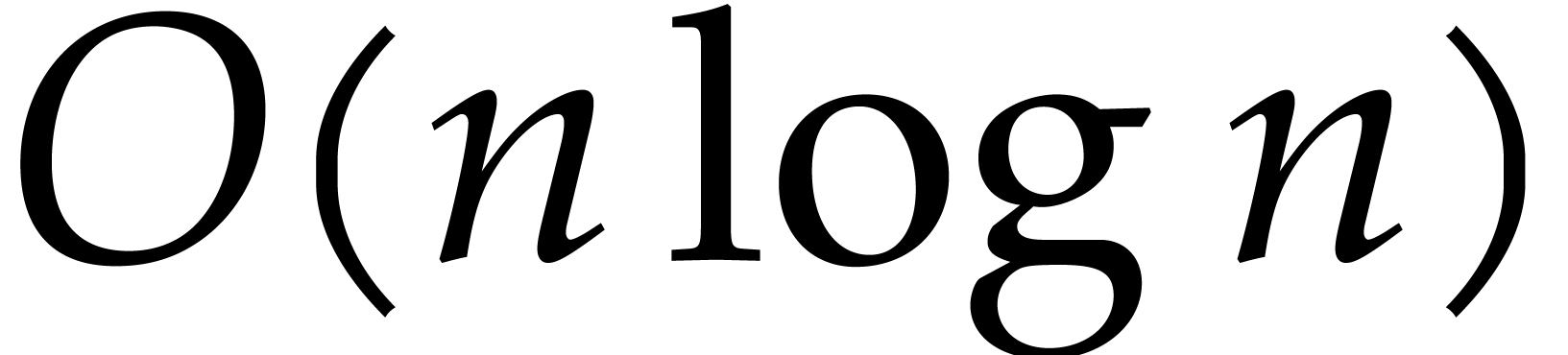 . As a
consequence, given an -bit
modulus
. As a
consequence, given an -bit
modulus 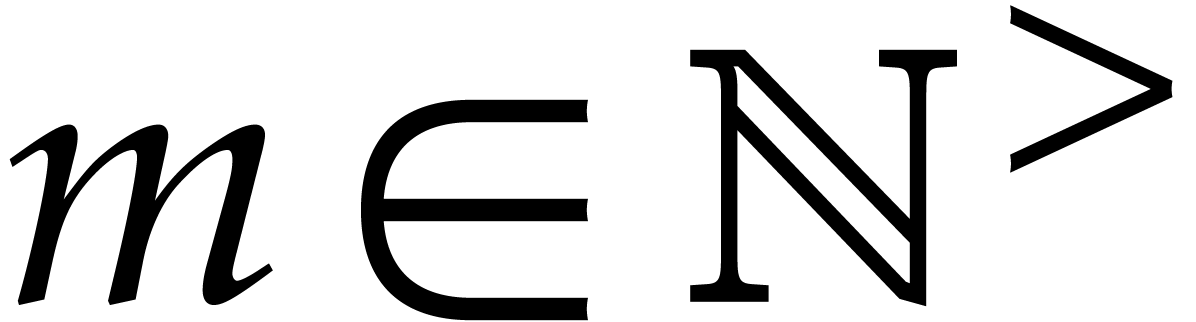 , the ring operations
in
, the ring operations
in 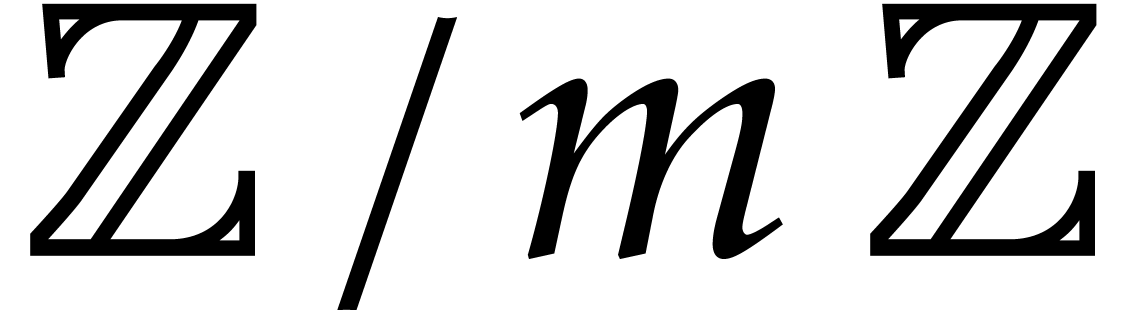 can be done with the same complexity [9, 15]. Inverses can be computed in time
can be done with the same complexity [9, 15]. Inverses can be computed in time 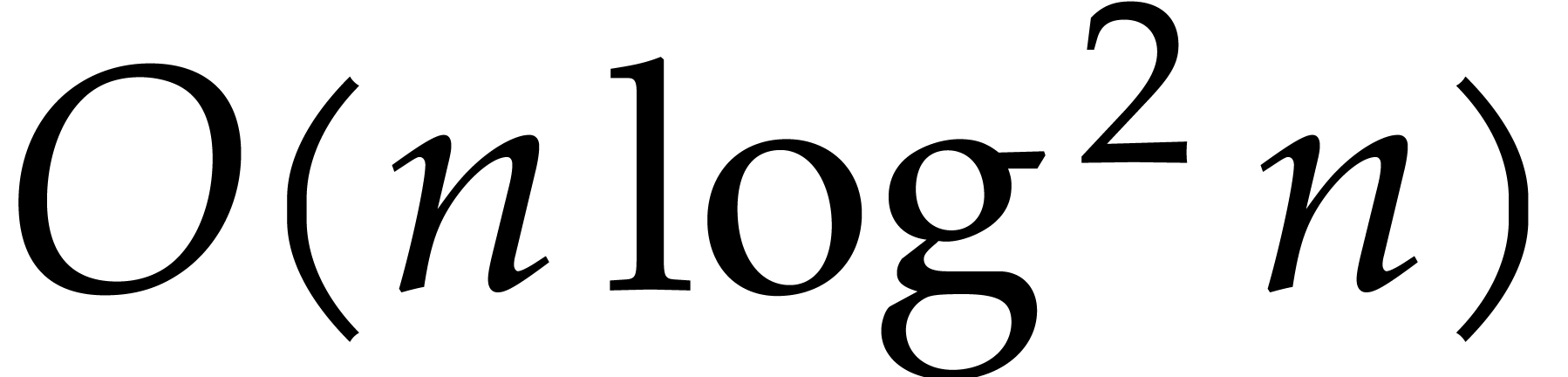 , whenever they exist [9,
15]. For randomized algorithms, we assume that we have an
instruction for generating a random bit in constant time.
, whenever they exist [9,
15]. For randomized algorithms, we assume that we have an
instruction for generating a random bit in constant time.
Consider a polynomial . A
modular blackbox representation for is
a program that takes a modulus and integers  as input, and that
returns
as input, and that
returns 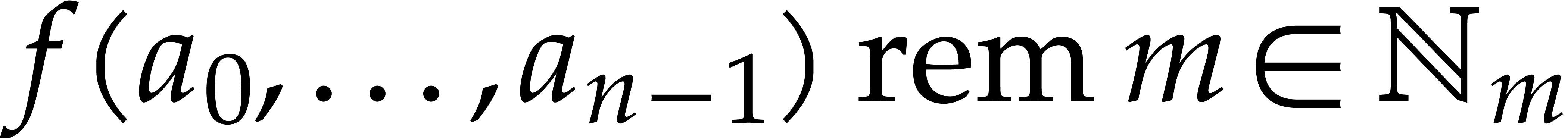 . A modular
blackbox polynomial is a polynomial that is
represented in this way. The cost (or, better, a cost function)
of such a polynomial is a function
. A modular
blackbox polynomial is a polynomial that is
represented in this way. The cost (or, better, a cost function)
of such a polynomial is a function  such that
yields an upper bound for the running time if
has bit-size
such that
yields an upper bound for the running time if
has bit-size  .
It will be convenient to always assume that the average cost
.
It will be convenient to always assume that the average cost
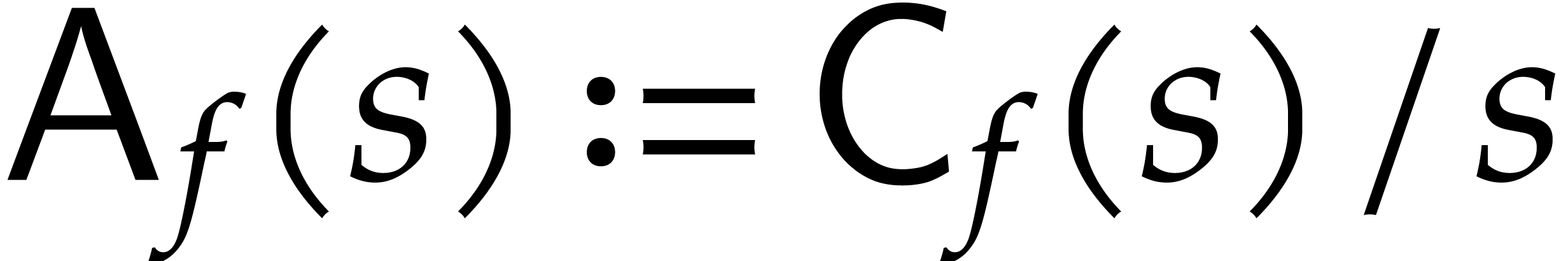 per bit of the modulus is non-decreasing and
that
per bit of the modulus is non-decreasing and
that 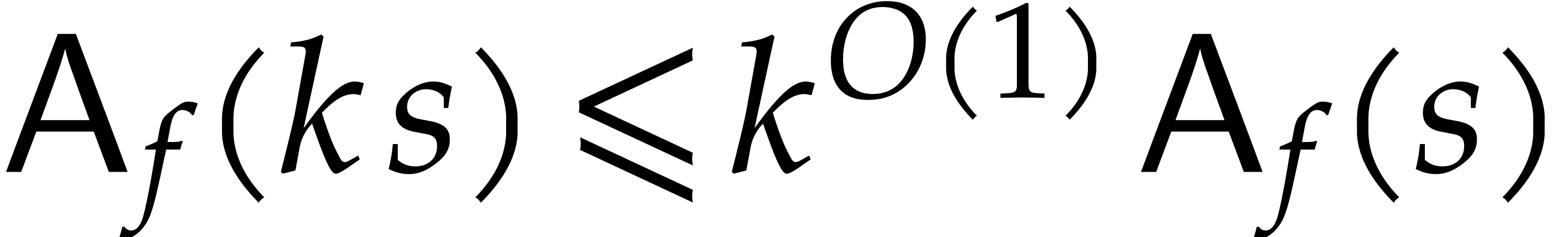 for any
for any 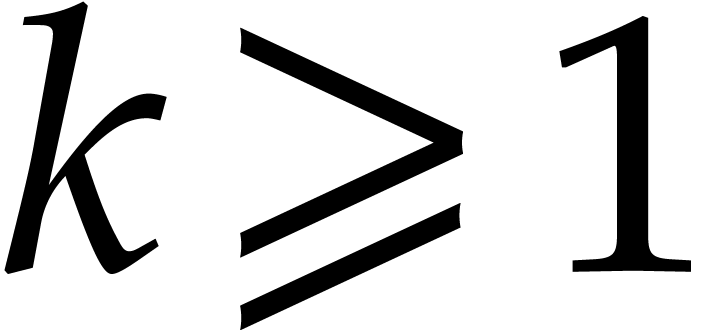 .
Since should at least read its
input values, we will freely assume that
.
Since should at least read its
input values, we will freely assume that 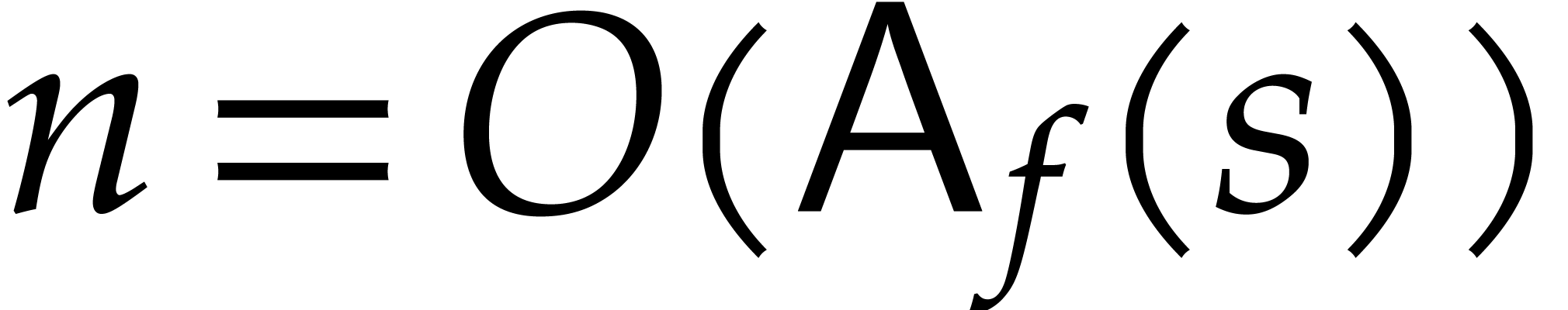 .
.
Remark  that only uses ring
operations, the above average cost function usually becomes
that only uses ring
operations, the above average cost function usually becomes 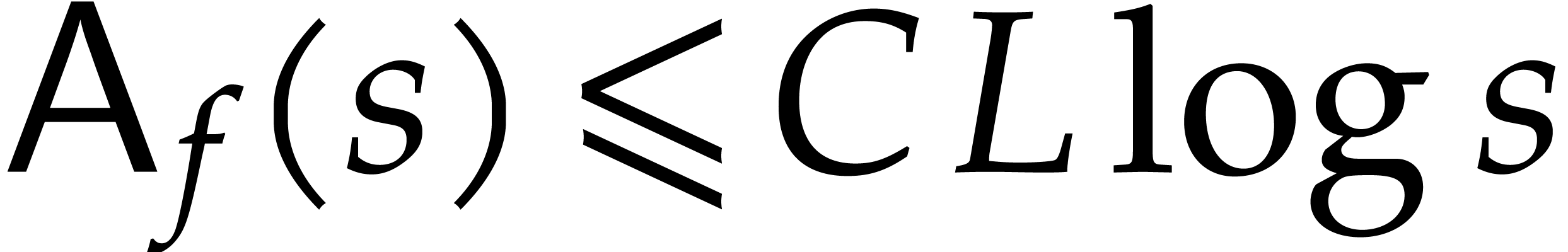 , for some fixed constant
, for some fixed constant  that does not depend on .
that does not depend on .
If the SLP also allows for divisions, then we rather obtain 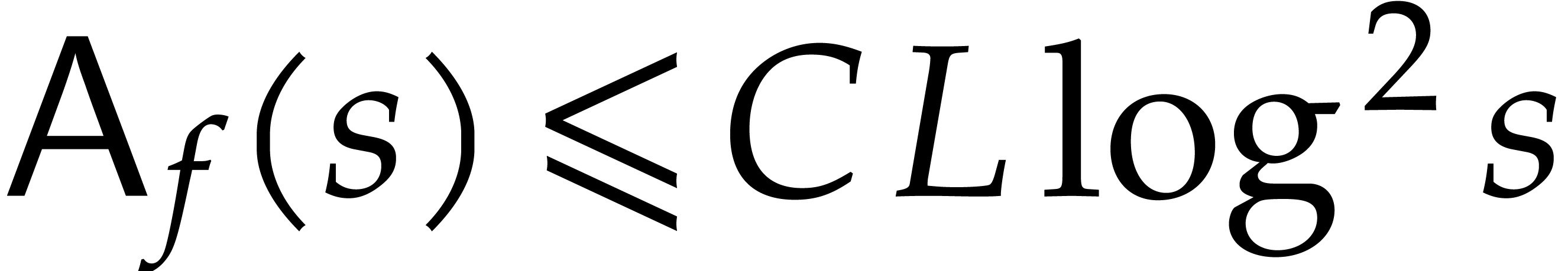 , but this is out of the scope of this paper,
due to the “division by zero” issue. In fact, computation
trees [10] are more suitable than SLPs in this context. For
instance, the computation of determinants using Gaussian elimination
naturally fits in this setting, since the chosen computation path may
then depend on the modulus
, but this is out of the scope of this paper,
due to the “division by zero” issue. In fact, computation
trees [10] are more suitable than SLPs in this context. For
instance, the computation of determinants using Gaussian elimination
naturally fits in this setting, since the chosen computation path may
then depend on the modulus  .
.
However, although these bounds “usually” hold
(i.e. for all common algebraic algorithms that we are aware
of, including the RAM model), they may fail in pathological cases when
the SLP randomly accesses data that are stored at very distant locations
on the Turing tape. For this reason, the blackbox cost model may be
preferred in order to study bit complexities. In this model, a suitable
replacement for the length of an SLP is the
average cost function  , which
typically involves only a logarithmic overhead in the bit-length
, which
typically involves only a logarithmic overhead in the bit-length  .
.
All along this paper  (resp. ) will bound the bit-size (resp. number of
terms) of the polynomial to be interpolated, and
(resp. ) will bound the bit-size (resp. number of
terms) of the polynomial to be interpolated, and  and
and 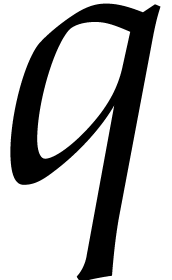 will denote random prime numbers that
satisfy:
will denote random prime numbers that
satisfy:
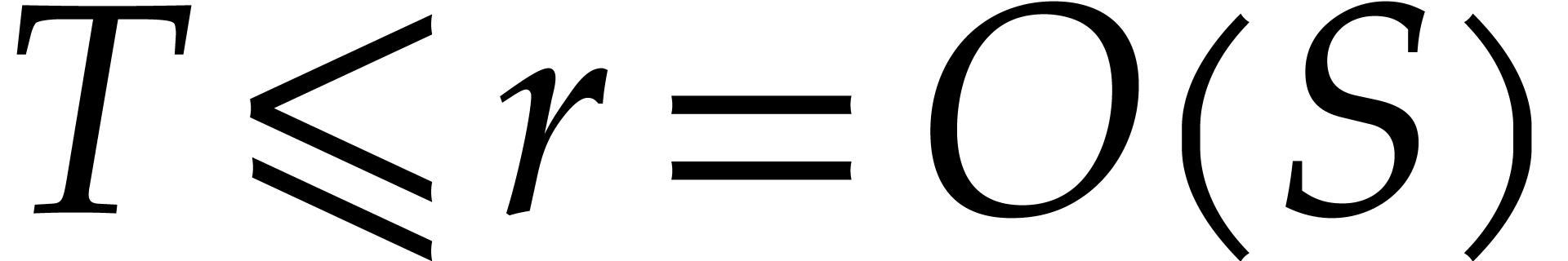 ,
,
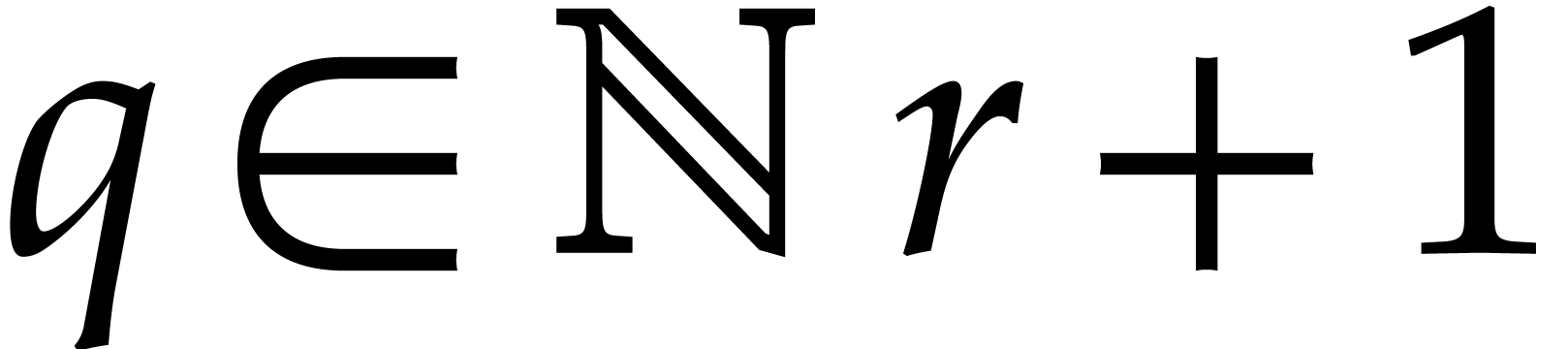 ,
,
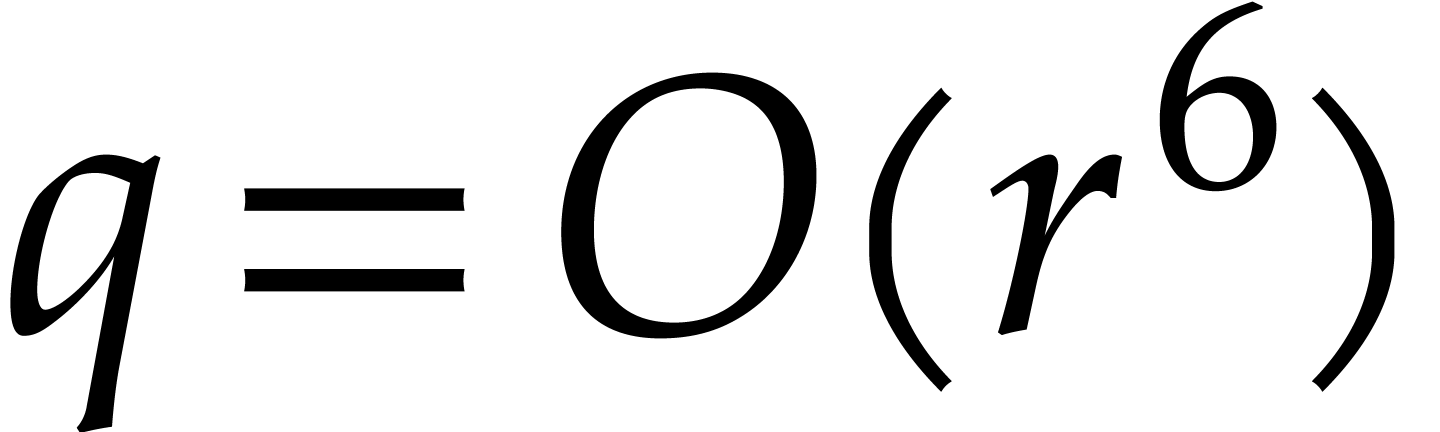 .
.
The construction of and
will rely on the following number theoretic theorems, where  stands for the natural logarithm, that is
stands for the natural logarithm, that is 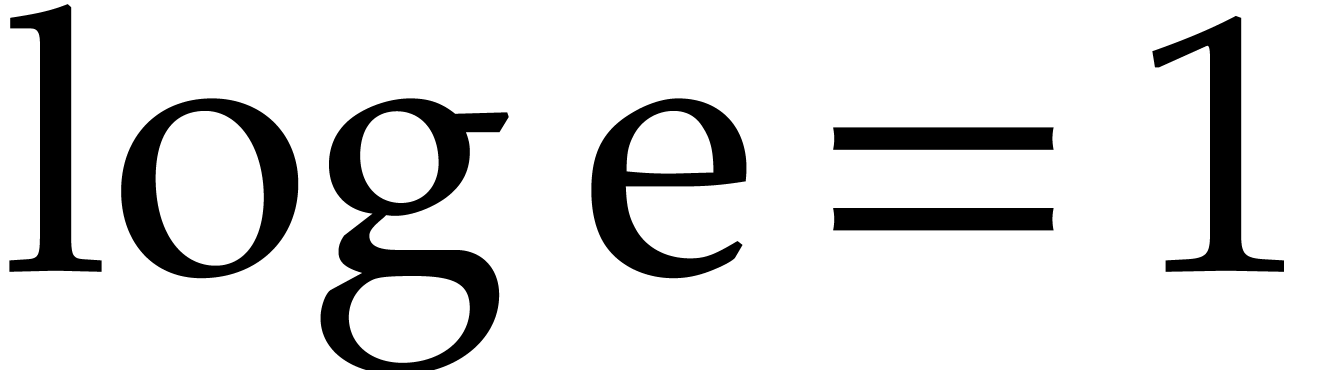 . We will also use
. We will also use 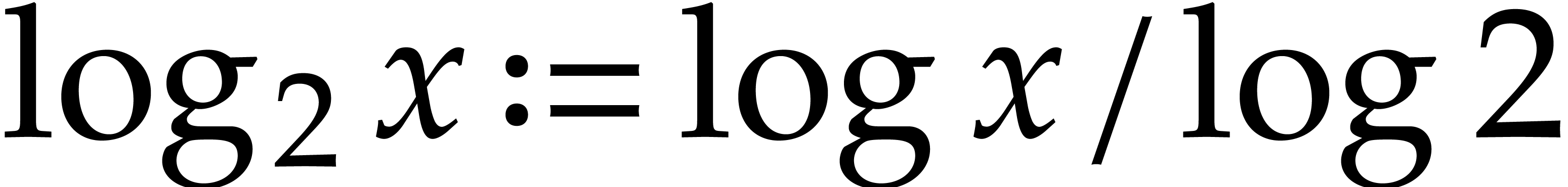 .
.
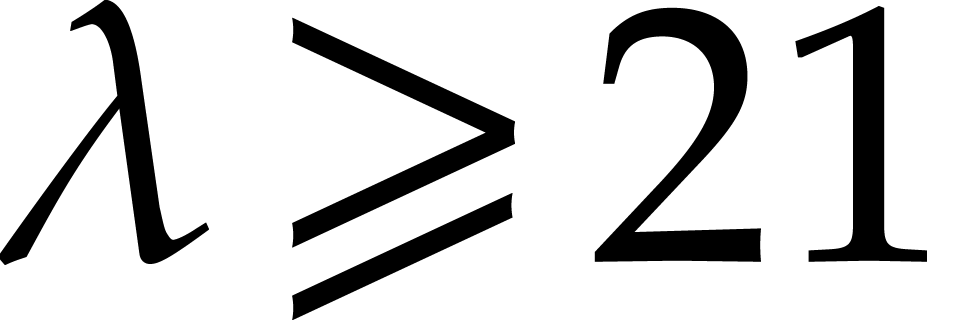 , there exist at least
, there exist at least 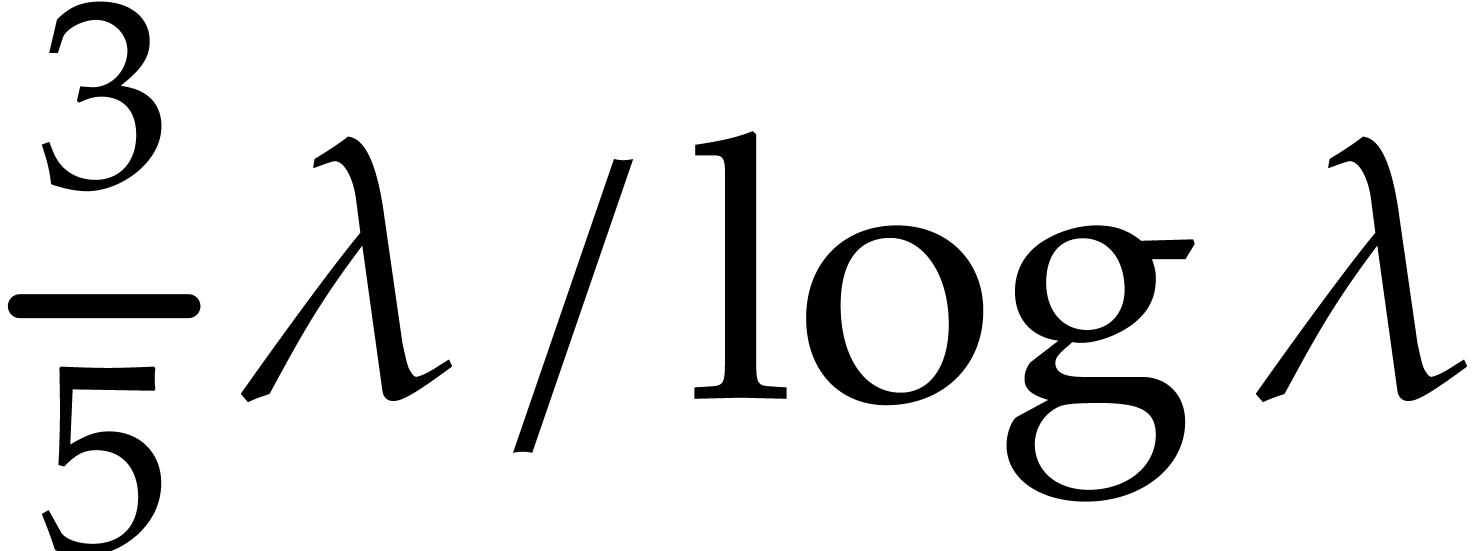 distinct prime numbers in the open interval
distinct prime numbers in the open interval 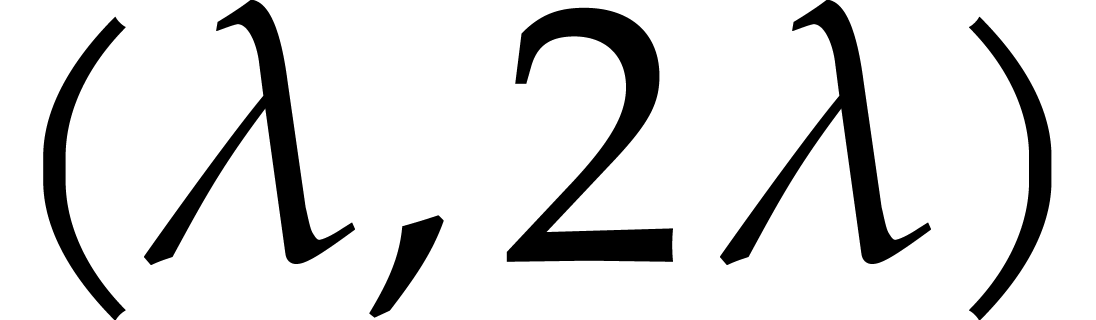 .
.
Proof. The function 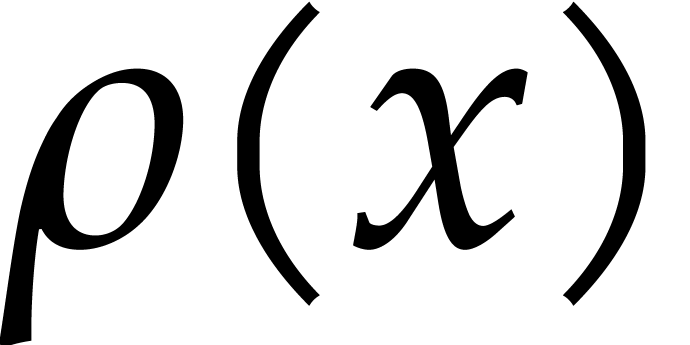 is
increasing for
is
increasing for 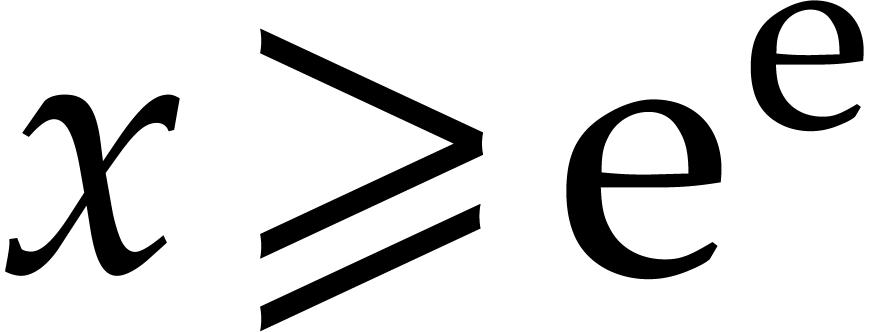 and
and 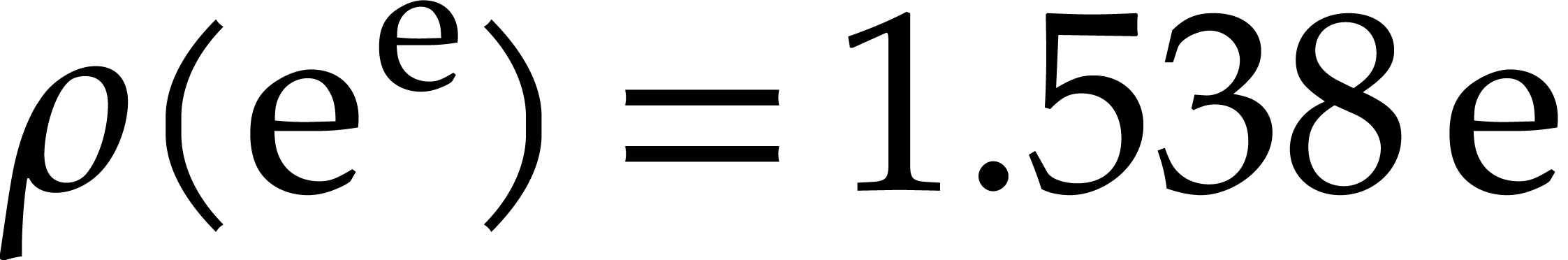 .
So it is always non-decreasing and continuous. The number of prime
divisor of any
.
So it is always non-decreasing and continuous. The number of prime
divisor of any 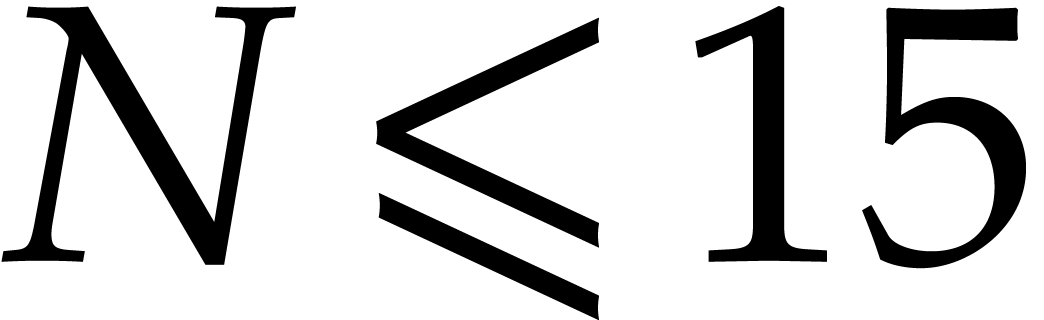 it at most
it at most 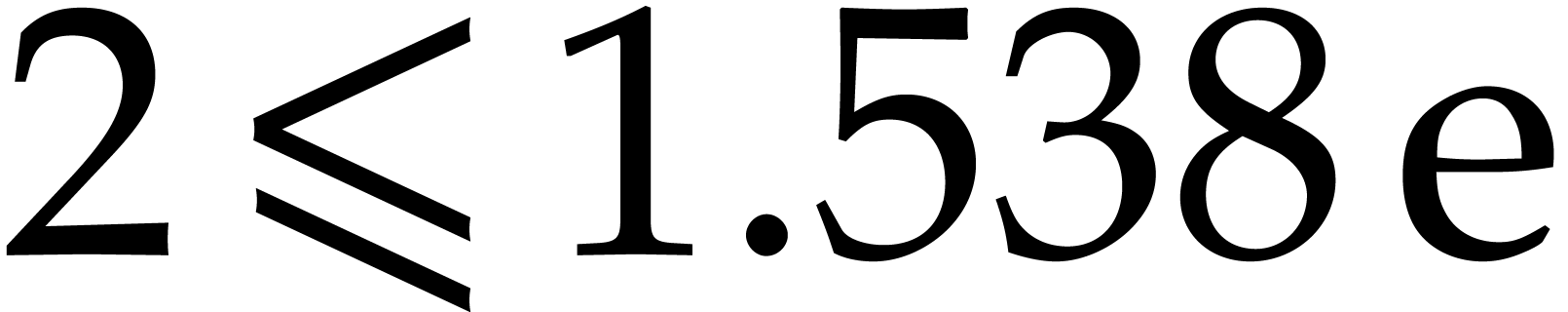 . Let
. Let 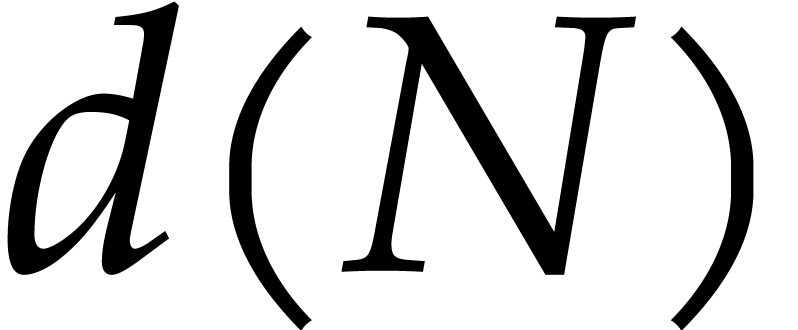 and
and 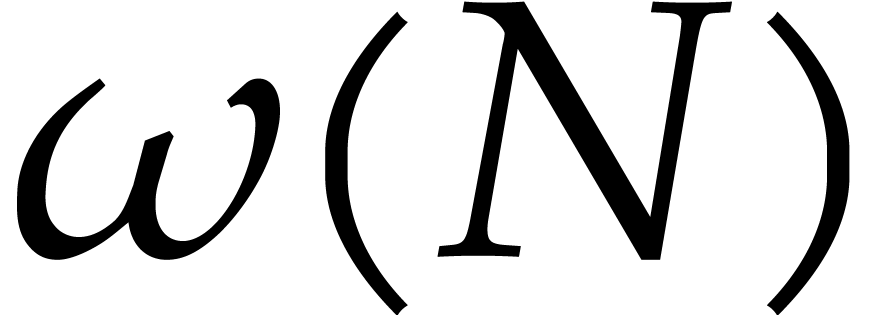 respectively be the number of divisors and prime divisors of
respectively be the number of divisors and prime divisors of  . Then clearly
. Then clearly 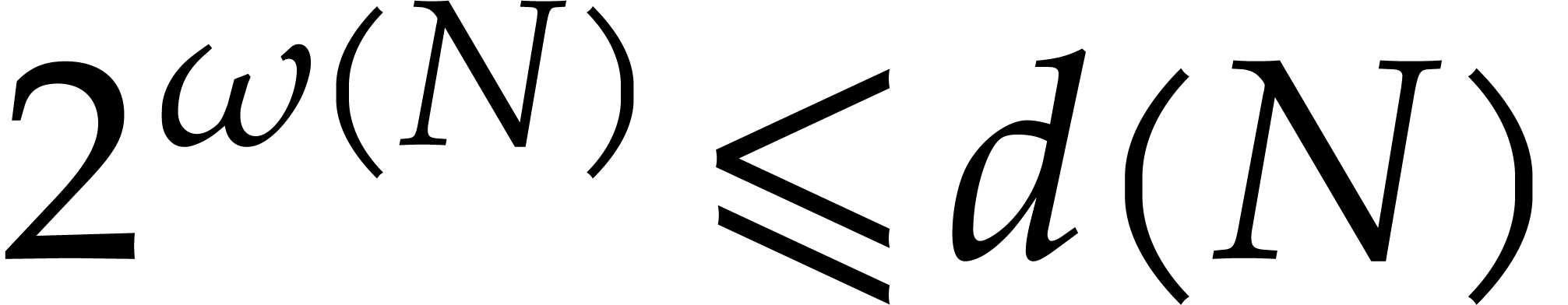 . Now for all
. Now for all 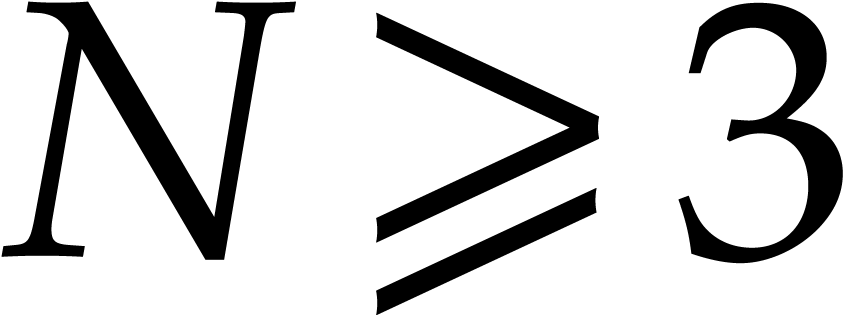 we know
from [39] that
we know
from [39] that
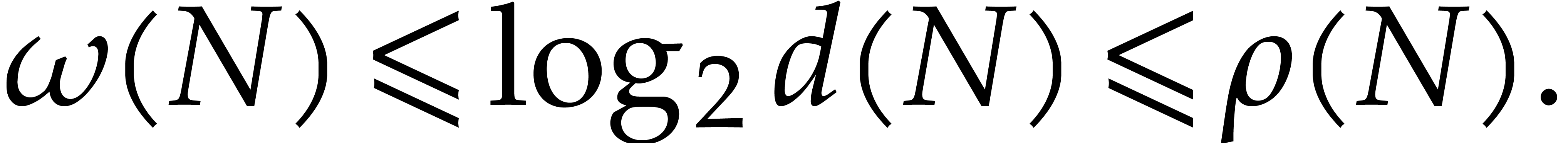

We will need the following slightly modified version of [16, Theorem 2.1], which is itself based on a result from [44].
 and
and  ,
produces a triple
,
produces a triple 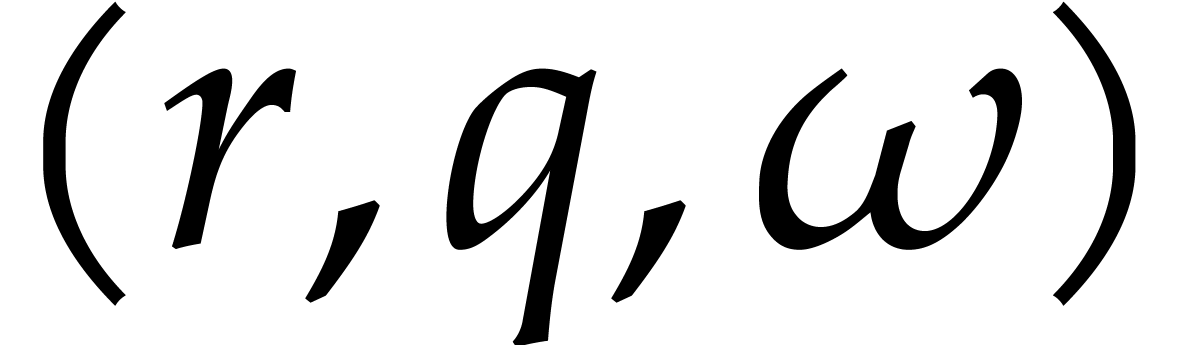 that has the following
properties with probability at least
that has the following
properties with probability at least  ,
and returns fail otherwise:
,
and returns fail otherwise:
is uniformly distributed amongst the
primes of  ;
;
there are at least 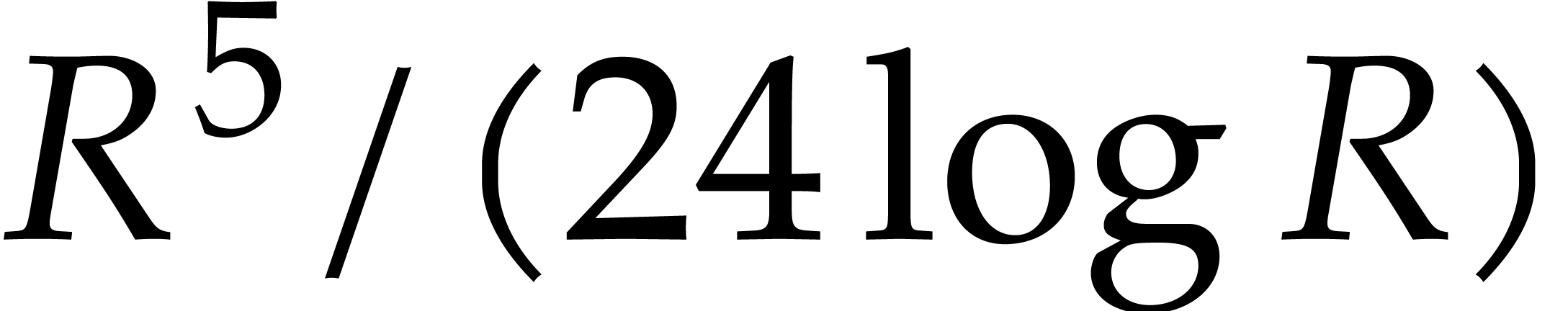 primes in
primes in  and is uniformly distributed
amongst them;
and is uniformly distributed
amongst them;
 is a primitive -th root of unity in
is a primitive -th root of unity in  .
.
Its worst-case bit complexity is 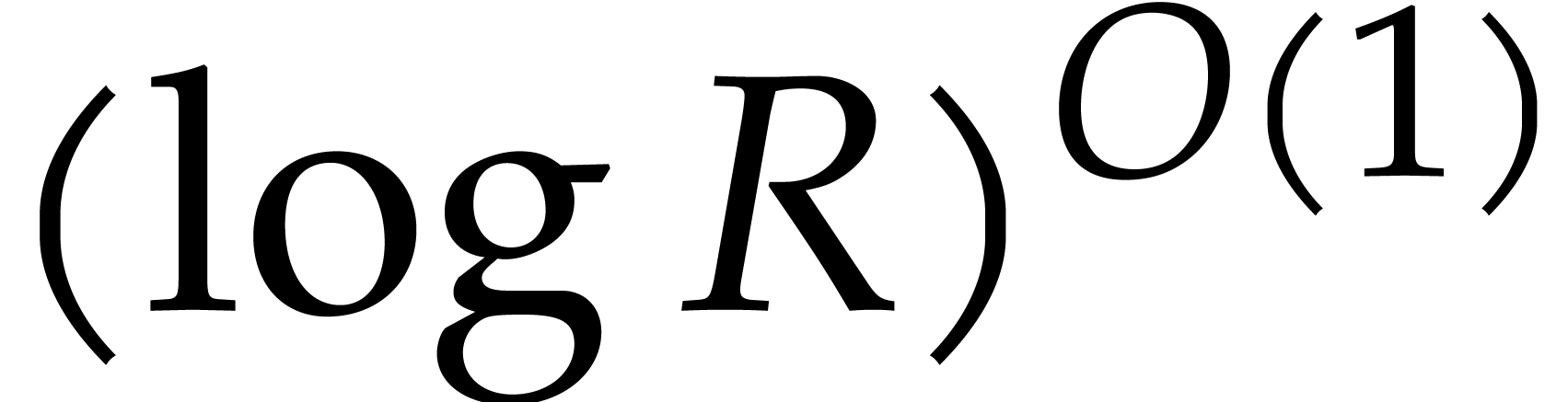 .
.
Proof. In [16, Theorem 2.1] the
statement (b) is replaced by the simpler condition that 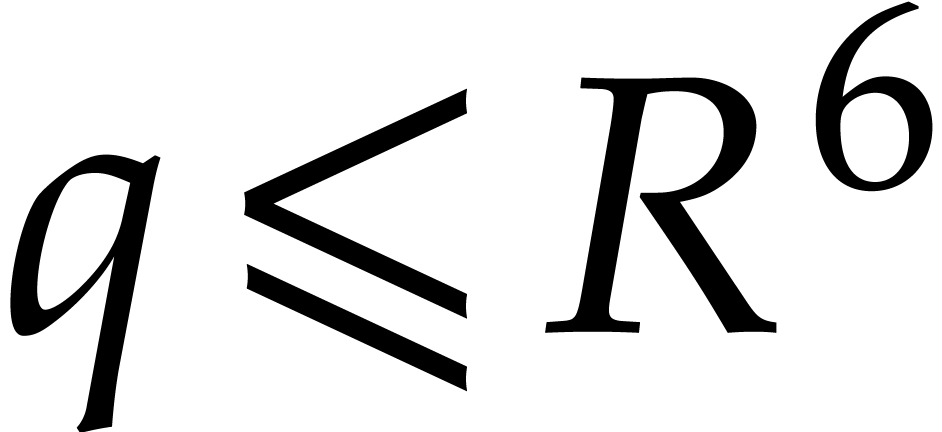 . But by looking at step 2 of the
algorithm on page 4 of [44], we observe that
. But by looking at step 2 of the
algorithm on page 4 of [44], we observe that 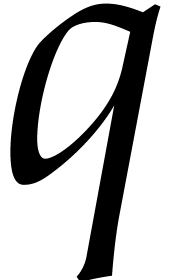 is actually uniformly distributed amongst the primes of
and that there are at least
such primes with high probability
is actually uniformly distributed amongst the primes of
and that there are at least
such primes with high probability 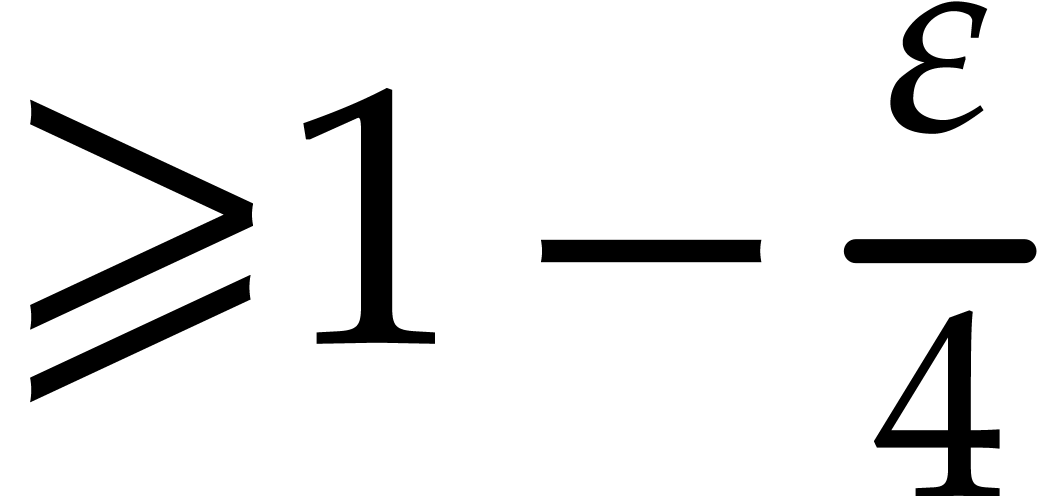 .
.
 be a real number in
be a real number in 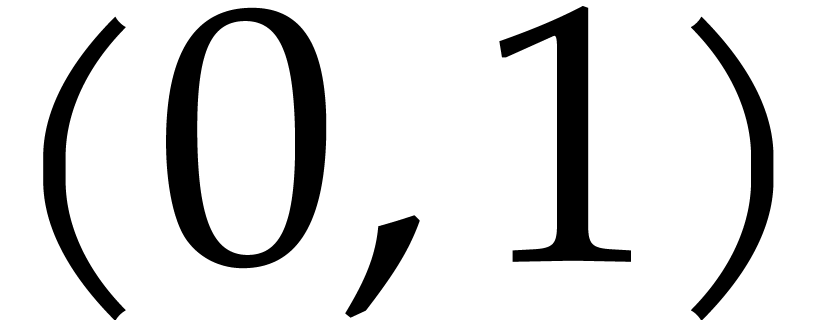 and let
and let 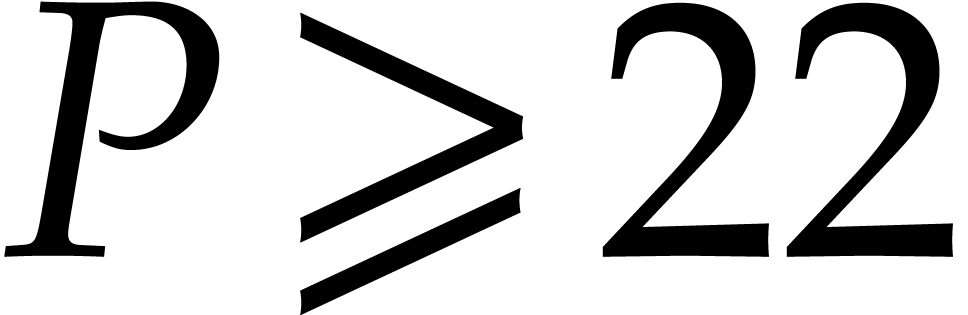 be such that
be such that 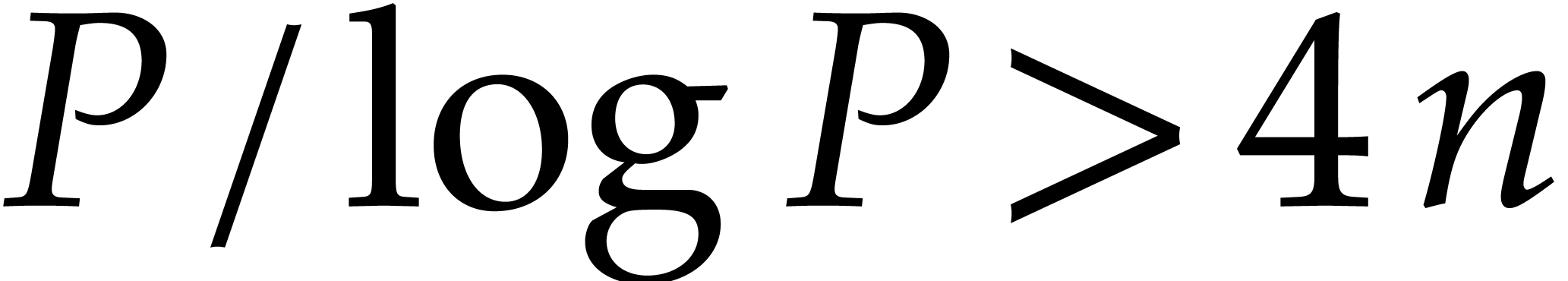 . There exists a Monte Carlo
algorithm that computes distinct random prime numbers
. There exists a Monte Carlo
algorithm that computes distinct random prime numbers  in
in  in time
in time

with a probability of success of at least  .
.
Proof. Theorem 2.3 asserts that
there are at least 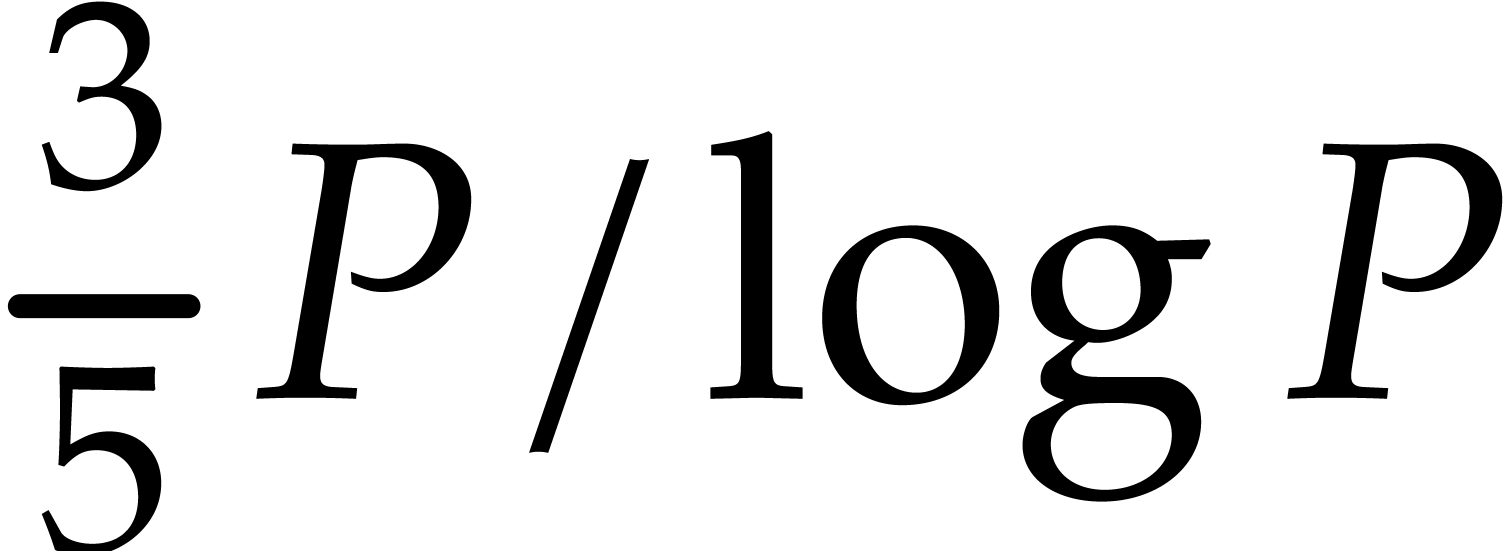 primes in the interval . The probability to fetch a prime
number in
primes in the interval . The probability to fetch a prime
number in  while avoiding at most
while avoiding at most 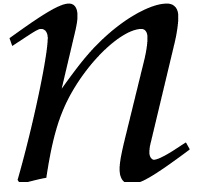 fixed numbers is at least
fixed numbers is at least
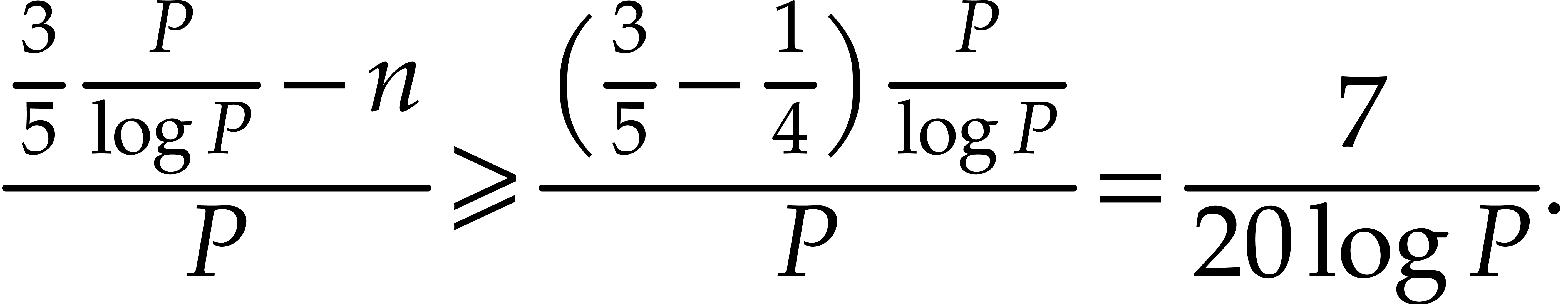
The probability of failure after 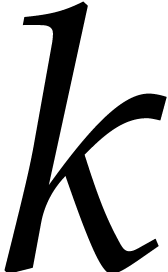 trials is at
most
trials is at
most 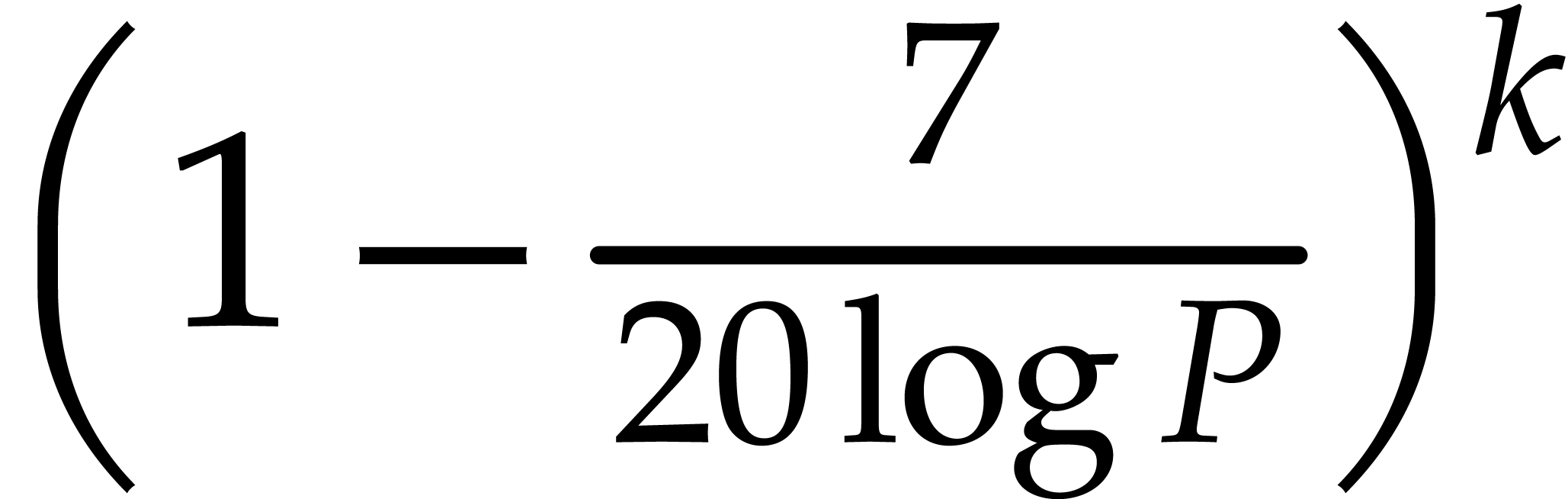 . By using the AKS
algorithm [1] each primality test takes time
. By using the AKS
algorithm [1] each primality test takes time 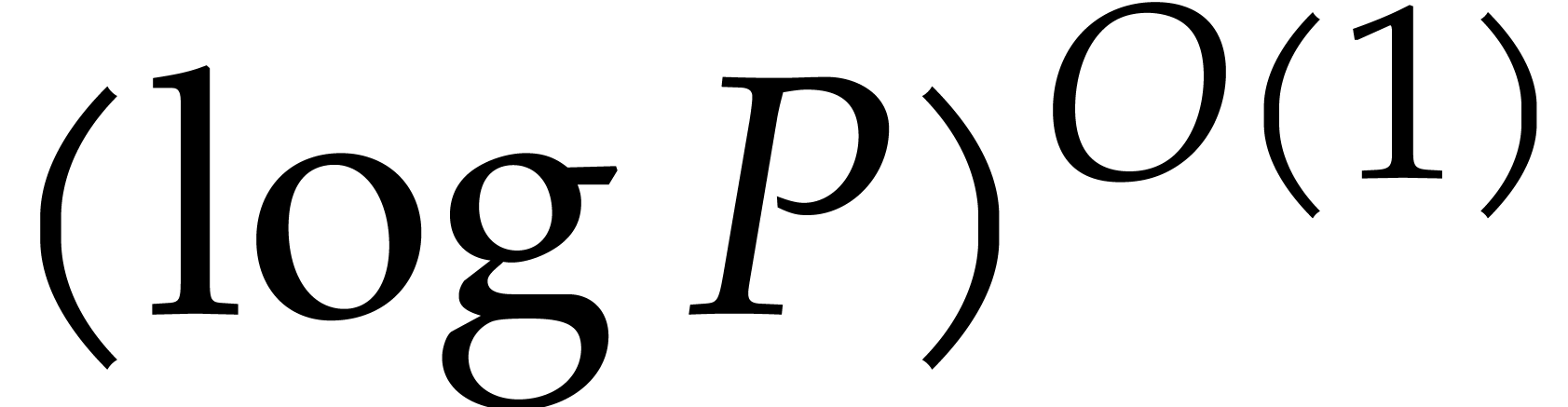 . The probability of success for picking distinct prime numbers in this way is at least
. The probability of success for picking distinct prime numbers in this way is at least
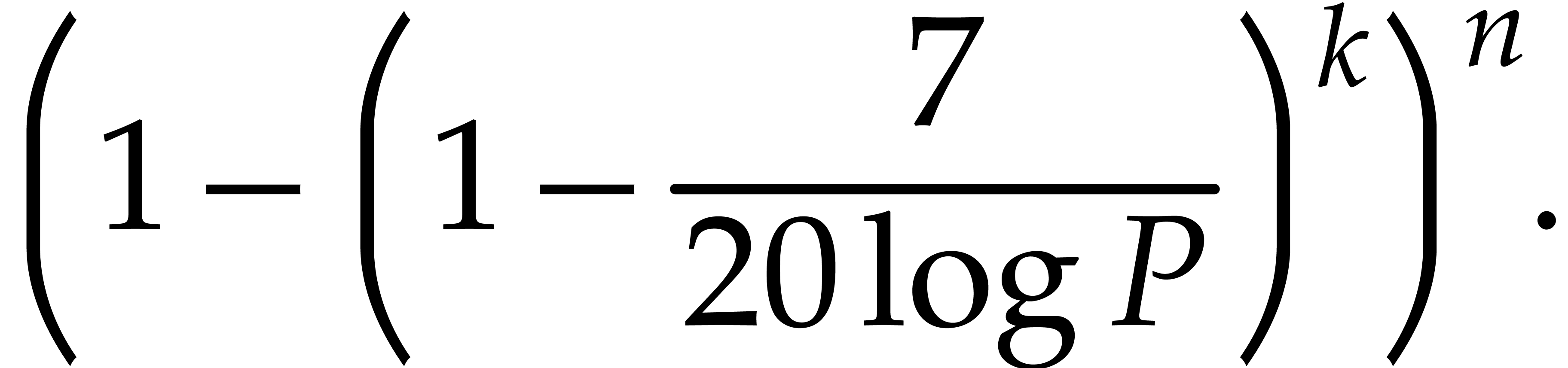
In order to guarantee this probability of success to be at least , it suffices to take
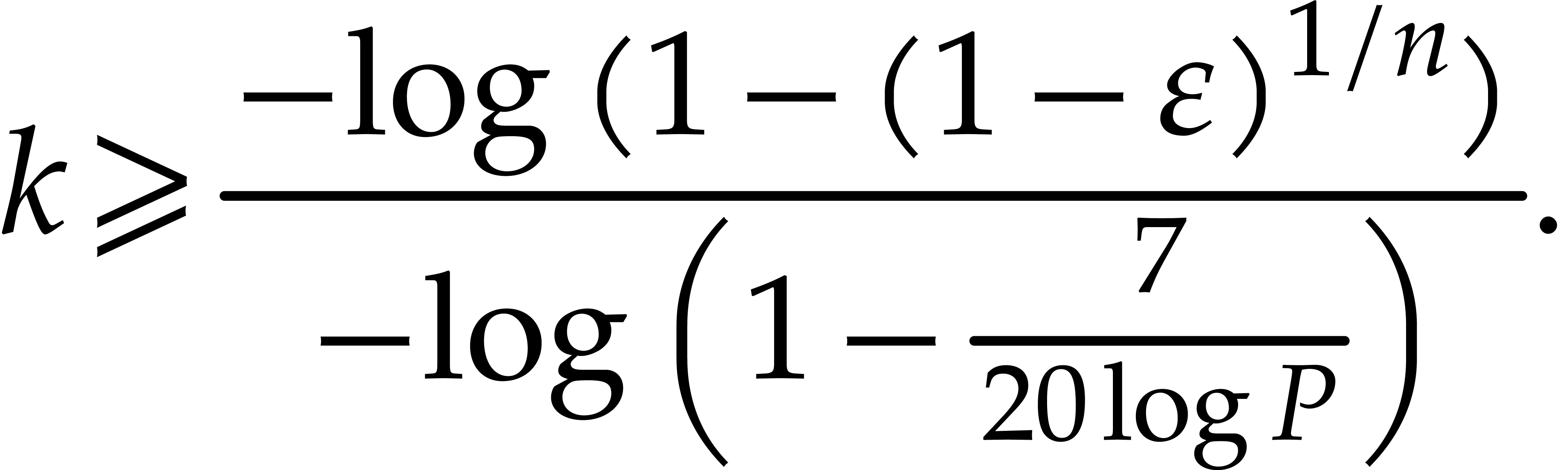
The concavity of the 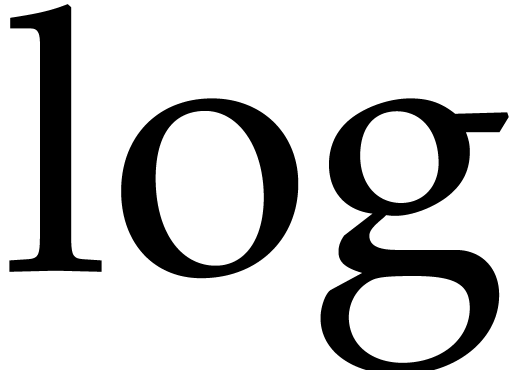 function yields
function yields 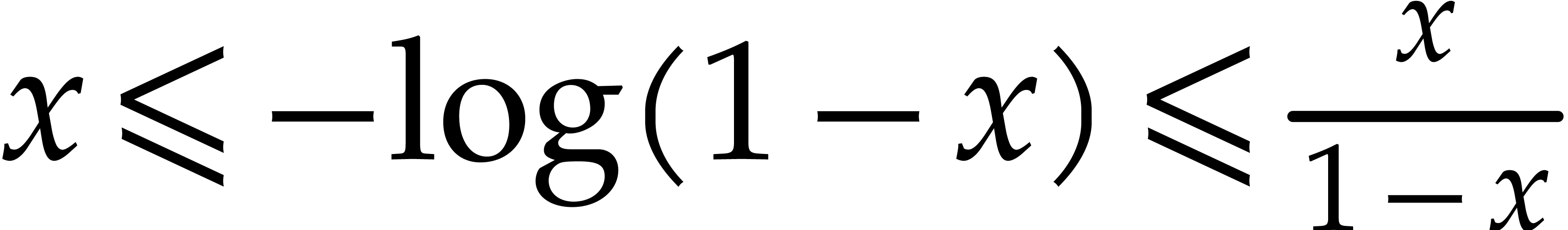 for
for 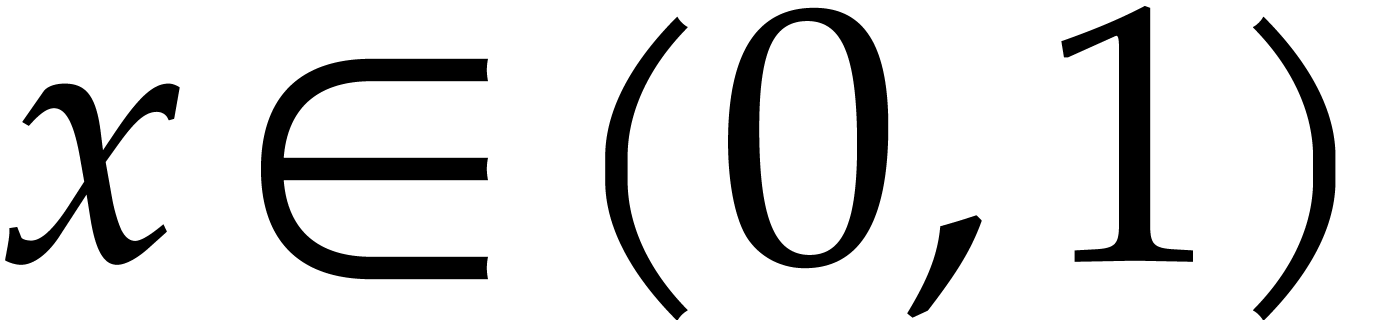 , whence
, whence
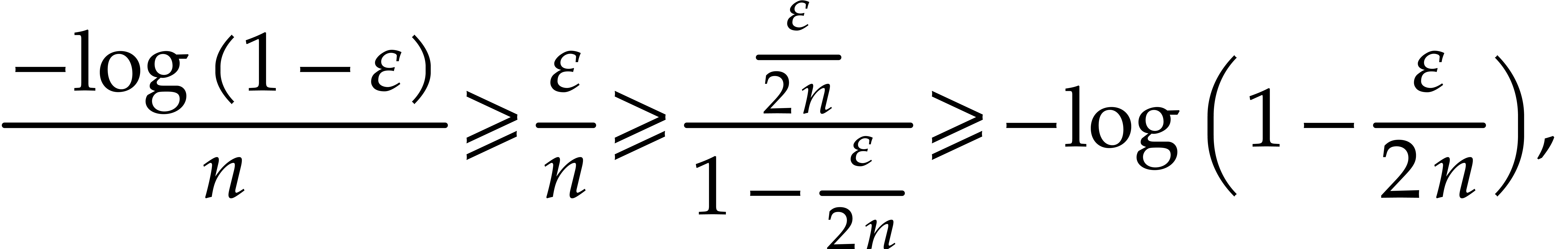
and consequently,
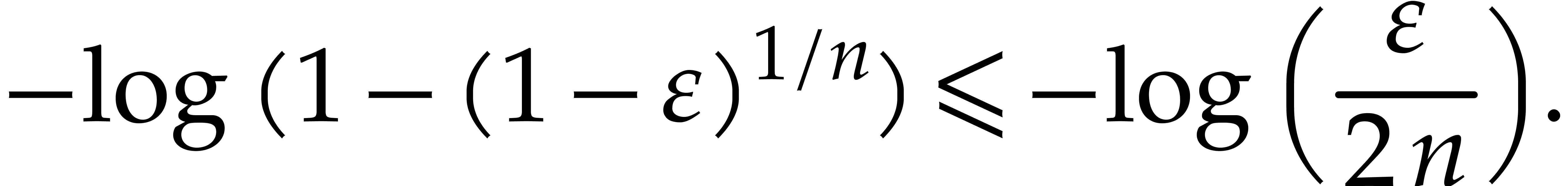
On the other hand we have 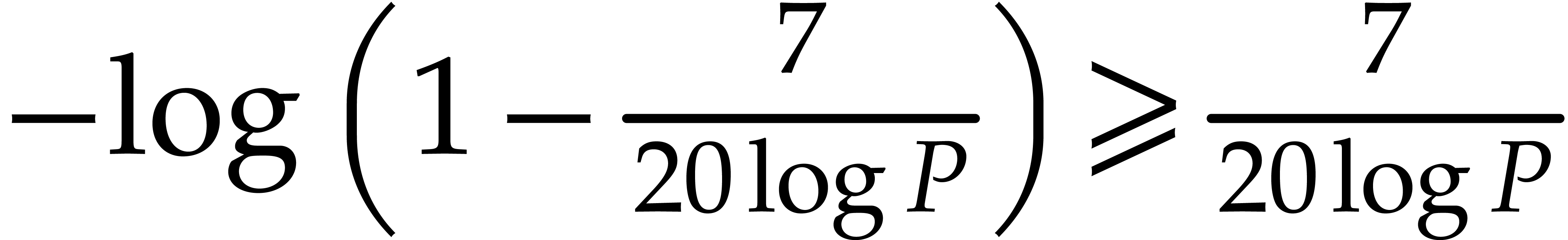 .
It therefore suffices to take
.
It therefore suffices to take
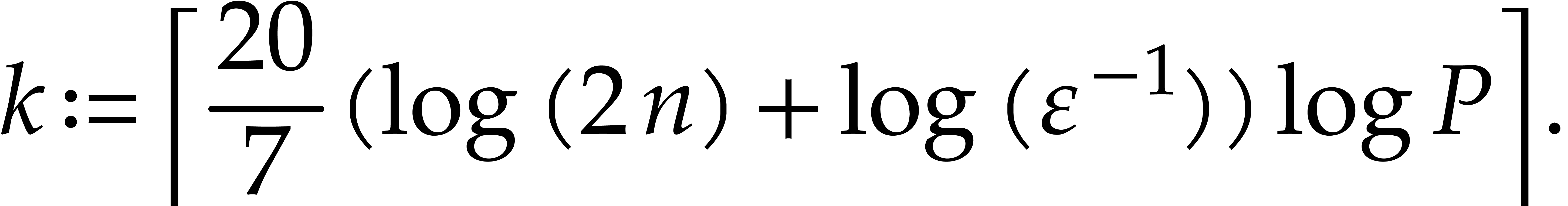
Let  be prime numbers and let
be prime numbers and let  be strictly positive integers. The aim of this subsection is to show
that the set of pairs
be strictly positive integers. The aim of this subsection is to show
that the set of pairs 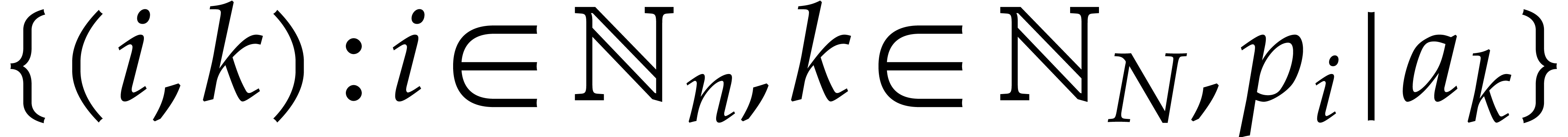 can be computed in
quasi-linear time using the following algorithm named
can be computed in
quasi-linear time using the following algorithm named  .
.
Algorithm divisors
Input: non empty subsets 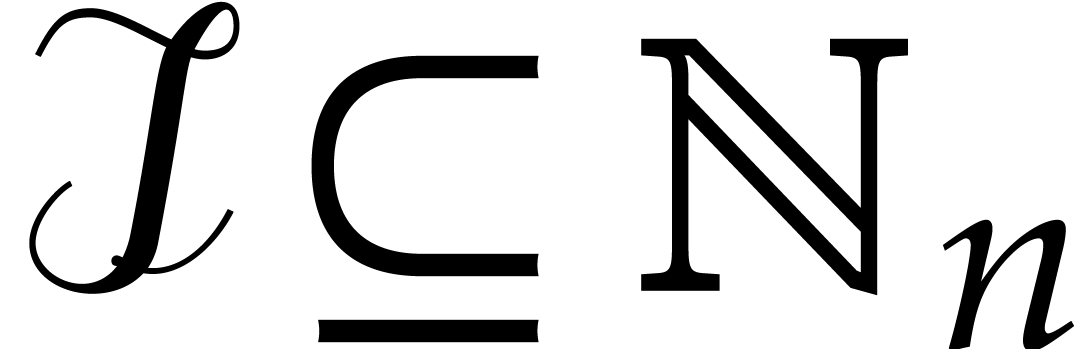 and
and
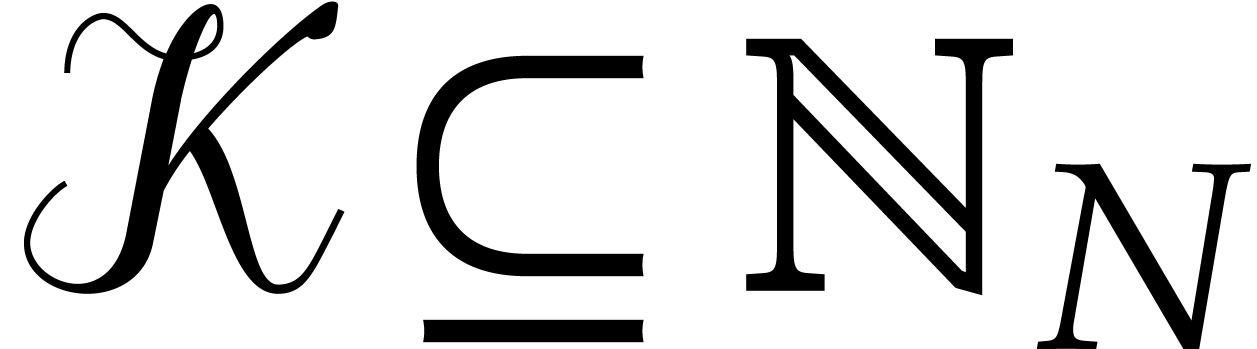 .
.
Output: the set 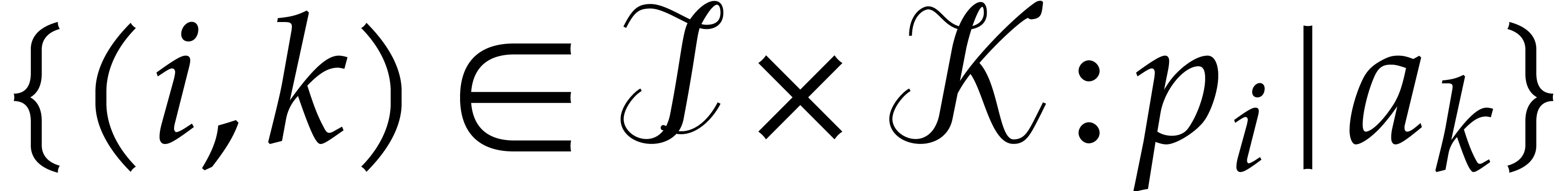 .
.
If  , then return
, then return
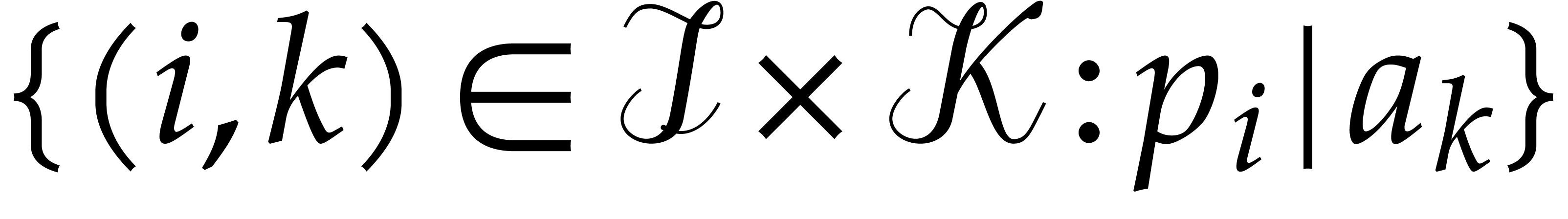 .
.
Let 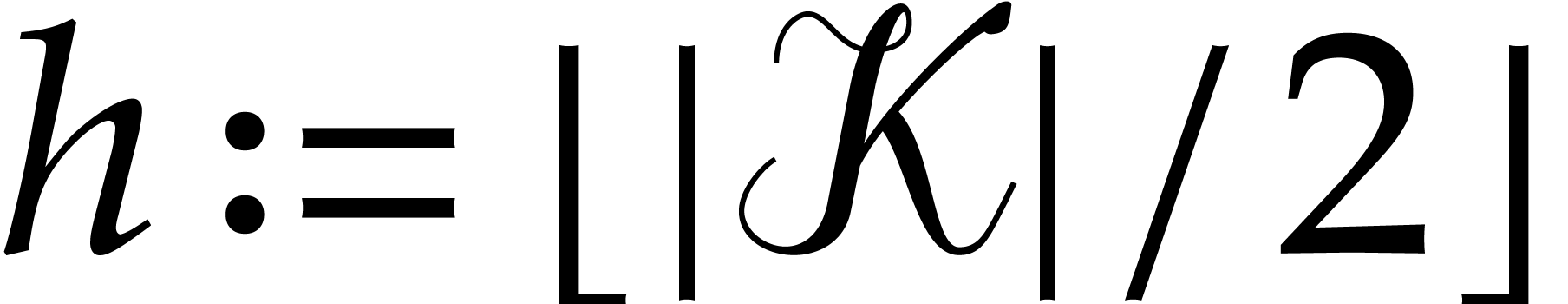 , let
, let 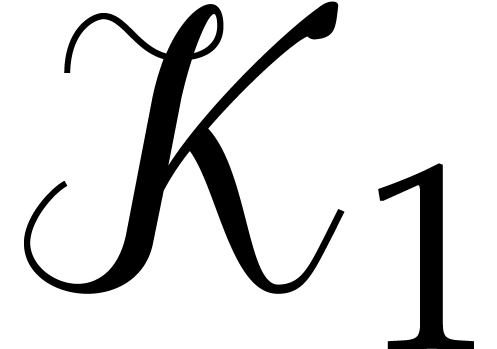 be a subset of
be a subset of  of
cardinality
of
cardinality 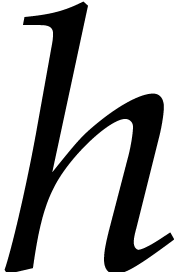 , and let
, and let
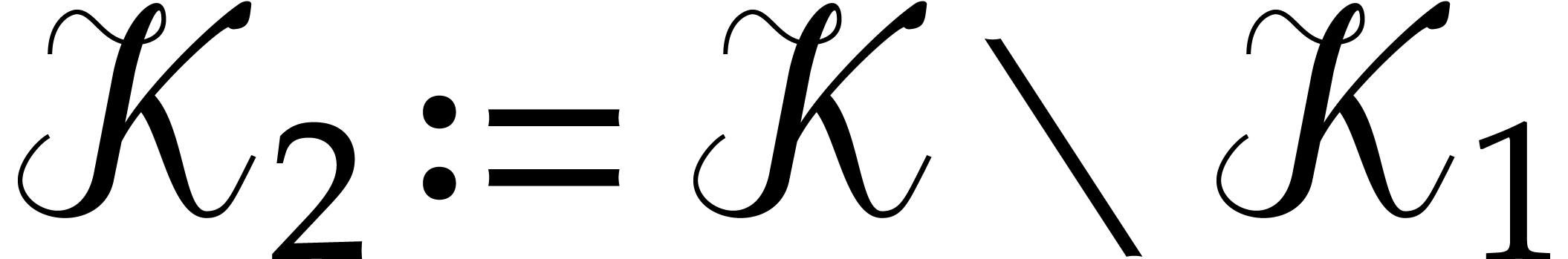 .
.
Compute 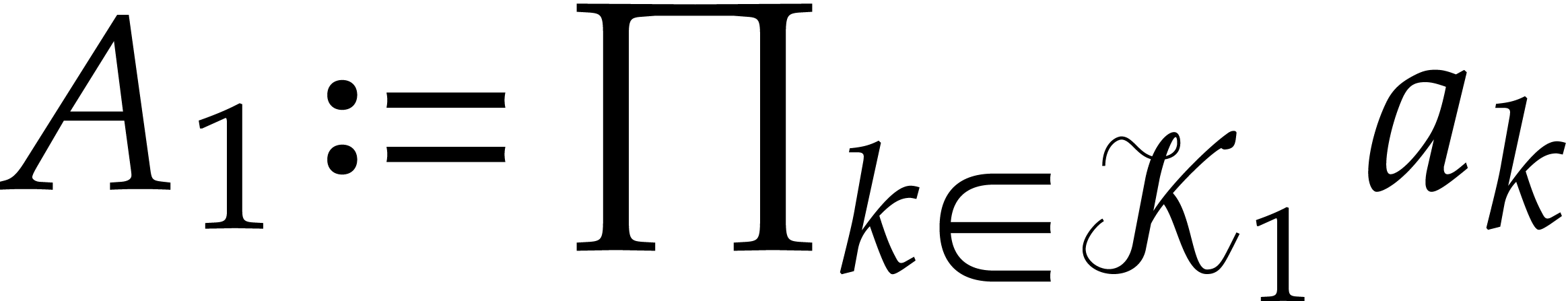 and
and 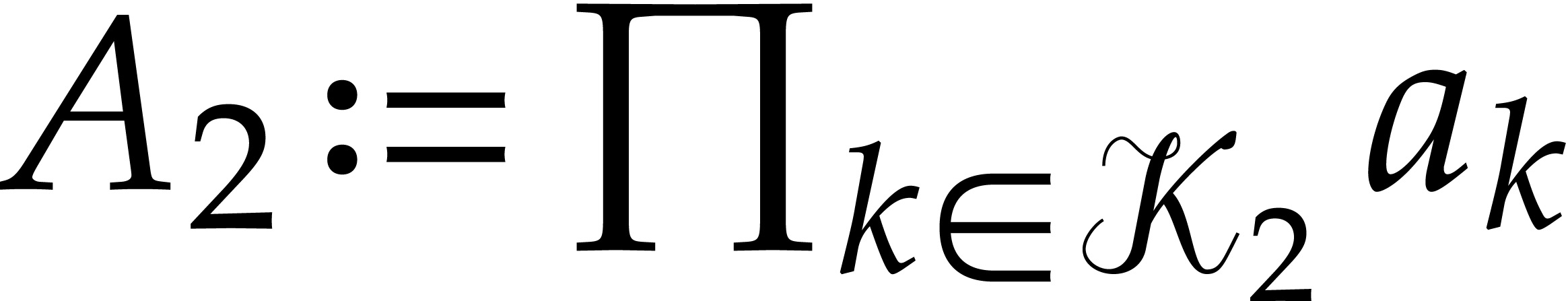 .
.
Compute 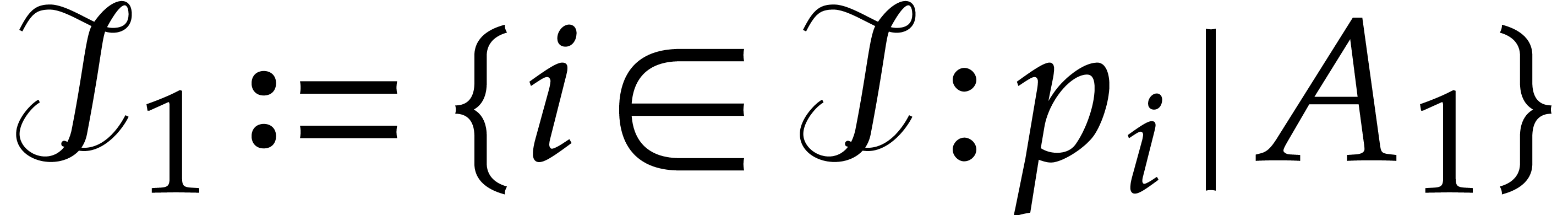 and
and 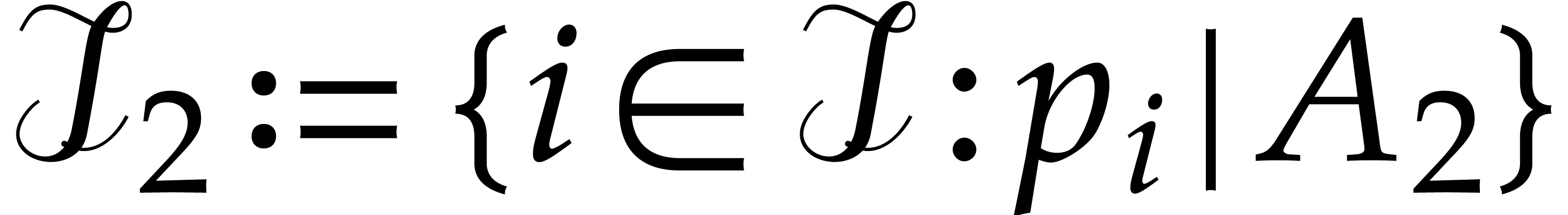 .
.
Return  .
.
Proof. Let  and
and 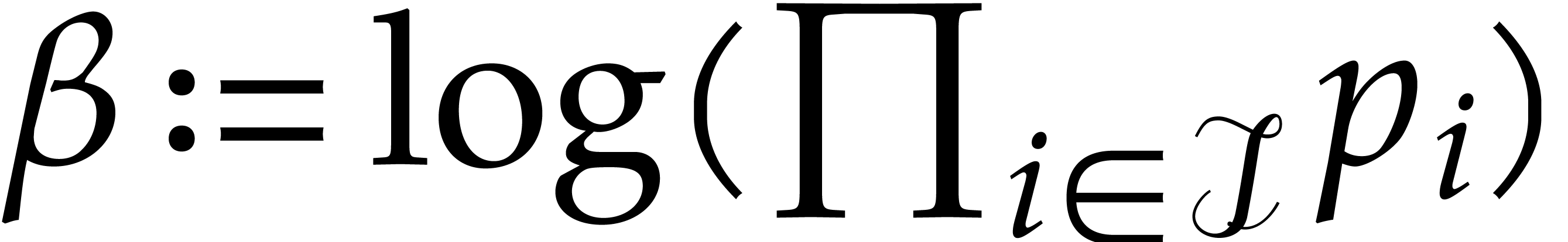 . Step 1 costs
. Step 1 costs 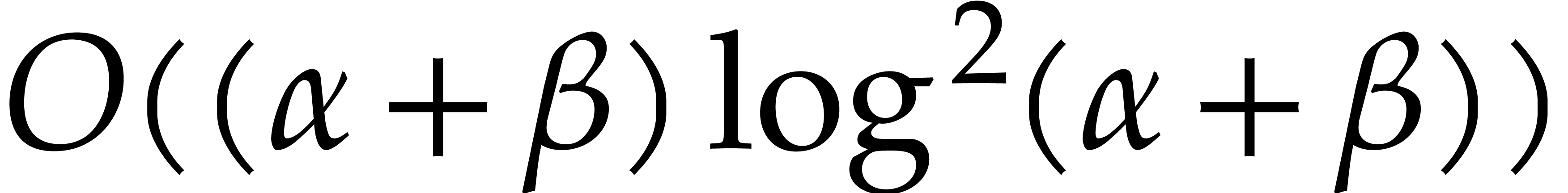 by using fast multi-remaindering [15, Chapter 10]. Using
fast sub-product trees [15, Chapter 10], step 3 takes
by using fast multi-remaindering [15, Chapter 10]. Using
fast sub-product trees [15, Chapter 10], step 3 takes 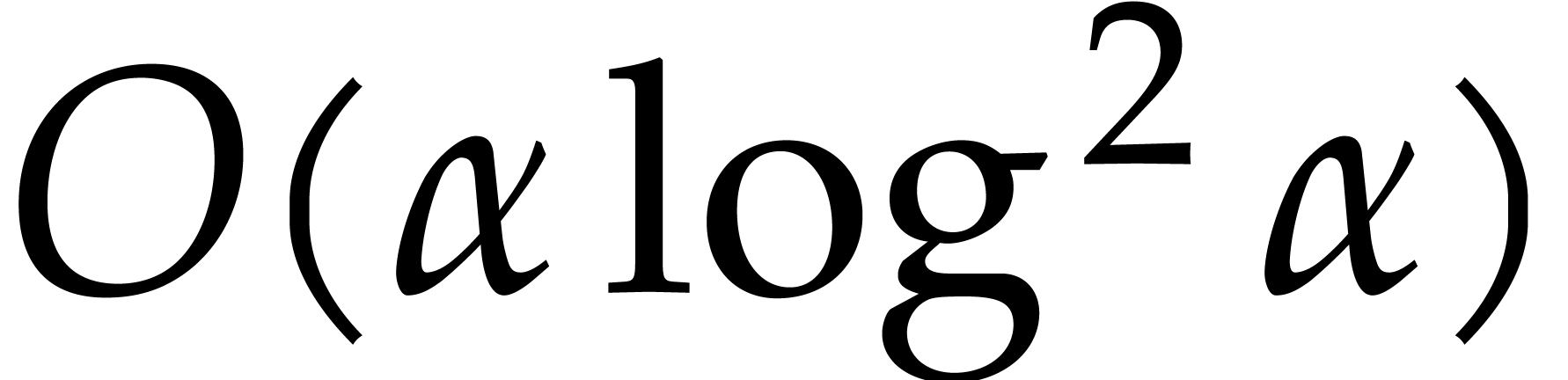 . By means of fast
multi-remaindering again, step 4 takes
operations.
. By means of fast
multi-remaindering again, step 4 takes
operations.
Since the 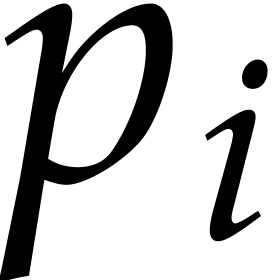 are distinct prime numbers, when
entering step 5 we have
are distinct prime numbers, when
entering step 5 we have
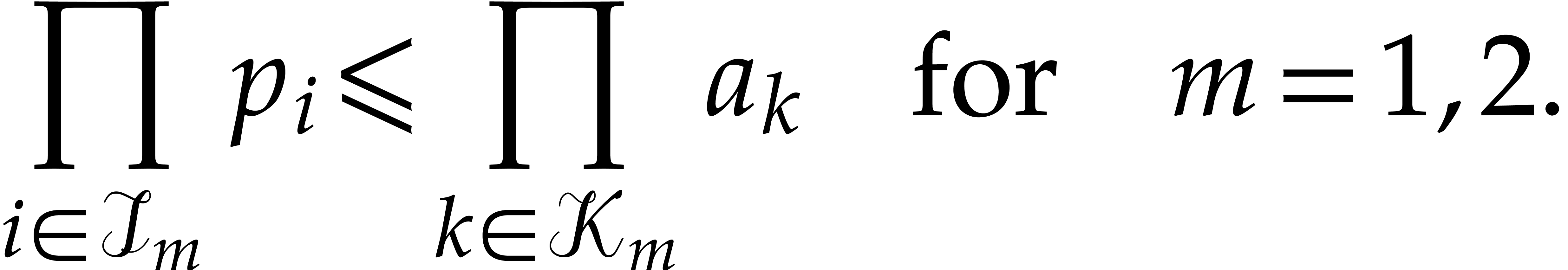
Let 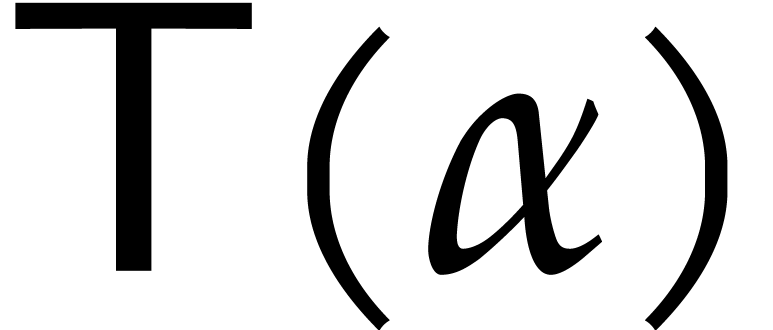 denote the cost of the inner recursive calls
occurring during the execution of the algorithm. Inside the recursive
calls,
denote the cost of the inner recursive calls
occurring during the execution of the algorithm. Inside the recursive
calls,  holds, so we have shown that
holds, so we have shown that
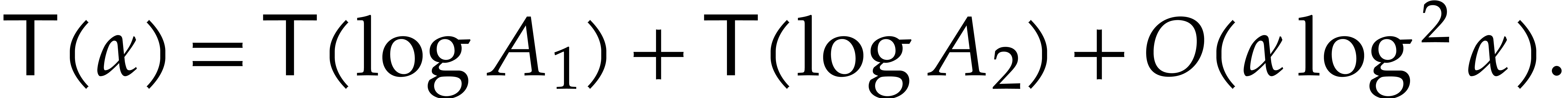
Unrolling this inequality and taking into account that the depth of the
recursion is 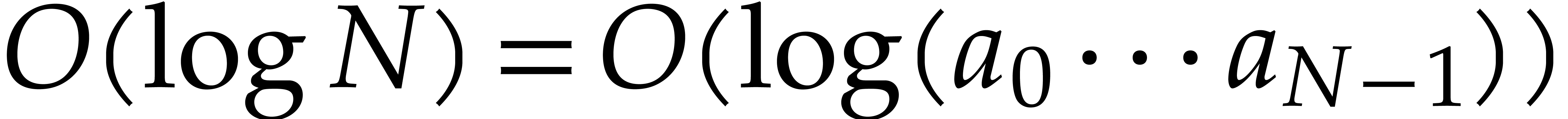 , we deduce that
, we deduce that
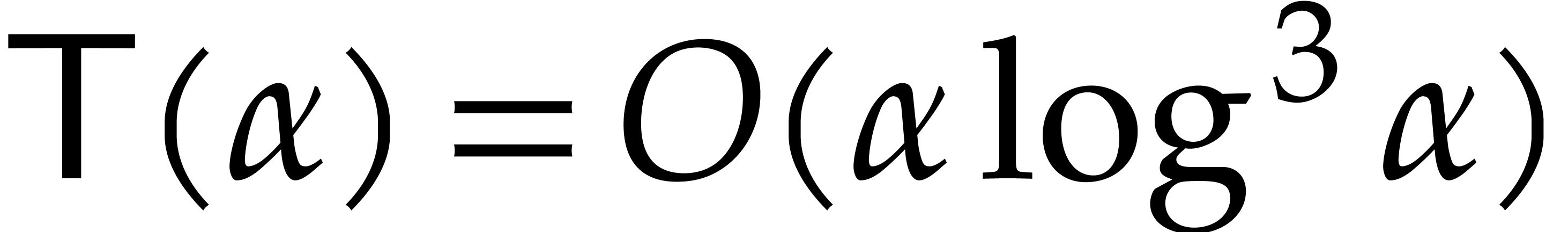 . Finally, the total cost of
the algorithm is obtained by adding the cost of the top-level call,
which is
. Finally, the total cost of
the algorithm is obtained by adding the cost of the top-level call,
which is
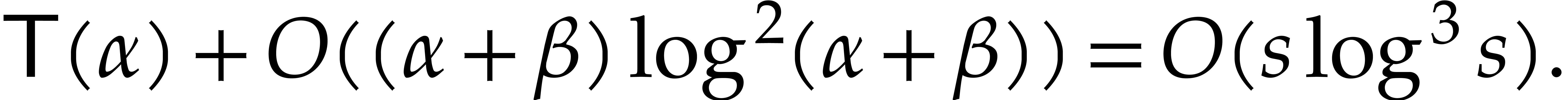
Note that does not necessarily hold for this
top-level call.
Consider a sparse polynomial  that we wish to
interpolate. In the next section, we will describe a method that allows
us to efficiently compute most of the exponents
that we wish to
interpolate. In the next section, we will describe a method that allows
us to efficiently compute most of the exponents 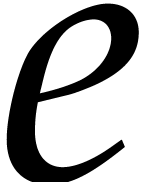 in an encoded form
in an encoded form 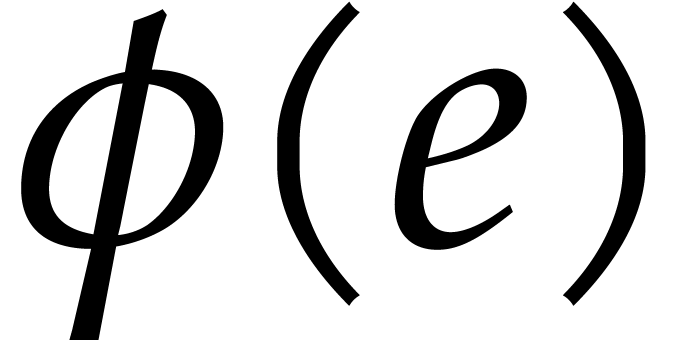 . The
simplest codes are of the form
. The
simplest codes are of the form
 |
(3.1) |
When 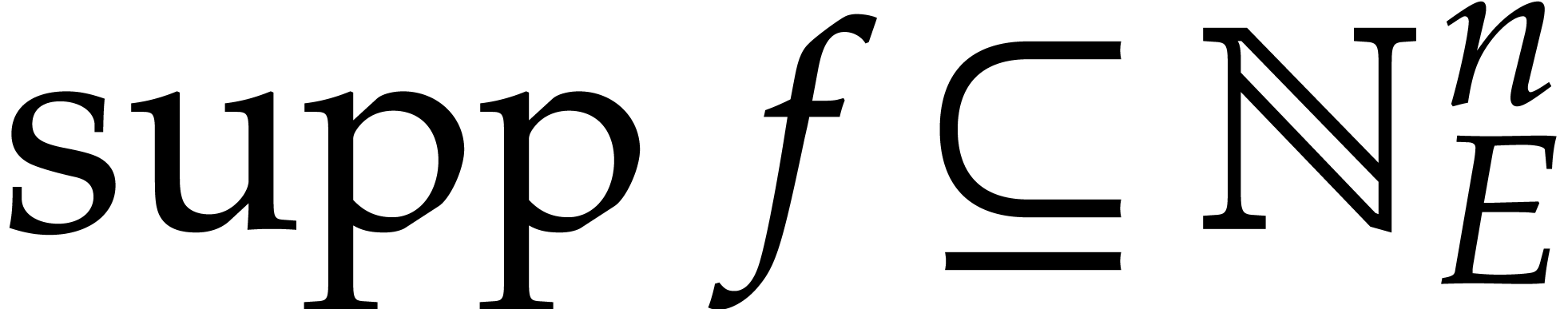 , the most common such
encoding is the Kronecker encoding, with
, the most common such
encoding is the Kronecker encoding, with 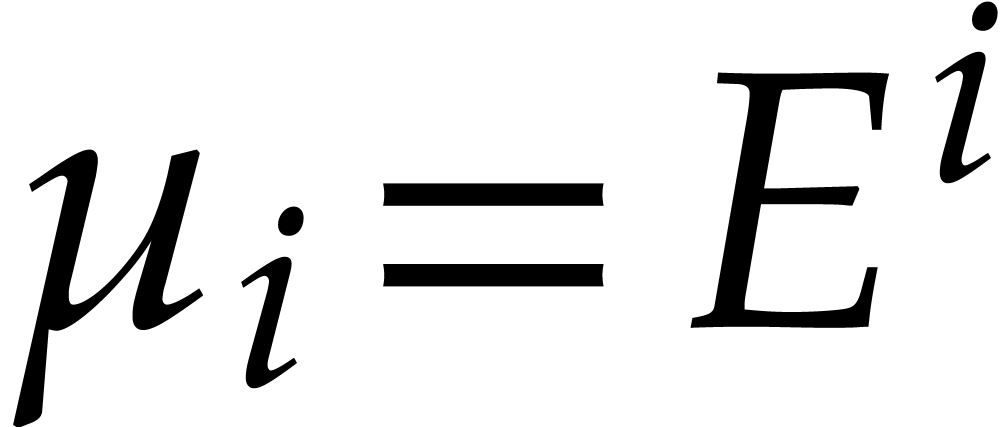 for all
for all  . However, this
encoding may incur large bit-size
. However, this
encoding may incur large bit-size  with respect
to the bit-size of .
with respect
to the bit-size of .
The aim of this section is to introduce more compact codes . These codes will be
“probabilistic” in the sense that we will only be able to
recover from with high
probability, under suitable assumptions on .
Moreover, the recovery algorithm is only efficient if we wish to
simultaneously “bulk recover”
exponents from their codes.
Throughout this section, the number of variables 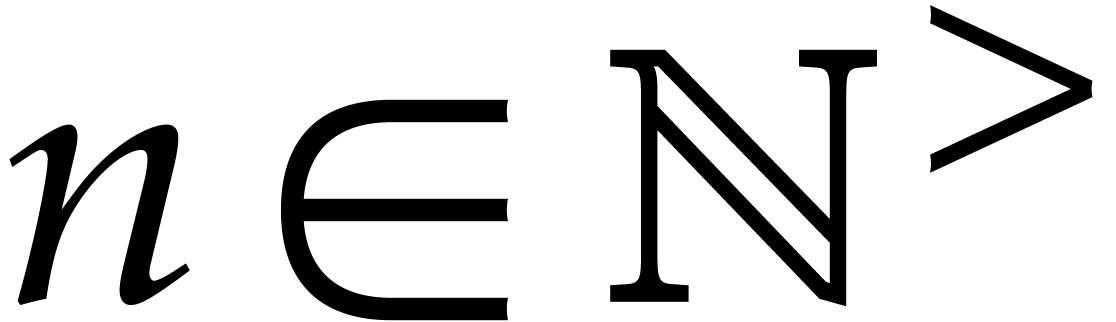 and the target number of exponents
and the target number of exponents 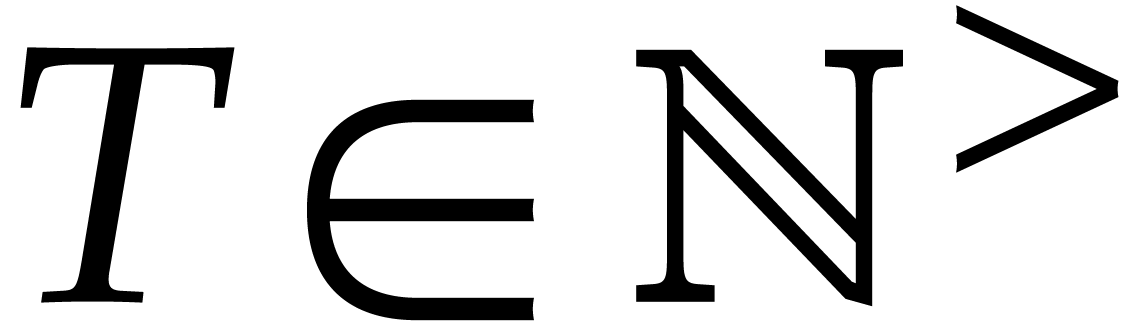 are assumed
to be given. We allow exponents to be vectors of arbitrary integers in
are assumed
to be given. We allow exponents to be vectors of arbitrary integers in
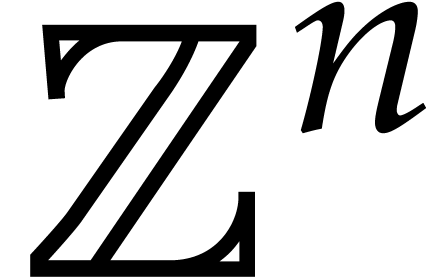 . Actual computations on
exponents will be done modulo
. Actual computations on
exponents will be done modulo 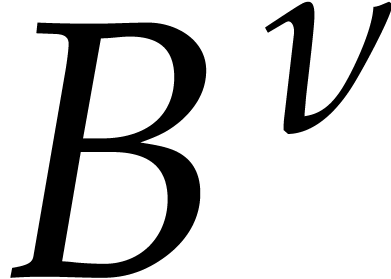 for a fixed odd
base
for a fixed odd
base  and a flexible -adic precision
and a flexible -adic precision  .
We also fix a constant
.
We also fix a constant  such that
such that
 |
(3.2) |
and we note that this assumption implies
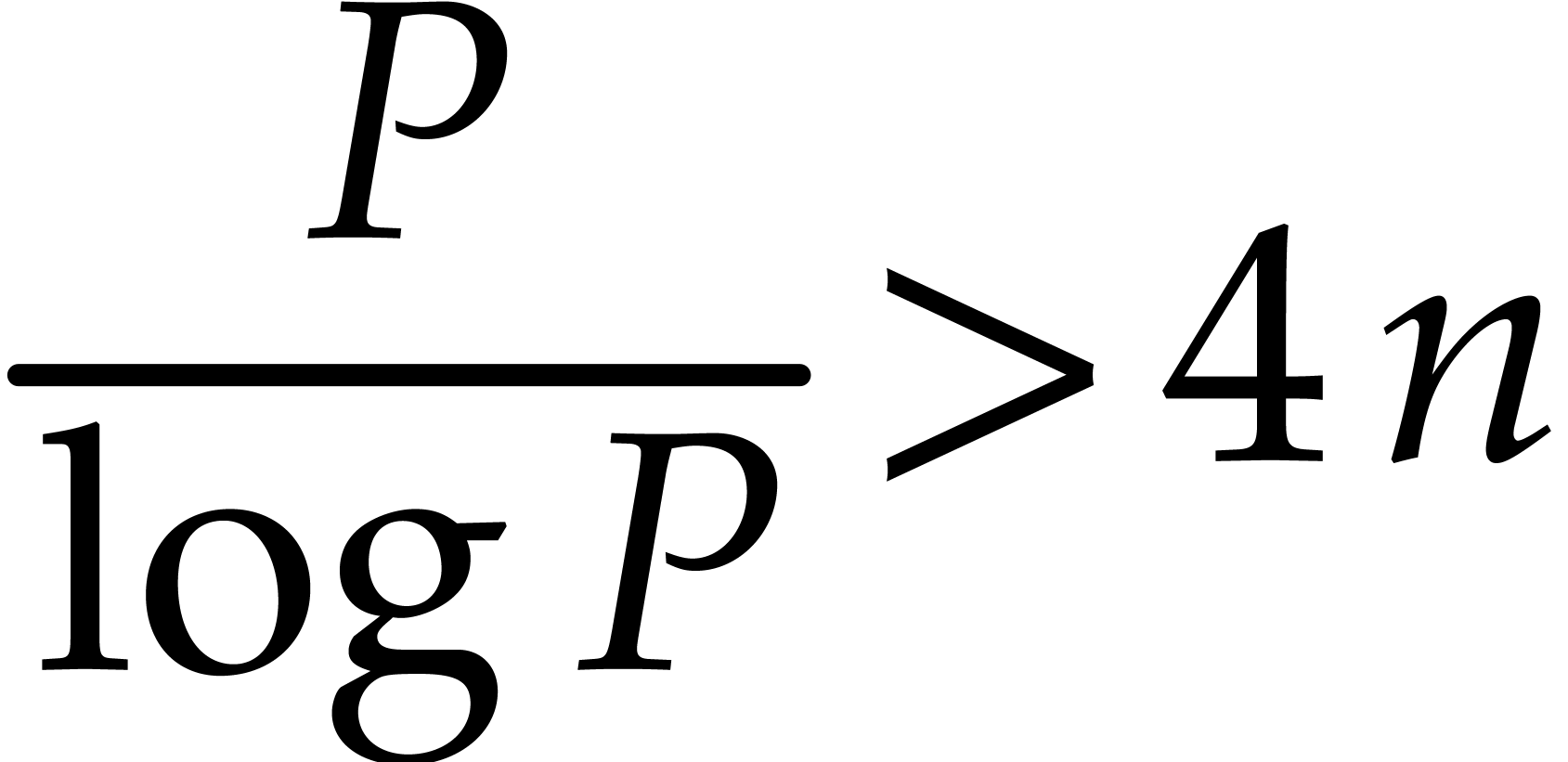 |
(3.3) |
and
 |
(3.4) |
We finally assume  to be a parameter that will be
specified in section 4. The exponent encoding will depend
on one more parameter
to be a parameter that will be
specified in section 4. The exponent encoding will depend
on one more parameter
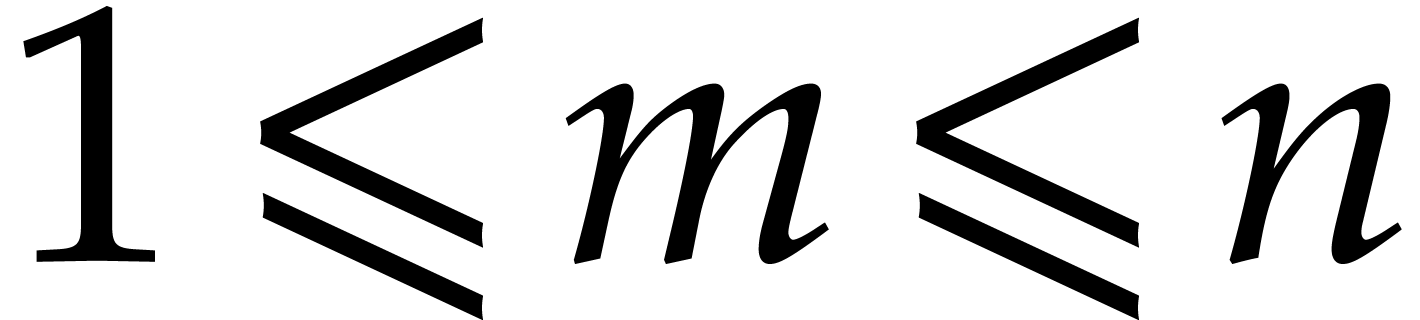
that will be fixed in section 3.2 and flexible in section 3.3. We define
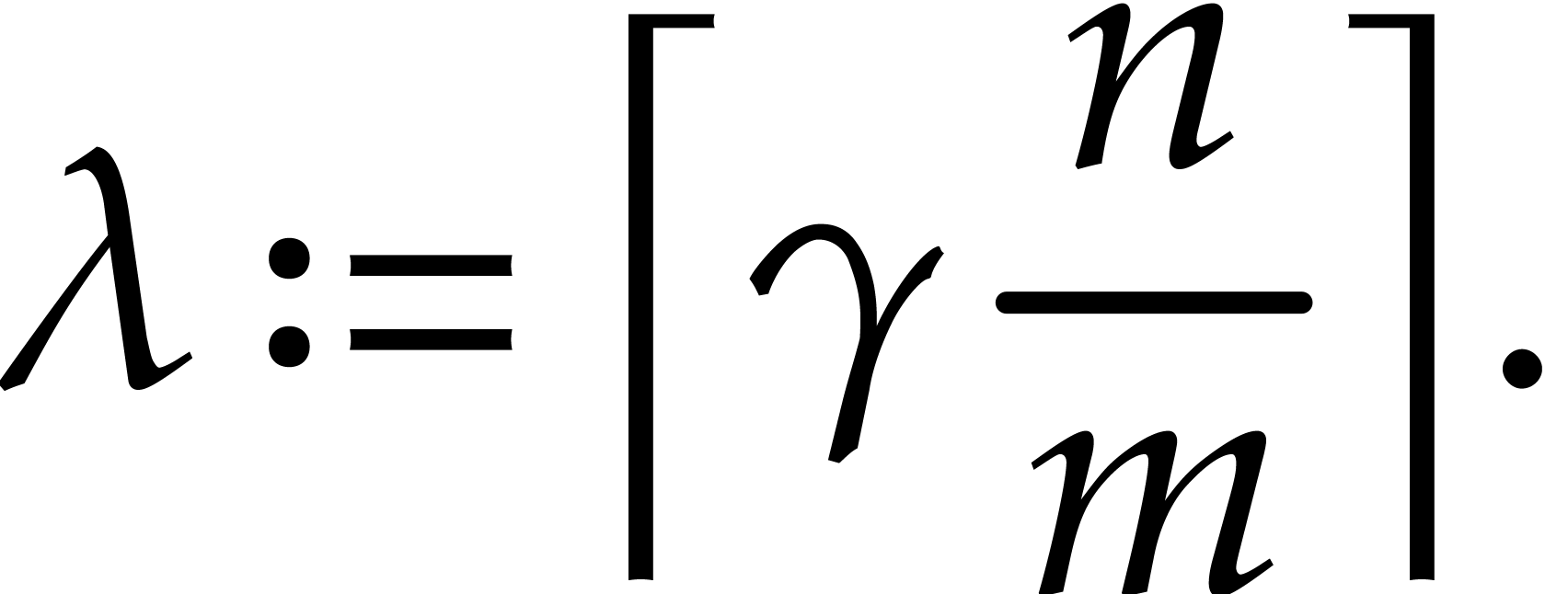
Our encoding also depends on the following random parameters:
For each 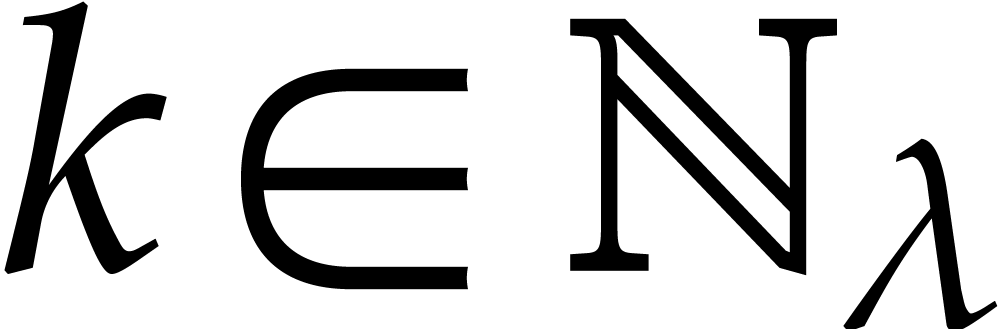 , let
, let 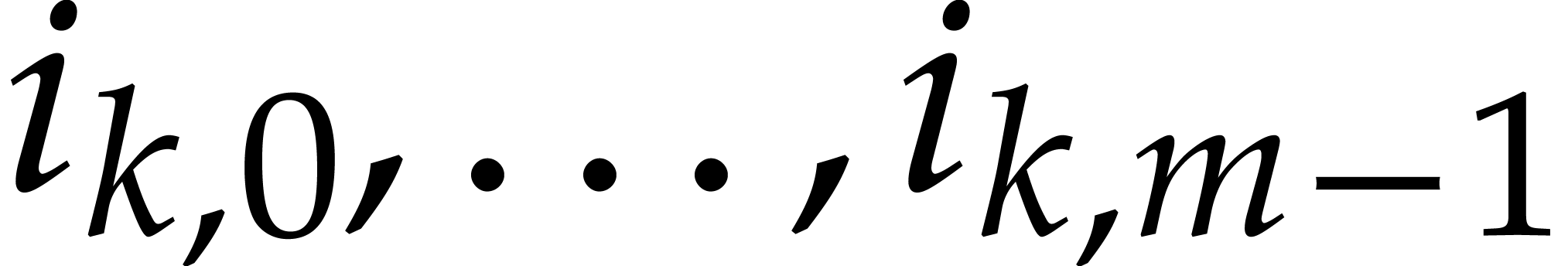 be random elements in
be random elements in 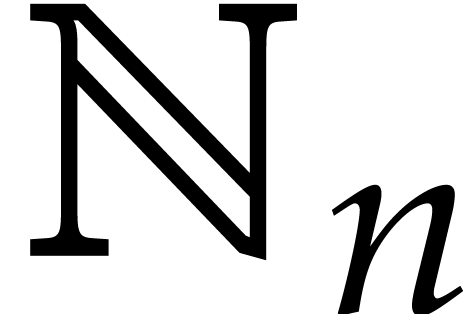 and
and
 .
.
Let be pairwise distinct random prime
numbers in the interval ;
such primes do exist thanks to Lemma 2.6 and
Now consider an exponent 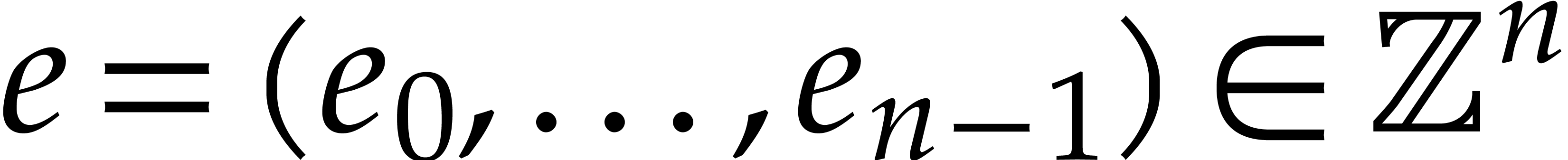 . We
encode as
. We
encode as
We will sometimes write 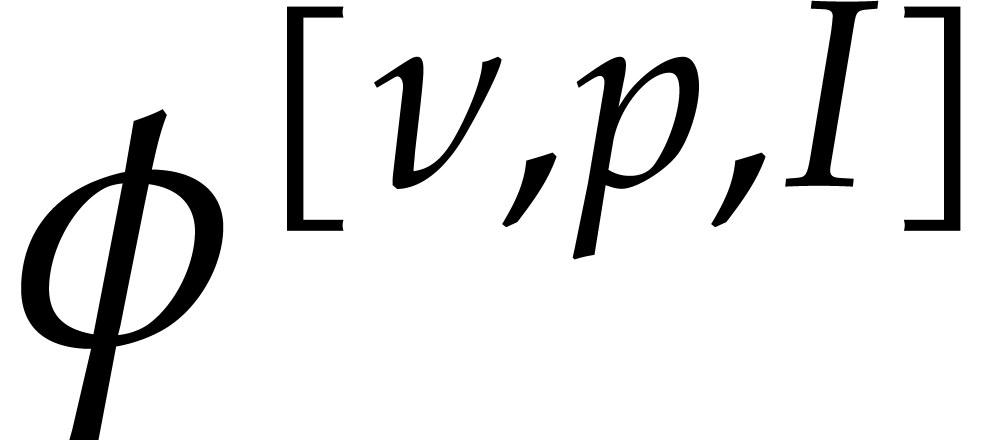 and
and 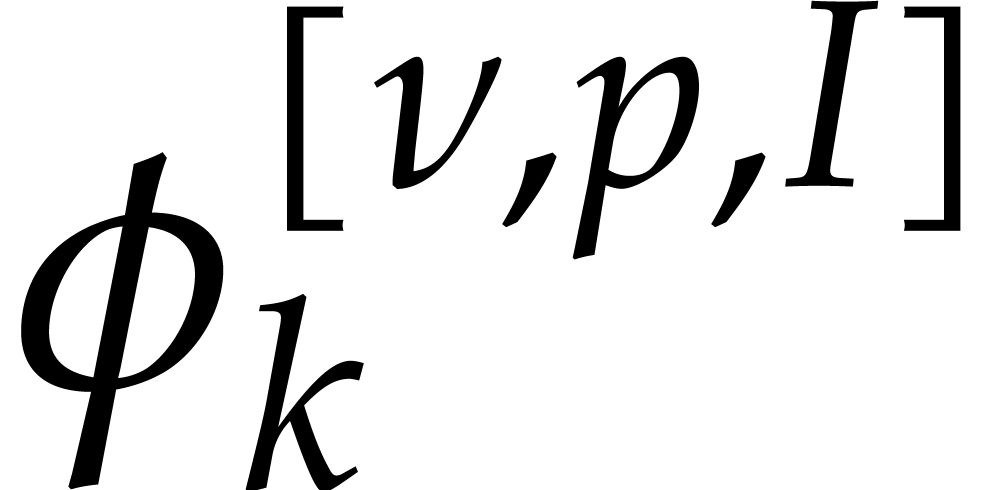 instead of
instead of  and
and  in order
to make the dependence on ,
in order
to make the dependence on ,
 and
and  explicit.
explicit.
Example 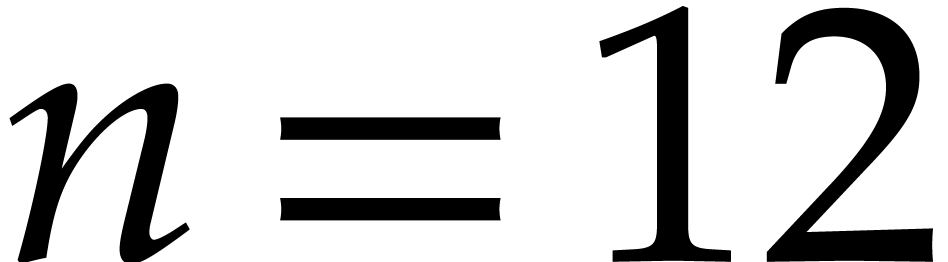 ,
, 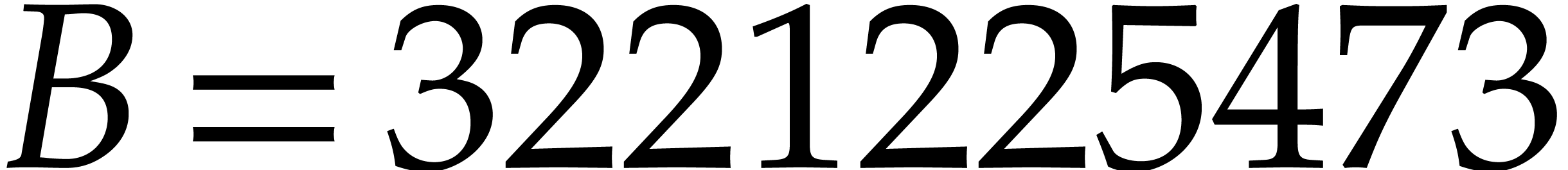 ,
, 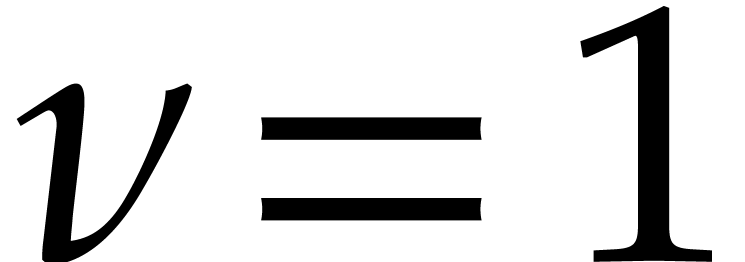 ,
,
 ,
, 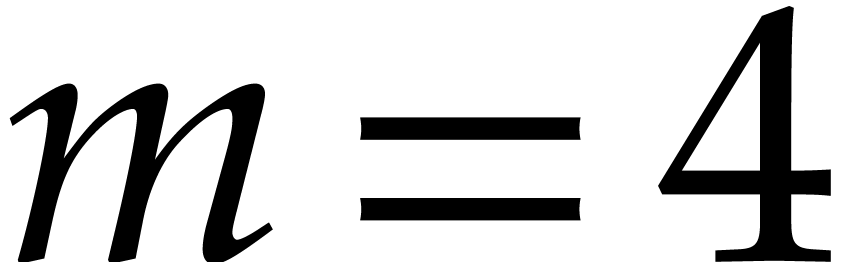 , and
, and  .
Then
.
Then  and possible random choices for and
and possible random choices for and  are
are
Now consider the sparse exponent vectors
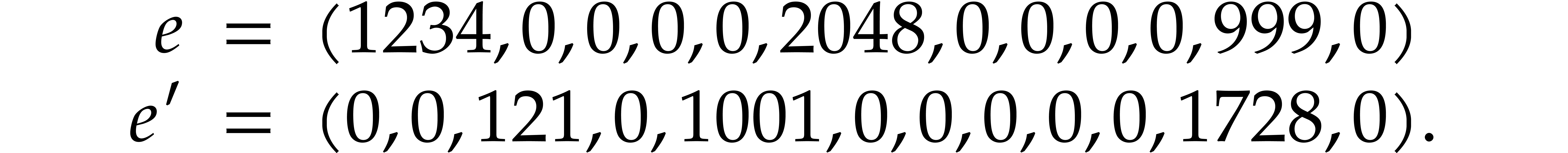
Their encodings are given by
Given an exponent of , our first aim is to determine the individual
exponents of small size. More precisely,
assuming that
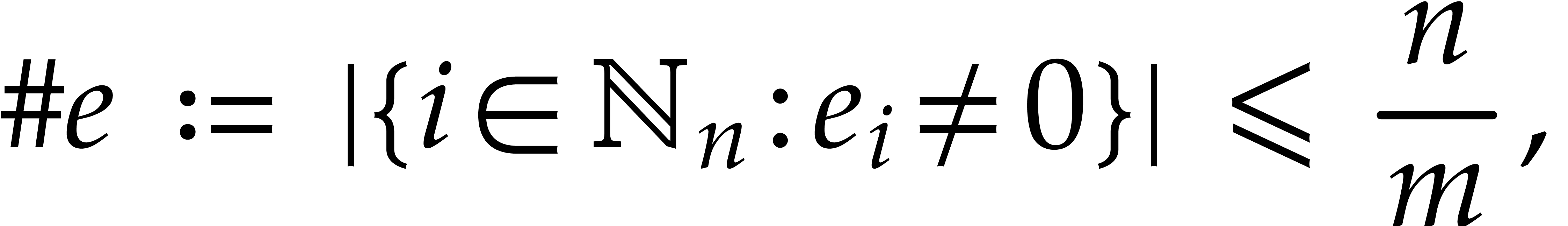
we wish to determine all with 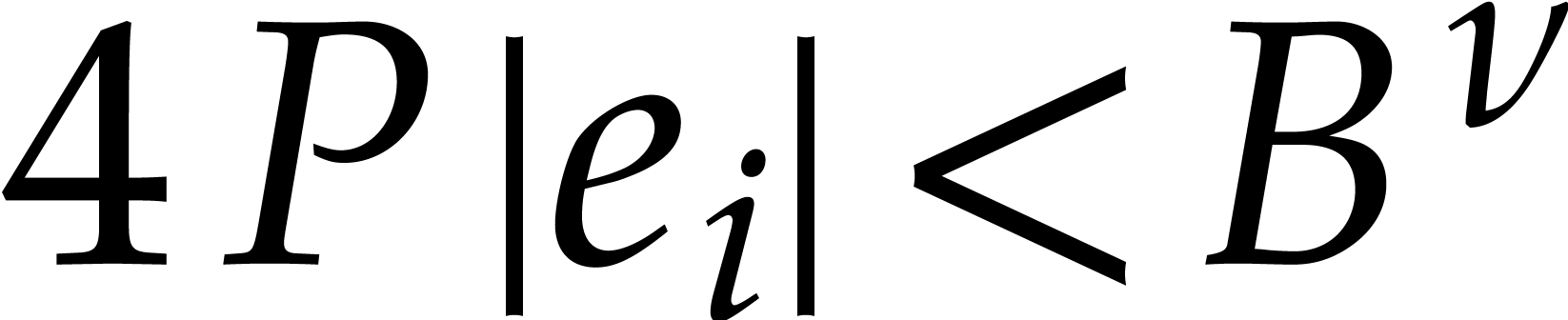 .
.
We say that is transparent if for each
with ,
there exists a such that 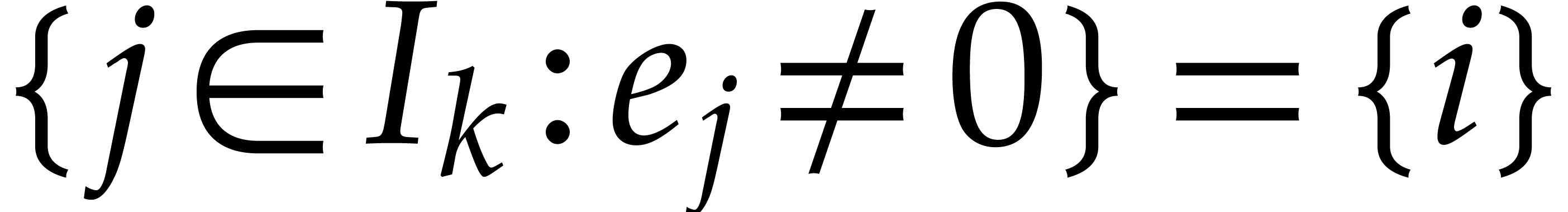 . This property does only depend on the random
choices of the
. This property does only depend on the random
choices of the  .
.
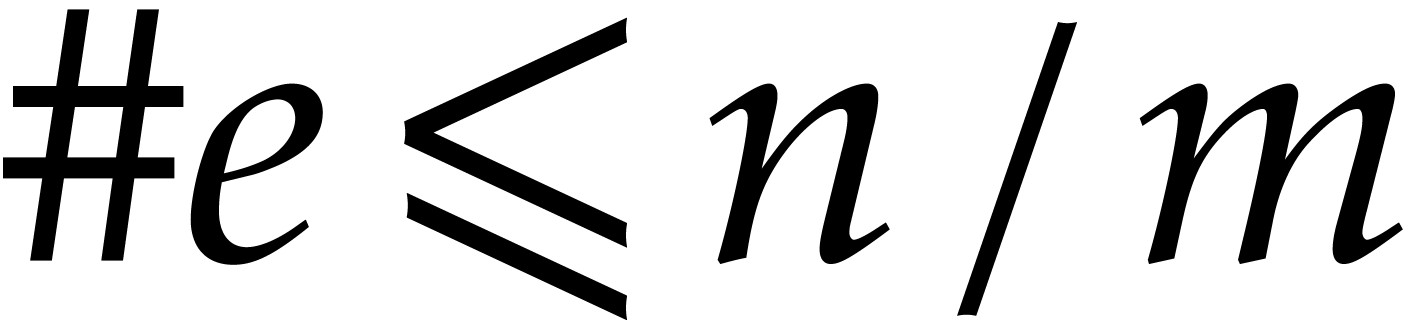 . Then,
for random choices of
. Then,
for random choices of  , the
probability that is transparent is at least
, the
probability that is transparent is at least
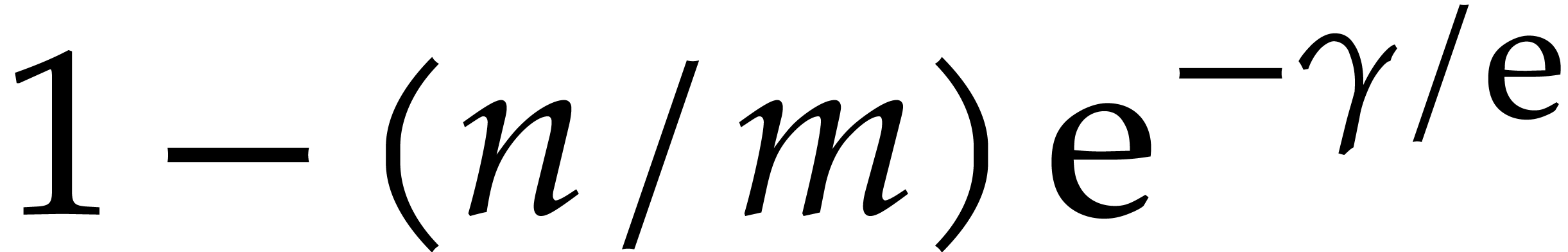 .
.
Proof. Let 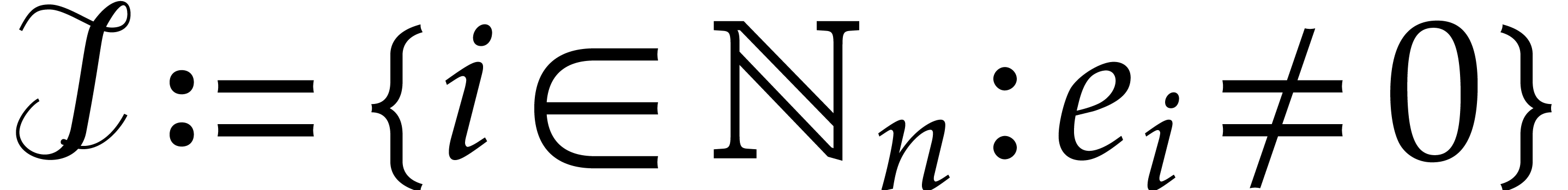 and
and 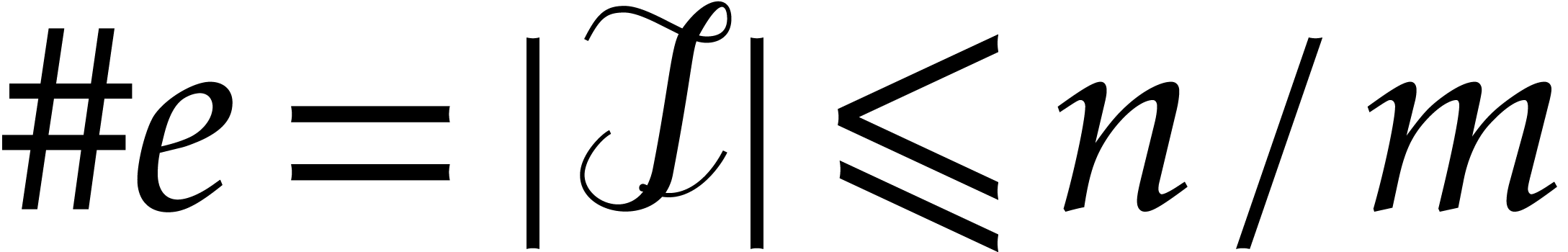 . Given and
. Given and
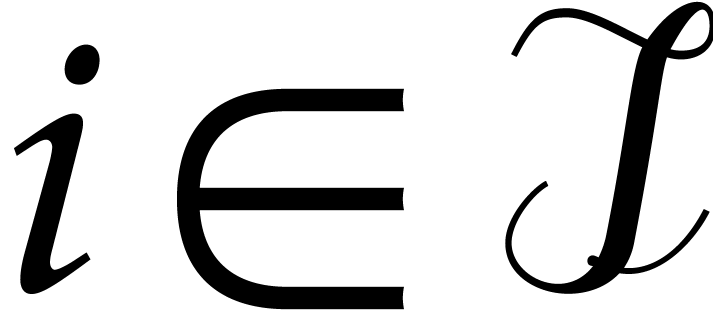 , the probability that
, the probability that 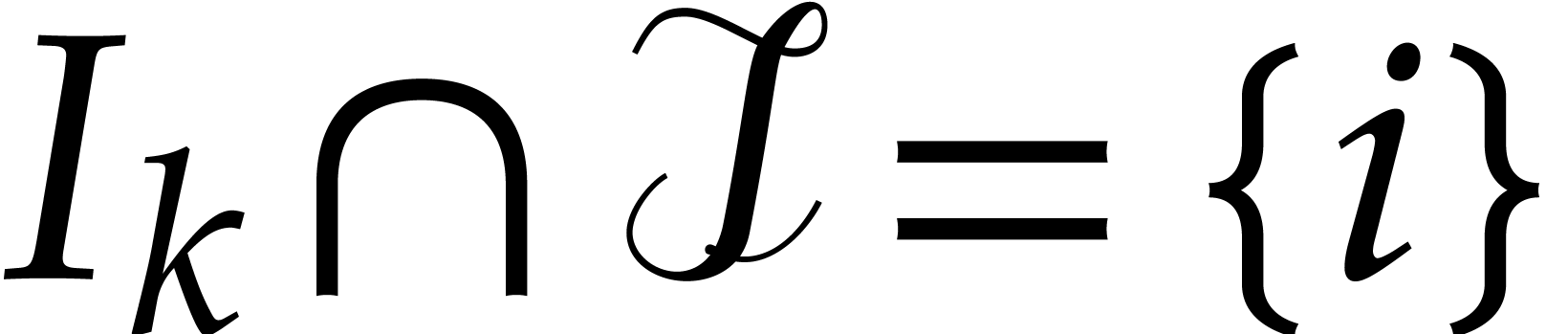 is
is
The probability that for some
is therefore at least
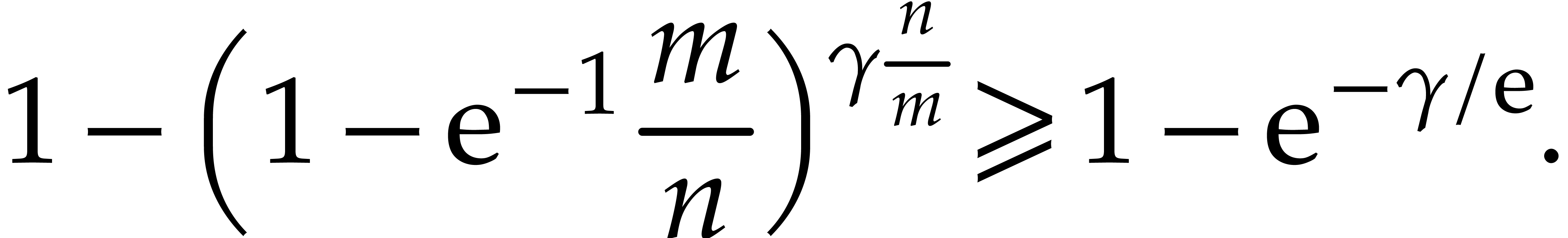
We conclude that the probability that this holds for all is at least .
Example is transparent,
by taking  for
for 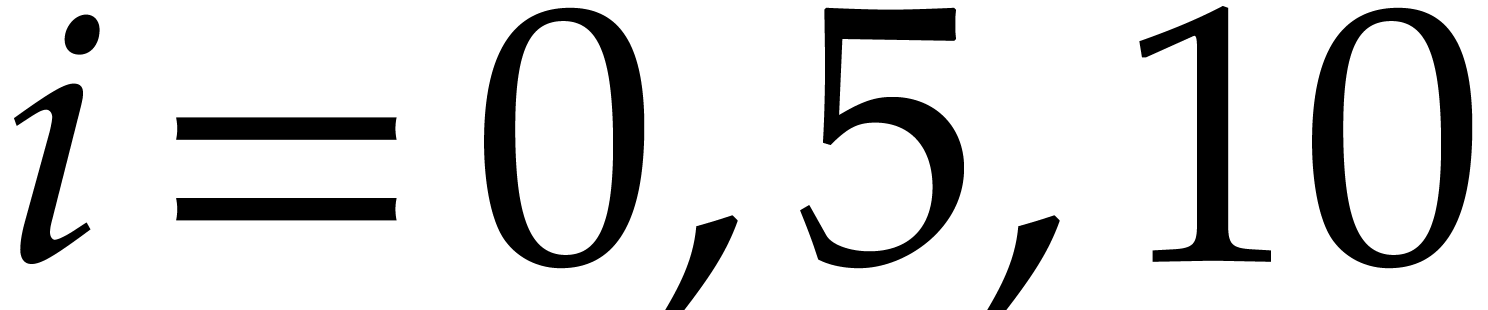 .
However,
.
However, 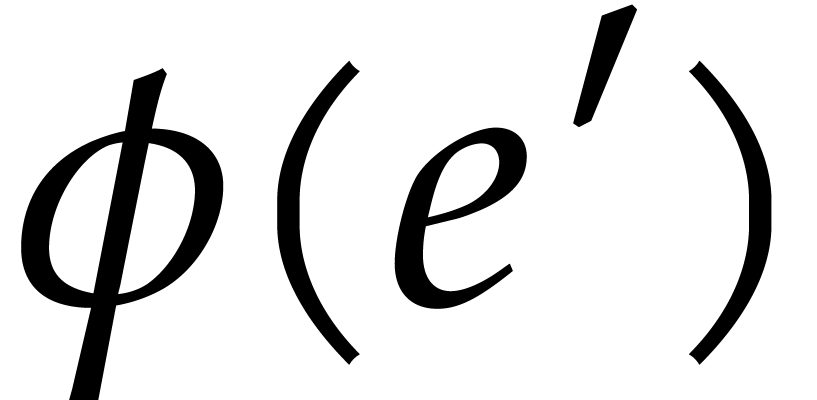 is not transparent, since no suitable
index can be found for
is not transparent, since no suitable
index can be found for 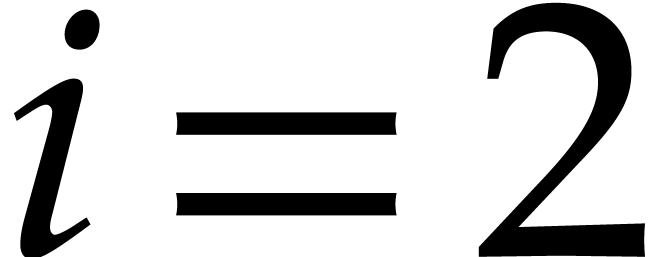 . For our parameters, the probability from Lemma 3.2 becomes
. For our parameters, the probability from Lemma 3.2 becomes  . For
random with
. For
random with 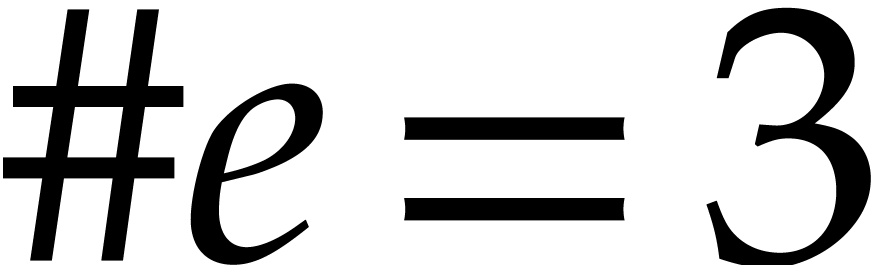 ,
it turns out that this bound is a bit pessimistic.
,
it turns out that this bound is a bit pessimistic.
We say that is faithful if for every
and such that and 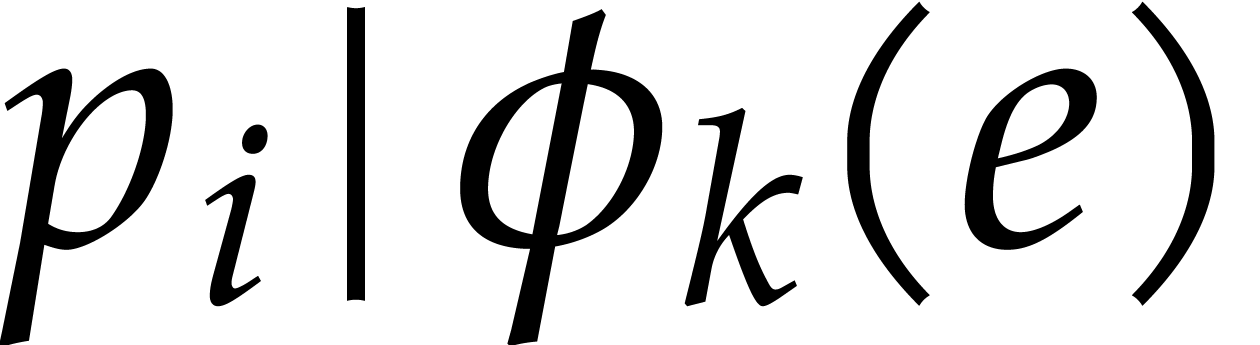 , we have
, we have
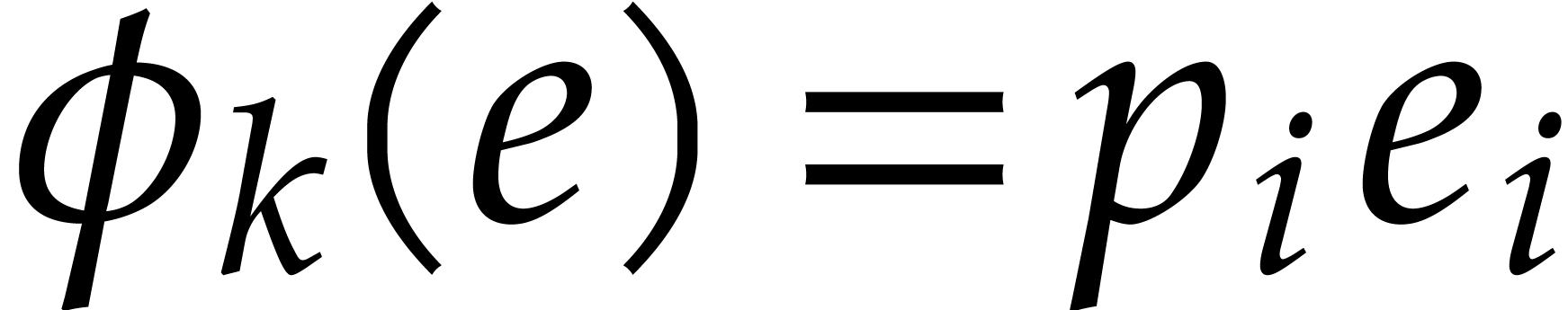 .
.
Proof. Let  be the set of
all primes strictly between
be the set of
all primes strictly between  and
and  . Let
. Let  be the set of all
be the set of all
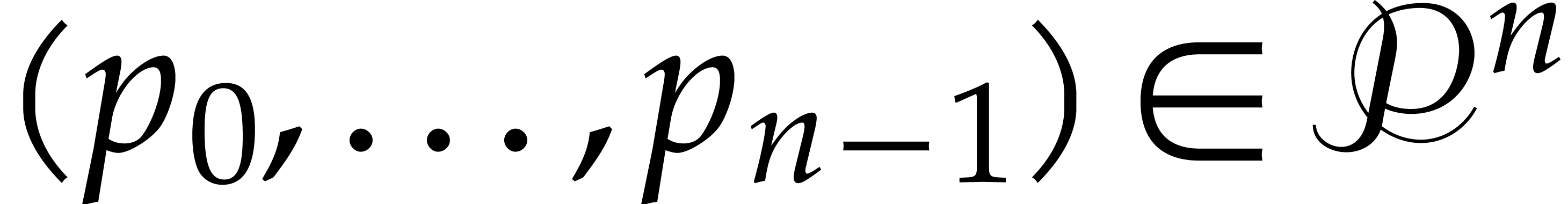 such that are pairwise
distinct. Let
such that are pairwise
distinct. Let  be the subset of
of all choices of for which
is not faithful.
be the subset of
of all choices of for which
is not faithful.
Consider , , and 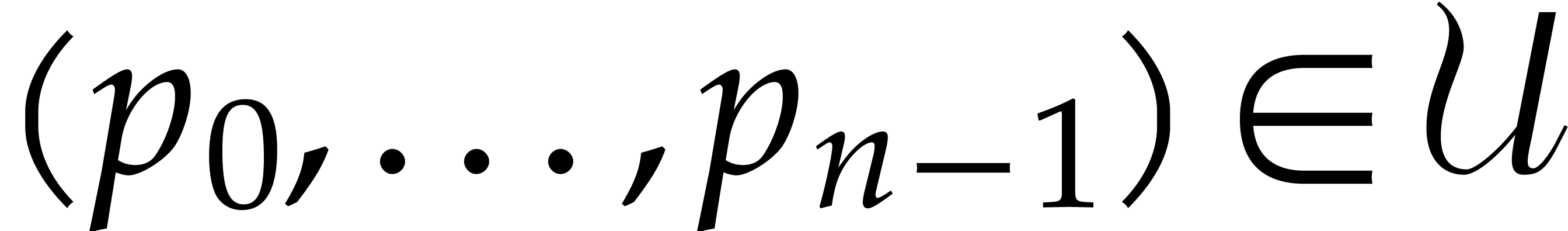 be such that
, and
be such that
, and
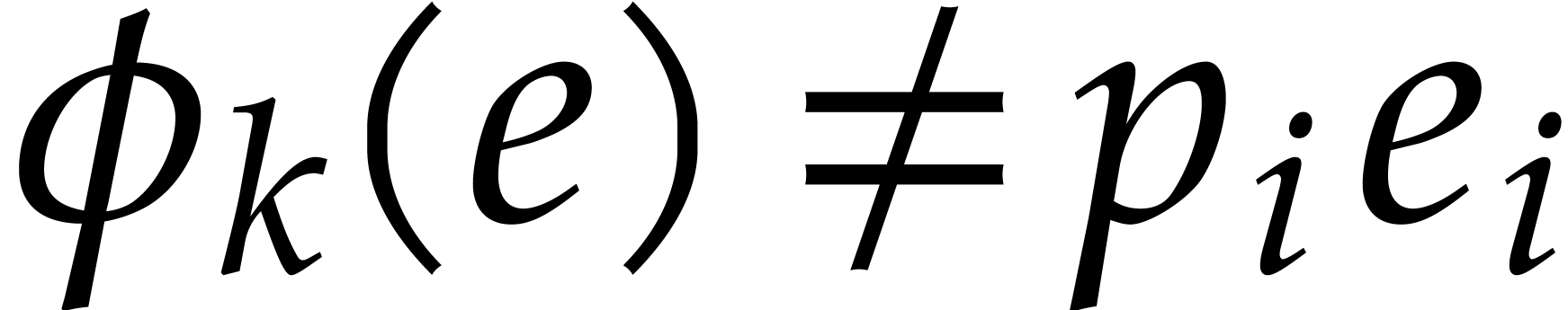 . Let
. Let 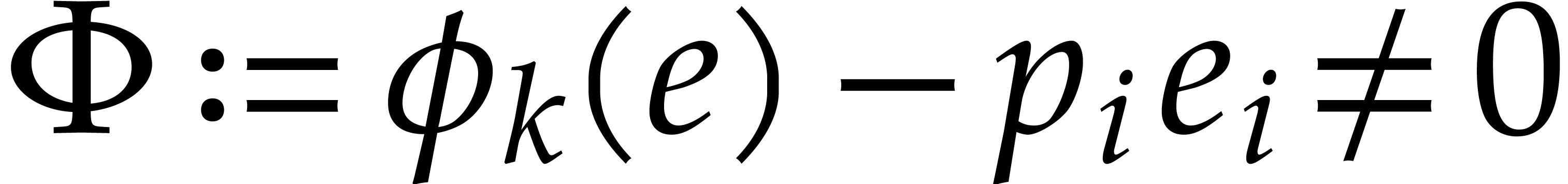 . For each
. For each 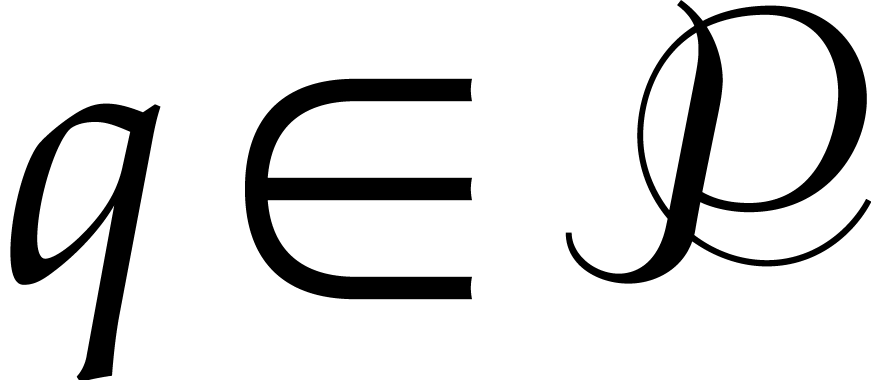 ,
let
,
let
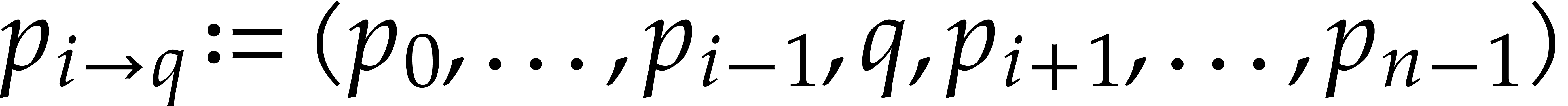
and  , so that
, so that  . For each ,
using , we observe that
. For each ,
using , we observe that
necessarily holds with 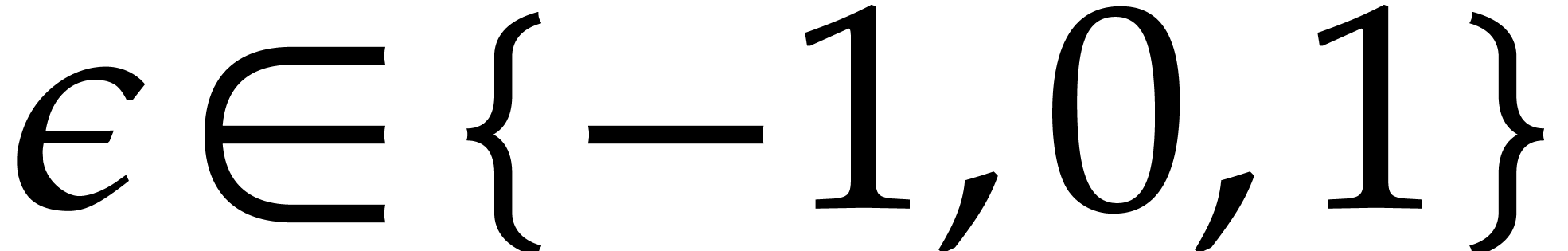 .
.
Now consider the set 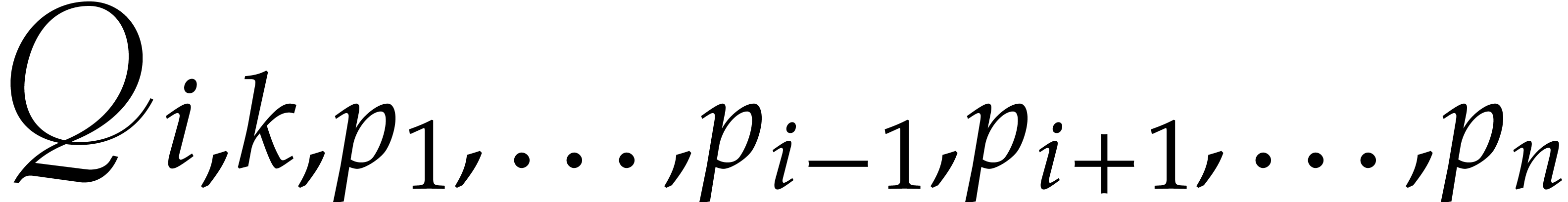 of
such that
of
such that 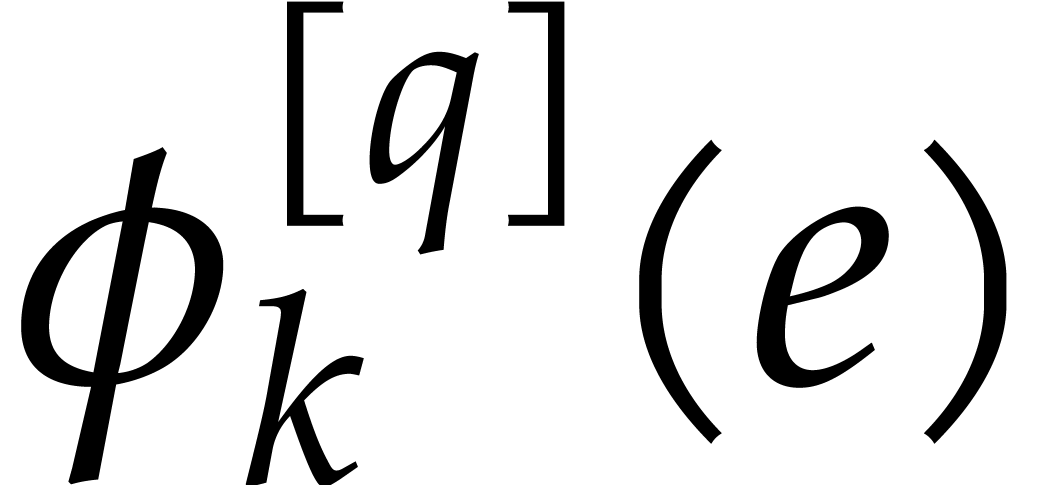 is divisible by . Any such is a divisor of
either
is divisible by . Any such is a divisor of
either 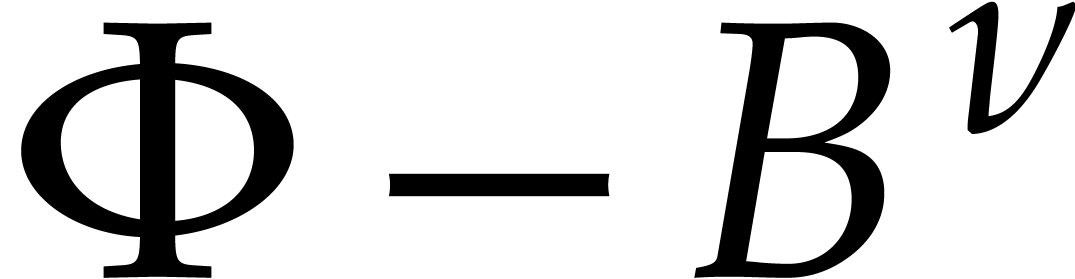 ,
,  , or
, or  .
Since
.
Since  is odd we have
is odd we have
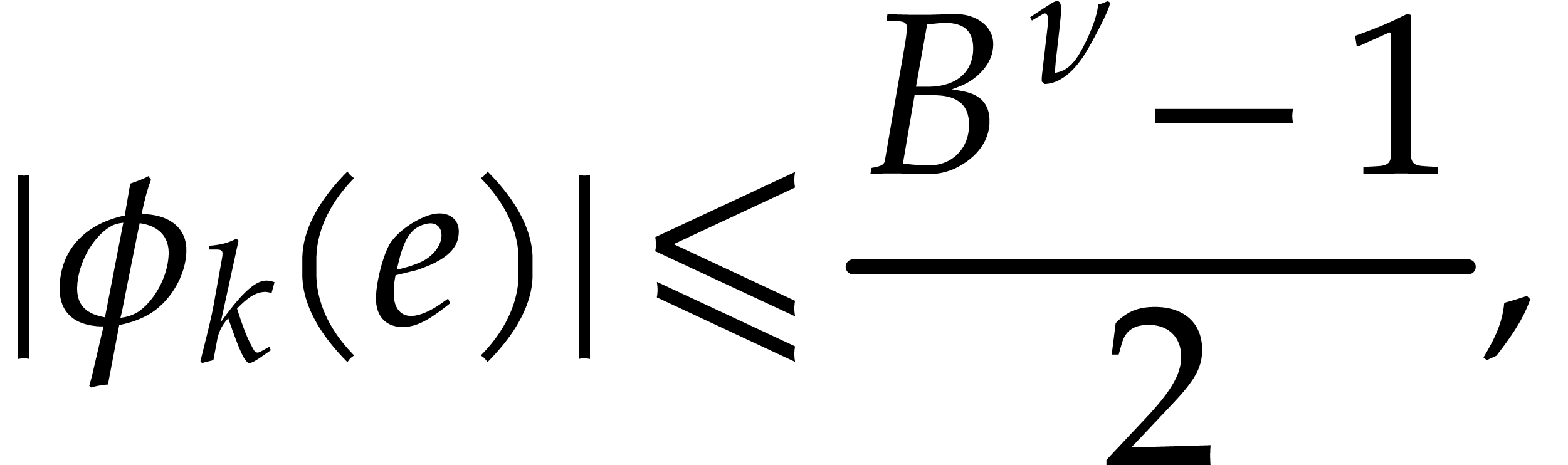
and therefore
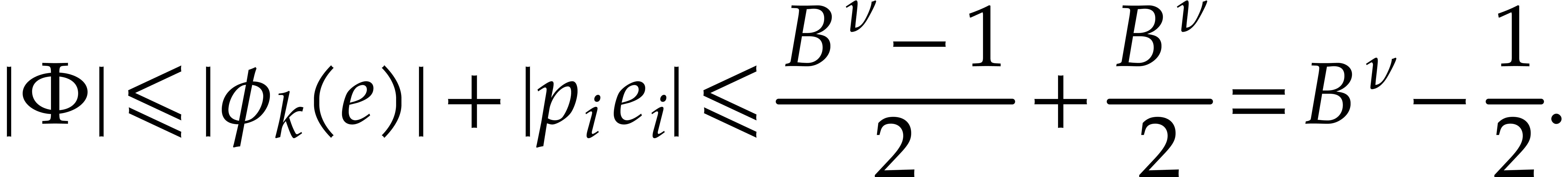
It follows that 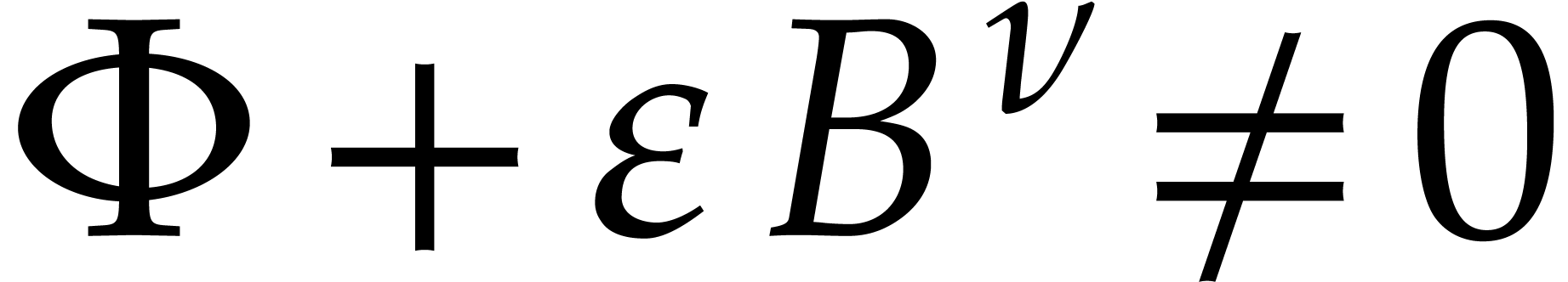 . Hence divides the non-zero integer
. Hence divides the non-zero integer 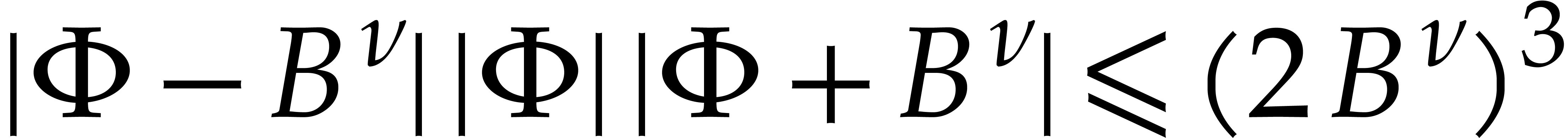 . Since
. Since 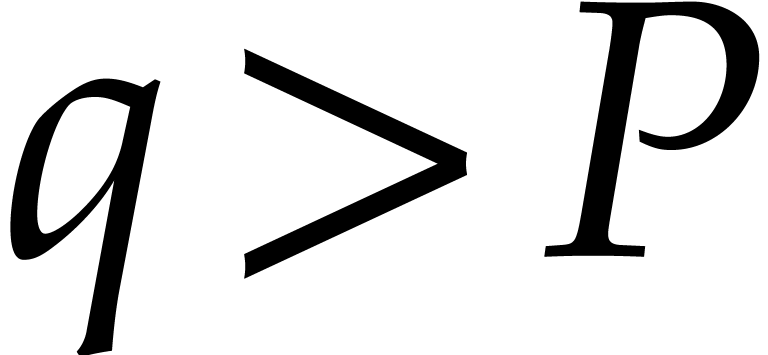 we deduce that
we deduce that
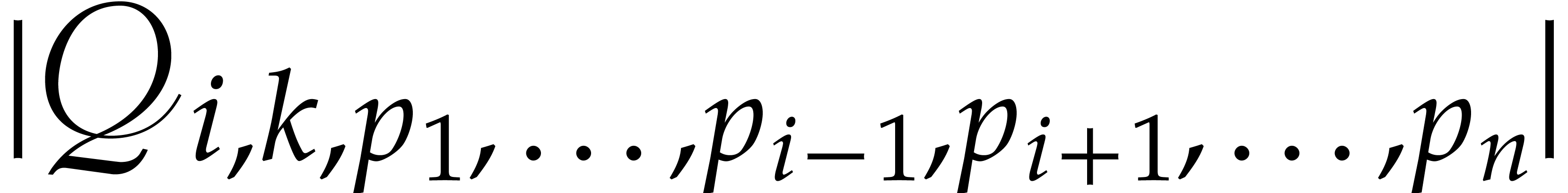 |
 |
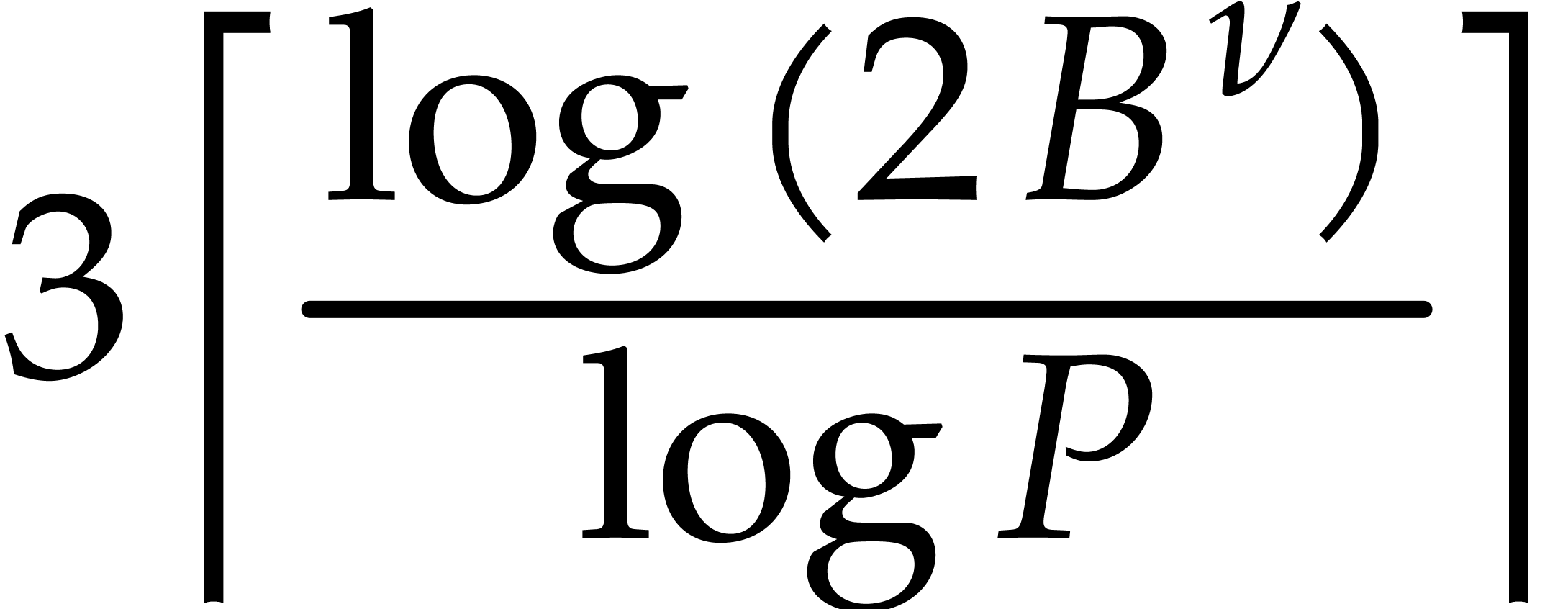 |
|
|
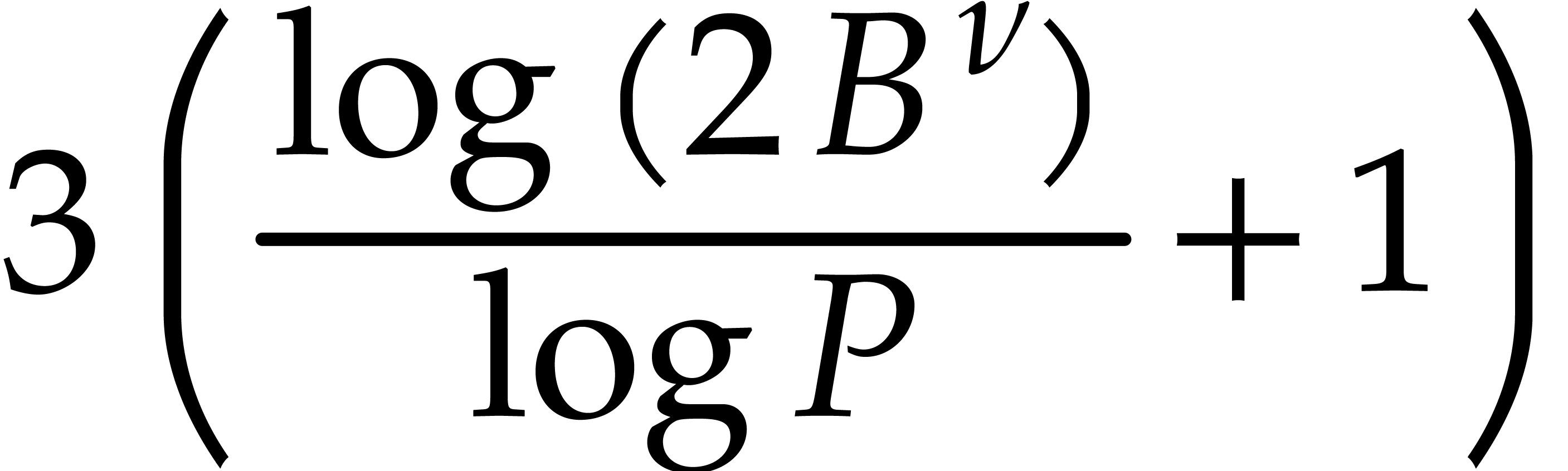 |
||
 |
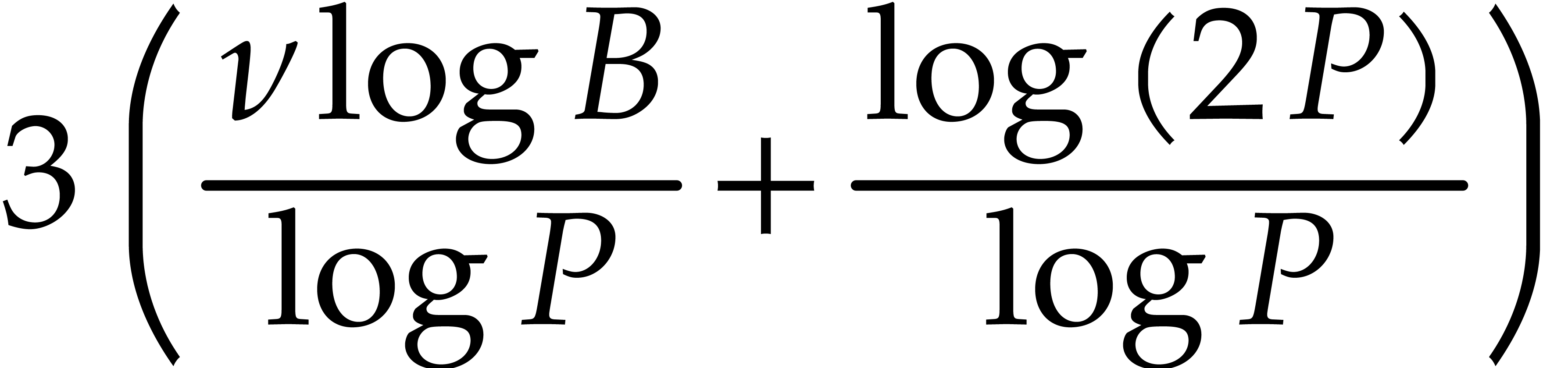 |
||
|
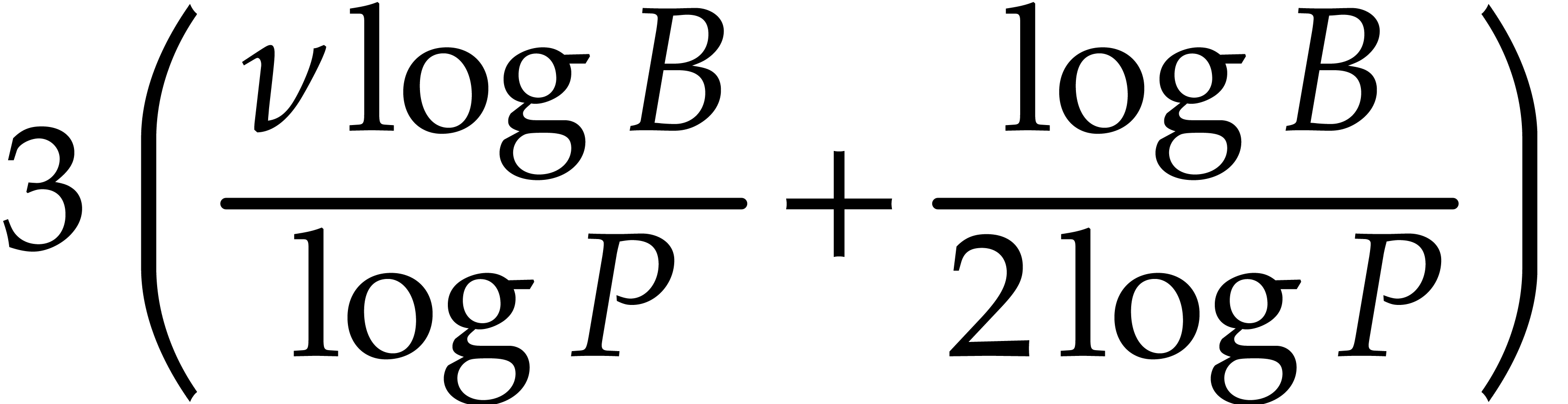 |
(by |
|
|
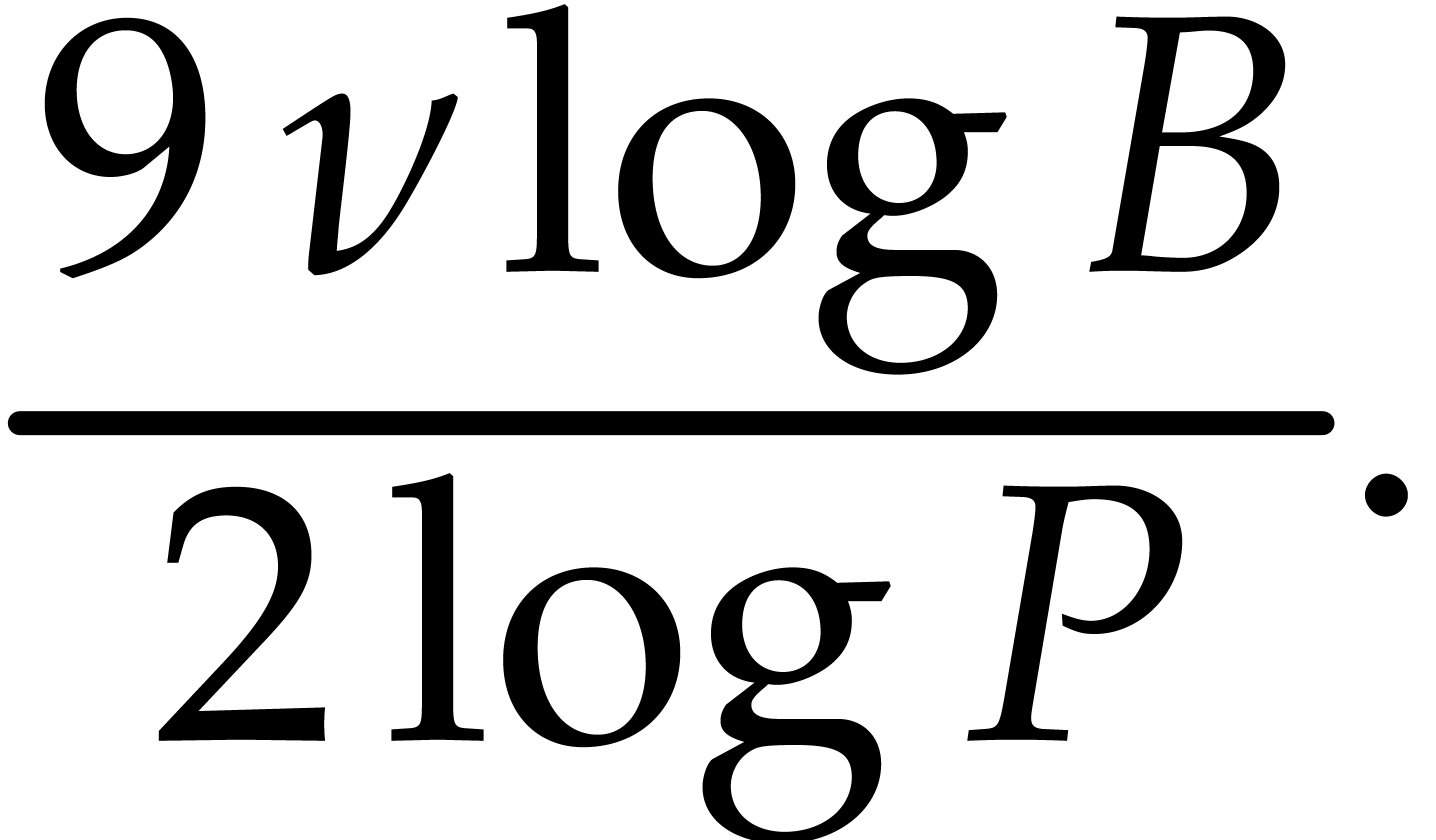 |
Now let
so that  . By what precedes,
we have
. By what precedes,
we have
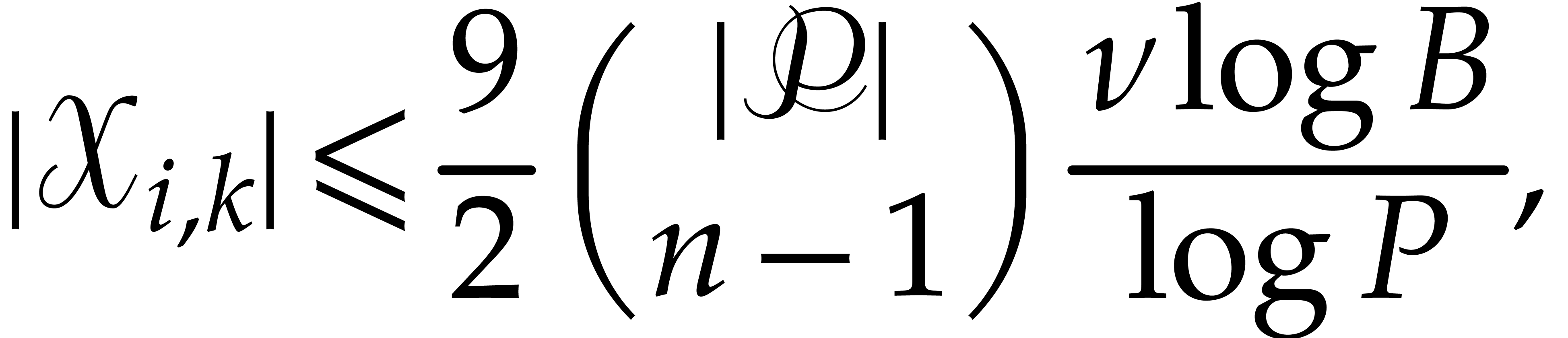
whence
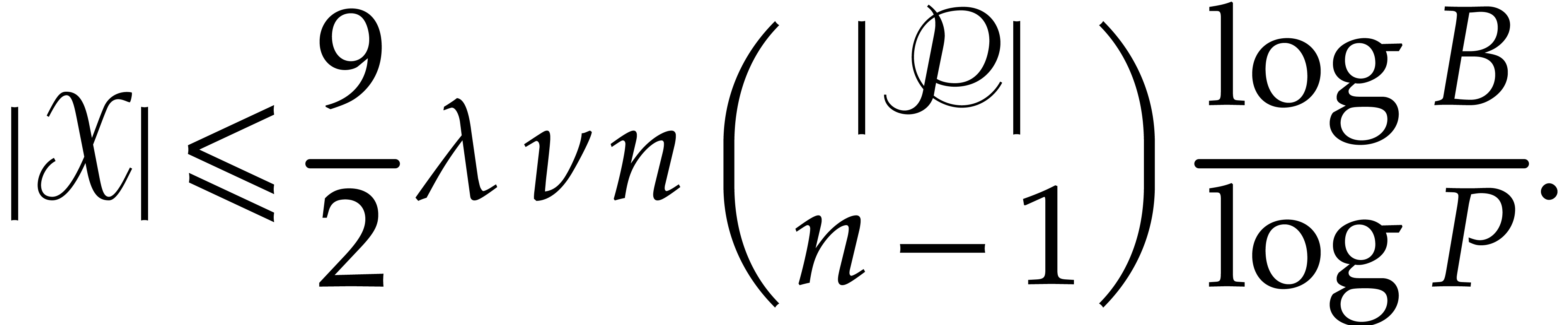
From  we deduce that
we deduce that
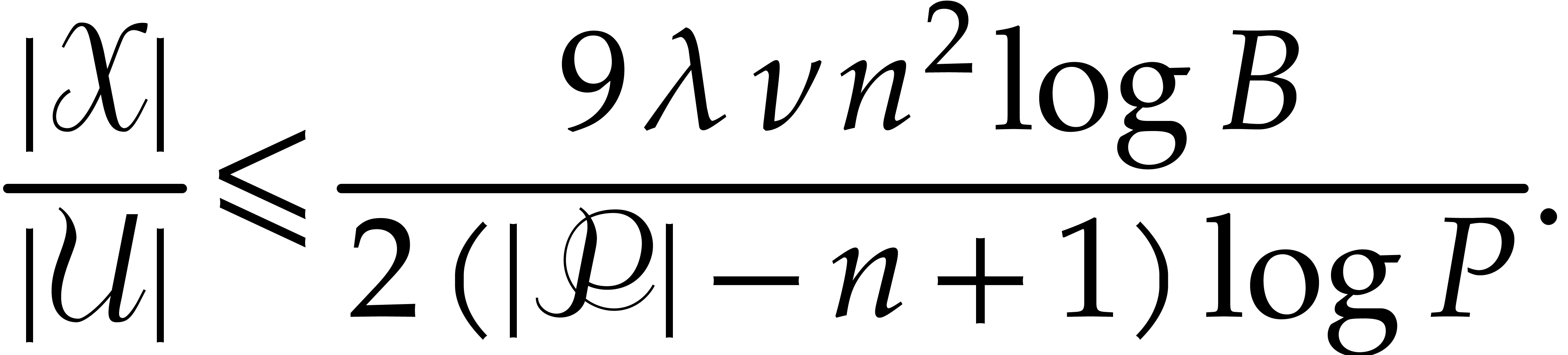
From Theorem 2.3 we know that 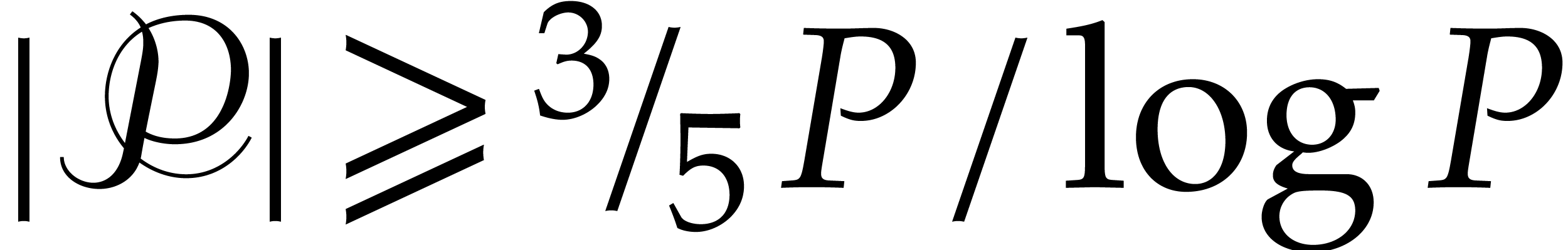 .
This yields
.
This yields 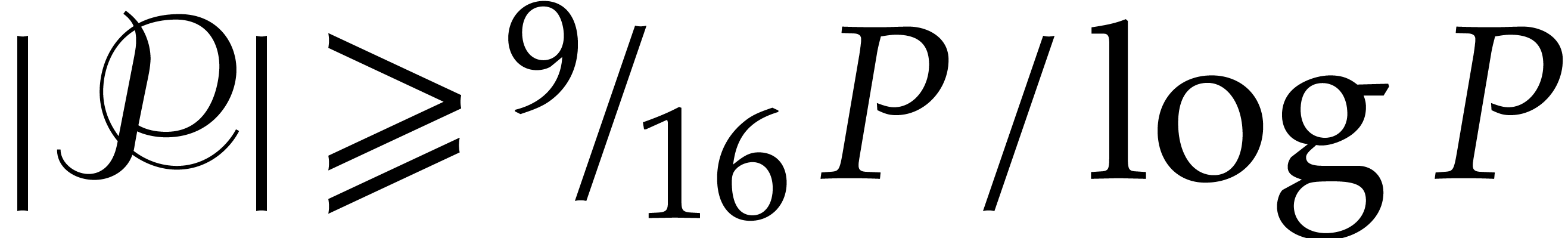 , as well as
, as well as
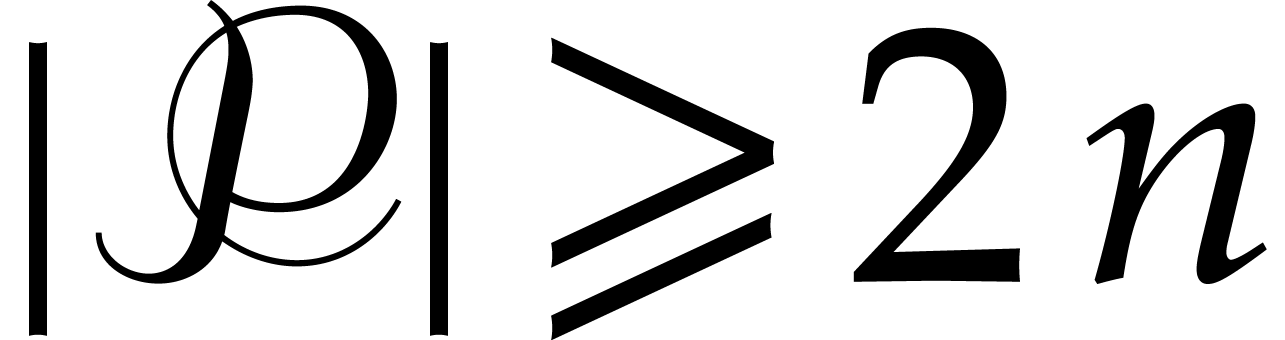 , thanks to
, thanks to
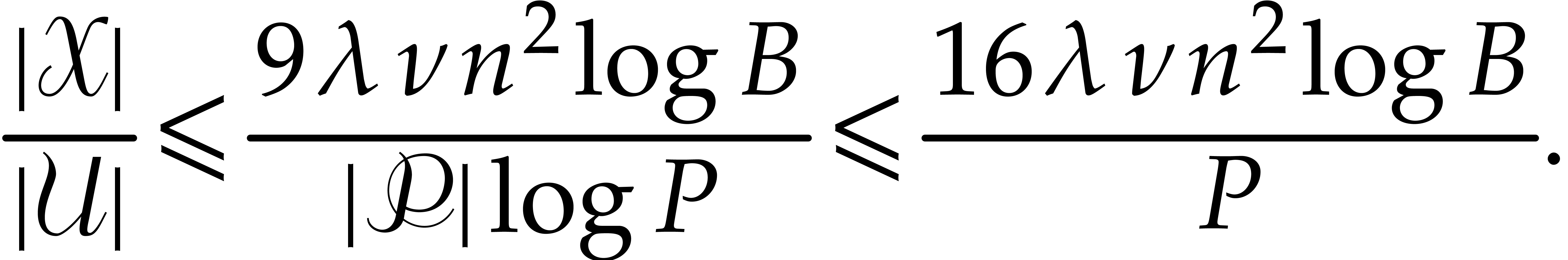
Example
 |
(3.5) |
whose rows are the reductions of modulo  . By investigating the zero
coefficients of this matrix, we verify that is
faithful. Again, for our choice of parameters, the probability estimate
from Lemma 3.4 turns out to be somewhat pessimistic.
. By investigating the zero
coefficients of this matrix, we verify that is
faithful. Again, for our choice of parameters, the probability estimate
from Lemma 3.4 turns out to be somewhat pessimistic.
Given 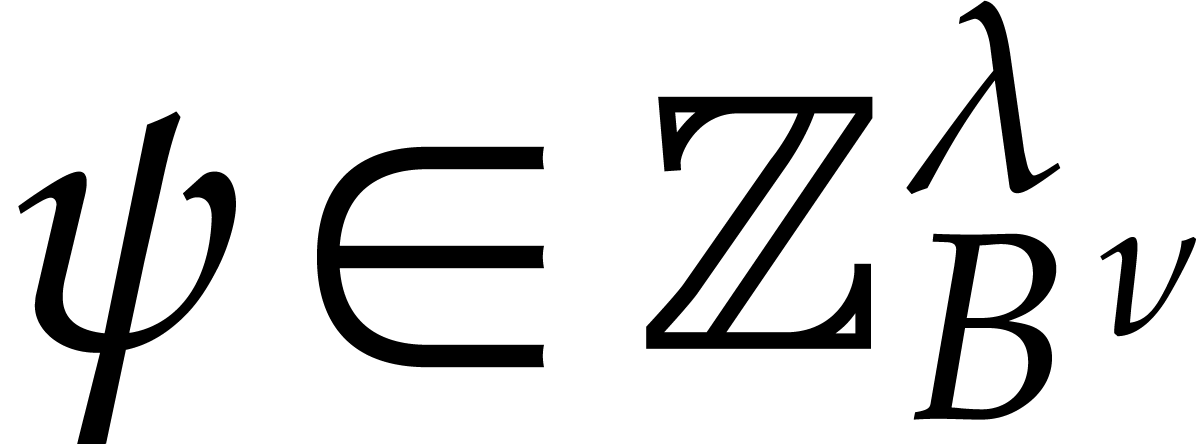 and ,
let
and ,
let 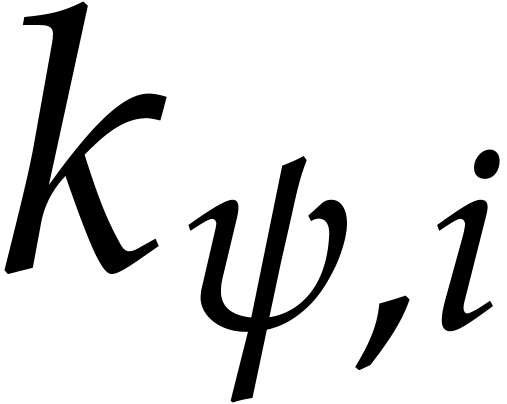 be the smallest index such that
be the smallest index such that 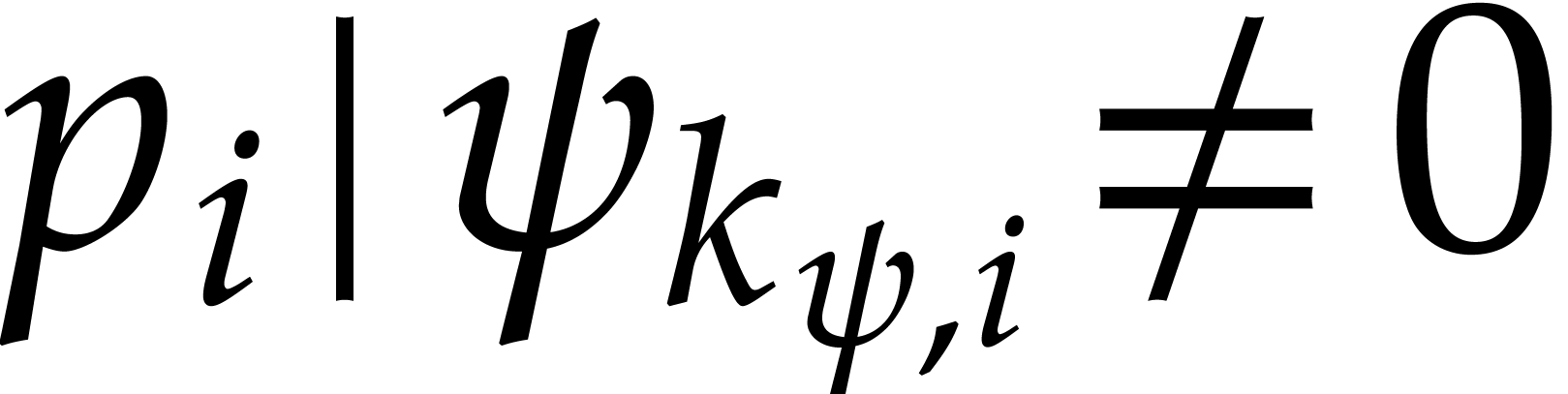 and
and 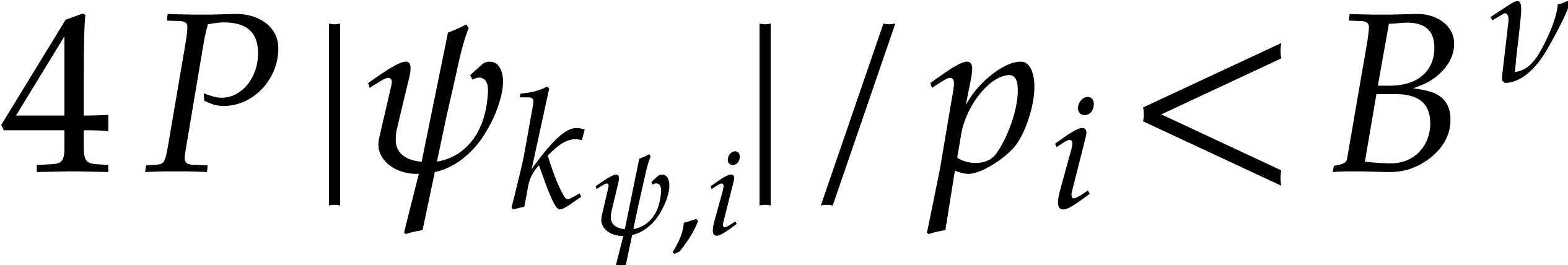 . If no
such exists, then we let
. If no
such exists, then we let 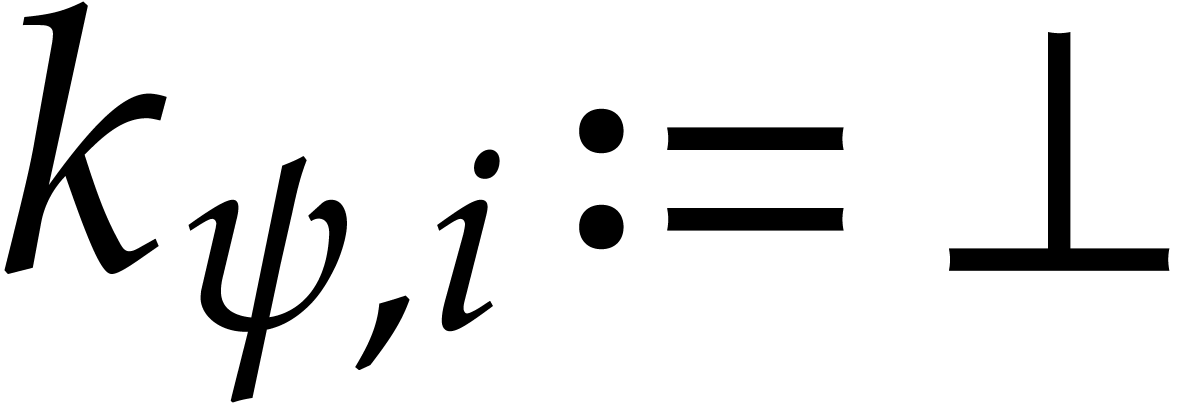 . We define
. We define 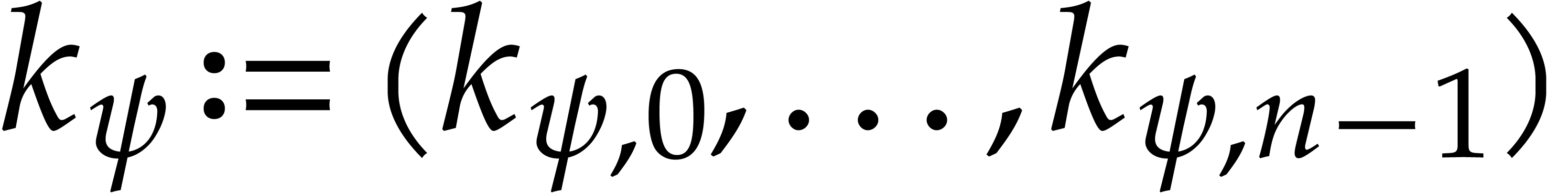 .
.
Assume that 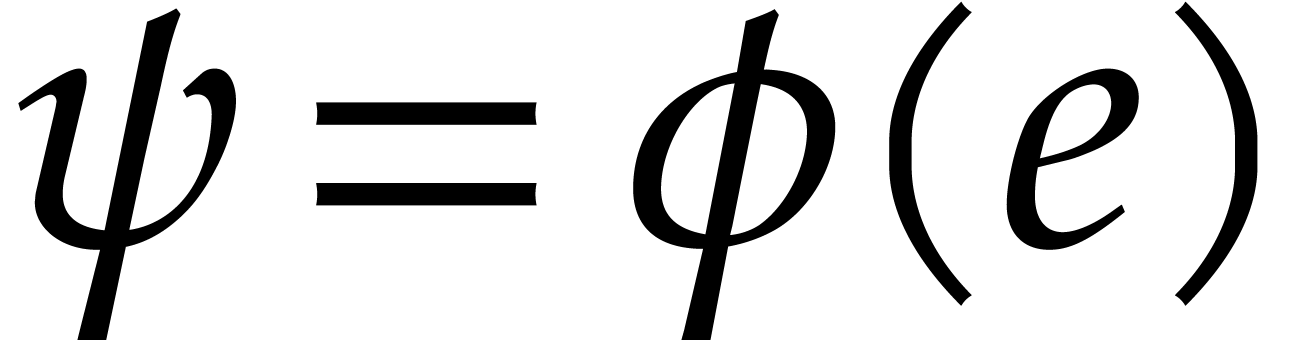 is transparent and faithful for some
. Given , let
is transparent and faithful for some
. Given , let 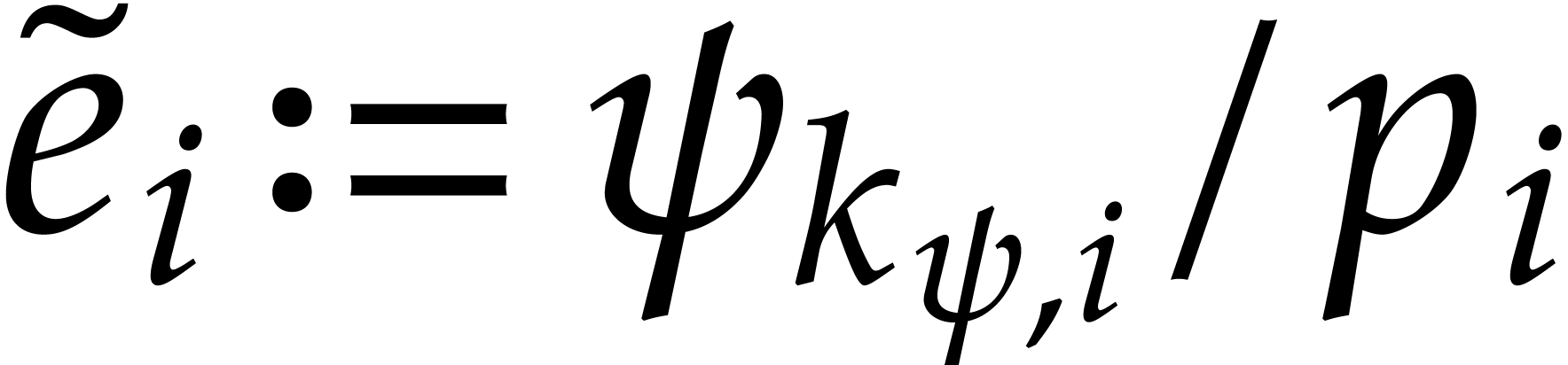 if
if 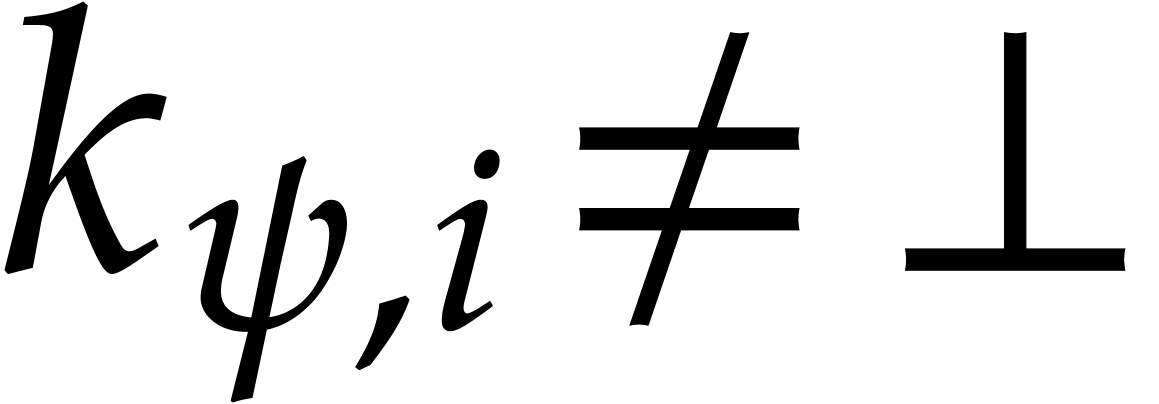 and
and 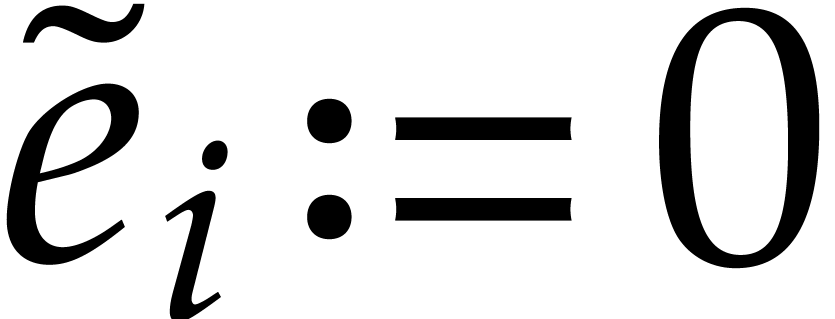 otherwise. Then the condition
implies that
otherwise. Then the condition
implies that 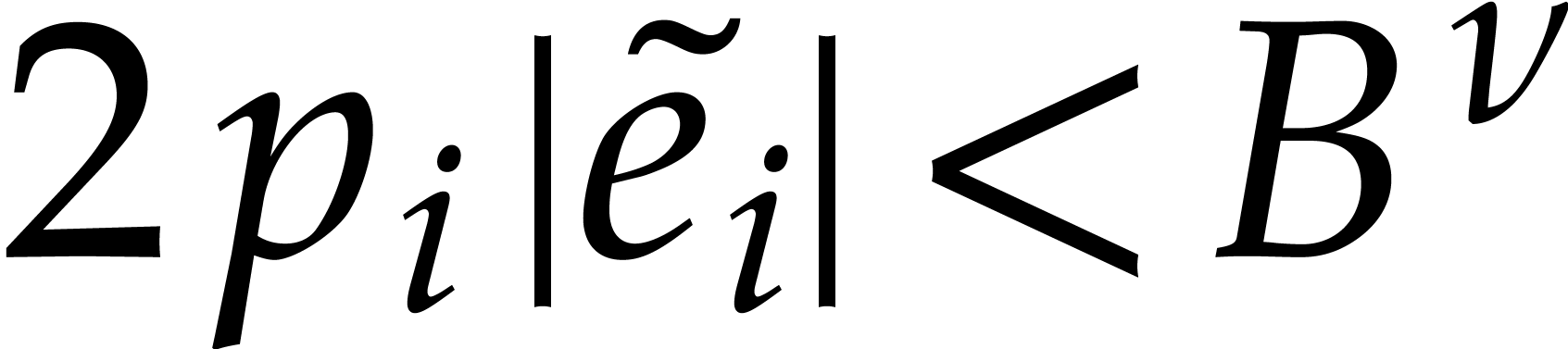 always
holds. Moreover, if , then
the definitions of “transparent” and “faithful”
imply that
always
holds. Moreover, if , then
the definitions of “transparent” and “faithful”
imply that 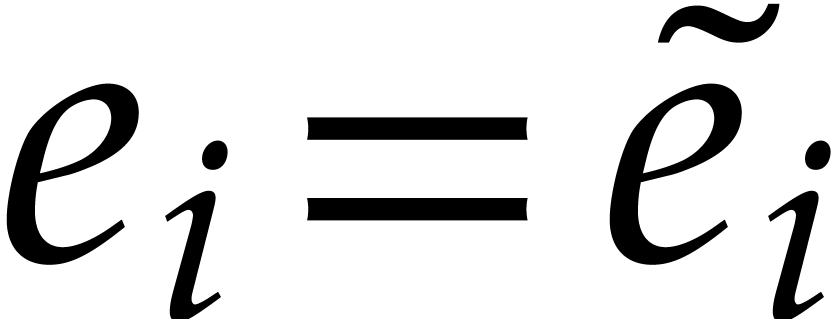 . In other words,
these can efficiently be recovered from
. In other words,
these can efficiently be recovered from  and
and  .
.
Example
is both transparent and faithful. We claim that we can reconstruct from .
Indeed, by looking at the matrix (3.5), we observe that
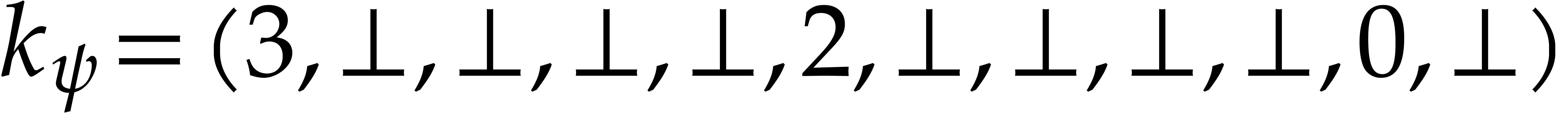 . Consequently,
. Consequently, 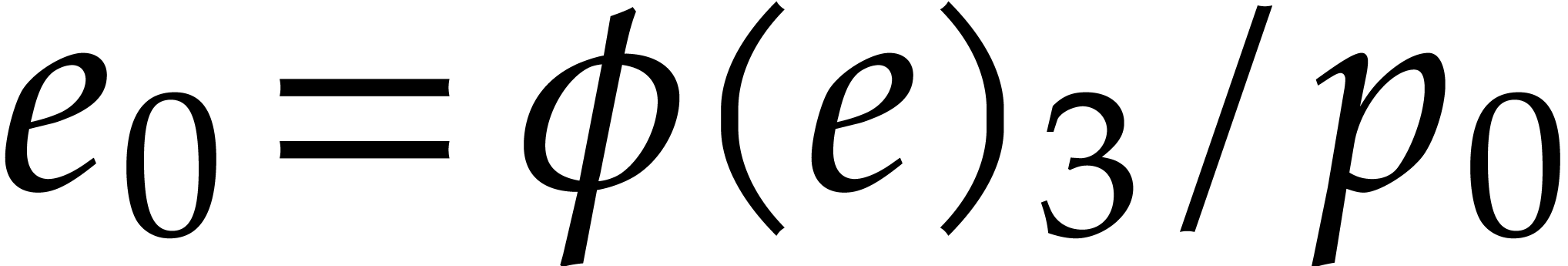 ,
, 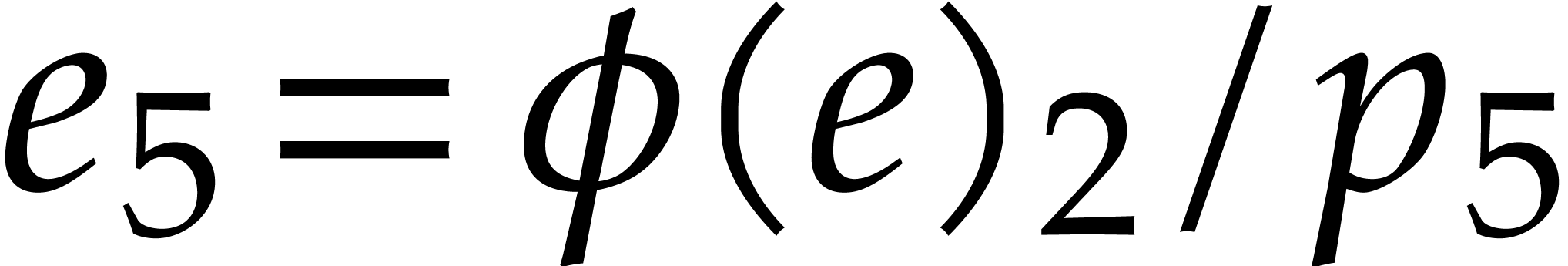 ,
and
,
and 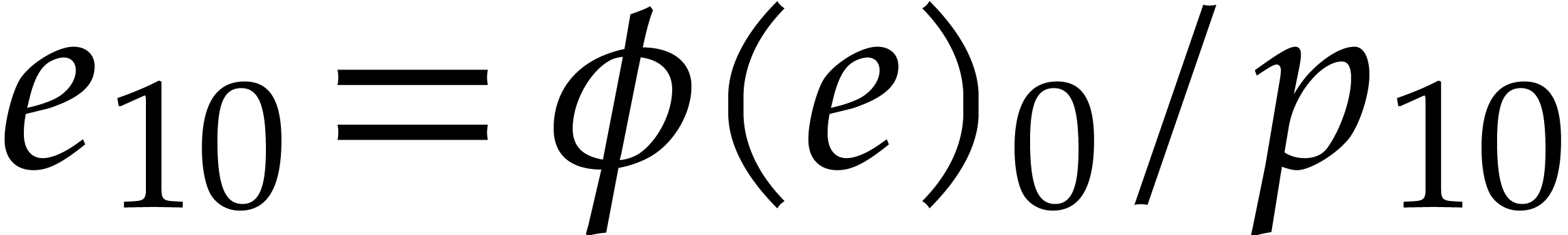 .
.
In what follows, we will need a procedure to efficiently compute for a large number of
different encodings ,
corresponding to the terms of a sparse polynomial.
Proof. Note that the hypotheses 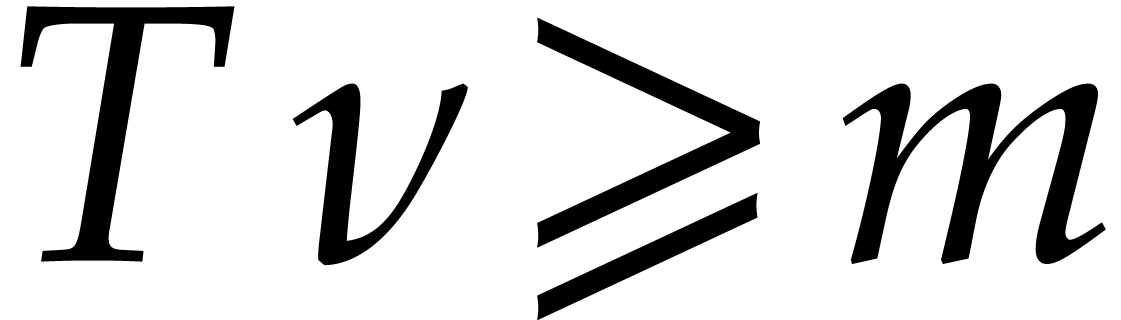 and
and  imply that
imply that 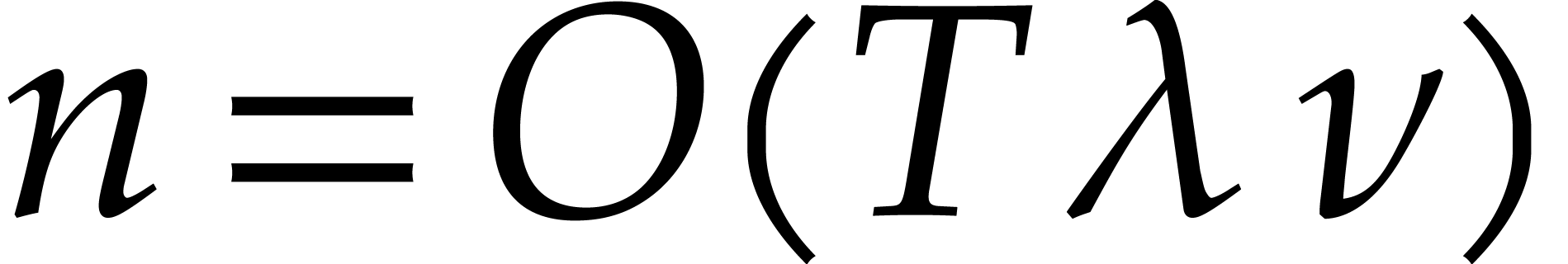 .
Using Lemma 2.7, we can compute all triples
.
Using Lemma 2.7, we can compute all triples 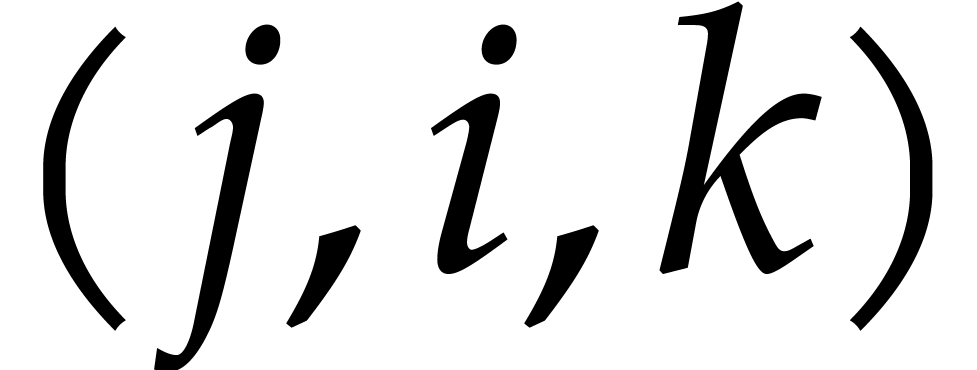 with
with 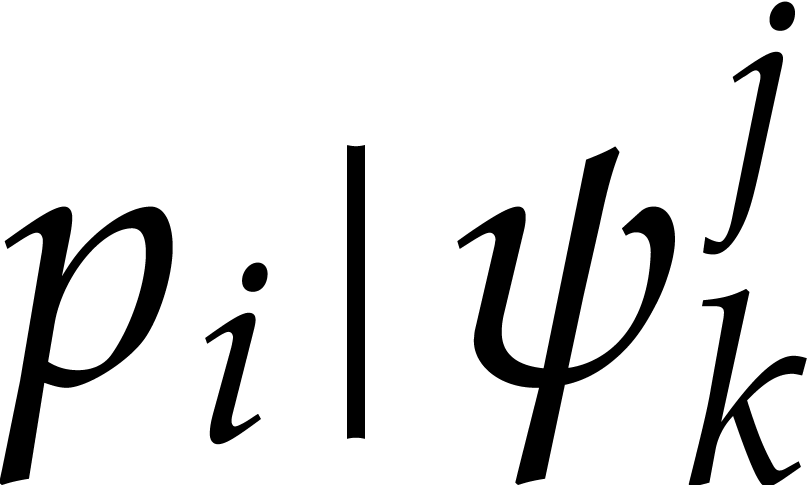 in time
in time
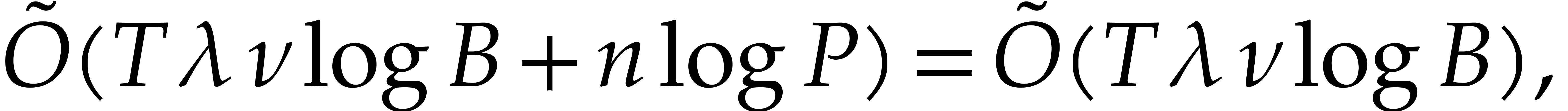
thanks to 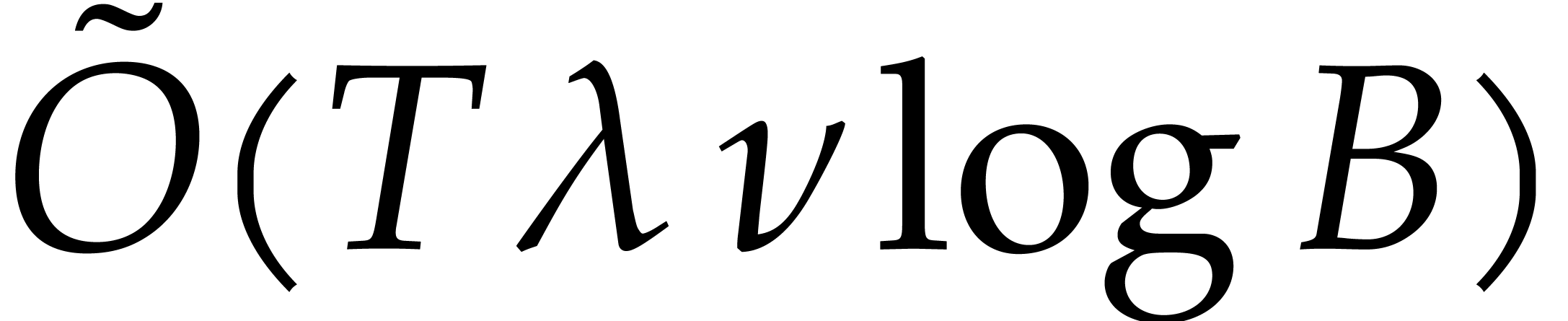 further operations we can filter out the triples
further operations we can filter out the triples 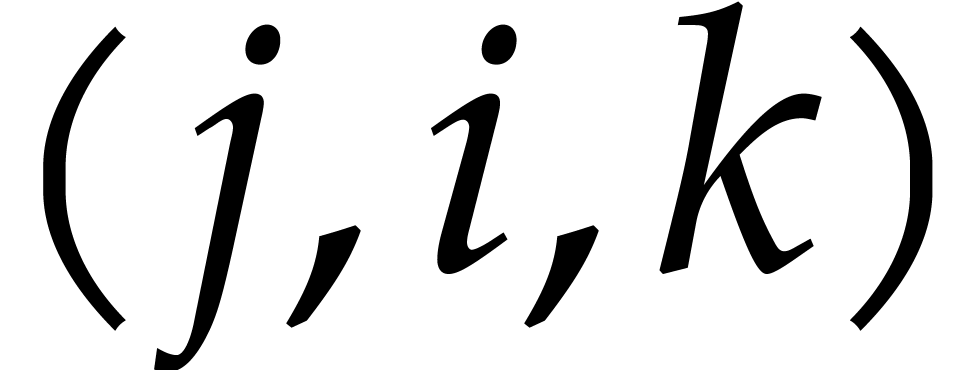 for which
for which 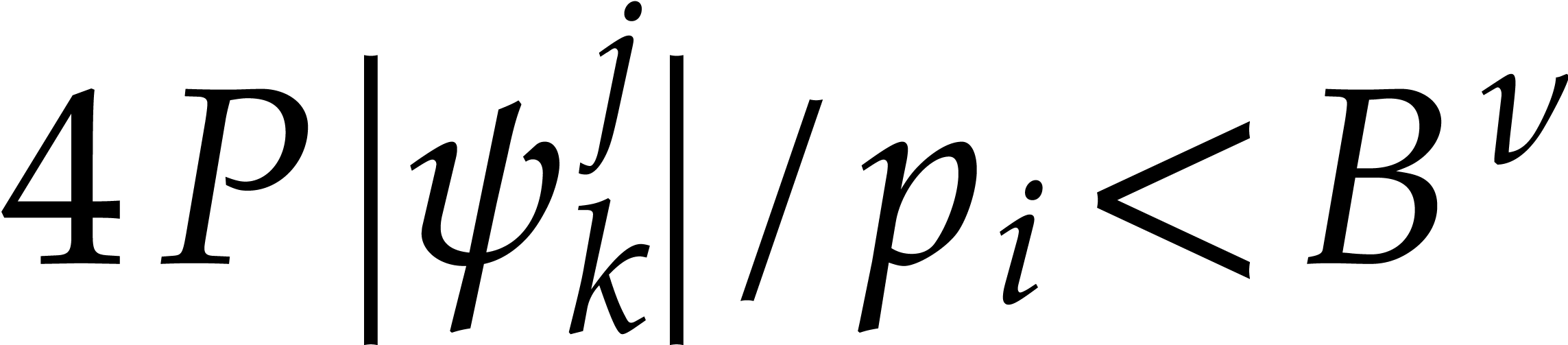 . We
next sort the resulting triples for the lexicographical ordering, which
can again be done in time .
For each pair
. We
next sort the resulting triples for the lexicographical ordering, which
can again be done in time .
For each pair 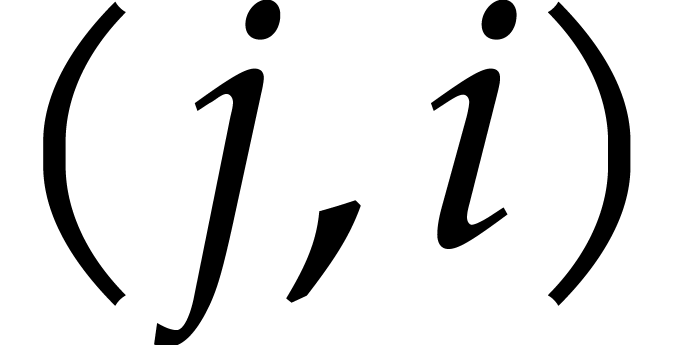 , we finally
only retain the first triple of the form .
This can once more be done in time .
Then the remaining triples are precisely those
, we finally
only retain the first triple of the form .
This can once more be done in time .
Then the remaining triples are precisely those 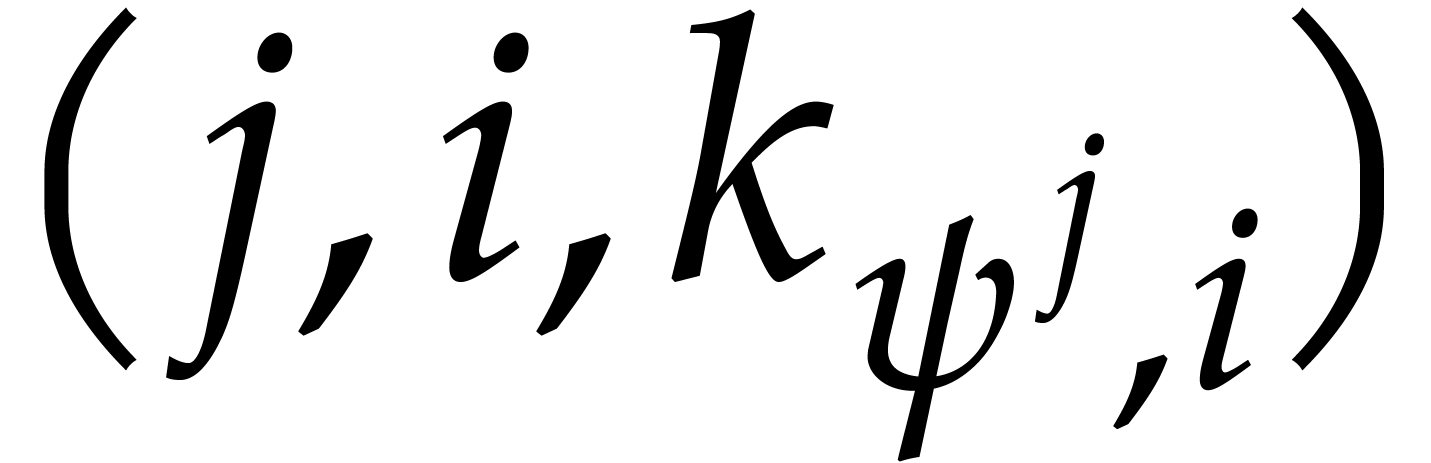 with
with  .
.
The following combination of the preceding lemmas will be used in the sequel:
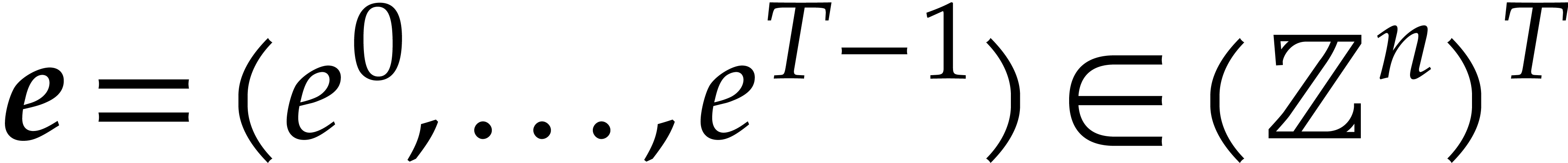 and let
and let 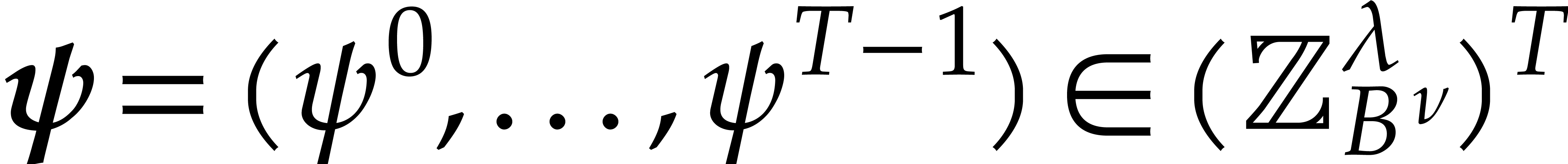 be
the corresponding values as above. Let
be
the corresponding values as above. Let  be the
set of indices
be the
set of indices 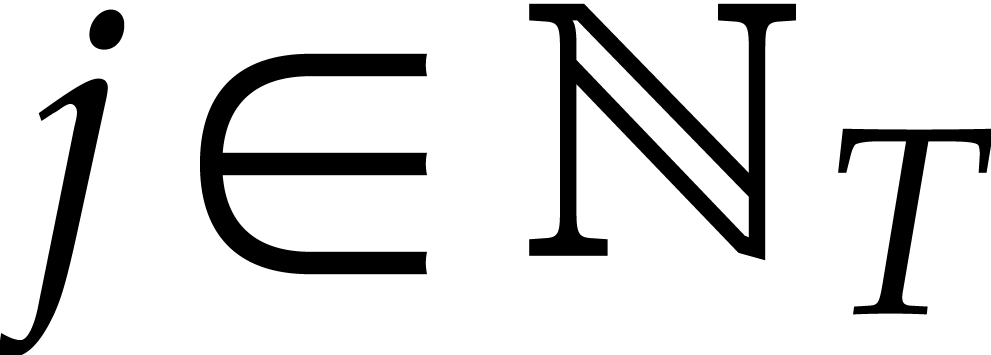 such that
such that 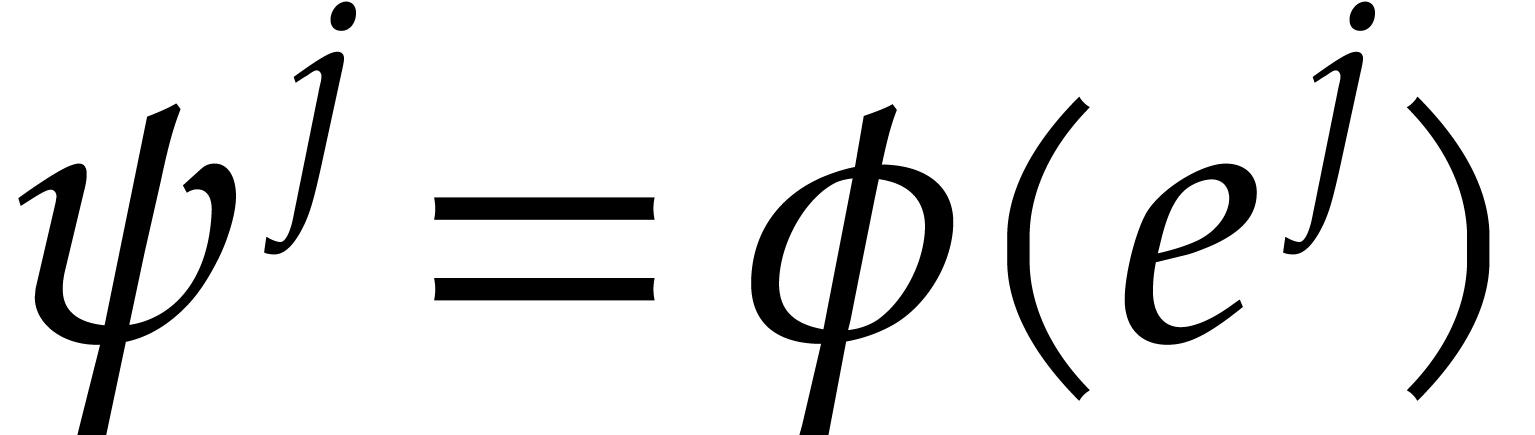 and
and 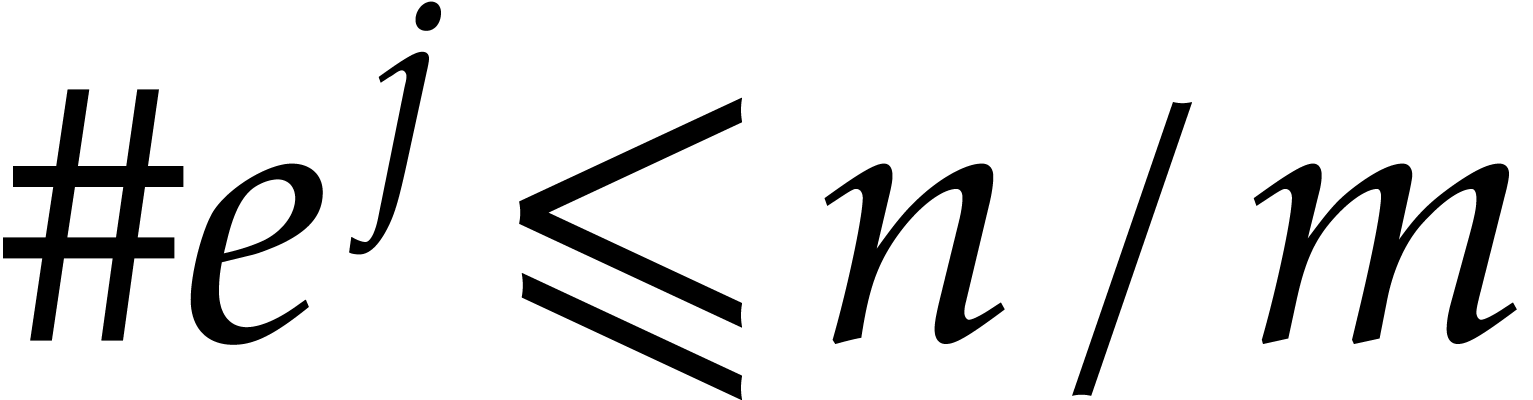 . Then there exists an
algorithm that takes
. Then there exists an
algorithm that takes  as input and that
computes
as input and that
computes 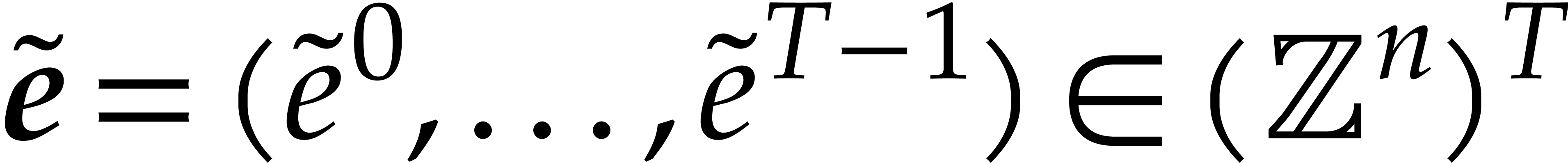 such that
such that 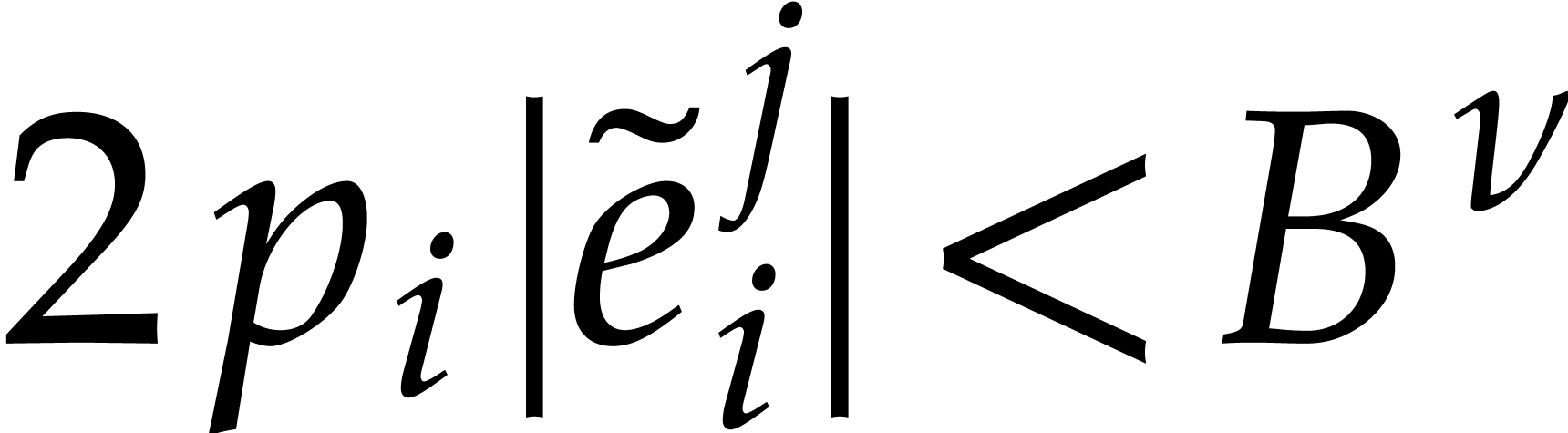 for
all
for
all  and
and 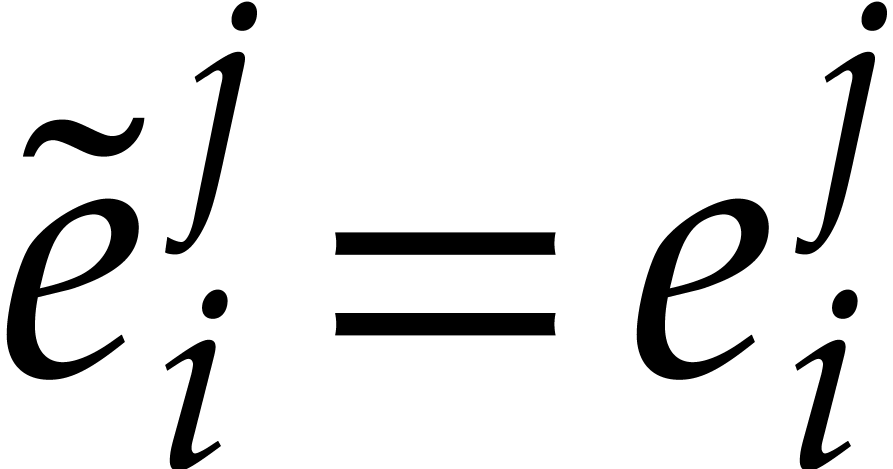 for all
for all  with
with 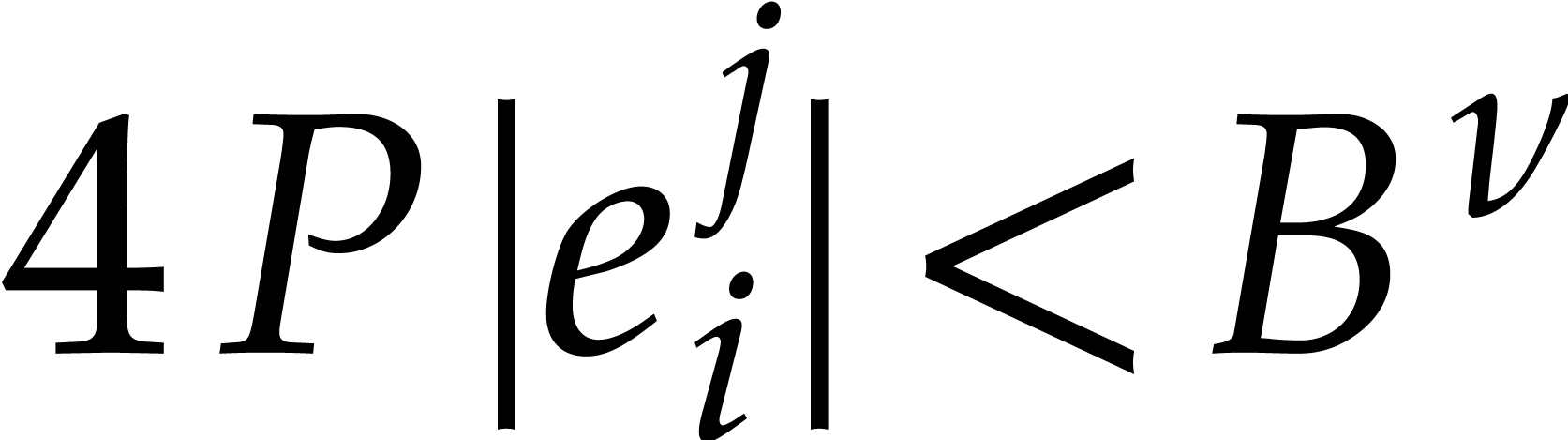 .
The algorithm runs in time and succeeds with
probability at least
.
The algorithm runs in time and succeeds with
probability at least
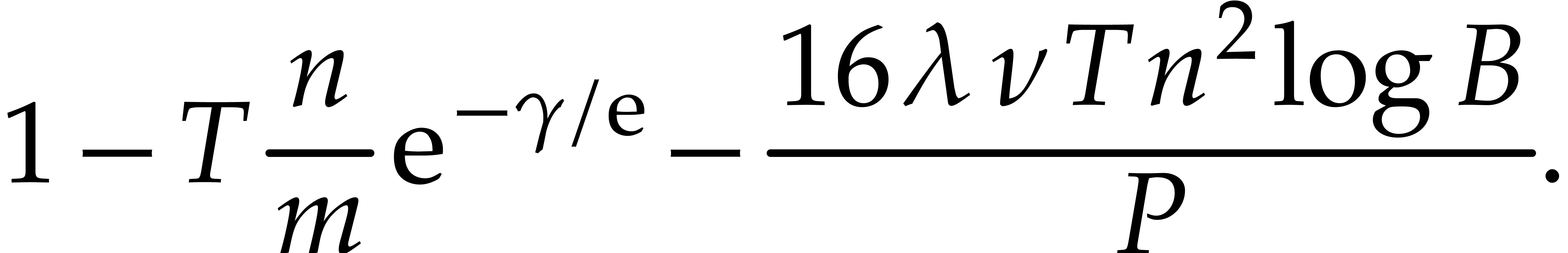
Proof. Lemmas 3.2 and 3.4
bound the probability of failure for the transparency and the
faithfulness of the random choices for each of the  terms. The complexity bound follows from Lemma 3.7.
terms. The complexity bound follows from Lemma 3.7.
Our next aim is to determine all exponents 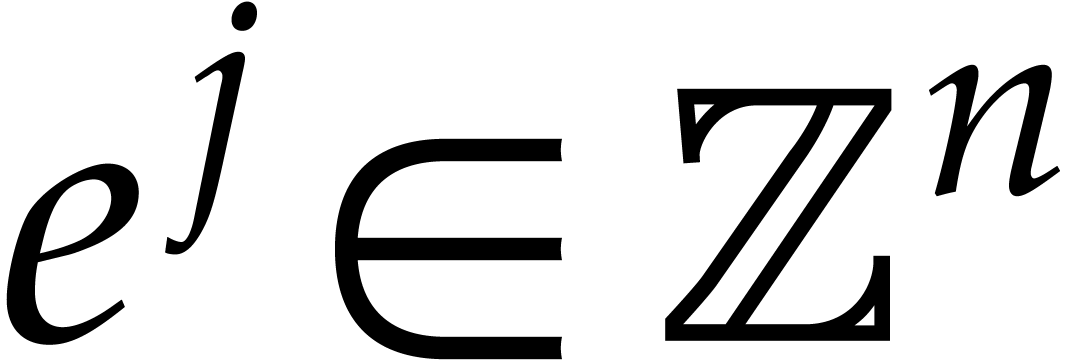 with
with
 , for some fixed threshold
, for some fixed threshold
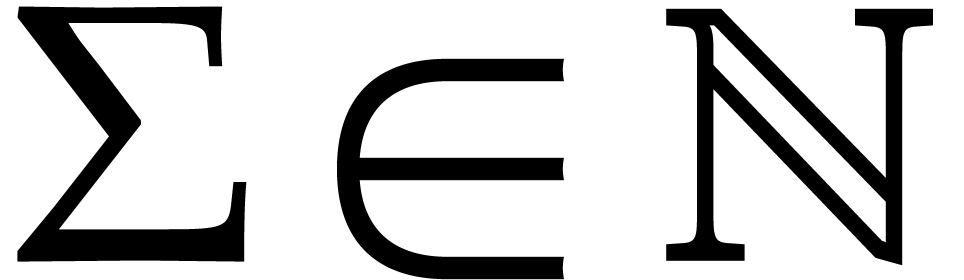 . For this, we will apply
Lemma 3.8 several times, for different choices of . Let
. For this, we will apply
Lemma 3.8 several times, for different choices of . Let

For 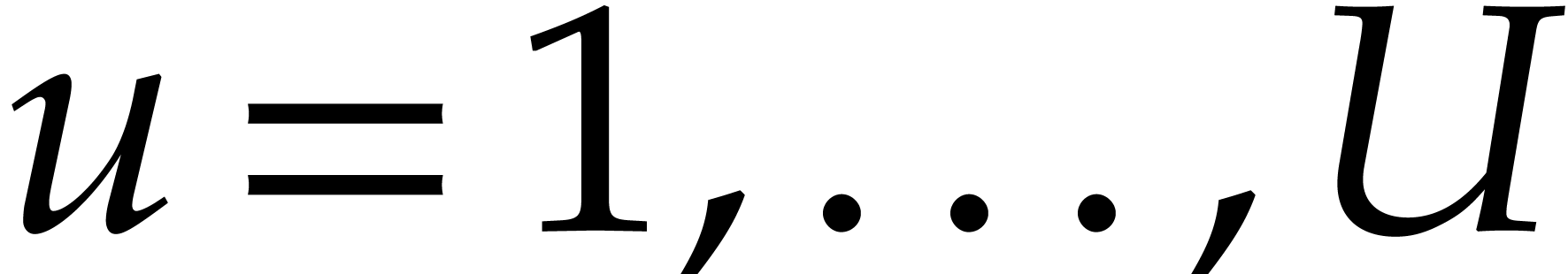 , let
, let
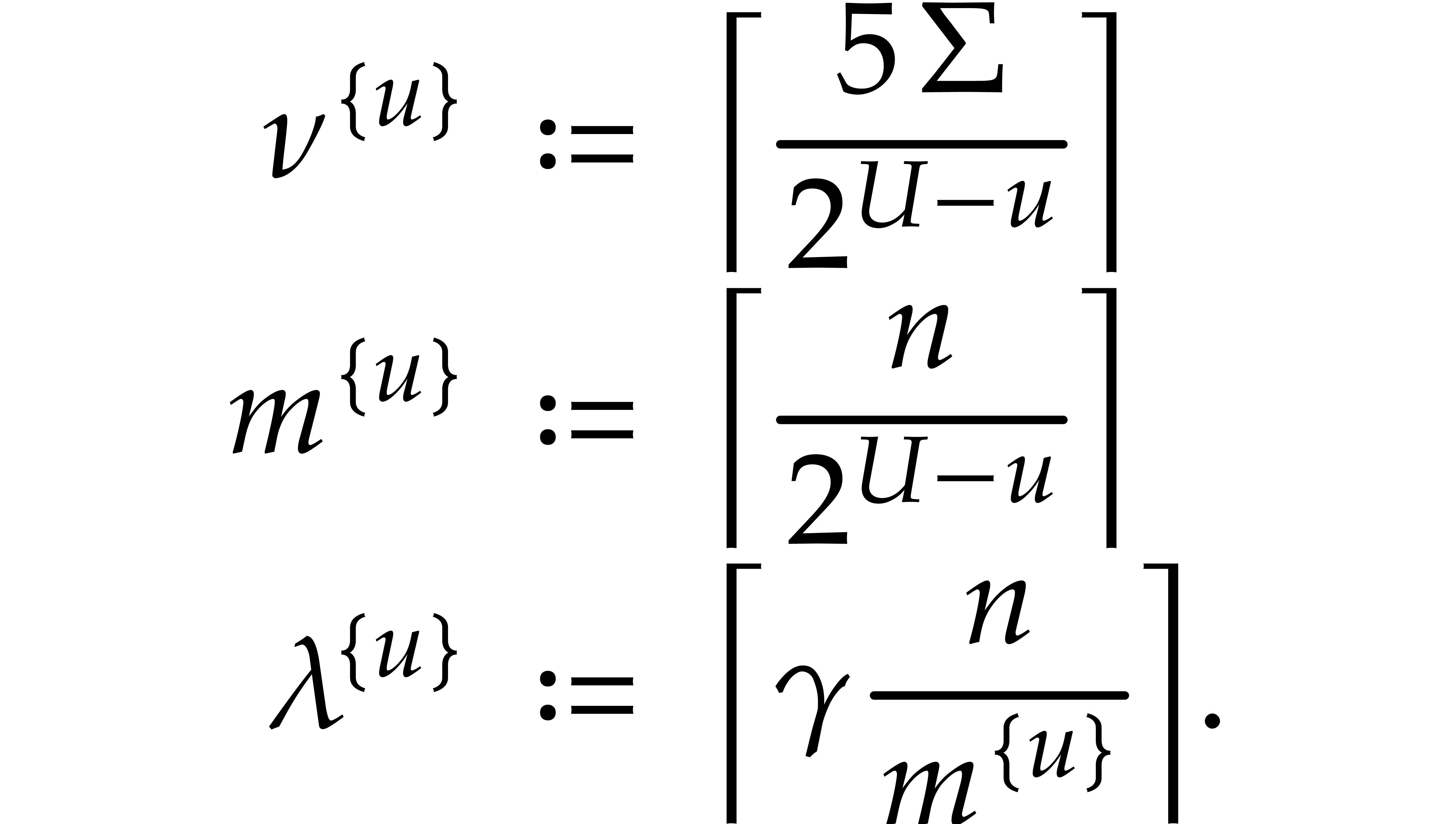
We also choose 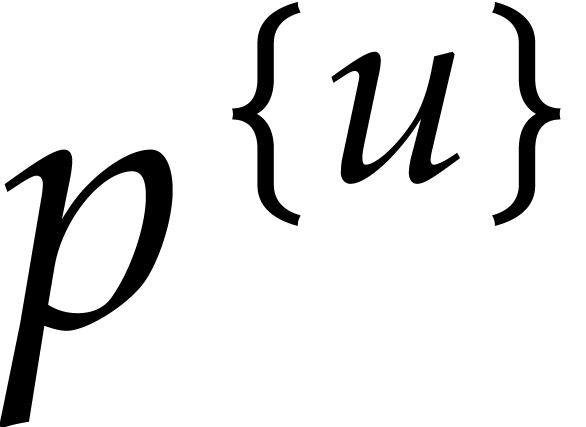 and
and 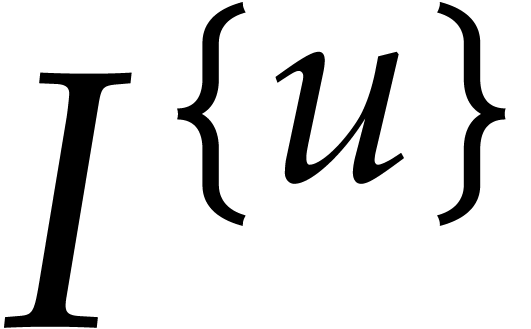 independently at random as explained in section 3.1, with
independently at random as explained in section 3.1, with
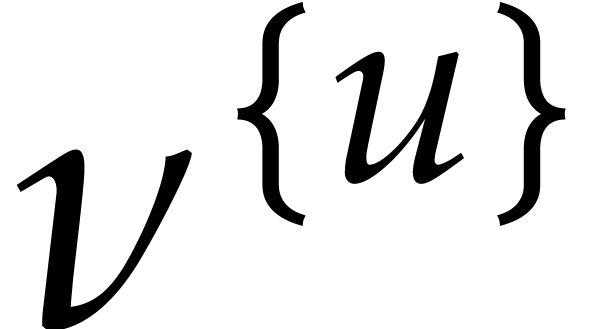 ,
, 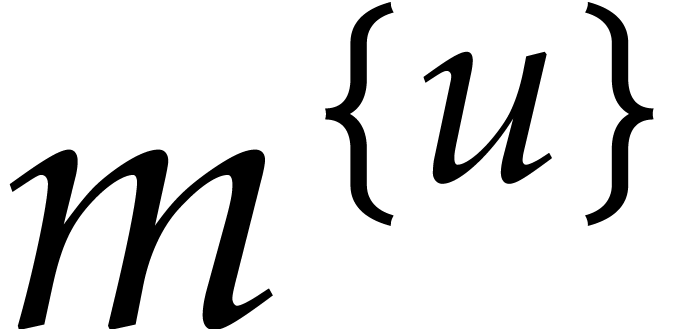 , and
, and 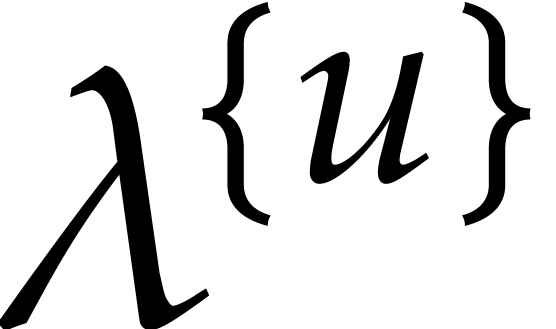 in the roles of , ,
and
in the roles of , ,
and 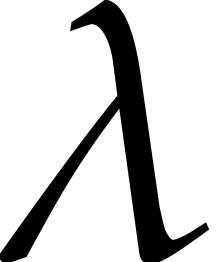 . So
is a set of pairwise distinct random prime
numbers in and is a
tuple
. So
is a set of pairwise distinct random prime
numbers in and is a
tuple 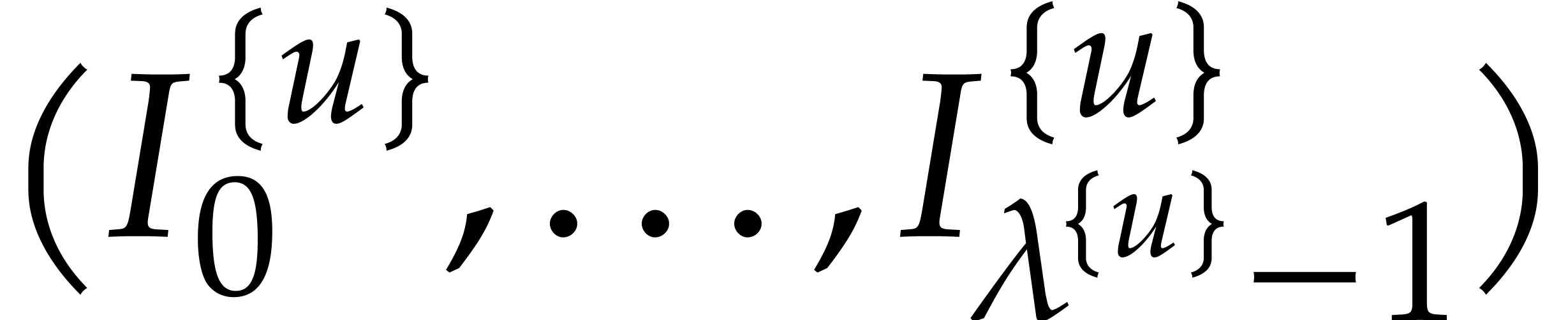 of subsets of of
cardinality . We finally
define
of subsets of of
cardinality . We finally
define

for .
Note that the above definitions imply
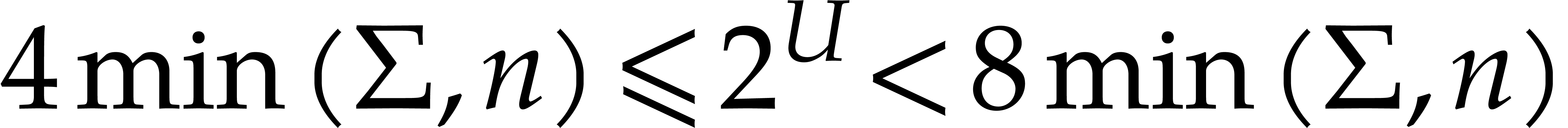 |
(3.6) |
and 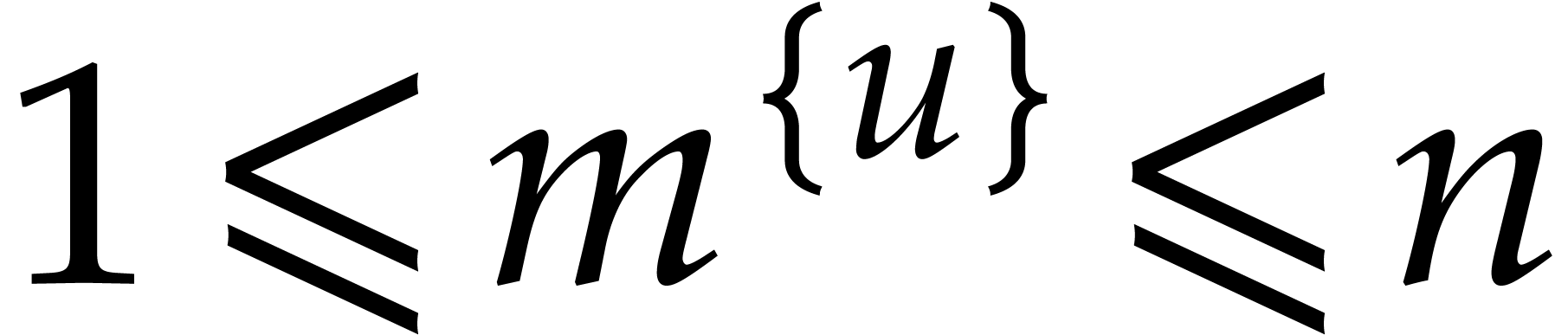 . The inequality
. The inequality 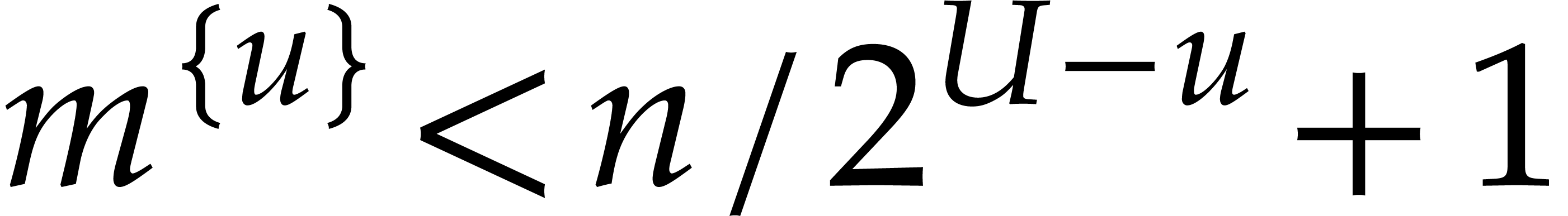 implies
implies
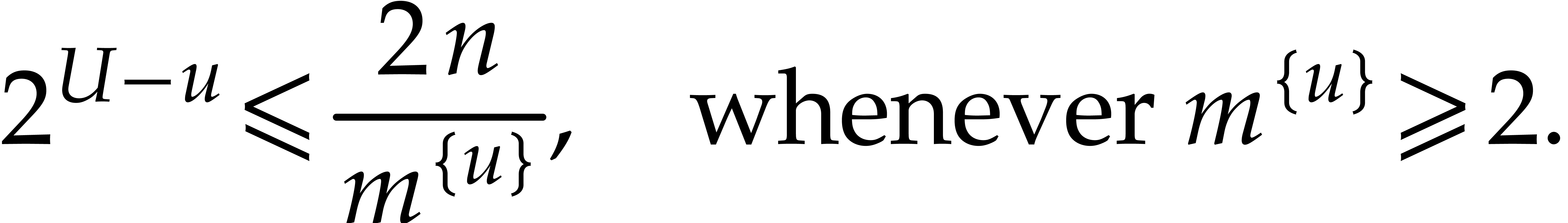 |
(3.7) |
If 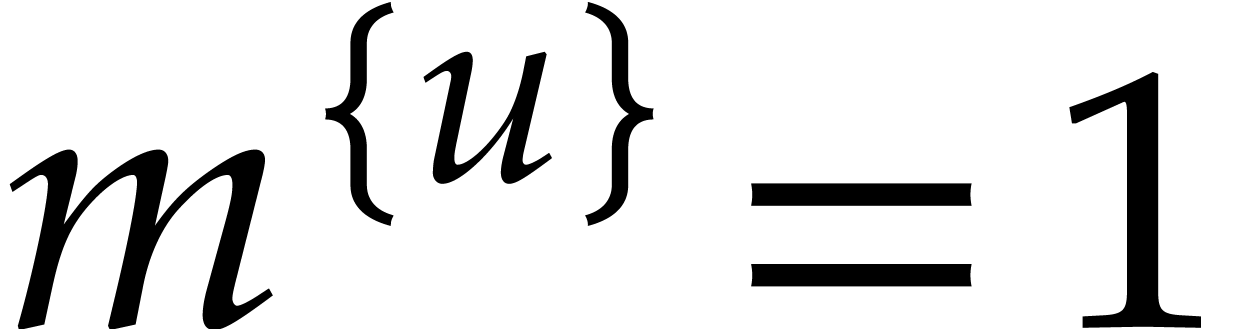 , then
, then  , so, in general,
, so, in general,
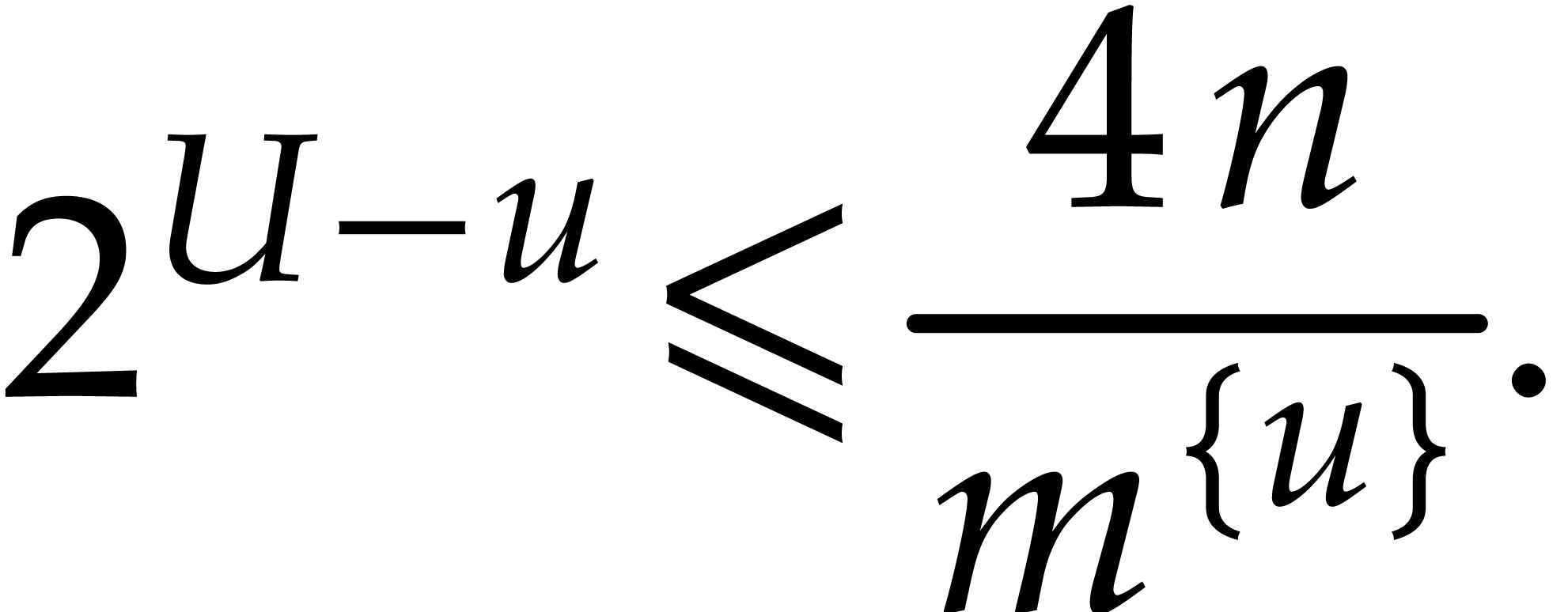 |
(3.8) |
By 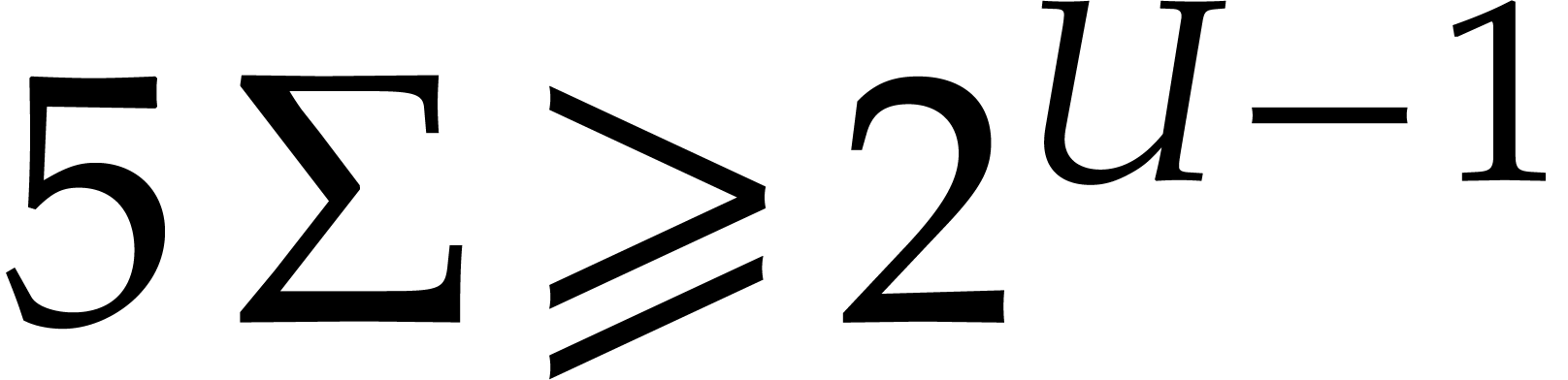 , whence
, whence
 |
(3.9) |
Proof. From ,
we get
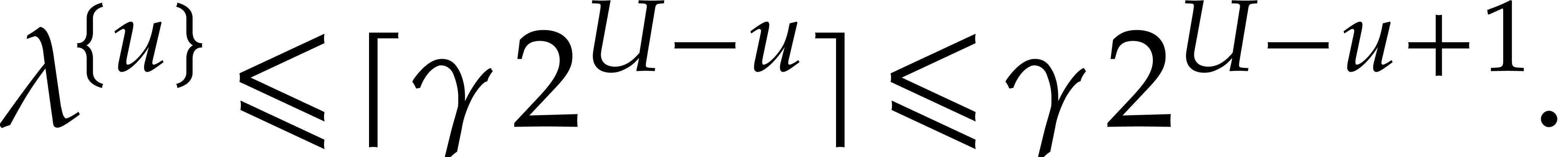 |
(3.10) |
Now
which concludes the proof.
and let 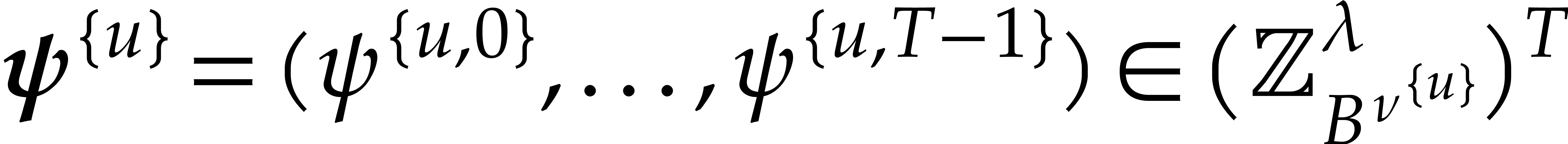 for
for 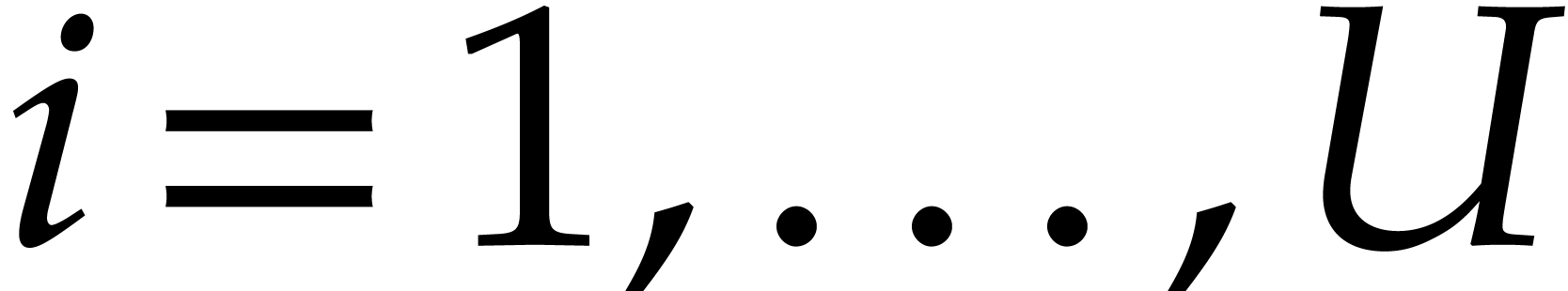 be as above. Assume that
be as above. Assume that 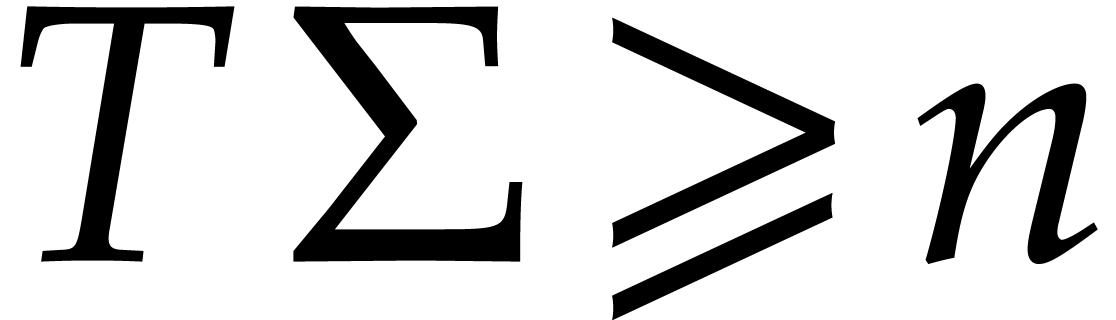 . Let be the set of
indices such that and
. Let be the set of
indices such that and
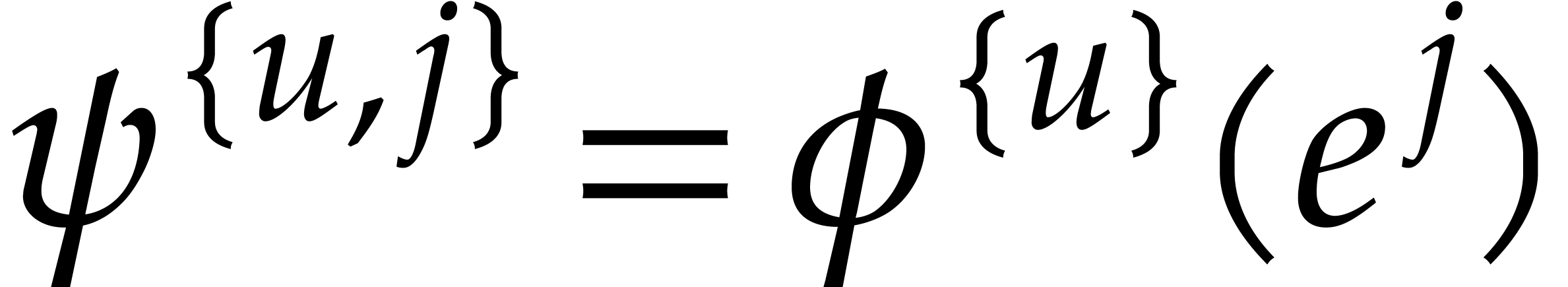 for all
for all 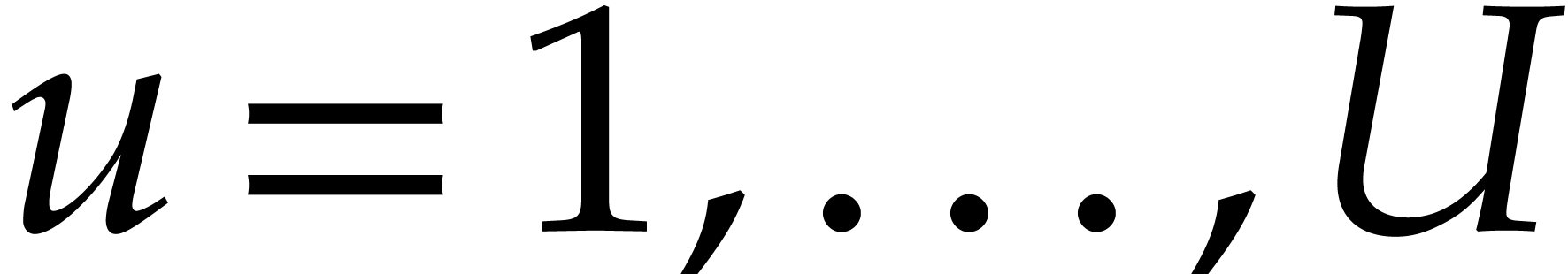 .
Then there exists an algorithm that takes
.
Then there exists an algorithm that takes  as
input and that computes
as
input and that computes 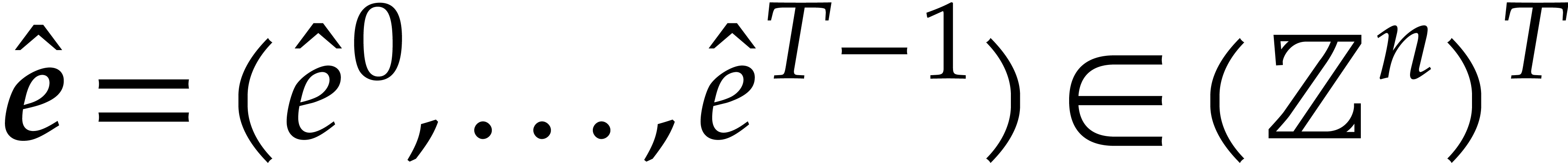 such that
such that  for all and
for all and 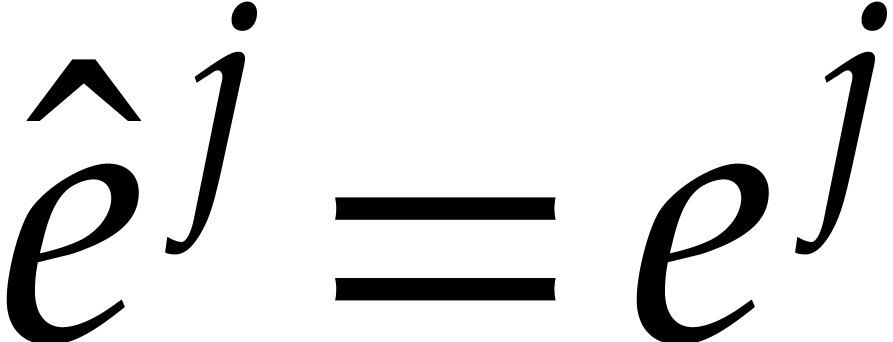 for all . The algorithm
runs in time
for all . The algorithm
runs in time 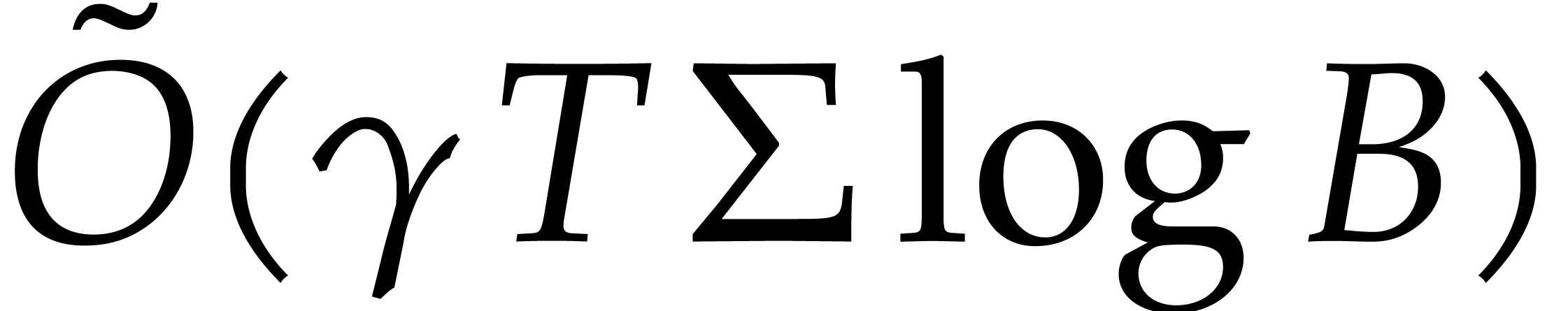 and succeeds with probability at
least
and succeeds with probability at
least
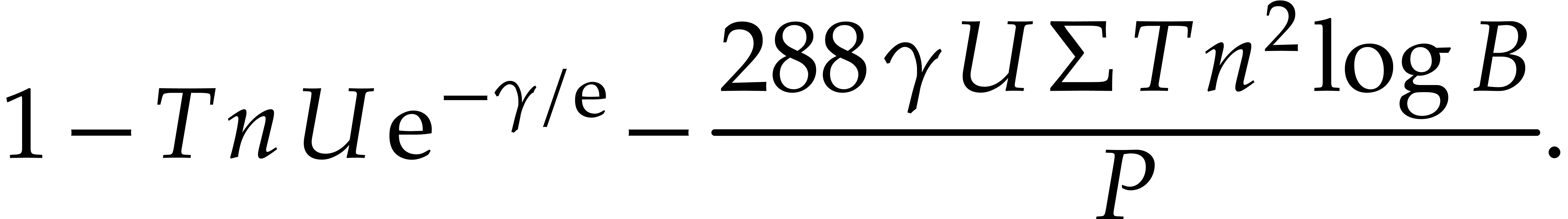
Proof. We compute successive approximations  of
of  as follows. We start with
as follows. We start with
 . Assuming that
. Assuming that  is known, we compute
is known, we compute
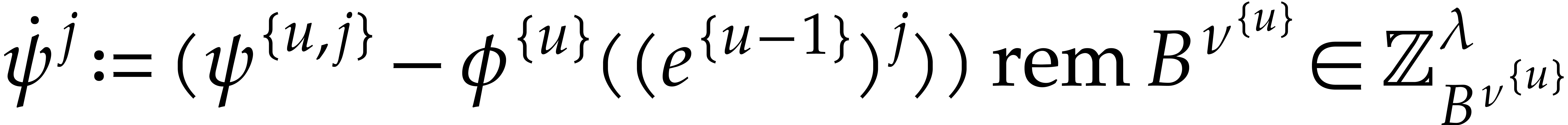
for all , and then apply the
algorithm underlying Lemma 3.8 to  and
and  . Note that for all the equality implies
. Note that for all the equality implies
Our choice of and ,
the inequality successively ensure that
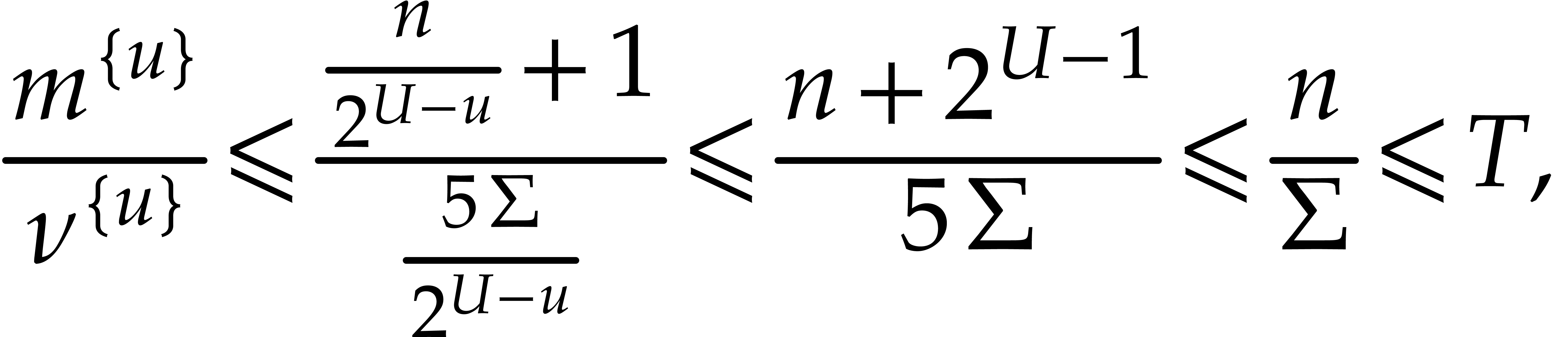
so we can actually apply Lemma 3.8.
Let 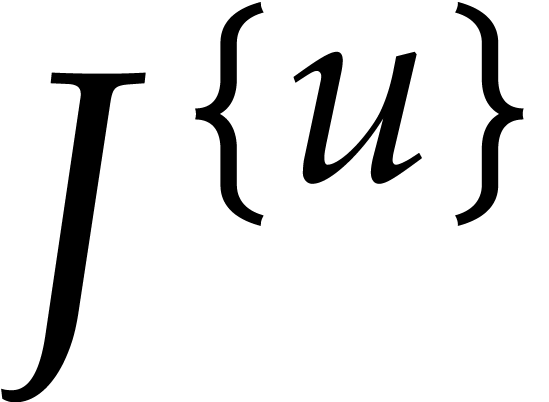 be the set of indices
such that
be the set of indices
such that  and
and 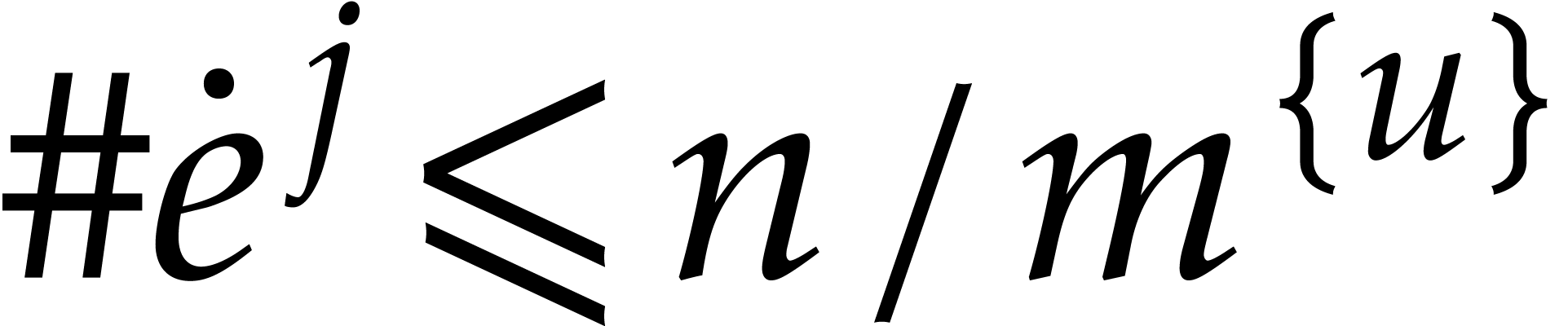 .
Lemma 3.8 provides us with such
that
.
Lemma 3.8 provides us with such
that 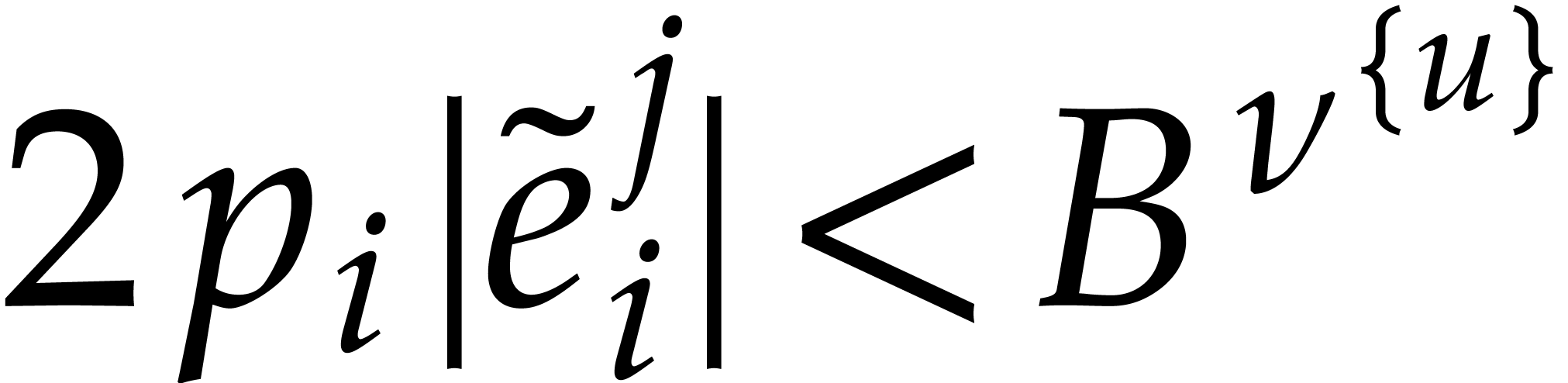 for all .
In addition
for all .
In addition 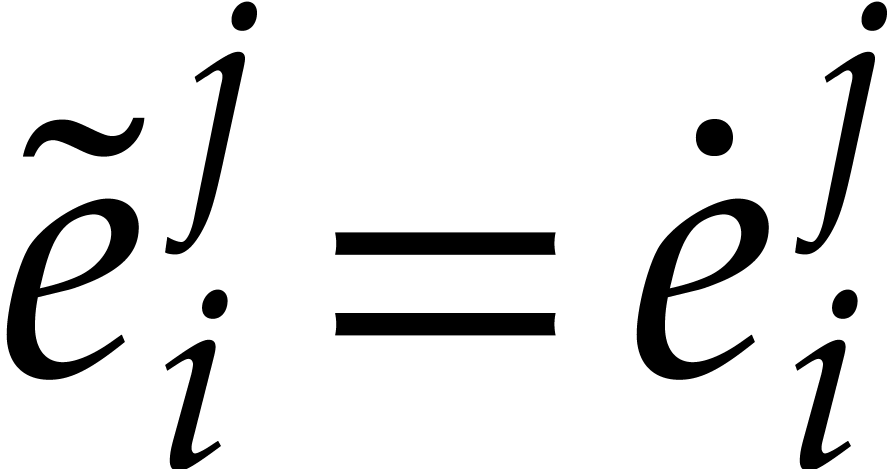 holds whenever
holds whenever  and
and 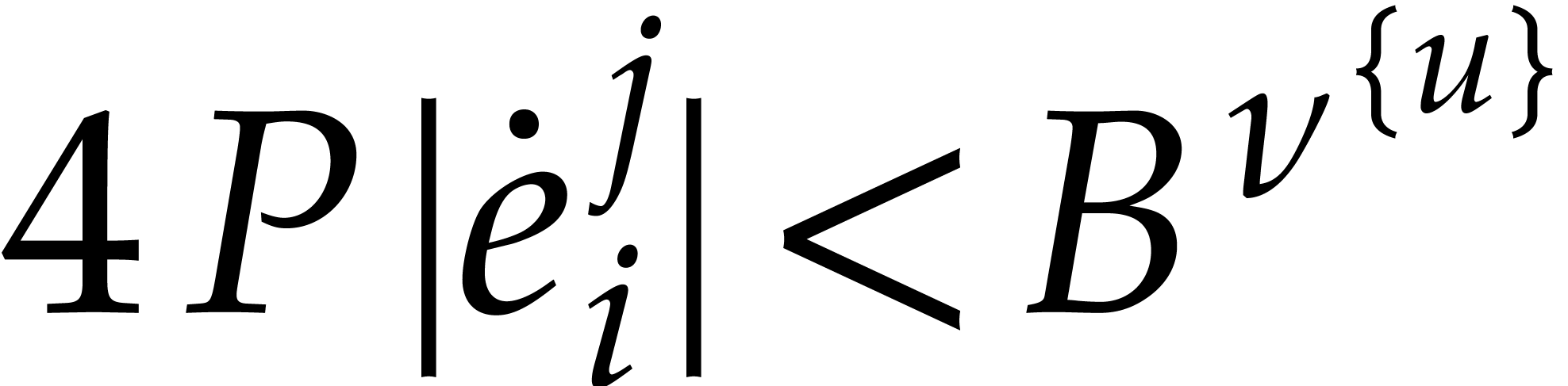 with probability at least
with probability at least
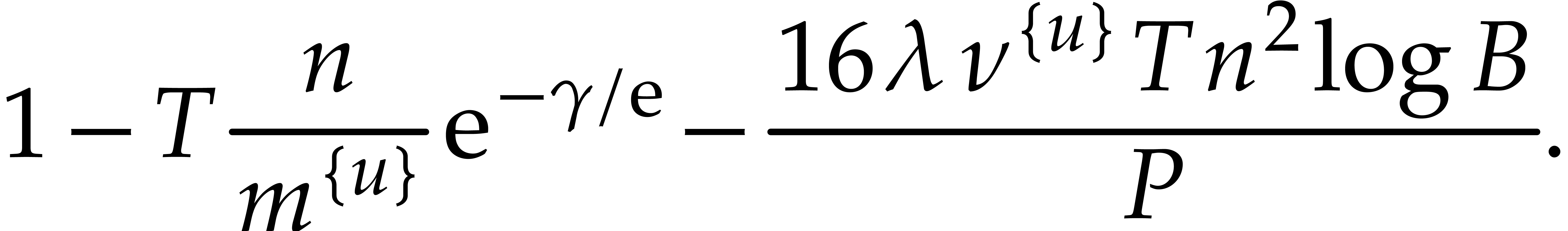
Now we set
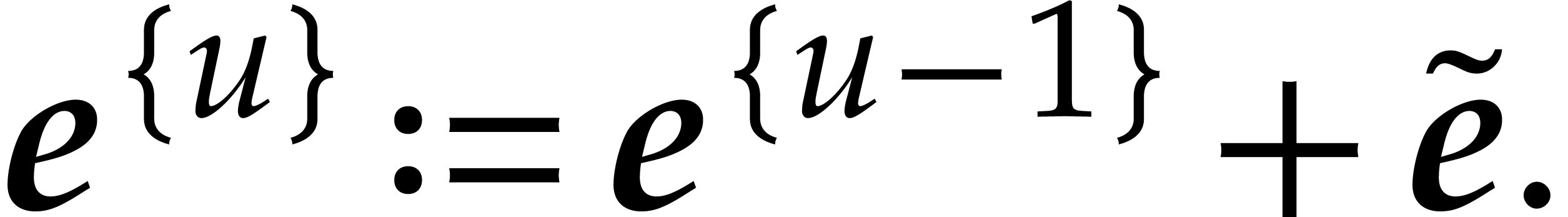 |
(3.11) |
At the end, we return 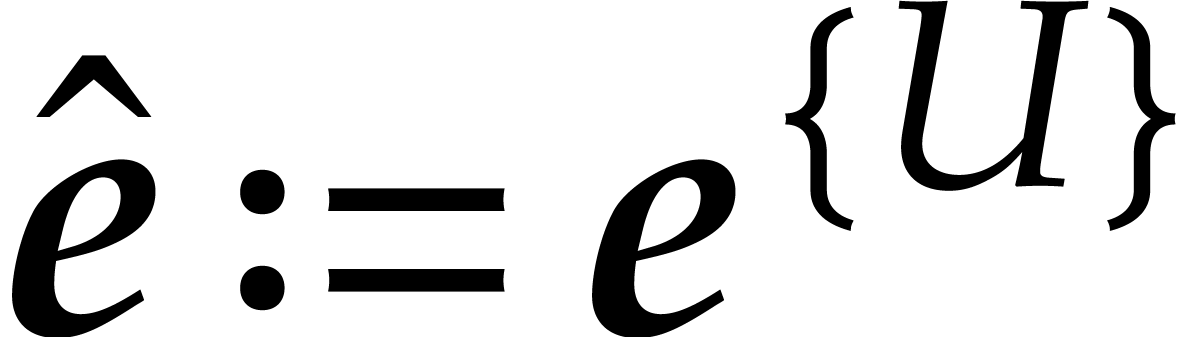 as our guess for . For the analysis of this
algorithm, we first assume that all applications of Lemma 3.8
succeed. Let us show by induction (and with the above definitions of
as our guess for . For the analysis of this
algorithm, we first assume that all applications of Lemma 3.8
succeed. Let us show by induction (and with the above definitions of
 and
and  )
that, for all , , and ,
we have:
)
that, for all , , and ,
we have:
If 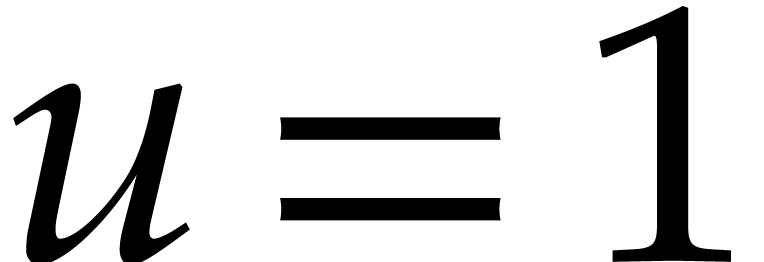 and
and 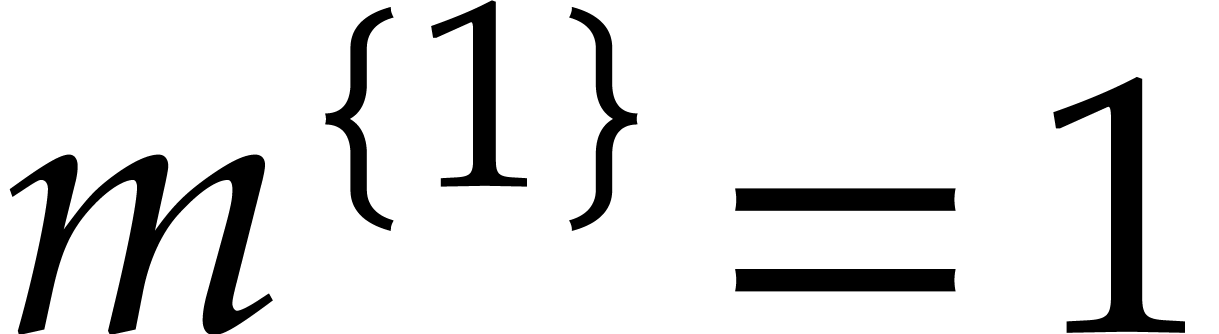 then (i)
clearly holds. If and
then (i)
clearly holds. If and 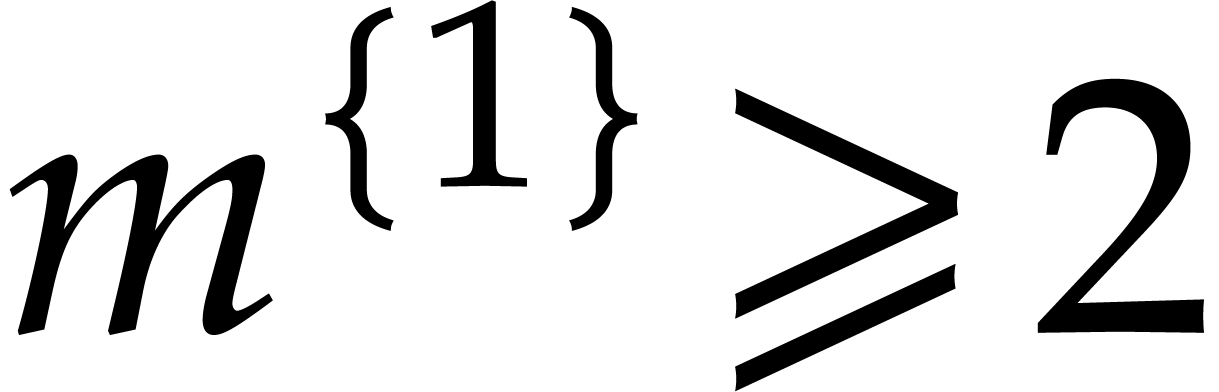 , then
, then 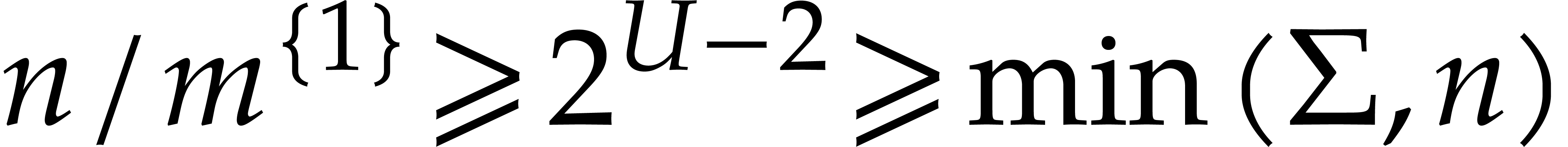 . Since we have . Now we clearly have
. Since we have . Now we clearly have 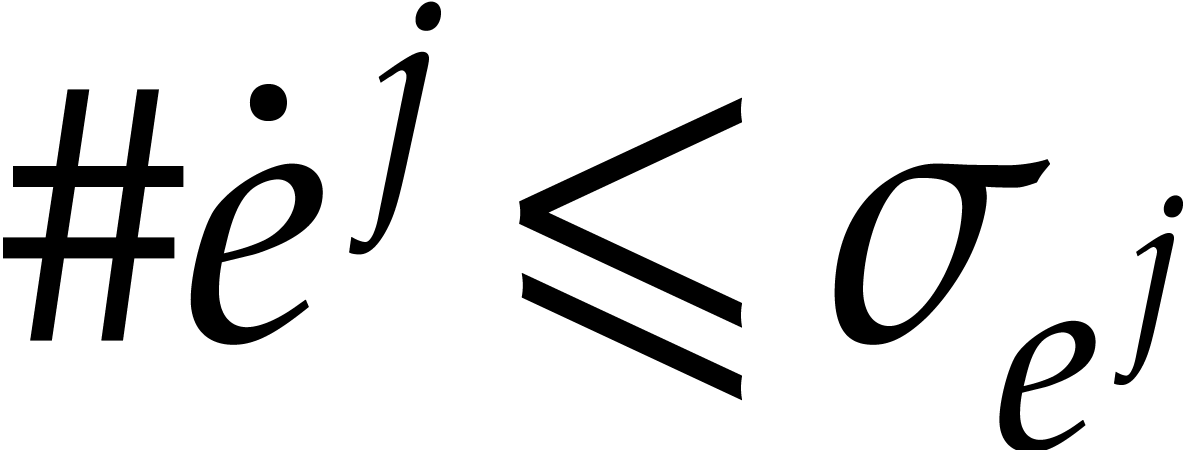 and
and 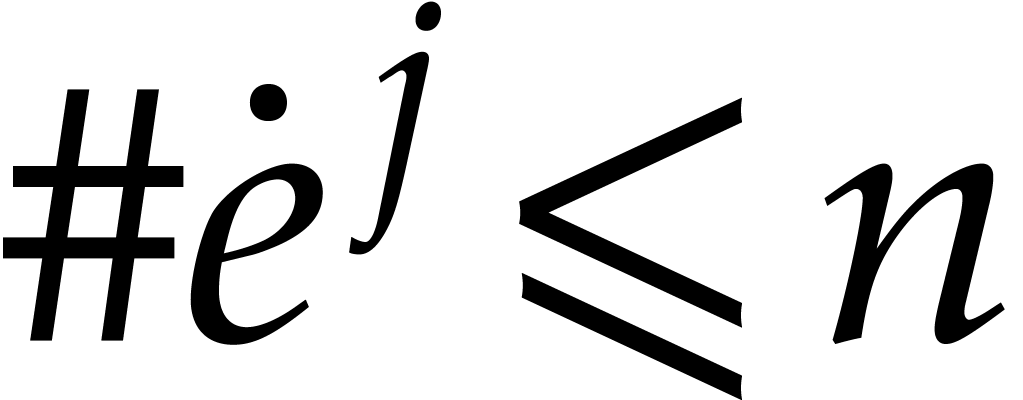 , so (i)
holds.
, so (i)
holds.
If  , then let be such that
, then let be such that 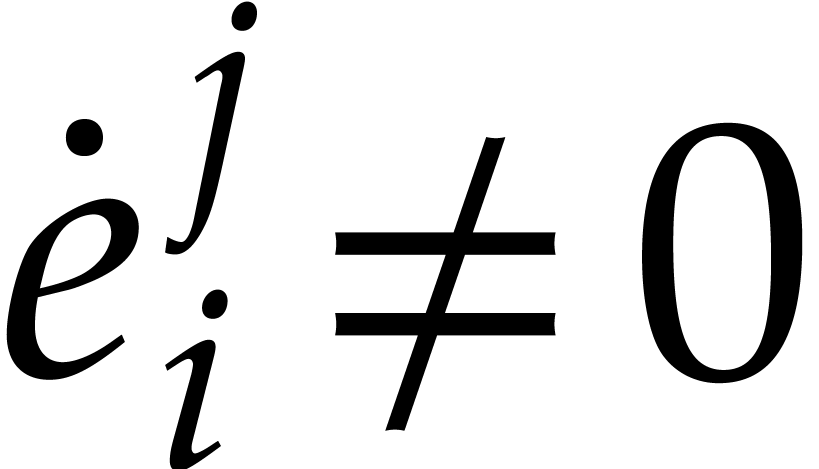 ,
so we have
,
so we have 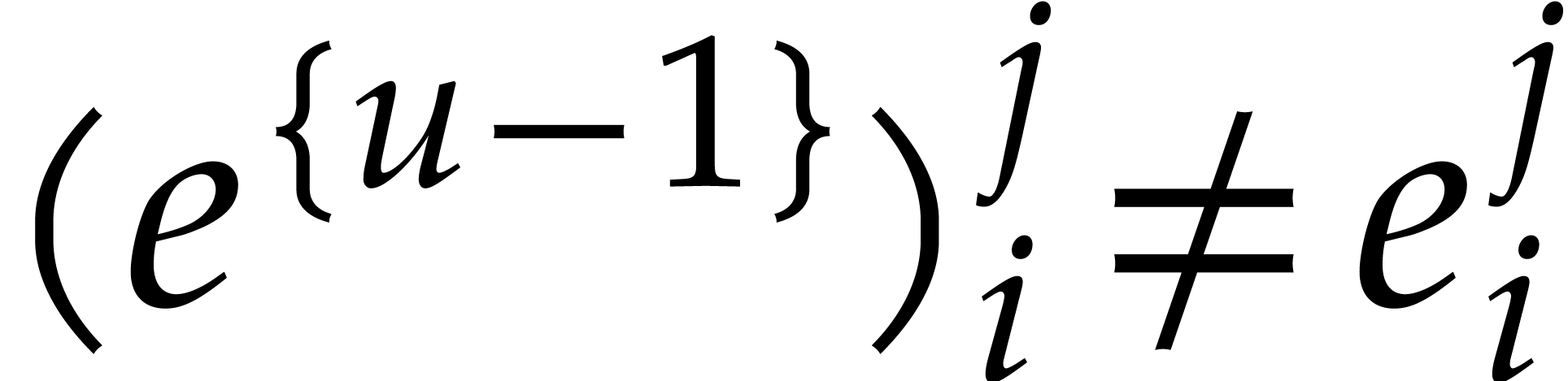 . The induction
hypothesis (iii) and
. The induction
hypothesis (iii) and
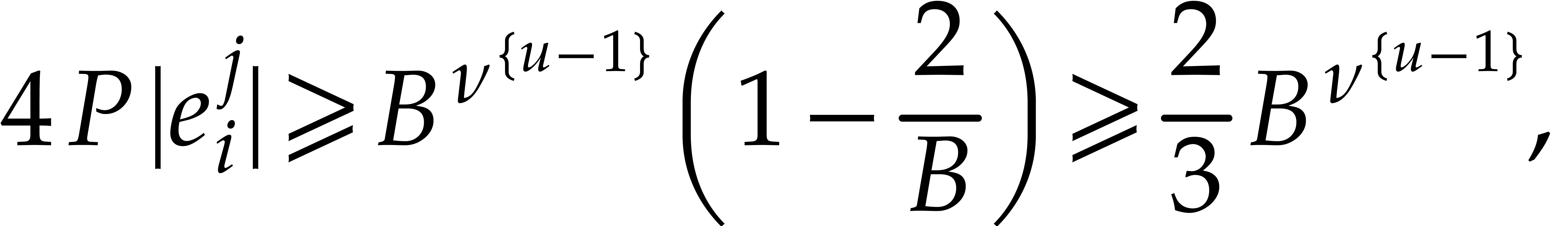
whence 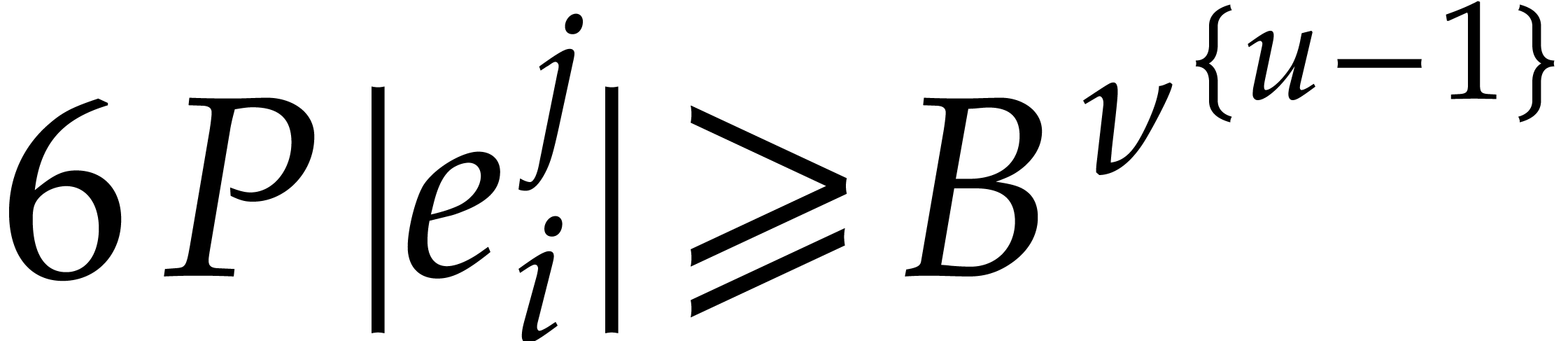 . Consequently,
. Consequently,
Hence the total bit-size of all 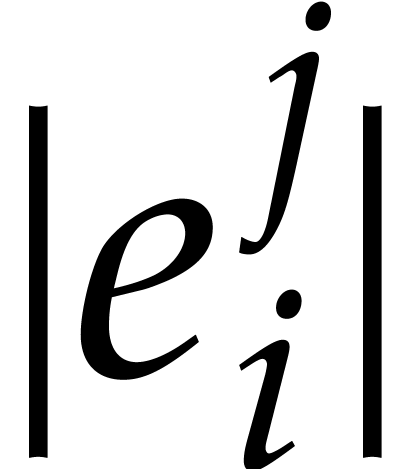 such that is at least
such that is at least  and at most
and at most  by definition of .
This concludes the proof of (i). Now if , then
by definition of .
This concludes the proof of (i). Now if , then  ,
so Lemma 3.8 and (i) imply that . In other words, we obtain an approximation
,
so Lemma 3.8 and (i) imply that . In other words, we obtain an approximation
 of such that
of such that 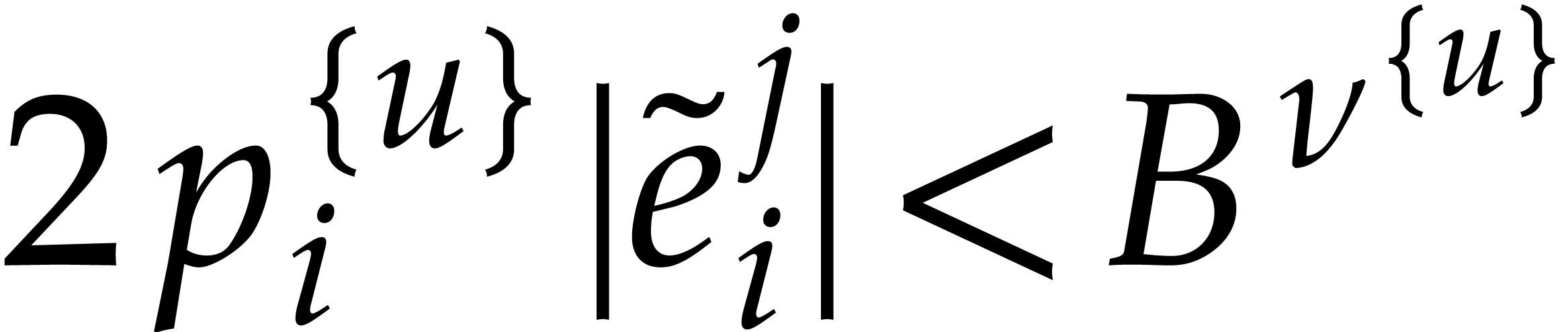 for all
for all 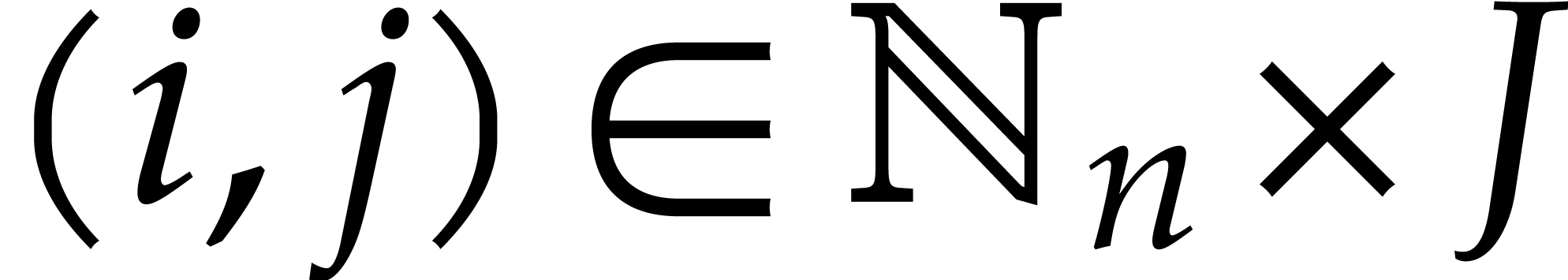 , and
, and
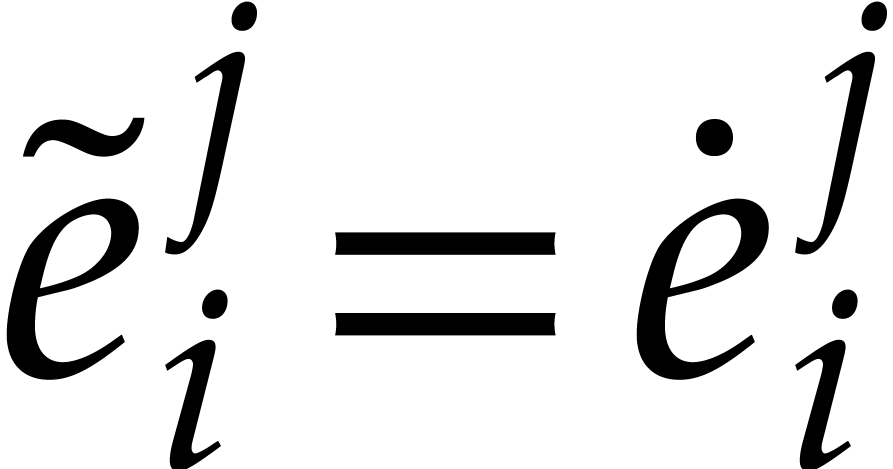 holds whenever .
holds whenever .
Let us prove (ii). If ,
then 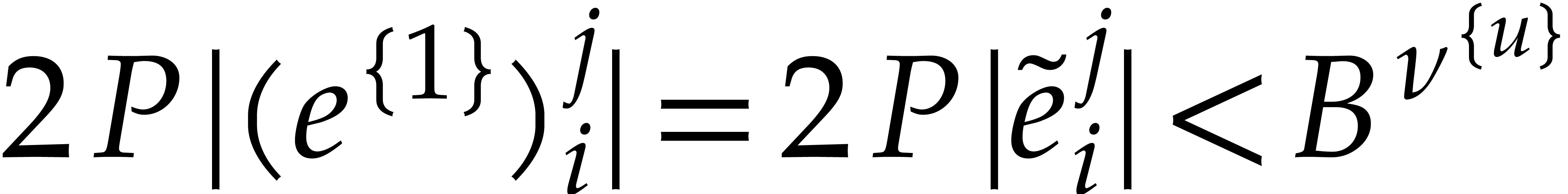 . If , then
. If , then
As to (iii), assume that 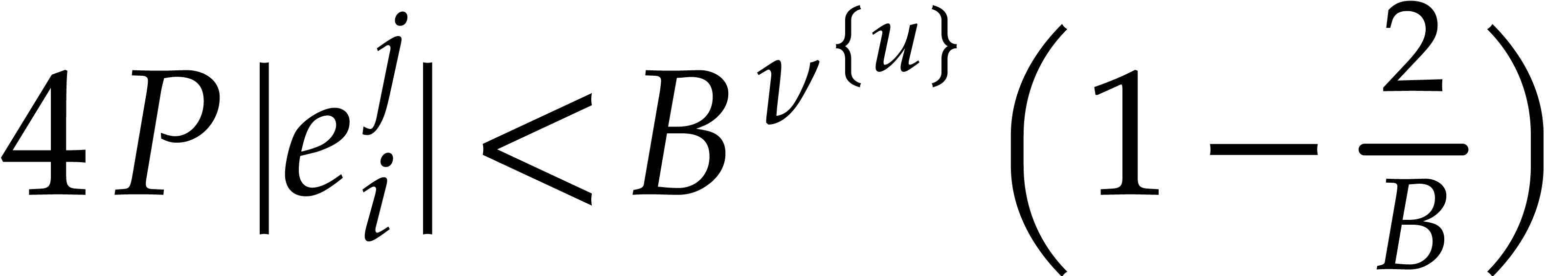 .
If , then
.
If , then 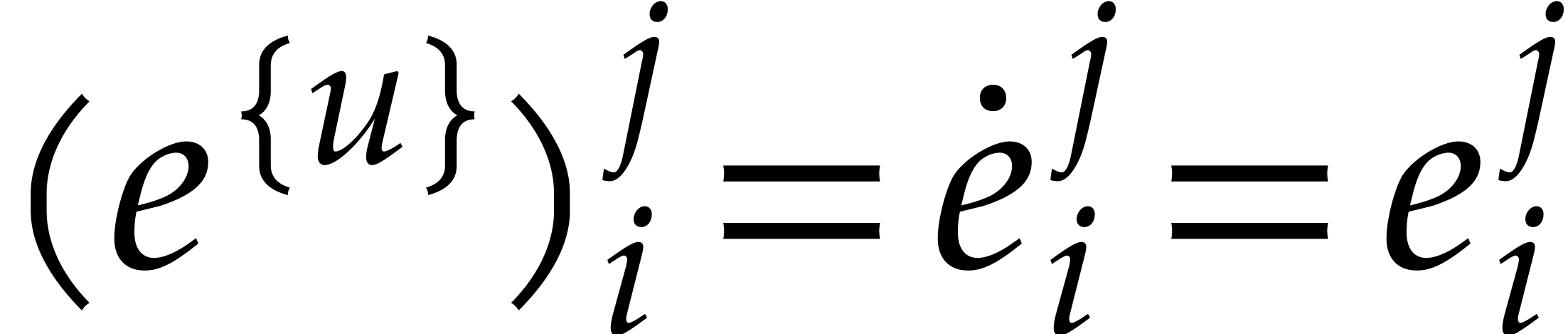 is immediate. If , then the
induction hypothesis (ii) yields
is immediate. If , then the
induction hypothesis (ii) yields 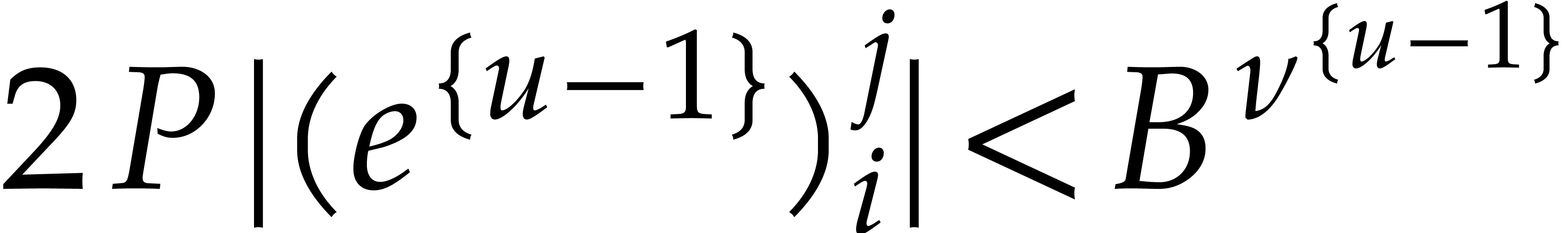 , whence
, whence
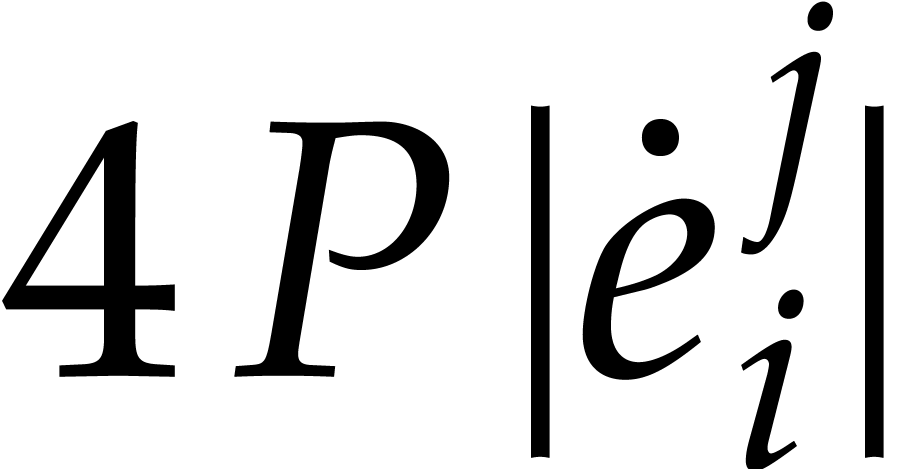 |
|
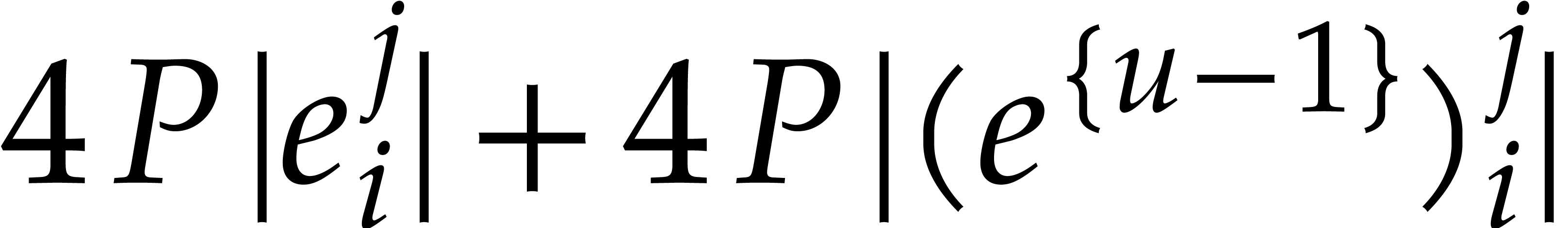 |
|
 |
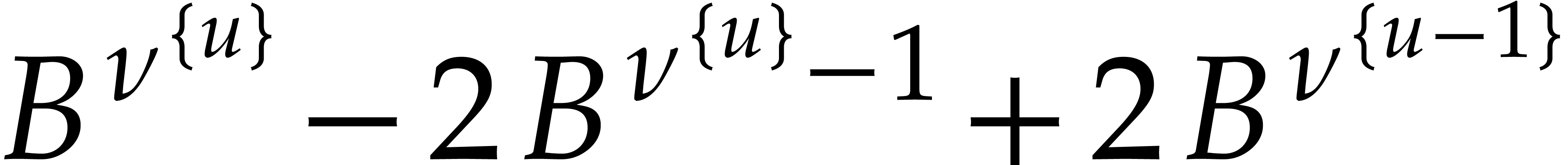 |
||
|
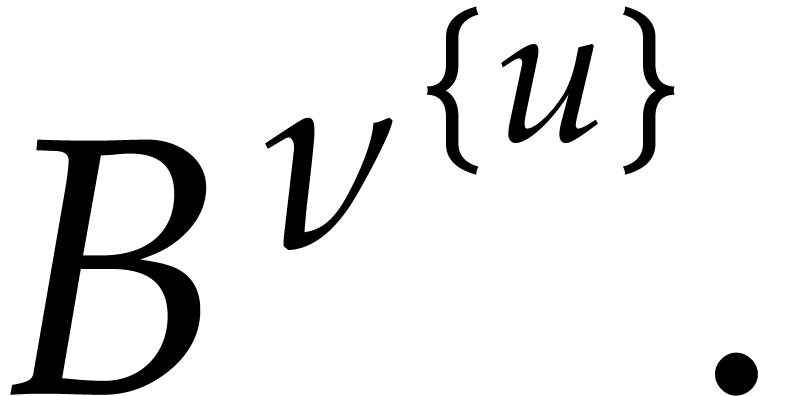 |
(by (3.9)) |
We deduce that holds, hence
At the end of the induction, we have 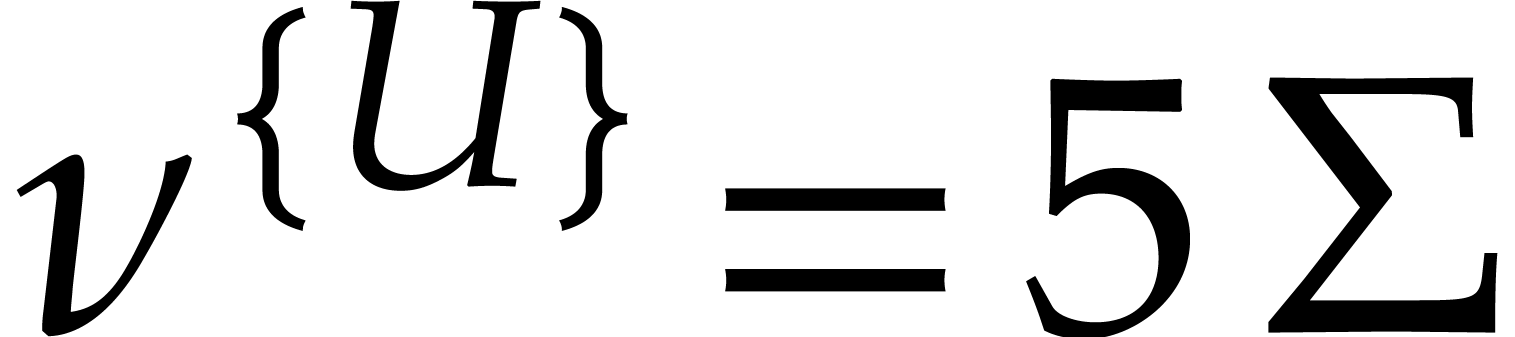 and, for
all ,
and, for
all ,
By (iii) and
As to the complexity bound, Lemma 3.9 shows that 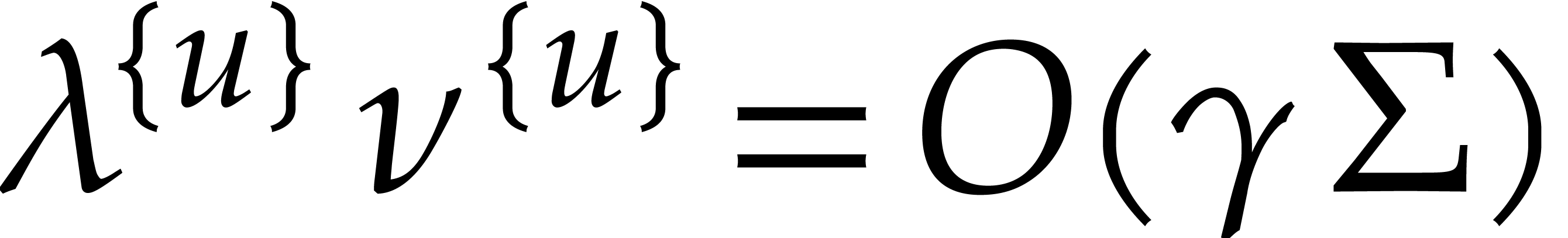 , when applying Lemma 3.8.
Consequently, the cost of all these applications for
is bounded by
, when applying Lemma 3.8.
Consequently, the cost of all these applications for
is bounded by
since 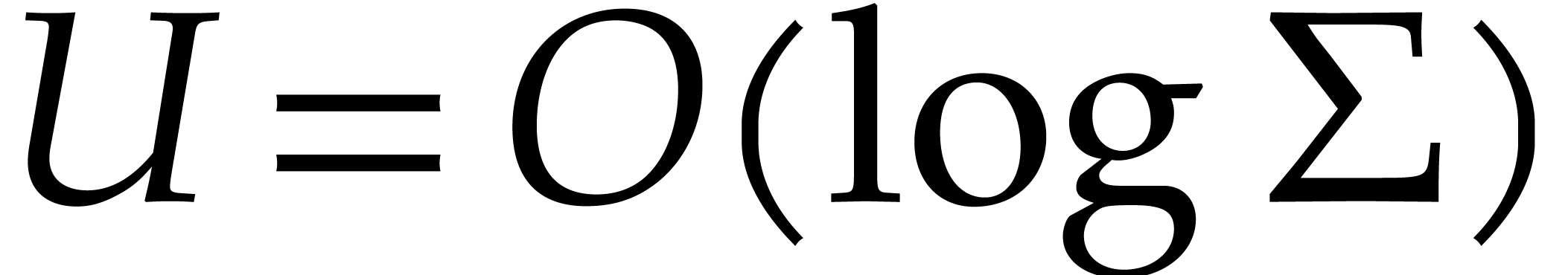 . The cost of the
evaluations of
. The cost of the
evaluations of 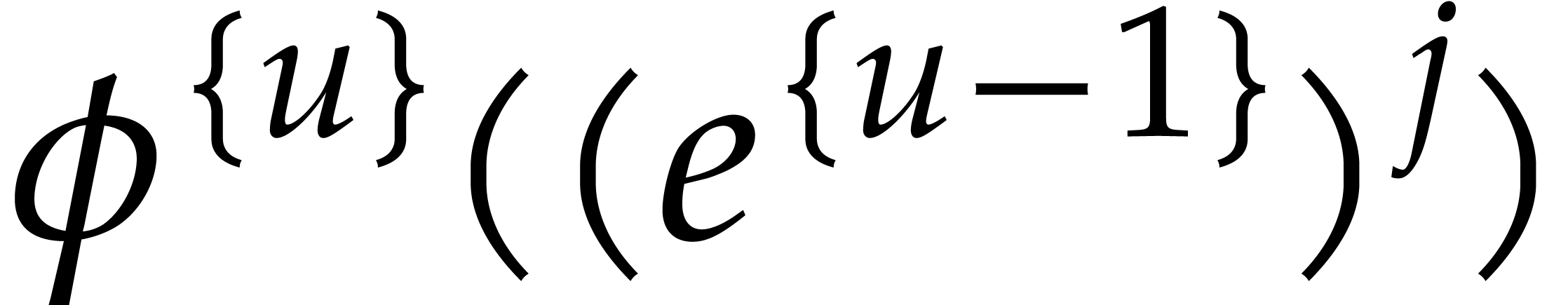 and all further additions,
subtractions, and modular reductions is not more expensive.
and all further additions,
subtractions, and modular reductions is not more expensive.
The bound for the probability of success follows by induction from
Lemmas 3.8 and 3.9, while using the fact that
all and are chosen
independently.
Throughout this section, we assume that is a
modular blackbox polynomial in  with at most terms and of bit-size at most
with at most terms and of bit-size at most 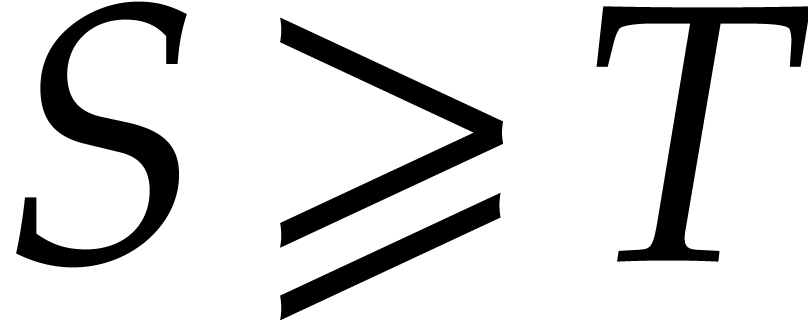 . In order to simplify the cost analyses, it will be
convenient to assume that
. In order to simplify the cost analyses, it will be
convenient to assume that
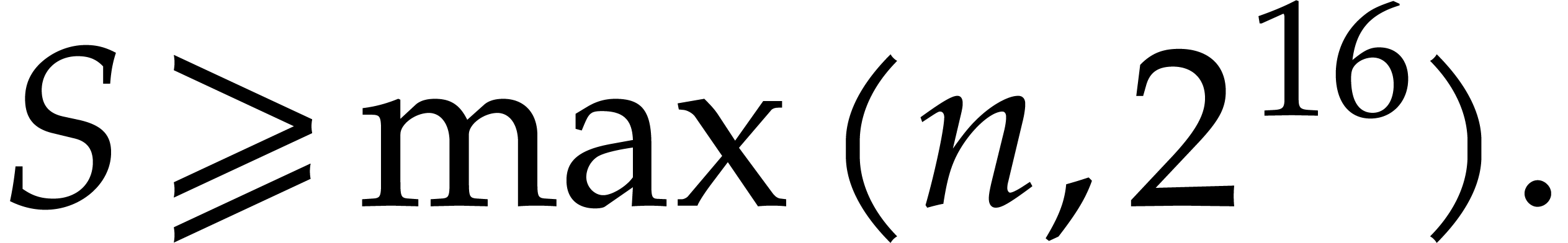
Our main goal is to interpolate .
From now on  will stand for the actual number of
non-zero terms in the sparse representation of .
will stand for the actual number of
non-zero terms in the sparse representation of .
Our strategy is based on the computation of increasingly good
approximations of the interpolation of ,
as in [3], for instance. The idea is to determine an
approximation  of ,
such that
of ,
such that 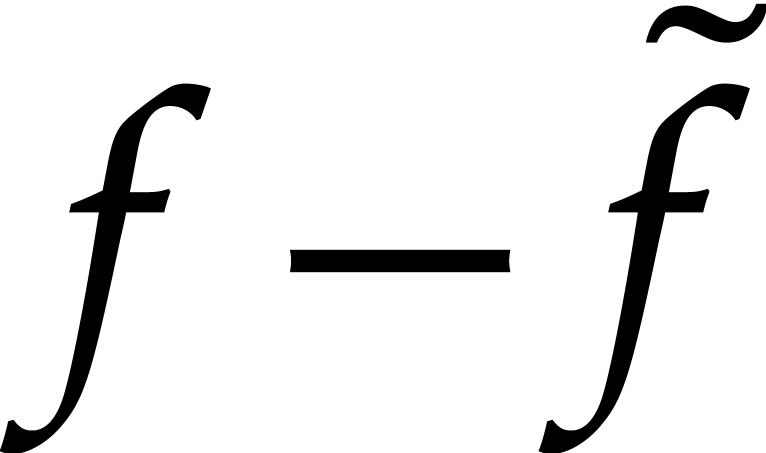 contains roughly half the number of
terms as , and then to
recursively re-run the same algorithm for
contains roughly half the number of
terms as , and then to
recursively re-run the same algorithm for 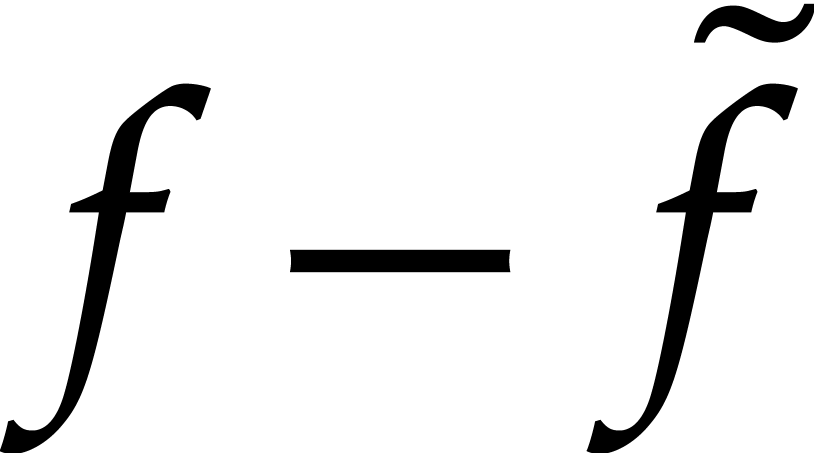 instead of . Our first
approximation will only contain terms of small bit-size. During later
iterations, we will include terms of larger and larger bit-sizes.
instead of . Our first
approximation will only contain terms of small bit-size. During later
iterations, we will include terms of larger and larger bit-sizes.
Throughout this section, we set
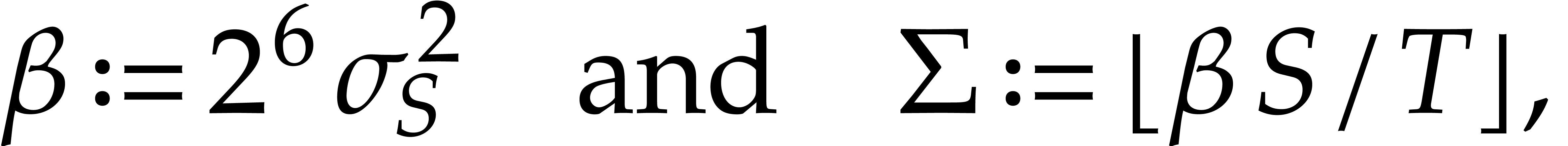 |
(4.1) |
so that at most 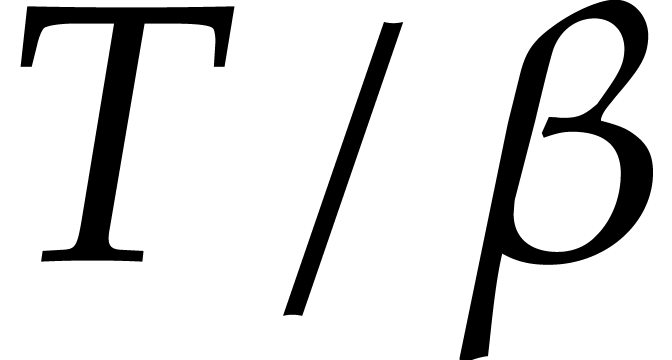 of the terms of
have size
of the terms of
have size  . Our main
technical aim will be to determine at least
. Our main
technical aim will be to determine at least 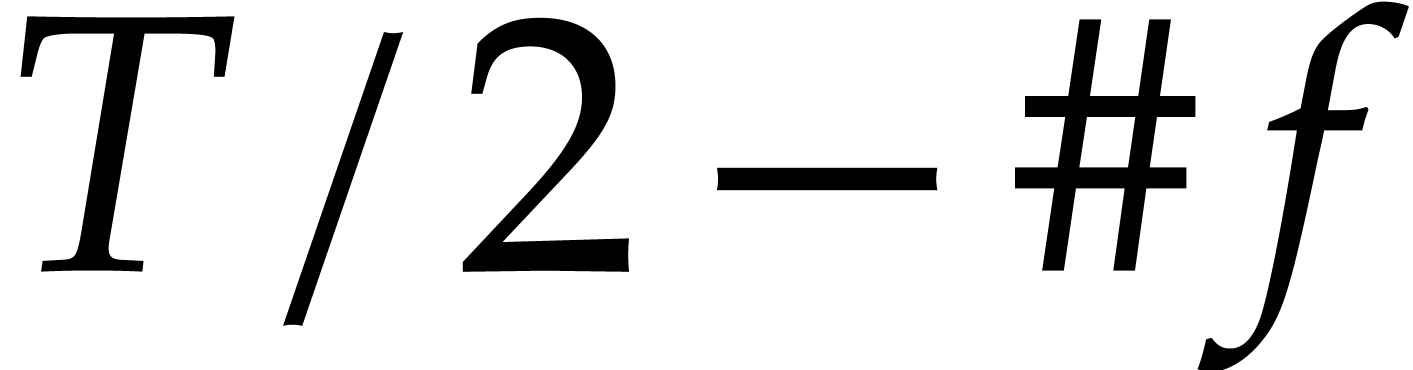 terms of of size ,
with high probability.
terms of of size ,
with high probability.
Our interpolation algorithm is based on an extension of the univariate
approach from [17]. One first key ingredient is to
homomorphically project the polynomial to an
element of 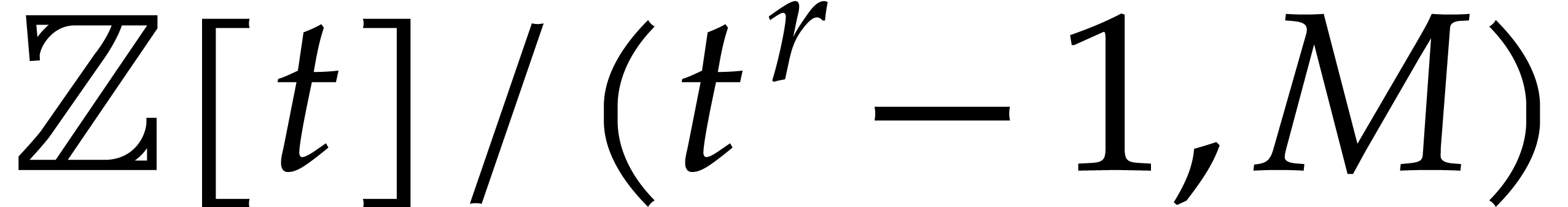 for a suitable cycle length
for a suitable cycle length 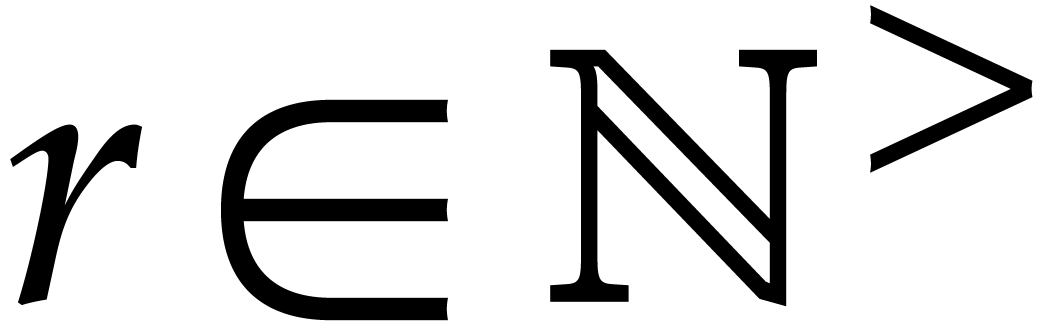 and a suitable modulus
and a suitable modulus 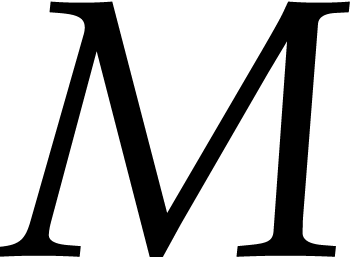 (of the
form
(of the
form 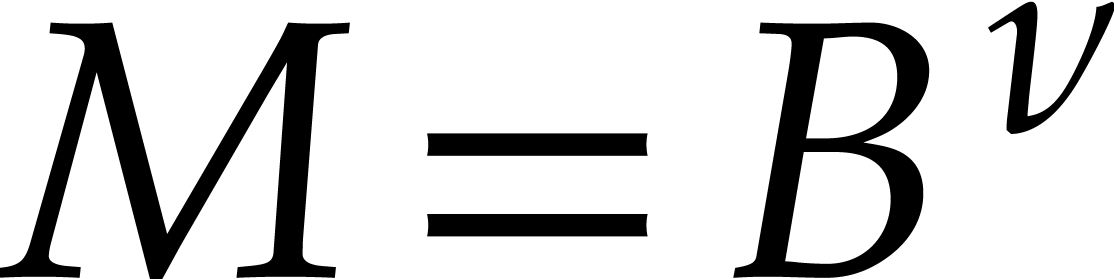 , where
is as in the previous section and
, where
is as in the previous section and 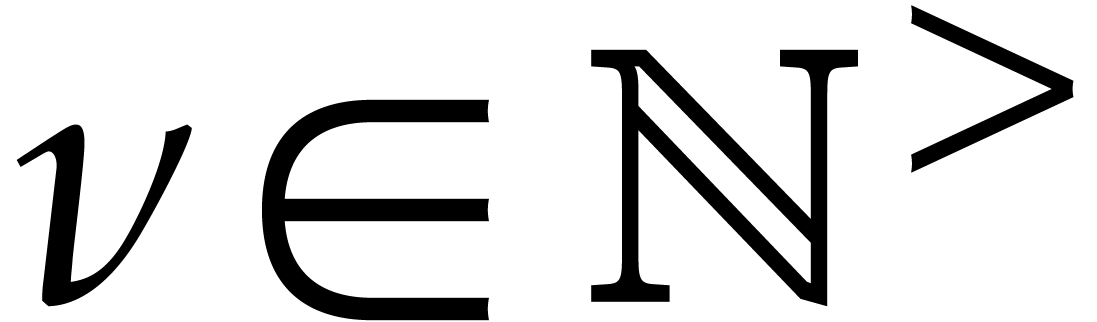 ).
).
More precisely, we fix
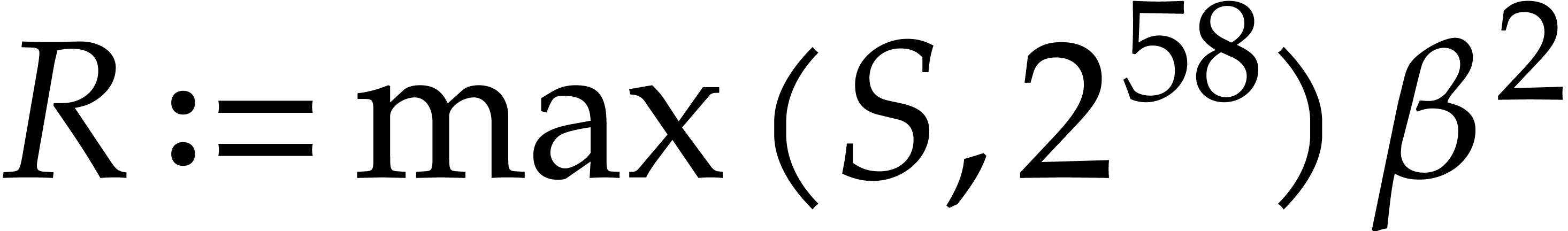 |
(4.2) |
and compute  as in Theorem 2.5. Now
let
as in Theorem 2.5. Now
let  be random elements of
be random elements of 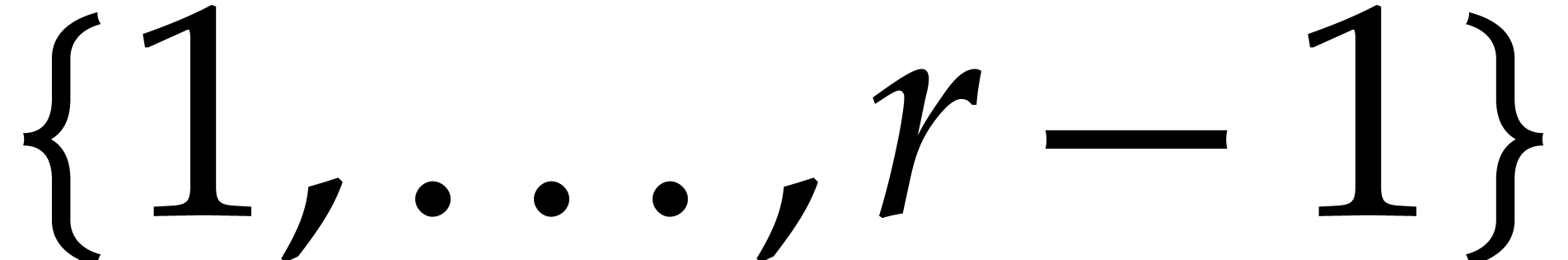 , and consider the map
, and consider the map
We call 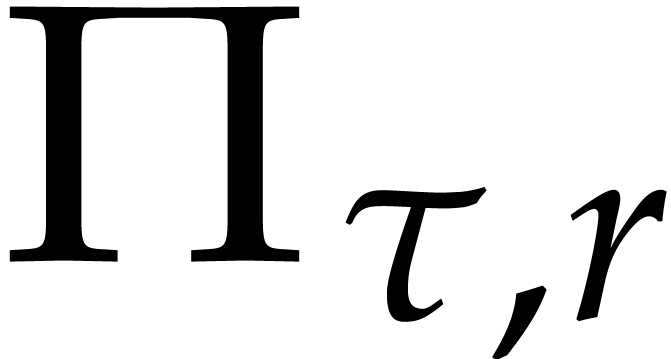 a cyclic projection.
a cyclic projection.
Proof. Given  ,
let
,
let 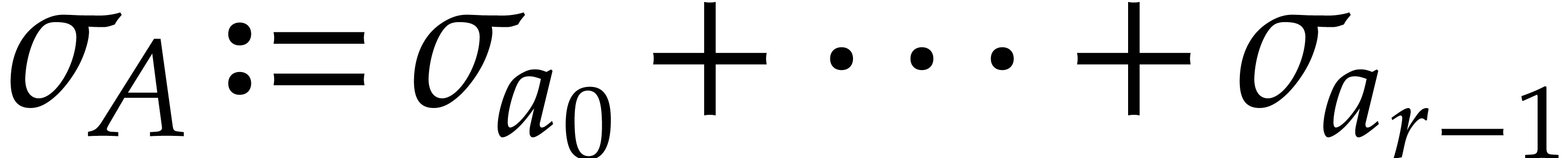 and
and 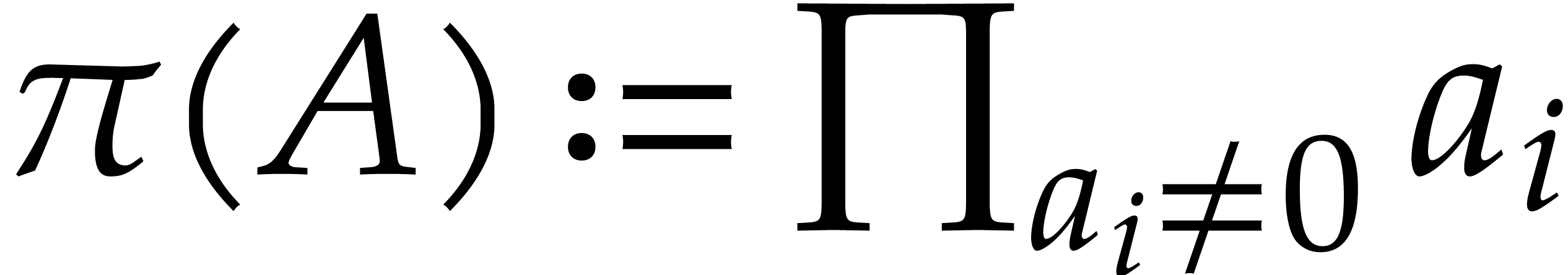 .
Note that
.
Note that 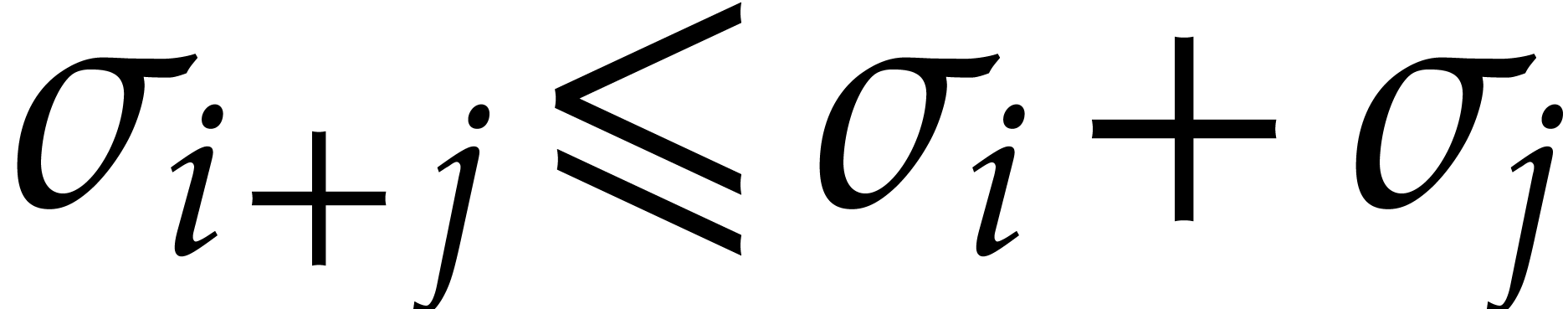 and
and 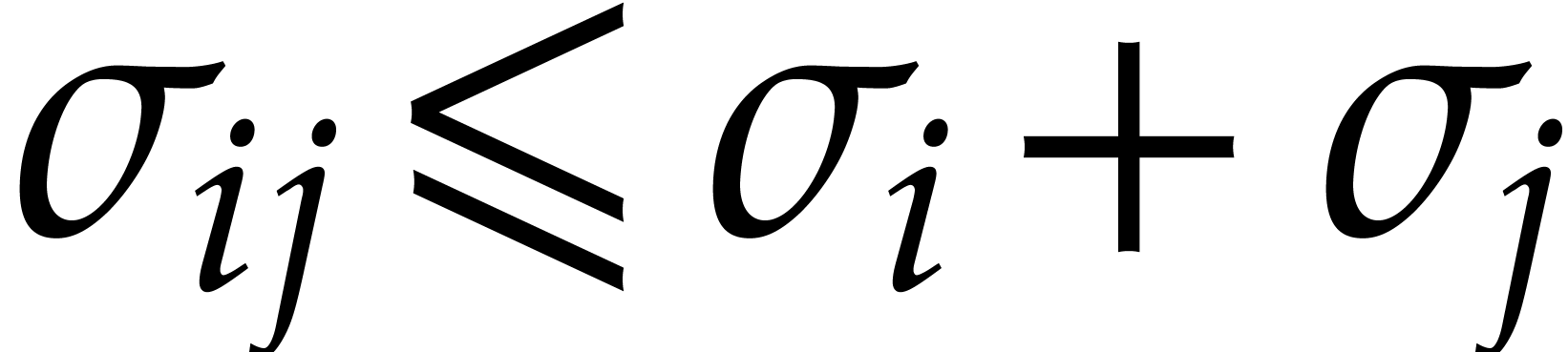 for any
for any
 . The first inequality yields
. The first inequality yields
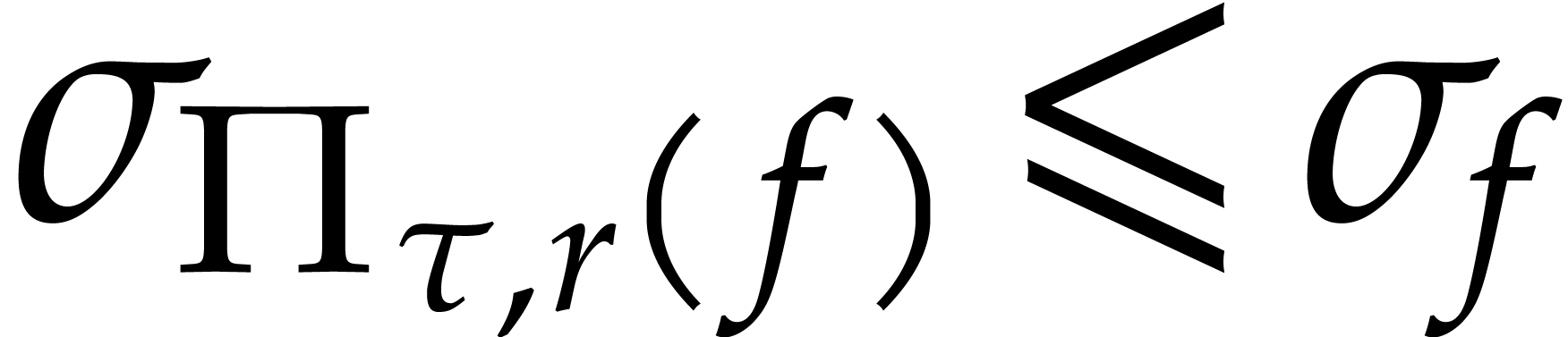 , whereas the second one
implies
, whereas the second one
implies 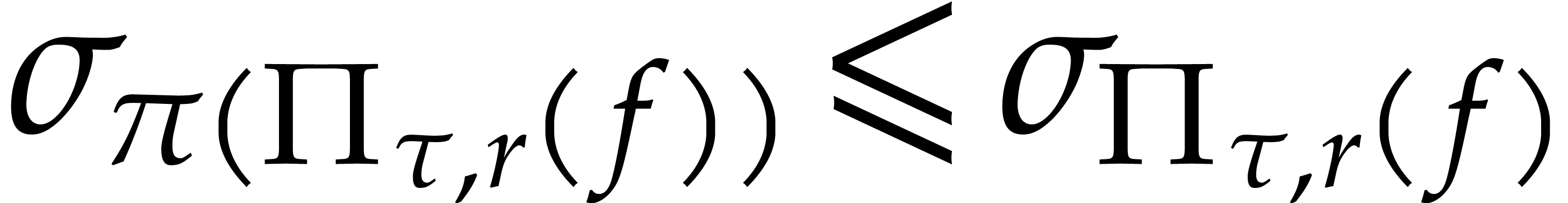 .
.
Given a modulus  , we also
define
, we also
define
and call 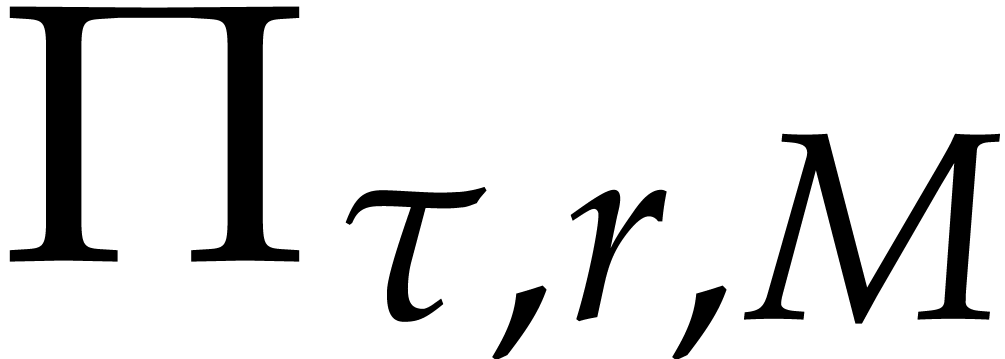 a cyclic modular projection.
a cyclic modular projection.
If 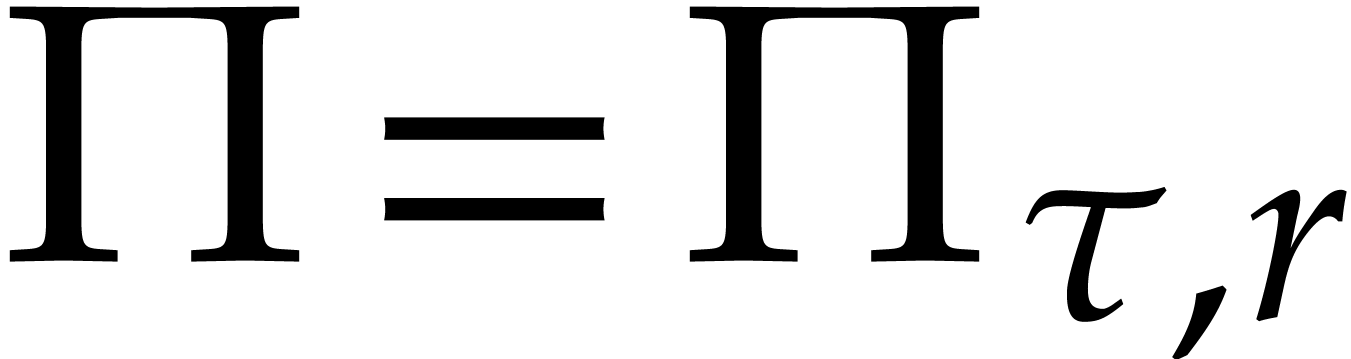 , then we say that a term
, then we say that a term
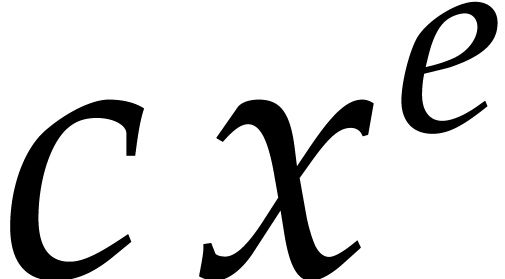 of and the corresponding
exponent are
of and the corresponding
exponent are  -faithful
if there is no other term
-faithful
if there is no other term 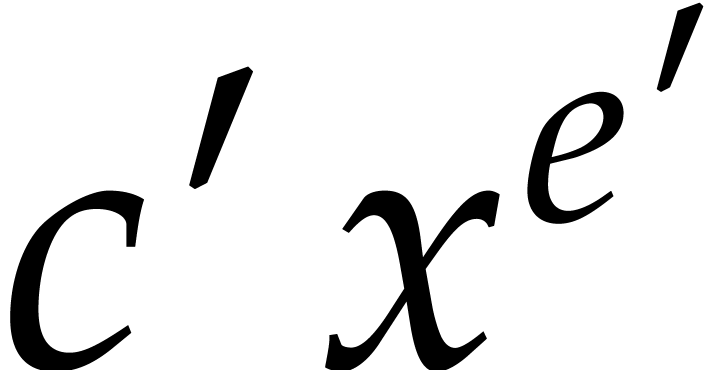 of
such that
of
such that 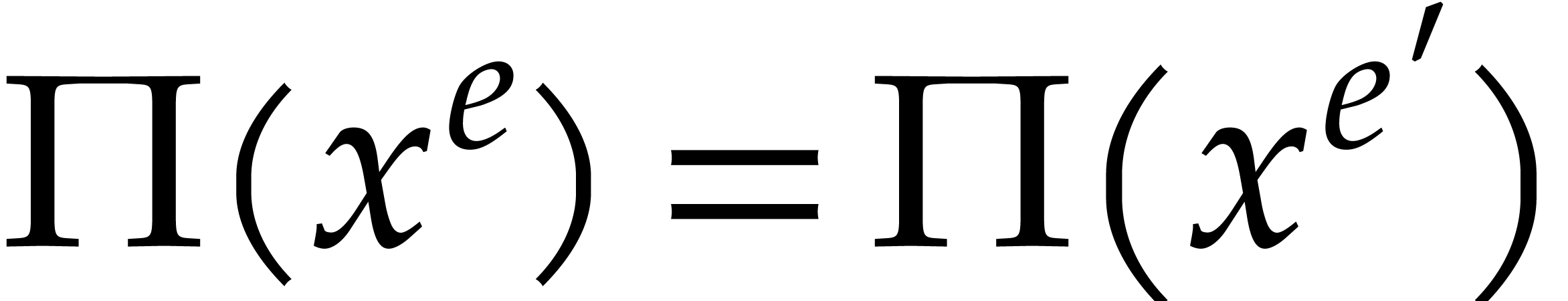 . If
. If  , then we define -faithfulness
in the same way, while requiring in addition that
, then we define -faithfulness
in the same way, while requiring in addition that  be invertible modulo . For
any
be invertible modulo . For
any  , we note that is -faithful if
and only if is
, we note that is -faithful if
and only if is 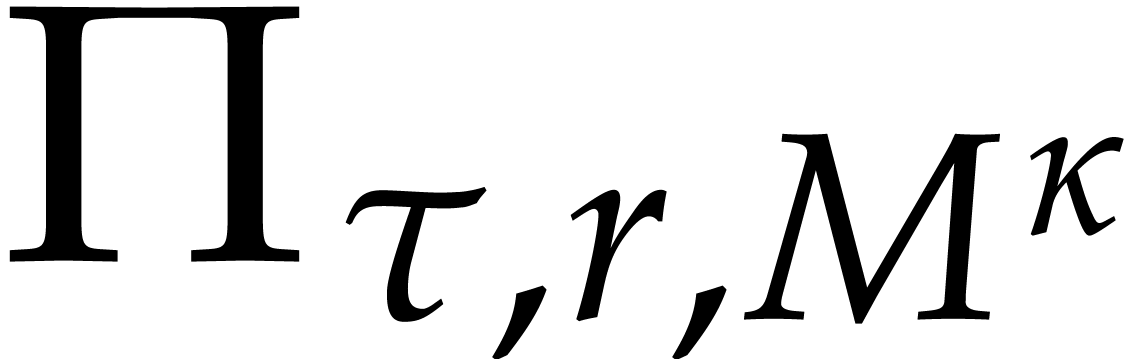 -faithful.
We say that is -faithful
if all its terms are -faithful.
In a similar way, we say that
-faithful.
We say that is -faithful
if all its terms are -faithful.
In a similar way, we say that  is -faithful if
is -faithful if  is
invertible for any non-zero term
is
invertible for any non-zero term 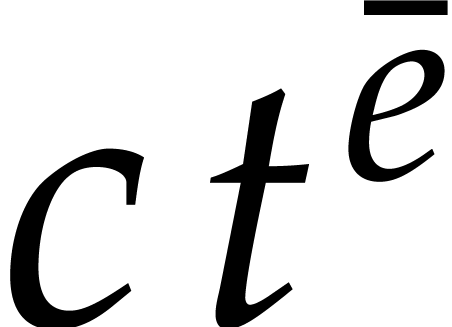 of
of  .
.
The first step of our interpolation algorithm is similar to the one from
[17] and consists of determining the exponents of . Let be a
prime number. If is -faithful, then the exponents of
are precisely those of 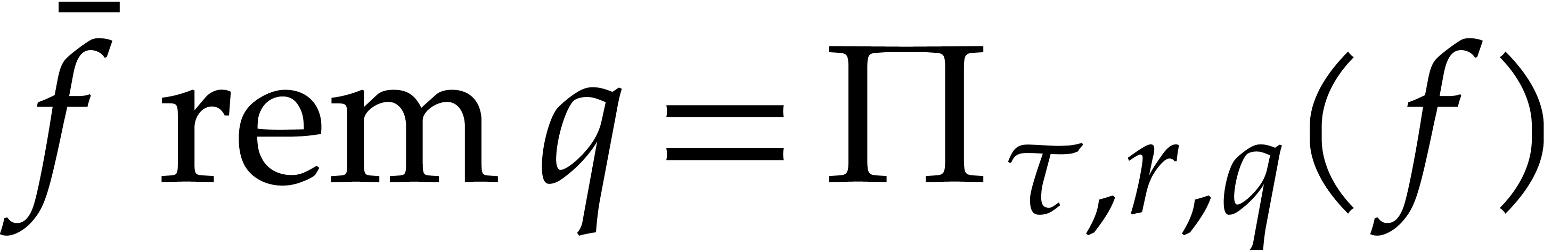 .
.
Proof. We first precompute  in time
in time 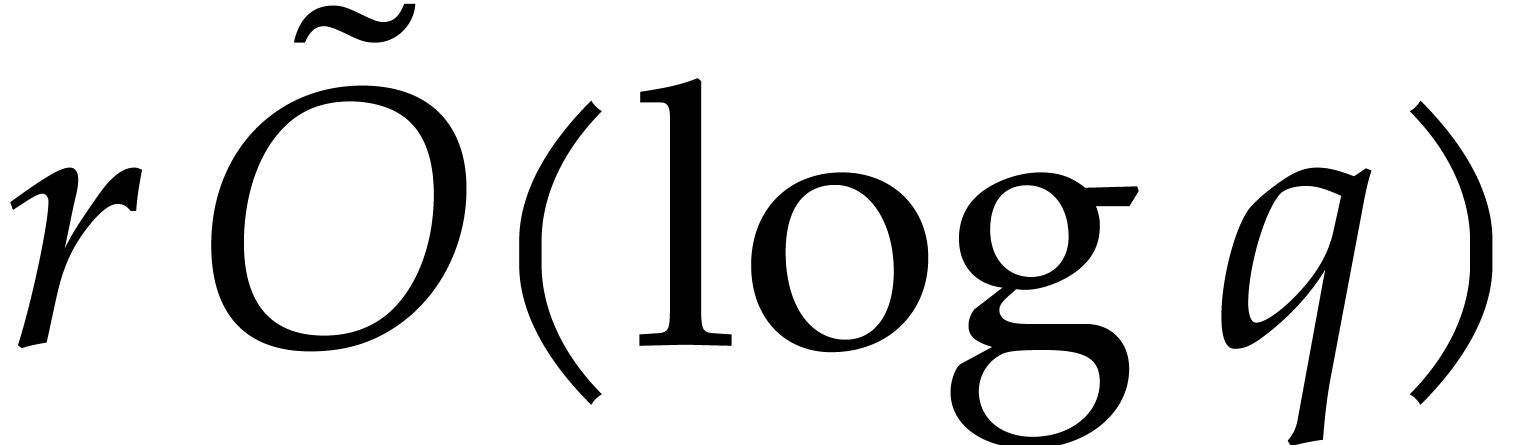 . We compute
. We compute 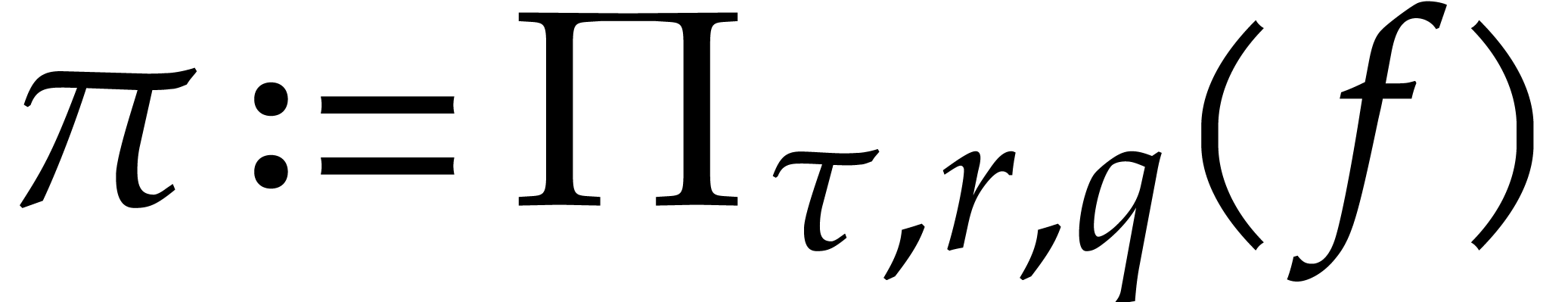 by evaluating
by evaluating 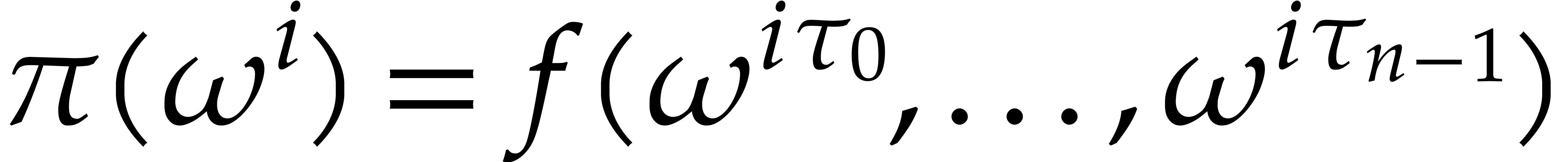 for
for  . This takes
. This takes  bit-operations. We next retrieve
bit-operations. We next retrieve  from these
values using an inverse discrete Fourier transform (DFT) of order
from these
values using an inverse discrete Fourier transform (DFT) of order  . This takes
. This takes 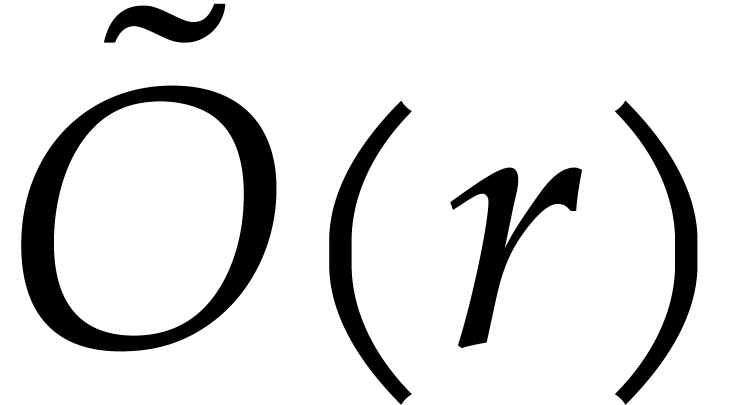 further operations in , using
Bluestein's method [7].
further operations in , using
Bluestein's method [7].
Assuming that is -faithful
and that we know 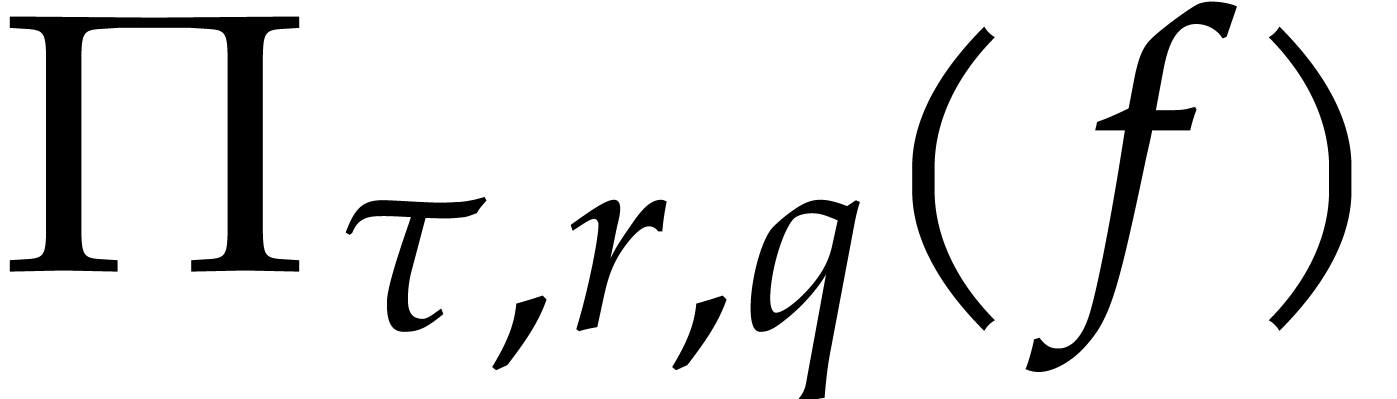 , consider
the computation of
, consider
the computation of 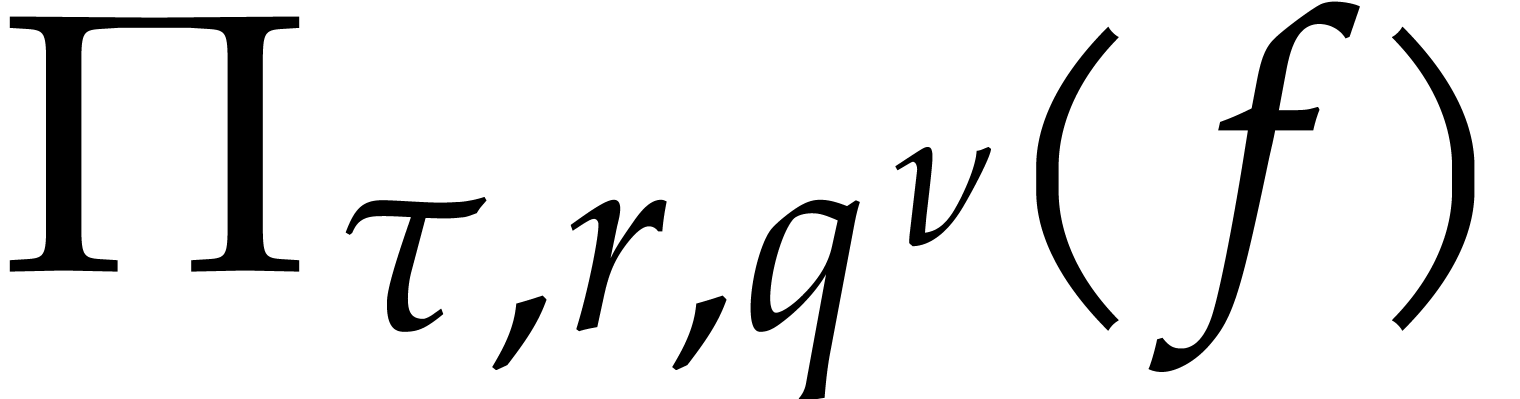 for higher precisions . Now is
also
for higher precisions . Now is
also 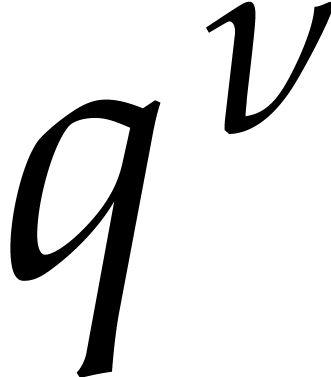 -faithful, so the
exponents of and
coincide. One crucial idea from [17] is to compute using only
-faithful, so the
exponents of and
coincide. One crucial idea from [17] is to compute using only 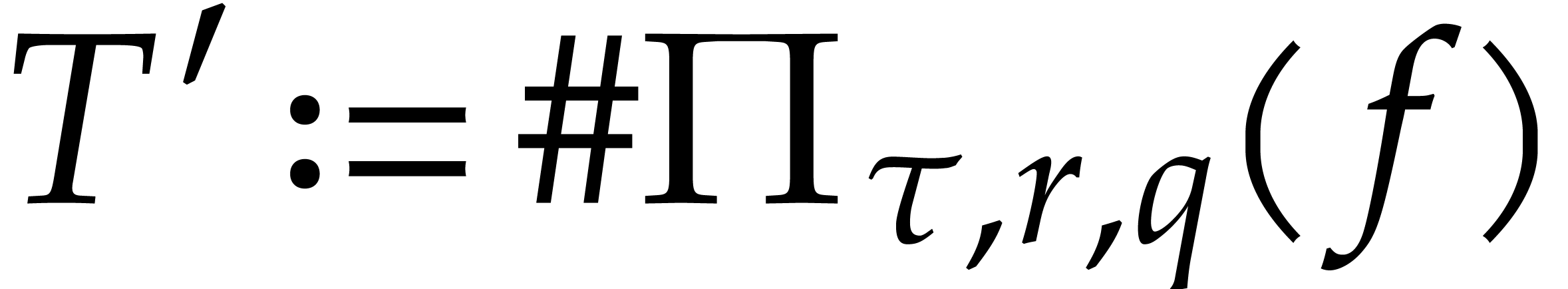 instead of evaluations of modulo . This is the purpose of the next
lemma.
instead of evaluations of modulo . This is the purpose of the next
lemma.
 is -faithful and that is
known. Let
is -faithful and that is
known. Let 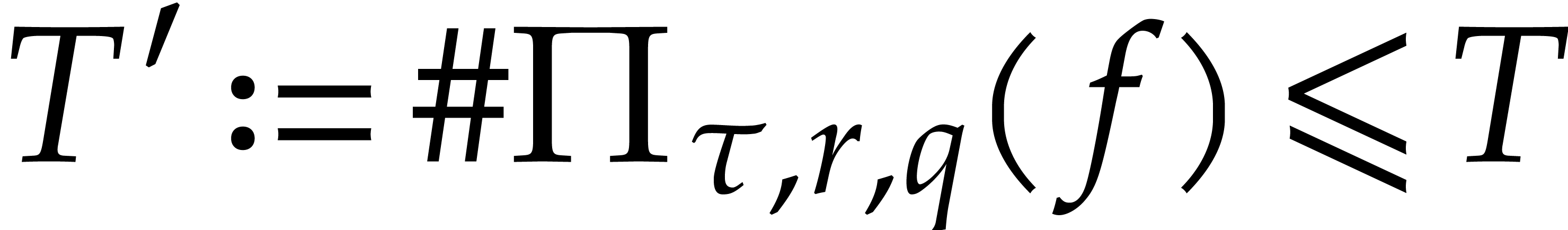 and let
and let  , where
, where  is such that
is such that  for all .
Then we may compute
for all .
Then we may compute  in time
in time
Proof. We first Hensel lift the primitive -th root of unity  in to a principal -th
root of unity
in to a principal -th
root of unity 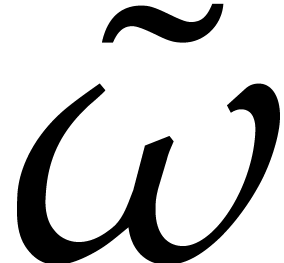 in
in 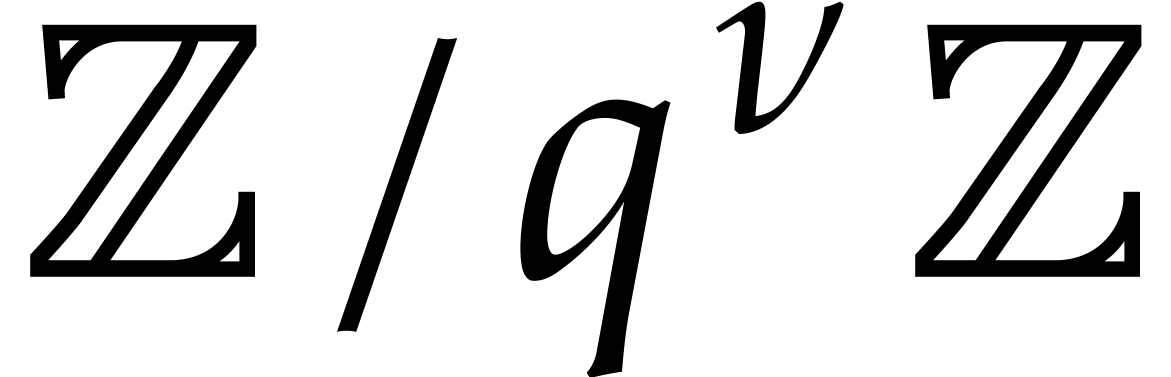 in time
in time
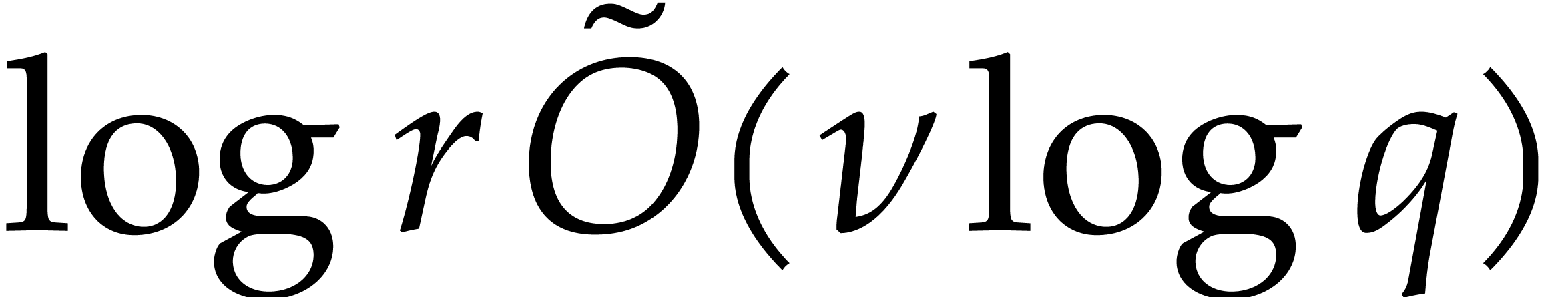 , as detailed in [17,
section 2.2]. We next compute
, as detailed in [17,
section 2.2]. We next compute  in time
in time 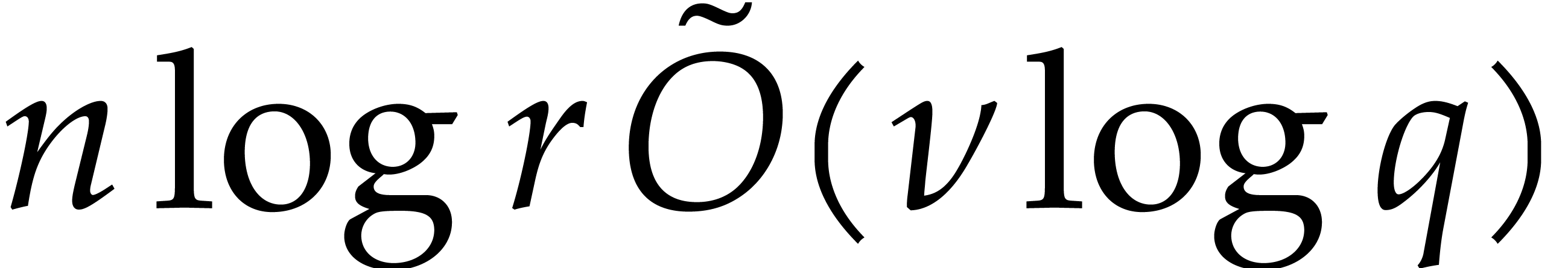 , using binary powering. We pursue
with the evaluations
, using binary powering. We pursue
with the evaluations 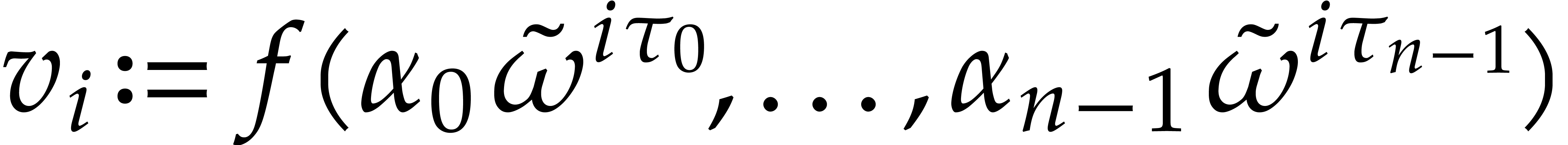 for
for  . This can be done in time
. This can be done in time
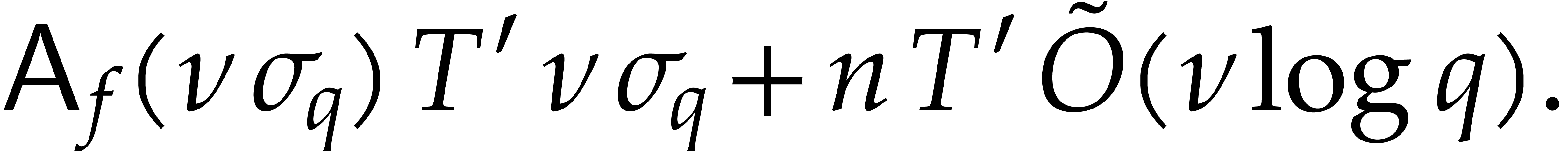
Now the exponents  of are
known, since they coincide with those of ,
and we have the relation
of are
known, since they coincide with those of ,
and we have the relation
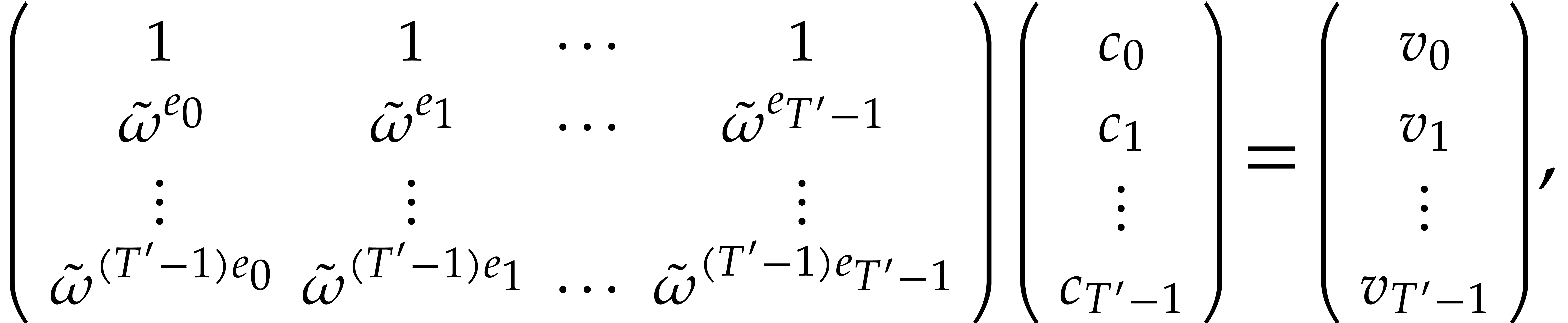
where  denotes the coefficient of
denotes the coefficient of 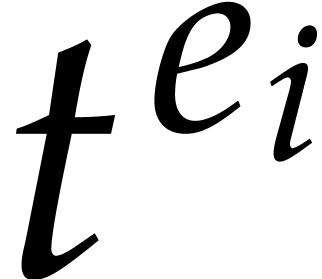 in , for . It is well known that this linear
system can be solved in quasi-linear time
in , for . It is well known that this linear
system can be solved in quasi-linear time 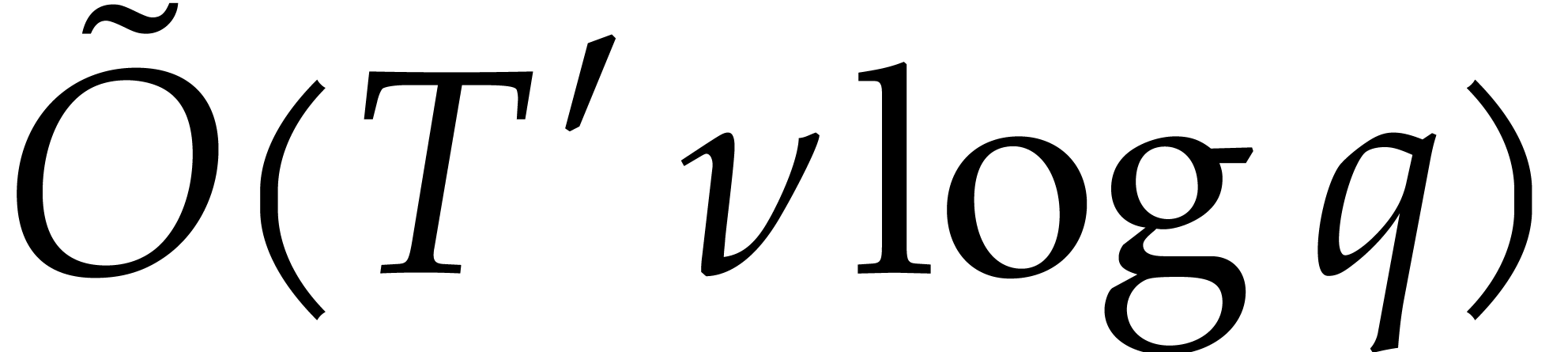 :
in fact this problem reduces to the usual interpolation problem thanks
to the transposition principle [8, 35]; see
for instance [25, section 5.1].
:
in fact this problem reduces to the usual interpolation problem thanks
to the transposition principle [8, 35]; see
for instance [25, section 5.1].
The next lemma is devoted to bounding the probability of picking up
random prime moduli that yield -faithful
projections.
(resp. 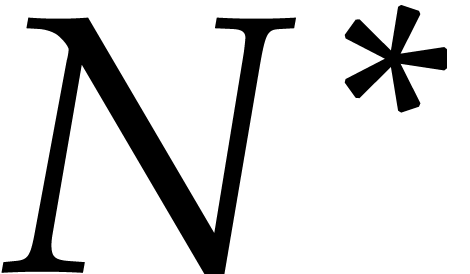 ) be the number of terms (resp.
) be the number of terms (resp.
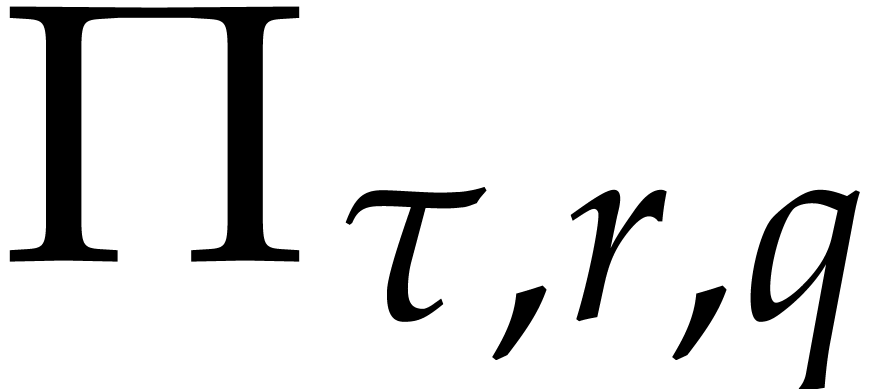 -faithful terms) of of size .
Let the cycle length and the modulus be given as described in Theorem 2.5. If
the are uniformly and independently taken at
random
-faithful terms) of of size .
Let the cycle length and the modulus be given as described in Theorem 2.5. If
the are uniformly and independently taken at
random 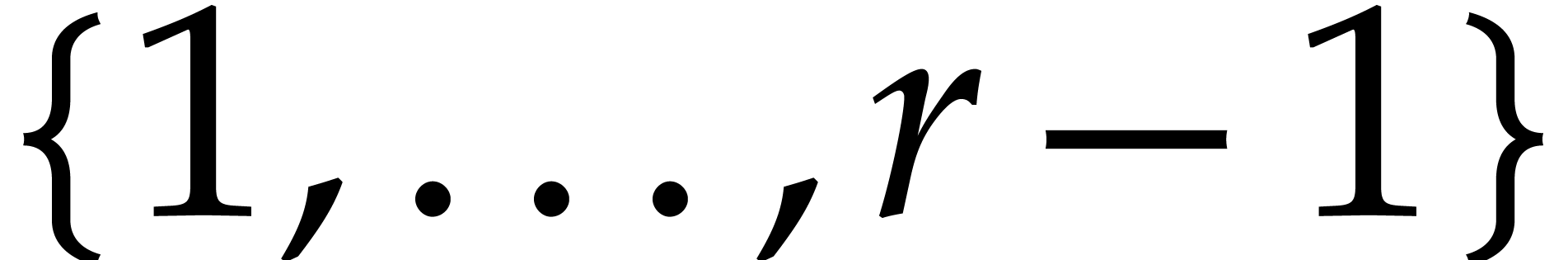 , then, with
probability
, then, with
probability 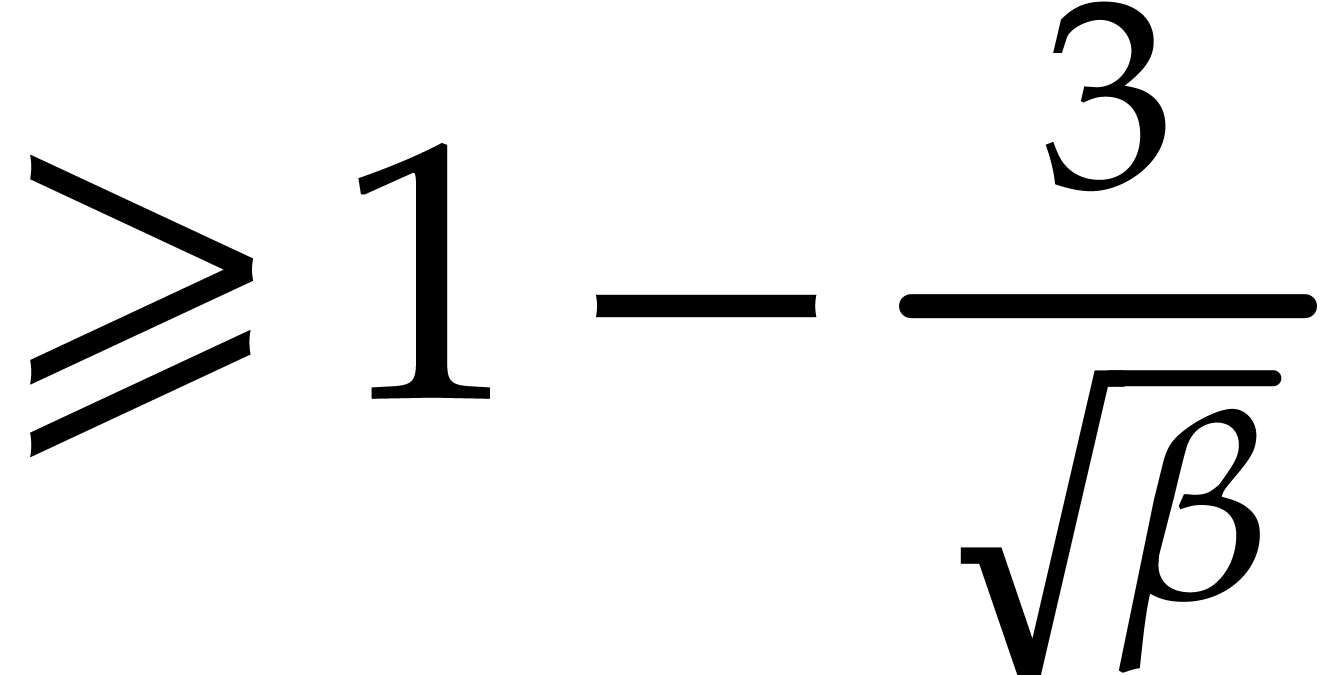 , the
projection is -faithful
and
, the
projection is -faithful
and
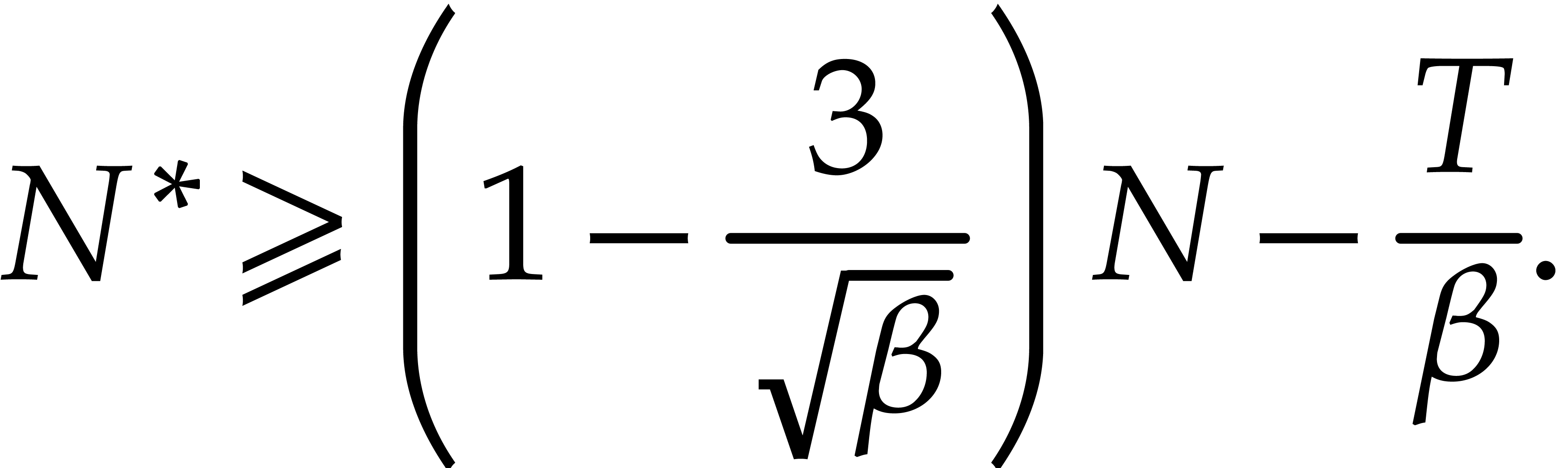
Proof. We let 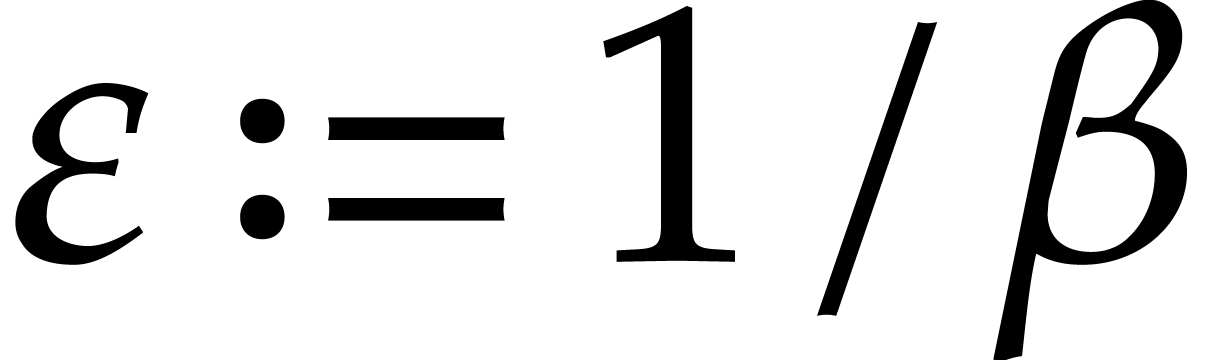 and
and 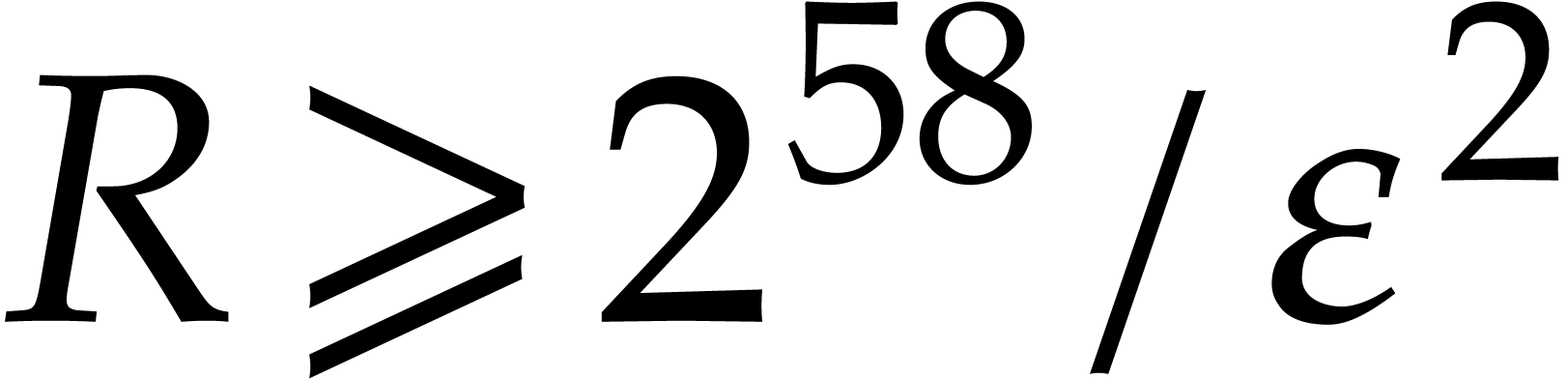 as in
as in 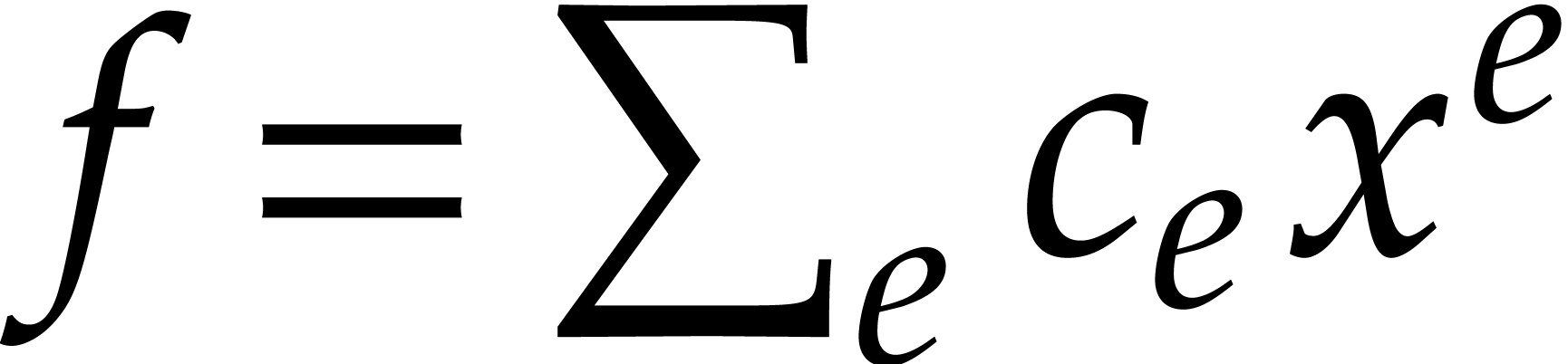 and
and 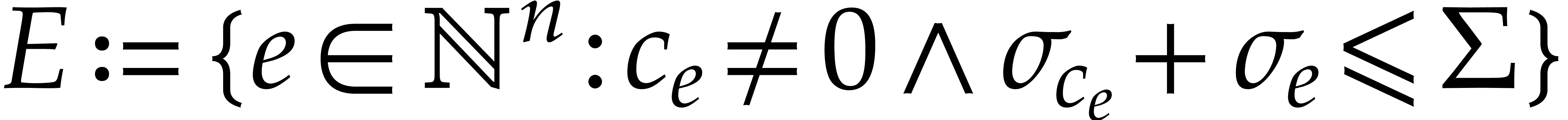 . For any , let
. For any , let
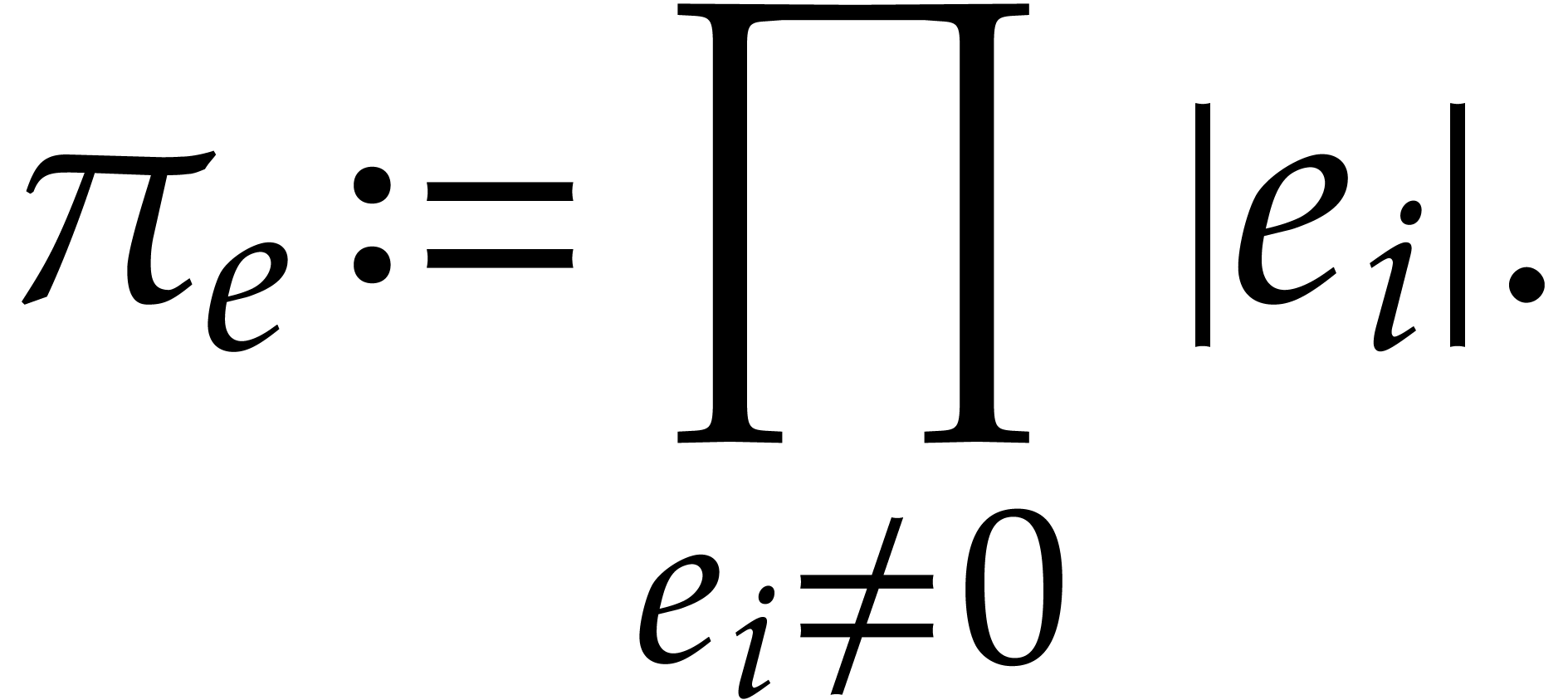
Given  , consider
, consider 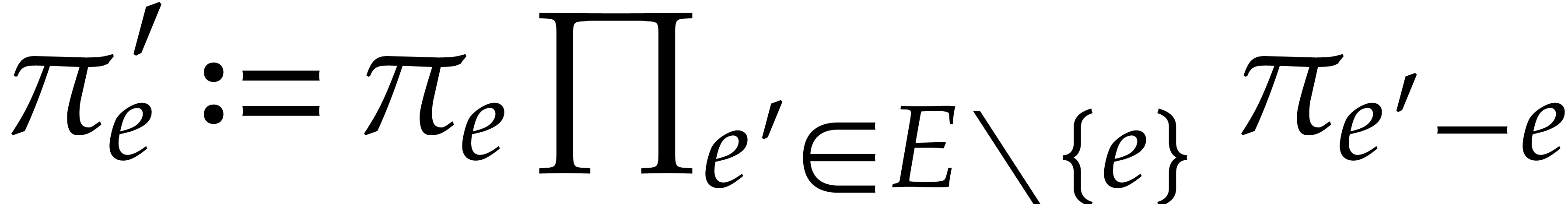 and note that
and note that 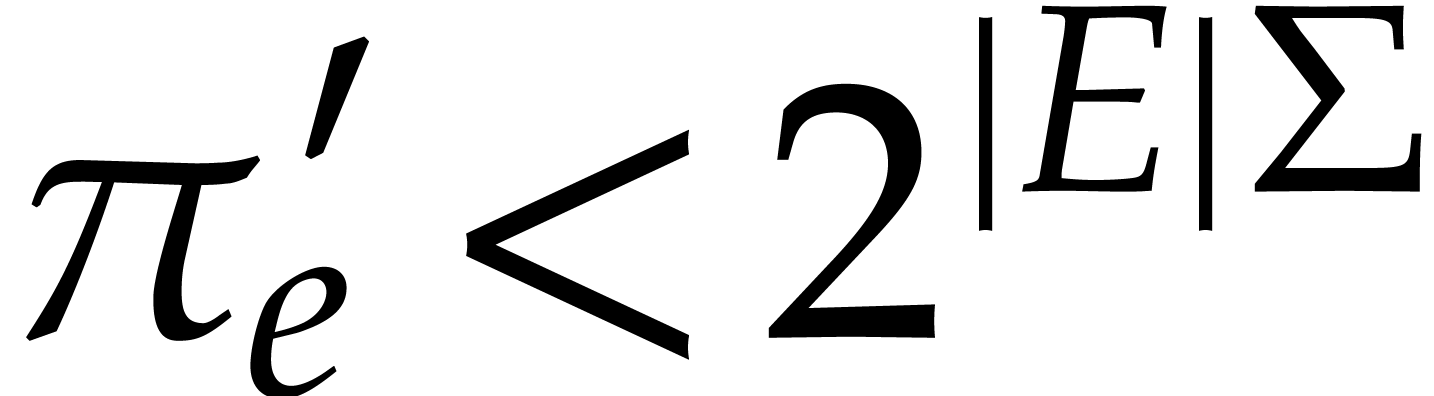 .
We say that is admissible if
.
We say that is admissible if 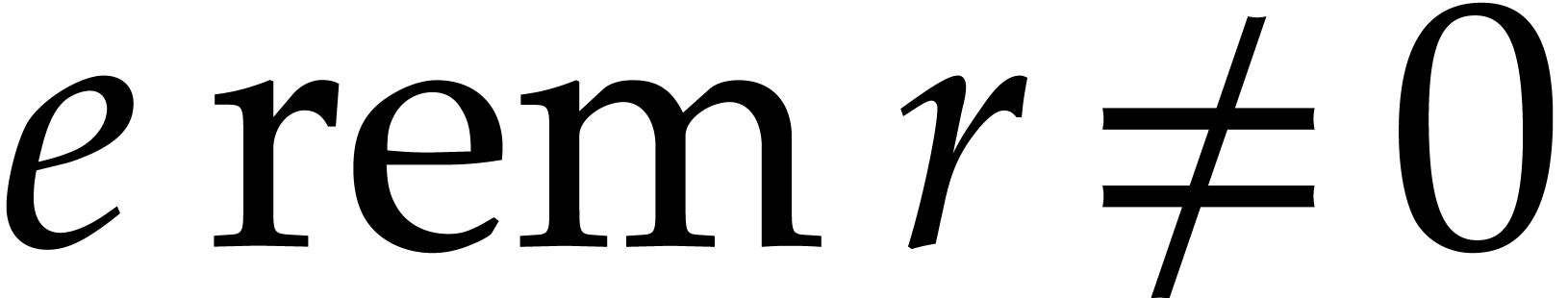 and
and 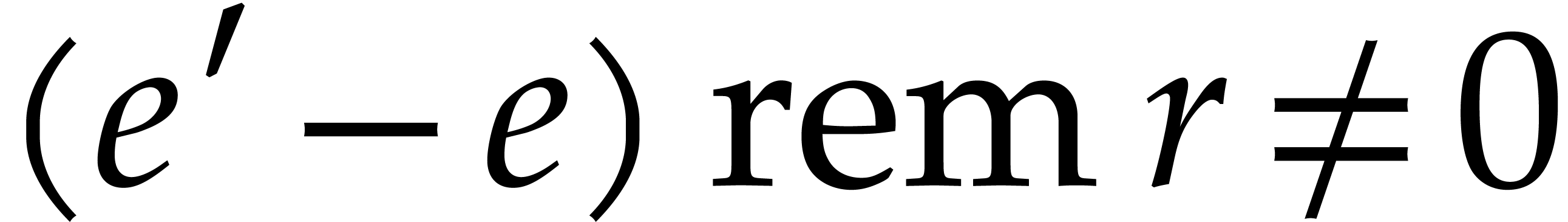 for all
for all 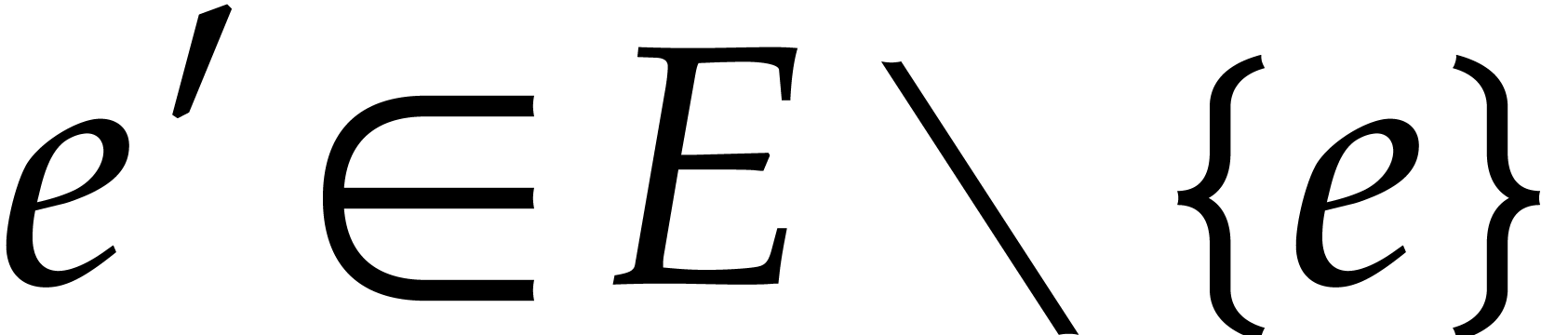 . This is the case if and only if
. This is the case if and only if 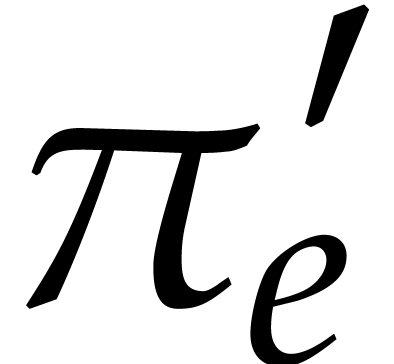 is not divisible by . Now
is divisible by at most
is not divisible by . Now
is divisible by at most 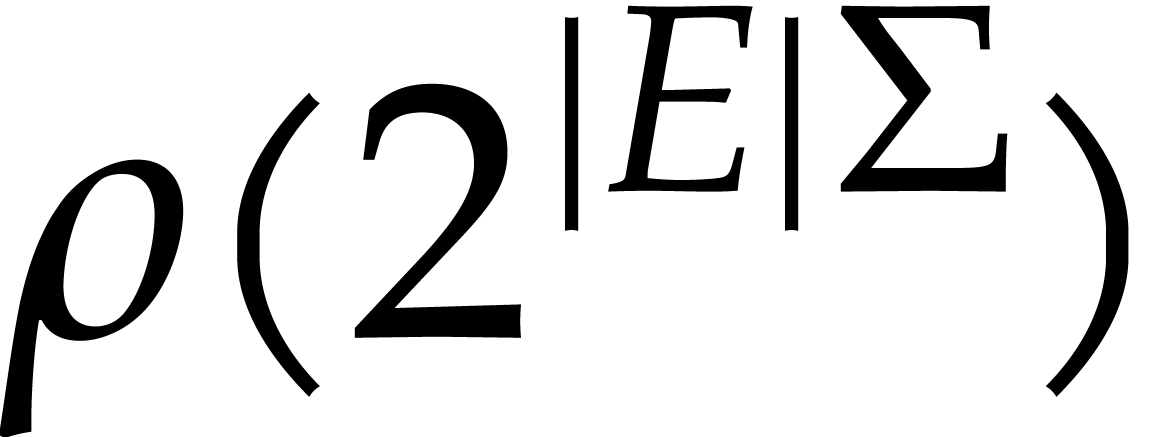 distinct prime numbers, by Theorem 2.4. Since there are at
least
distinct prime numbers, by Theorem 2.4. Since there are at
least
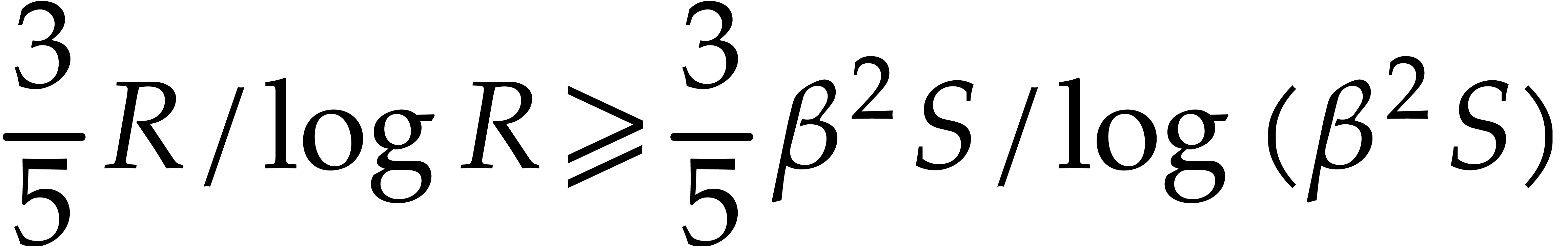
prime numbers in 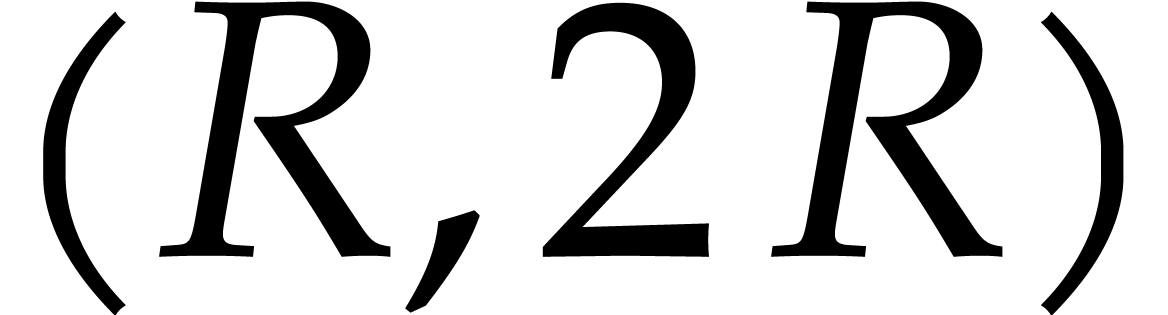 , by Theorem
2.3, the probability that
, by Theorem
2.3, the probability that  is
divisible by is at most
is
divisible by is at most
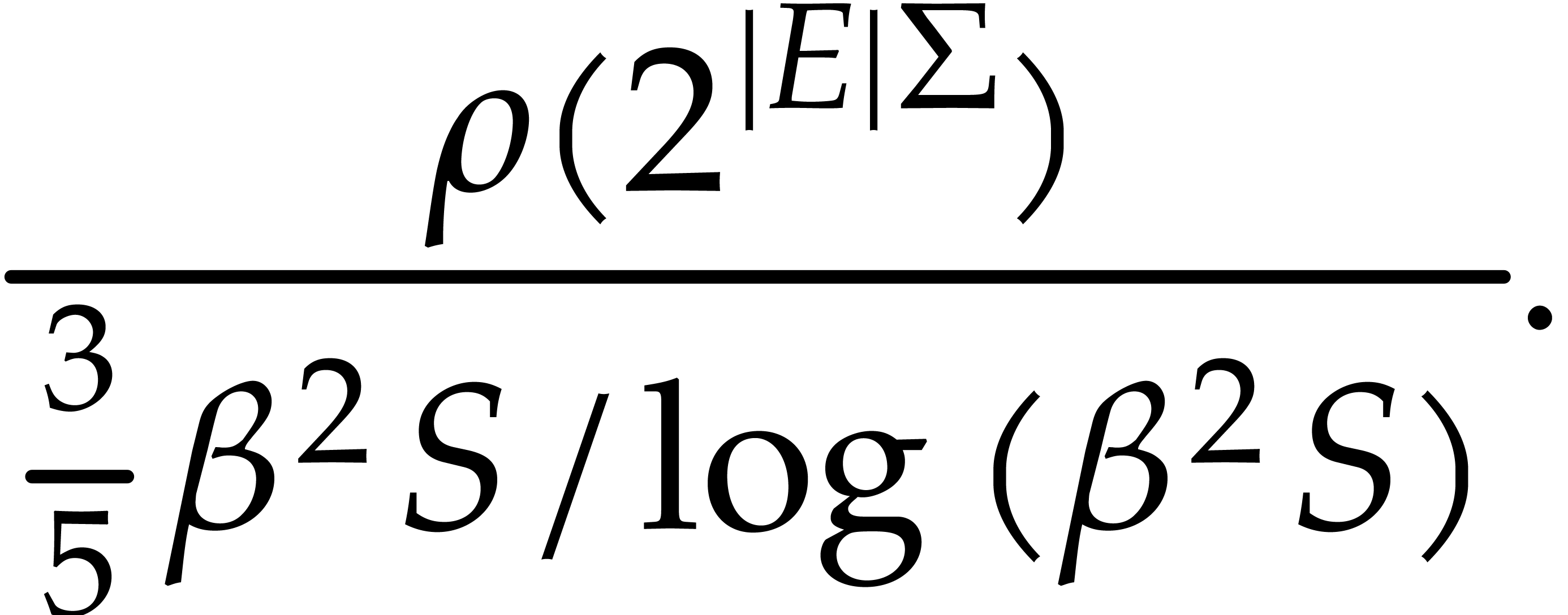
From 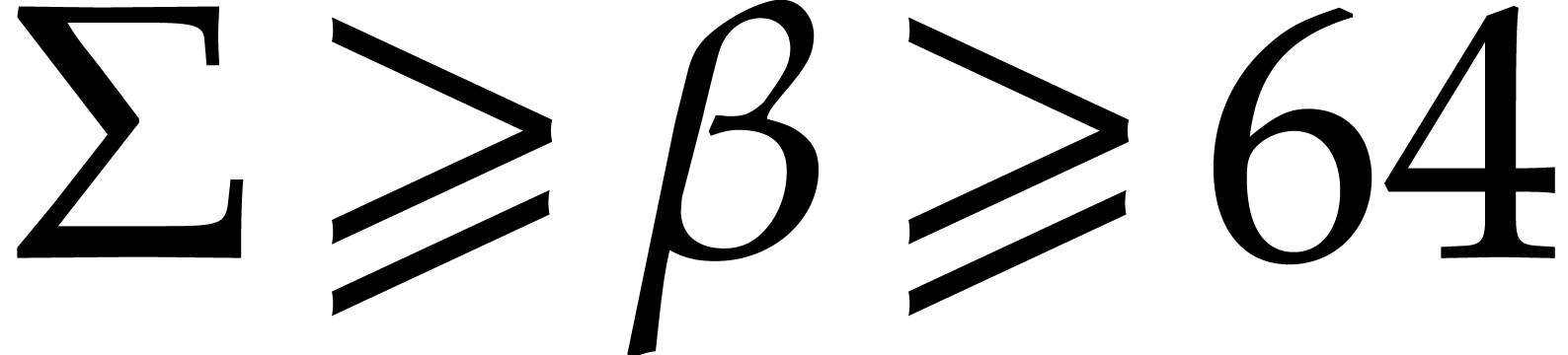 , whence
, whence 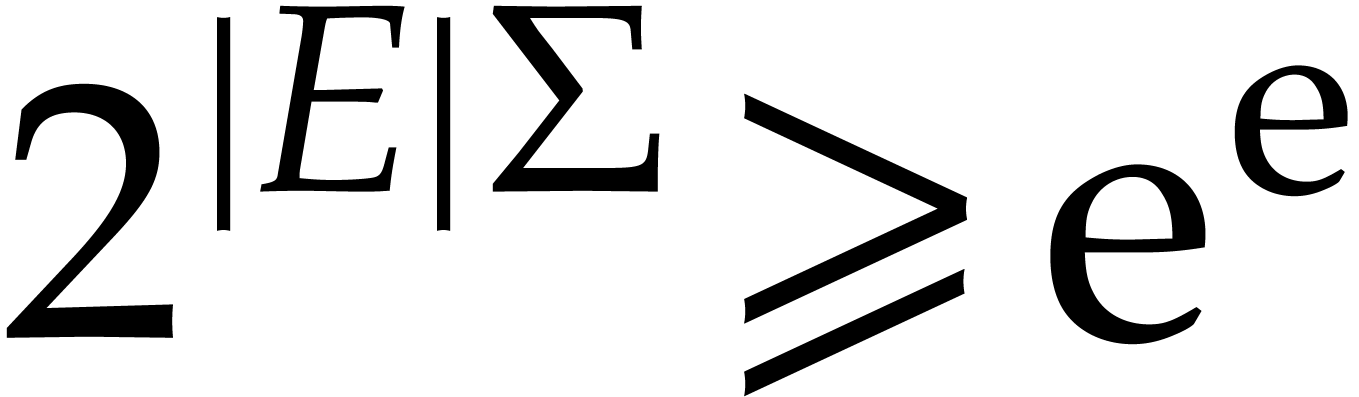 .
It follows that
.
It follows that
since  from
from  in
in  and let with
and let with  . For fixed values of
. For fixed values of  with
with 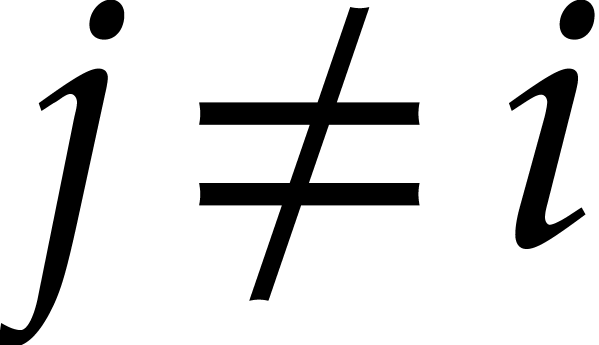 , there is a single
choice of
, there is a single
choice of  with
with 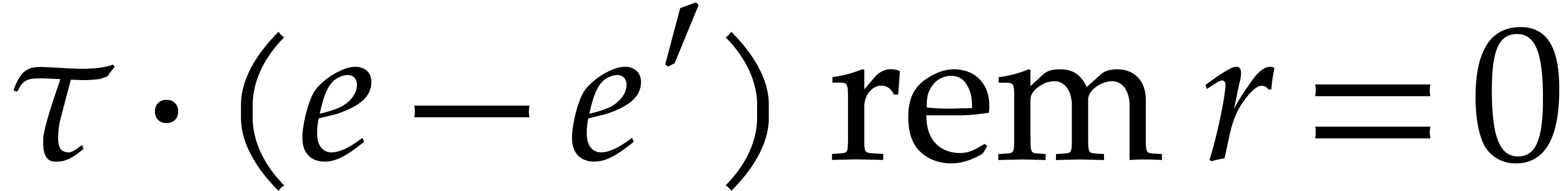 .
Hence the probability that this happens with random
is
.
Hence the probability that this happens with random
is 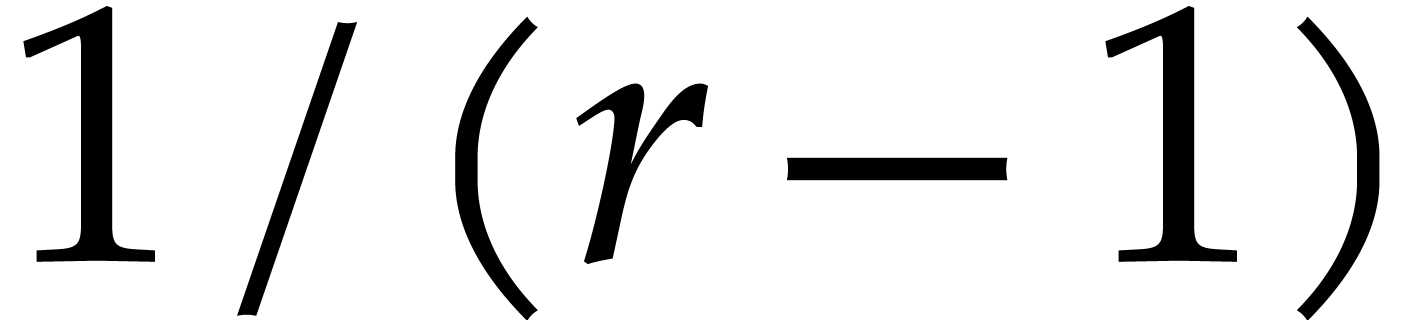 . Consequently, for fixed
, the probability that for some is at most
. Consequently, for fixed
, the probability that for some is at most
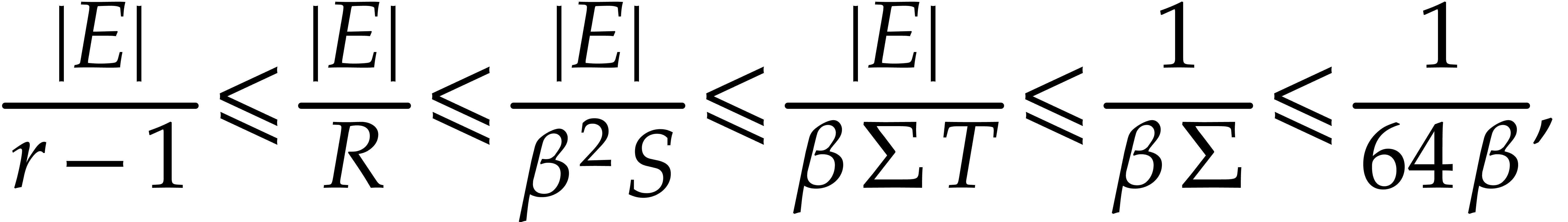 |
(4.4) |
thanks to
Assuming now that is fixed, let us examine the
probability that is -faithful. Let be the
product of all non-zero coefficients of .
Then is faithful if and
only if does not divide . Now the bit-size of the product
is bounded by 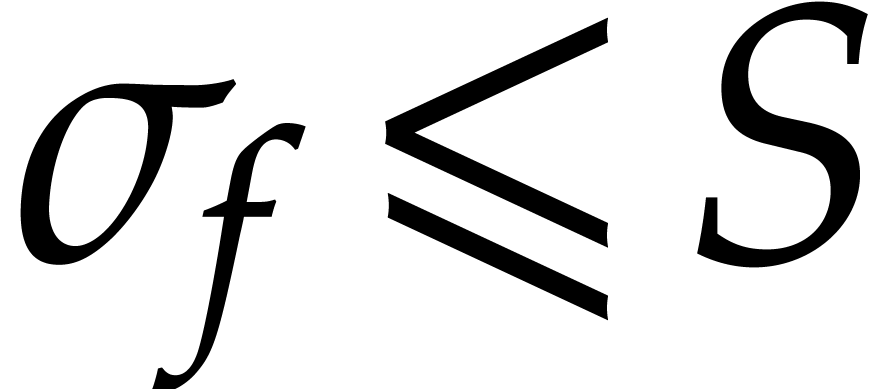 , by Lemma 4.1. Hence is divisible by at most
, by Lemma 4.1. Hence is divisible by at most
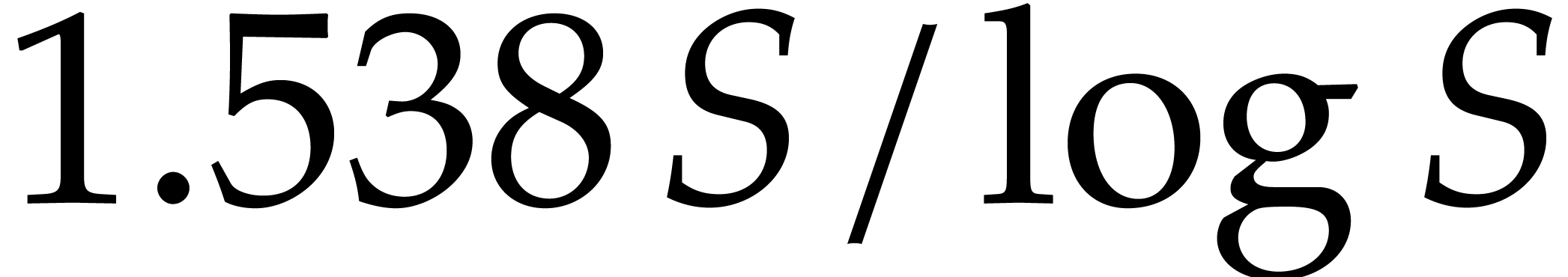 prime numbers, by Theorem 2.4 and
our assumption that
prime numbers, by Theorem 2.4 and
our assumption that 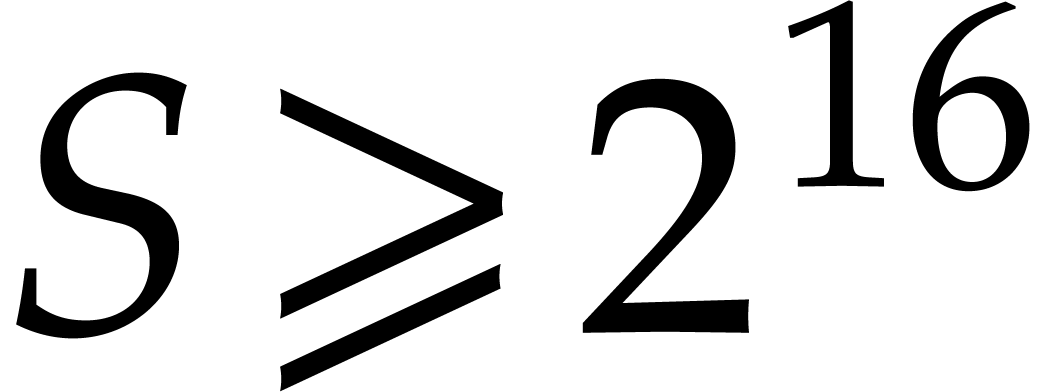 . With
probability at least
. With
probability at least
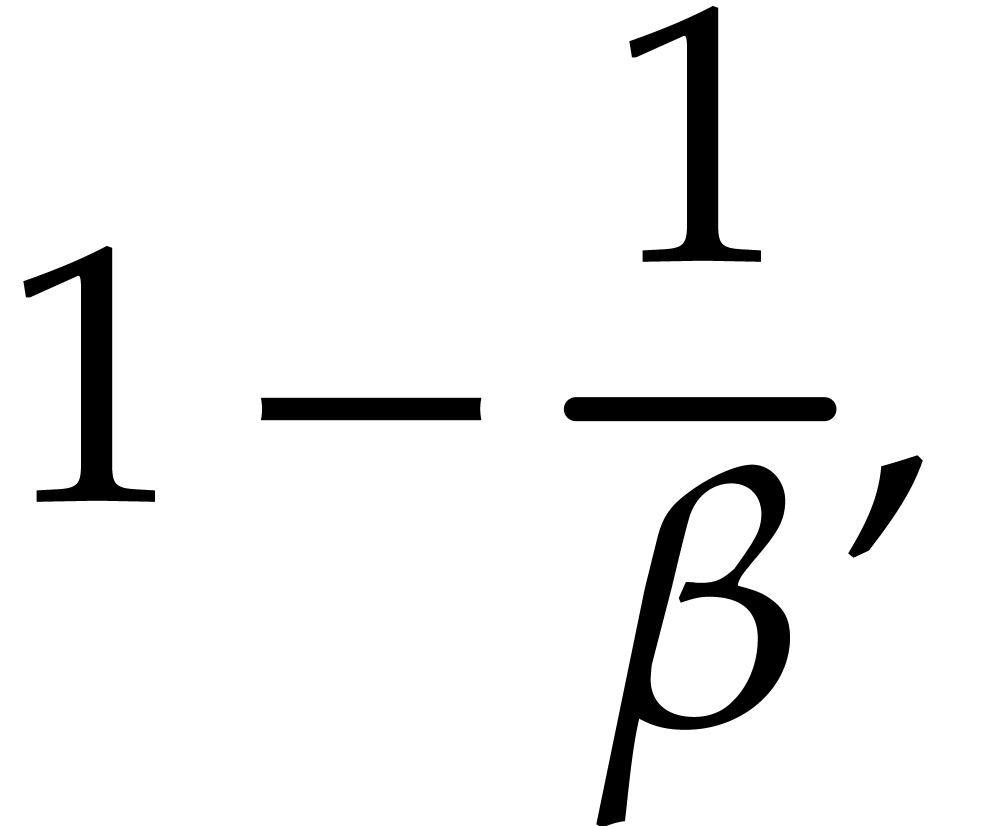 |
(4.5) |
there are at least prime numbers amongst which
is chosen at random, by Theorem 2.5(b).
Assuming this, is not -faithful with probability at most
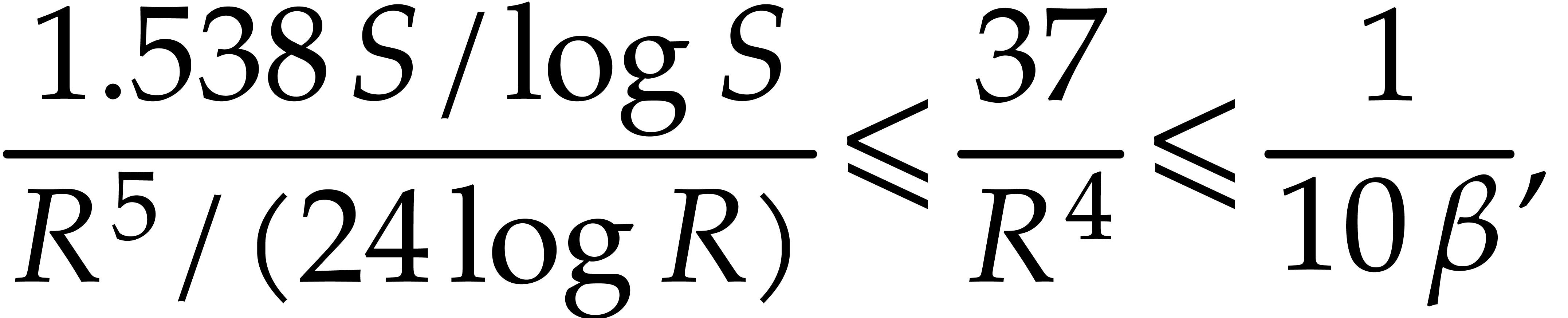 |
(4.6) |
since  , by
, by
Let 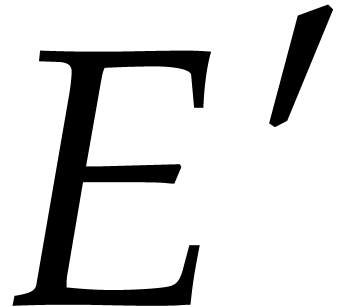 be the set of such
that
be the set of such
that 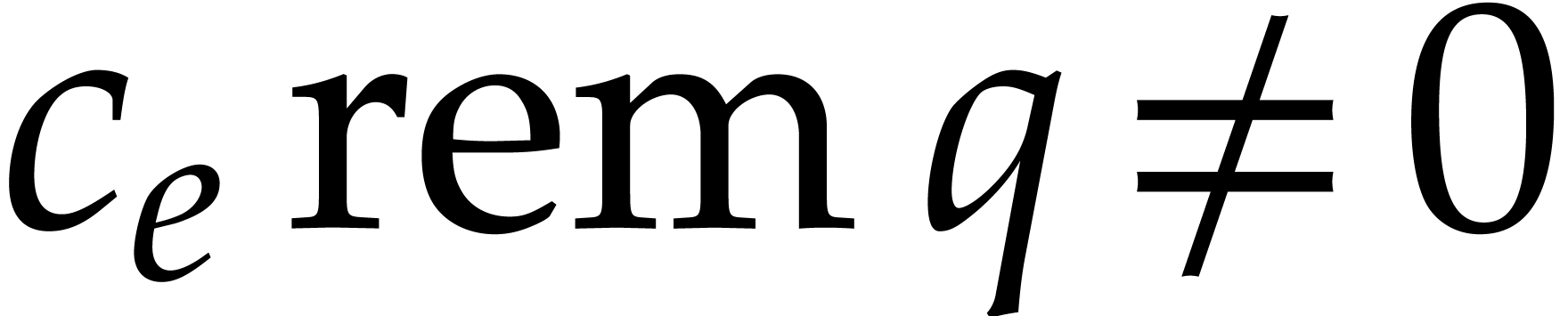 and
and 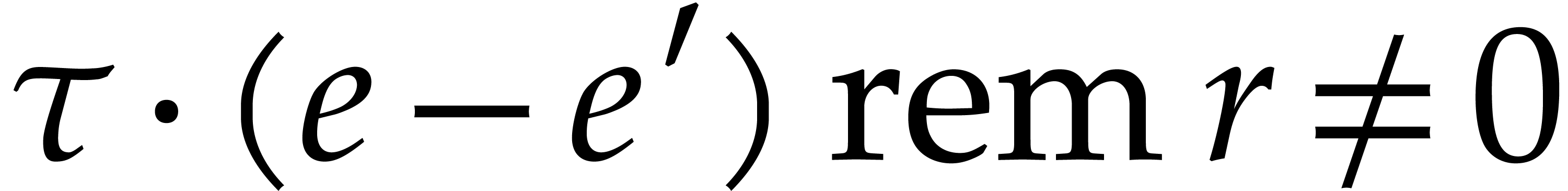 for all . Altogether, the bounds belongs to is at least
for all . Altogether, the bounds belongs to is at least 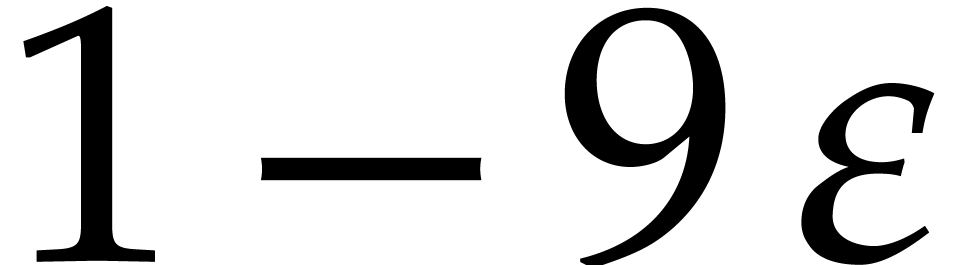 .
It follows that the expectation of
.
It follows that the expectation of 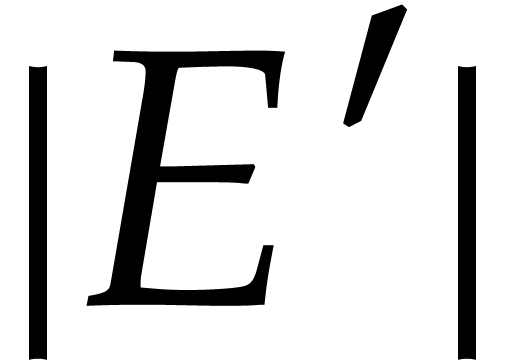 is at least
is at least
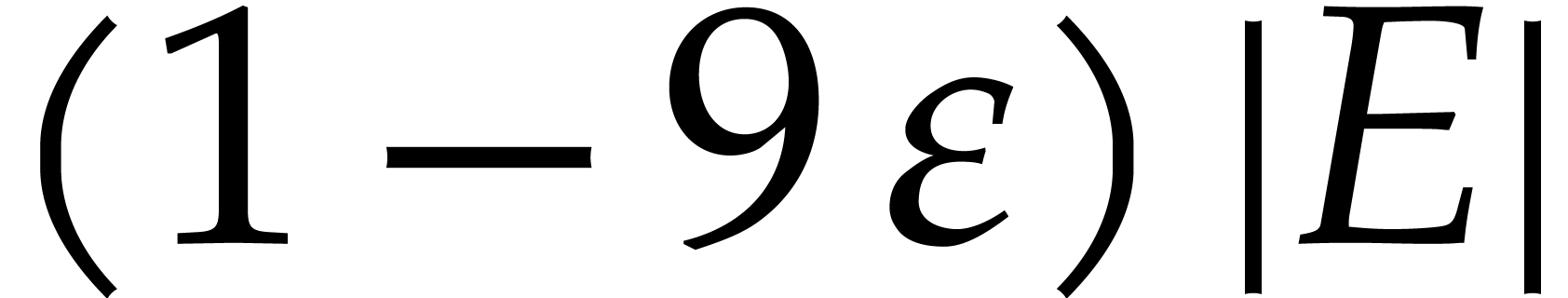 . For
. For
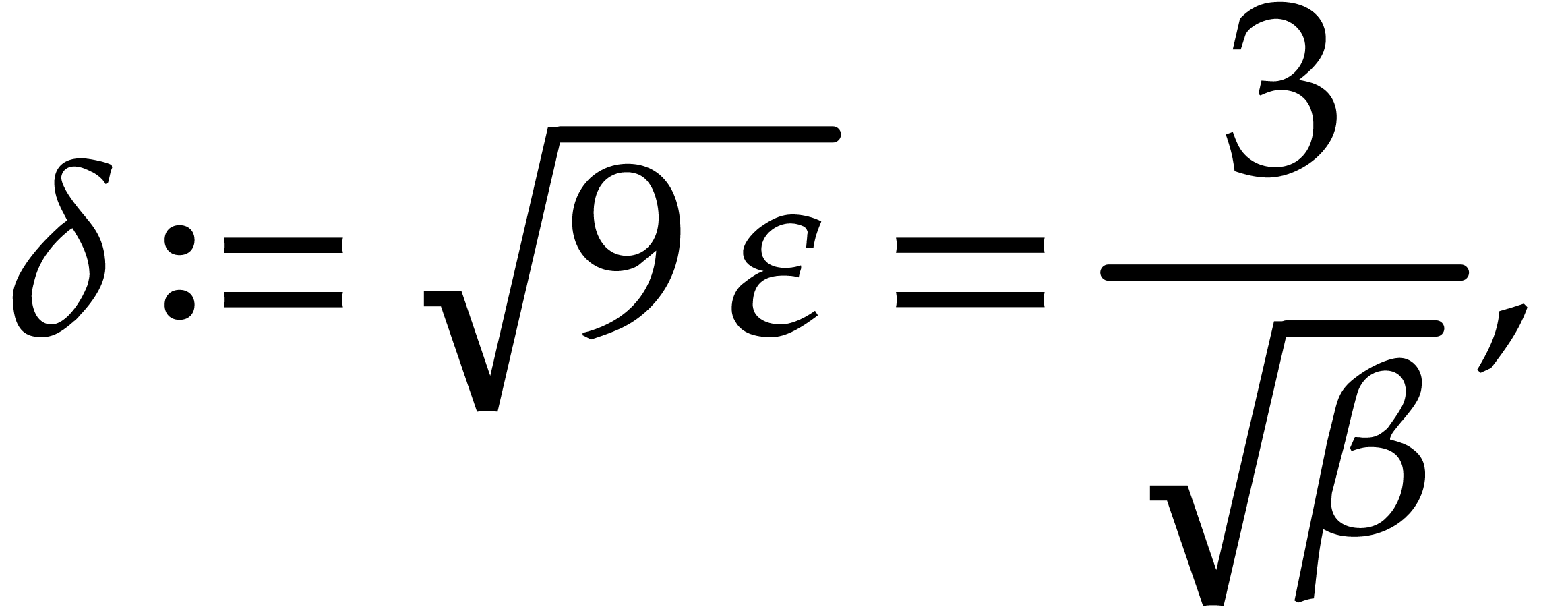
this further implies that the probability that 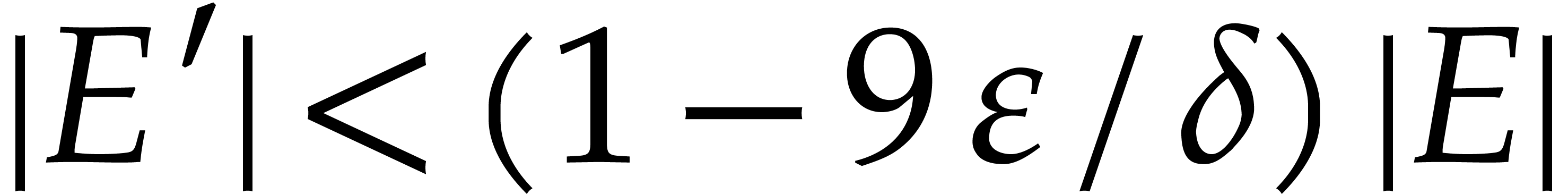 cannot exceed
cannot exceed  : otherwise the
expectation of would be
: otherwise the
expectation of would be 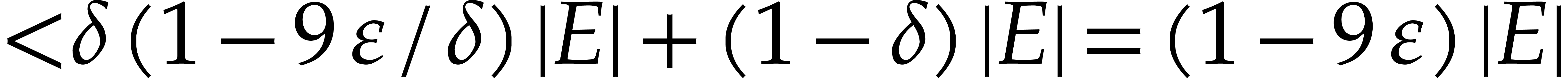 .
.
We finally observe that 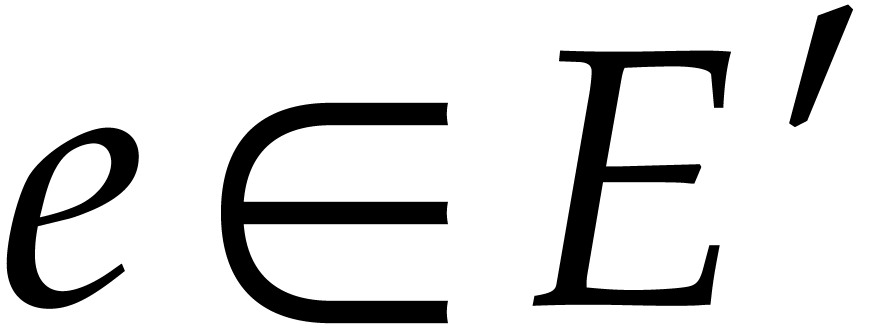 is -faithful whenever for
all
is -faithful whenever for
all  such that
such that 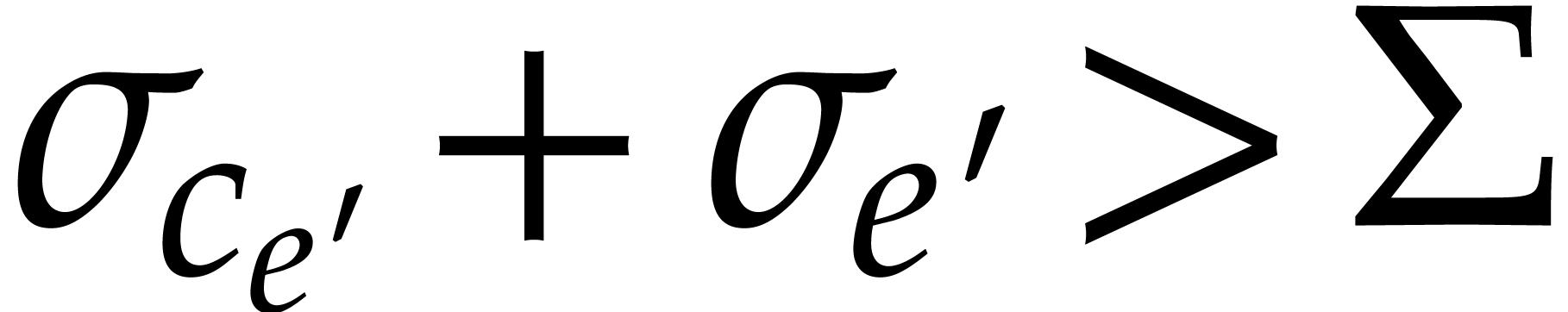 .
Now for every
.
Now for every 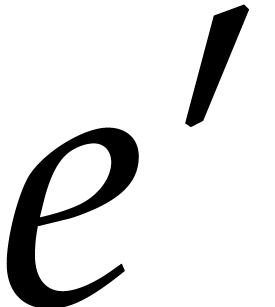 with ,
there is at most one with : if
with ,
there is at most one with : if 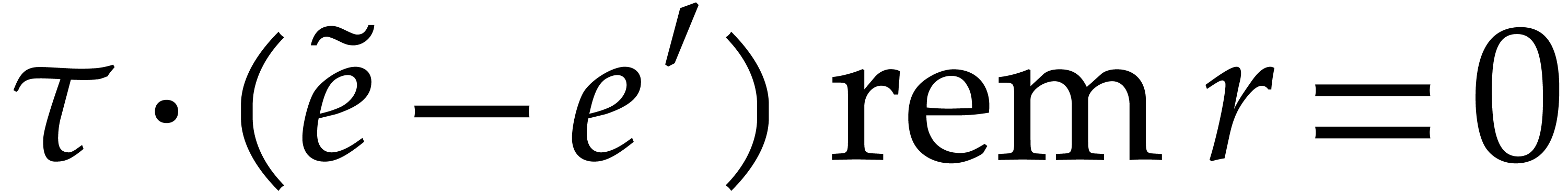 for
for 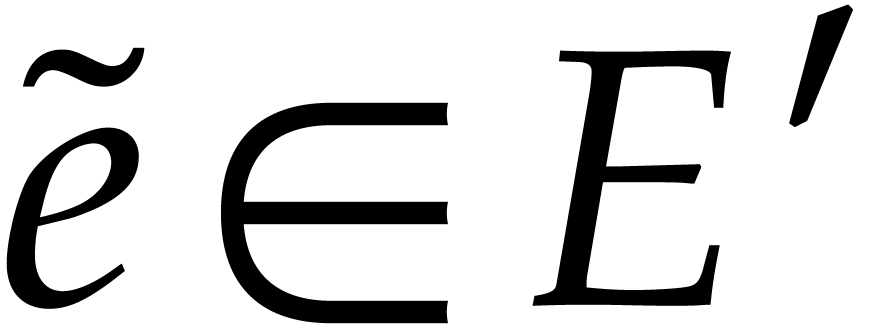 , then
, then 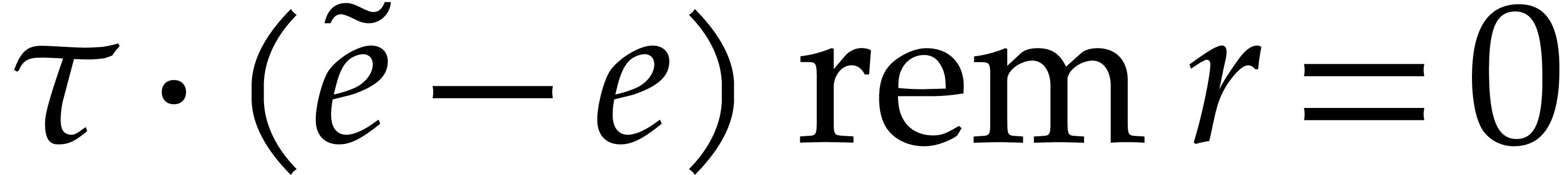 ,
whence
,
whence 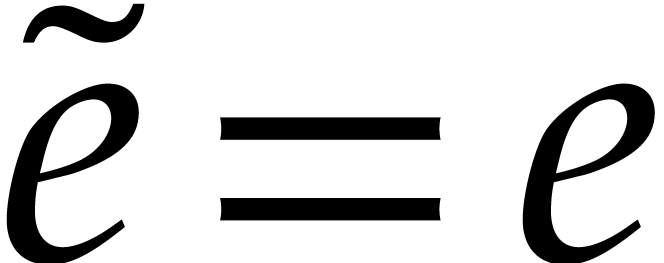 . By (4.1),
there are at most
. By (4.1),
there are at most 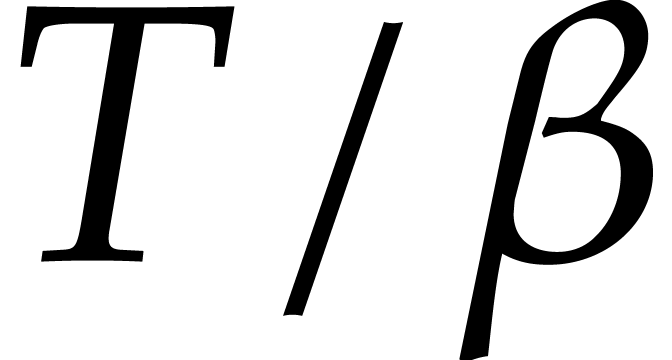 exponents
with . We conclude that
exponents
with . We conclude that 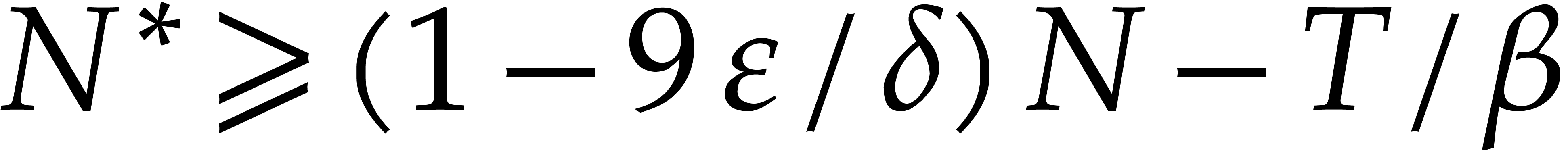 , whenever
, whenever 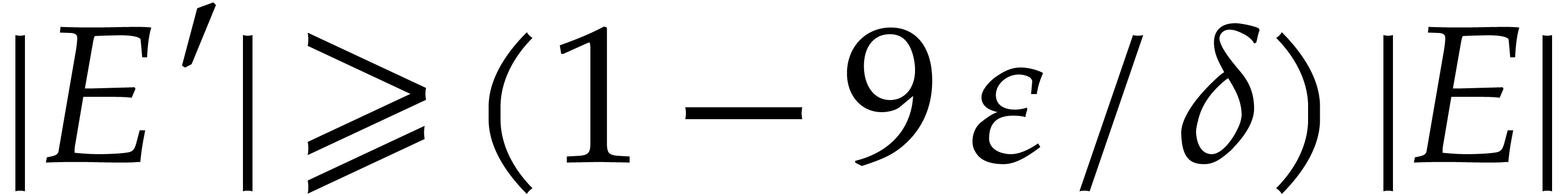 .
.
Lemma 4.3 allows us to compute the coefficients of 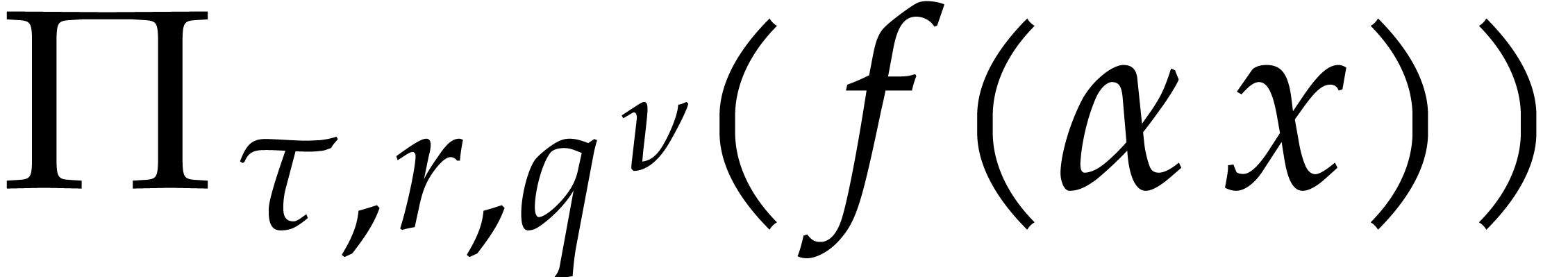 with good complexity. In the univariate case, it
turns out that the exponents of -faithful
terms of can be recovered as quotients of
matching terms of
with good complexity. In the univariate case, it
turns out that the exponents of -faithful
terms of can be recovered as quotients of
matching terms of 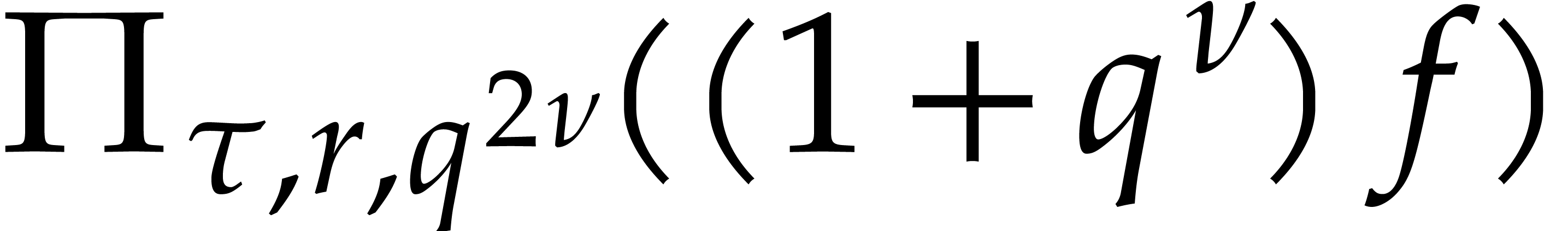 and
and 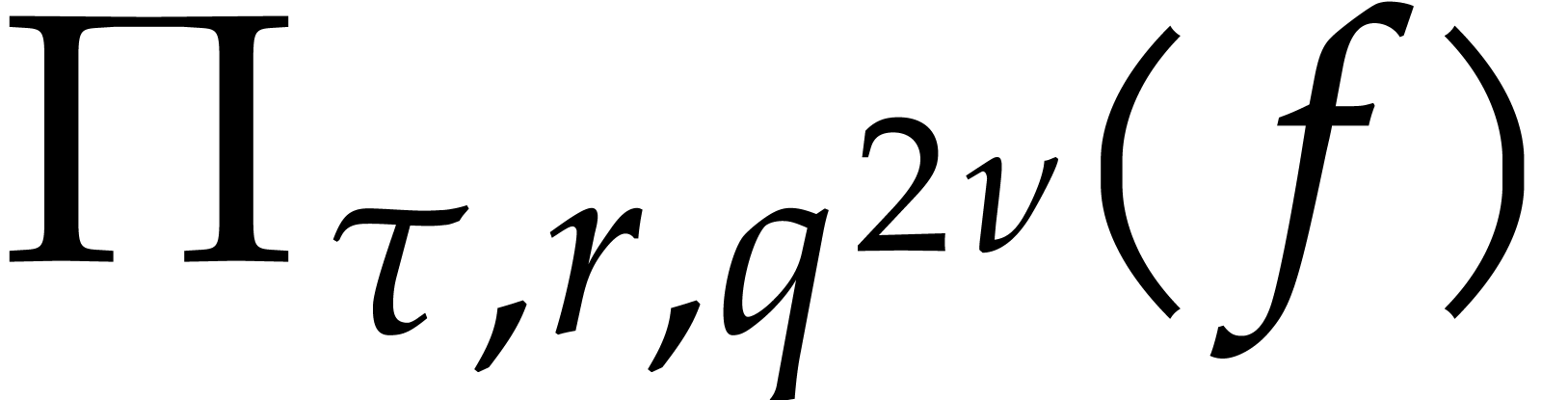 by
taking sufficiently large.
by
taking sufficiently large.
In the multivariate case, this idea still works, for a suitable
Kronecker-style choice of  .
However, we only reach a suboptimal complexity when the exponents of
are themselves sparse and/or of unequal
magnitudes. The remedy is to generalize the “quotient trick”
from the univariate case, by combining it with the algorithms from
section 3: the quotients will now yield the exponents in
encoded form.
.
However, we only reach a suboptimal complexity when the exponents of
are themselves sparse and/or of unequal
magnitudes. The remedy is to generalize the “quotient trick”
from the univariate case, by combining it with the algorithms from
section 3: the quotients will now yield the exponents in
encoded form.
Let us now specify the remaining parameters from section 3.
First of all, we take 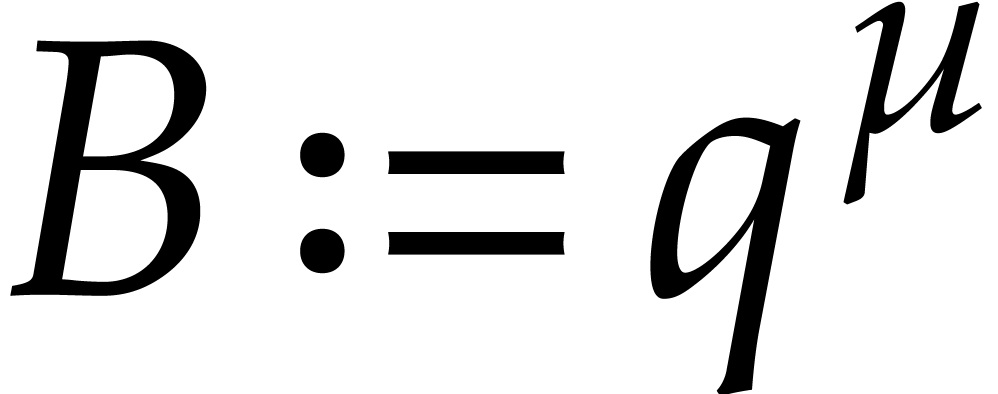 , where
, where
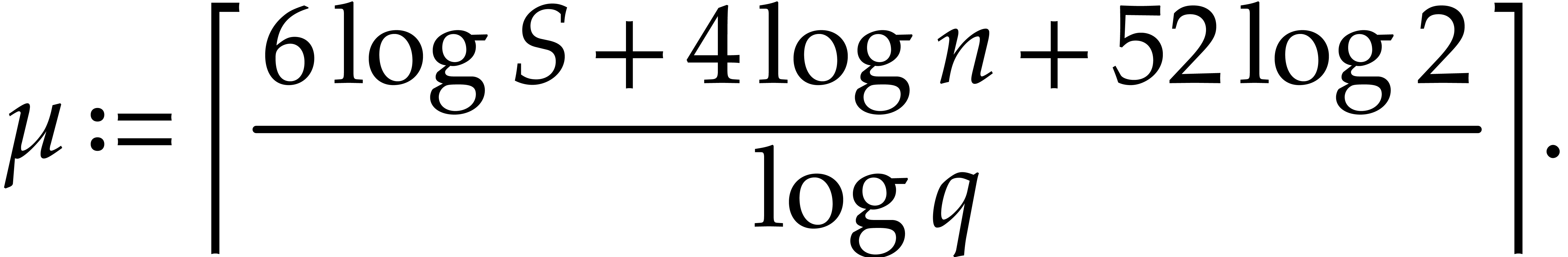
Consequently,
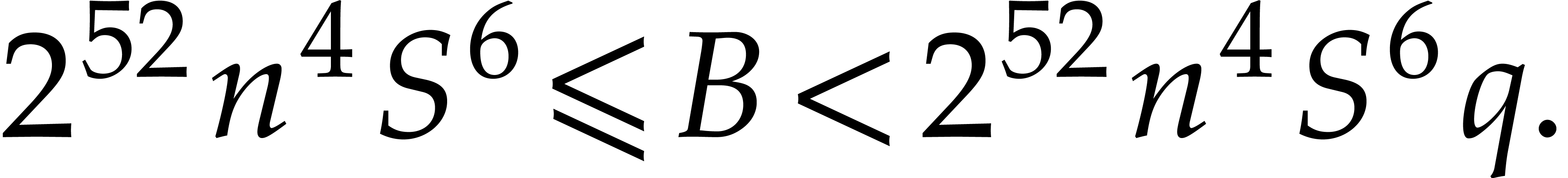 |
(4.7) |
We also take 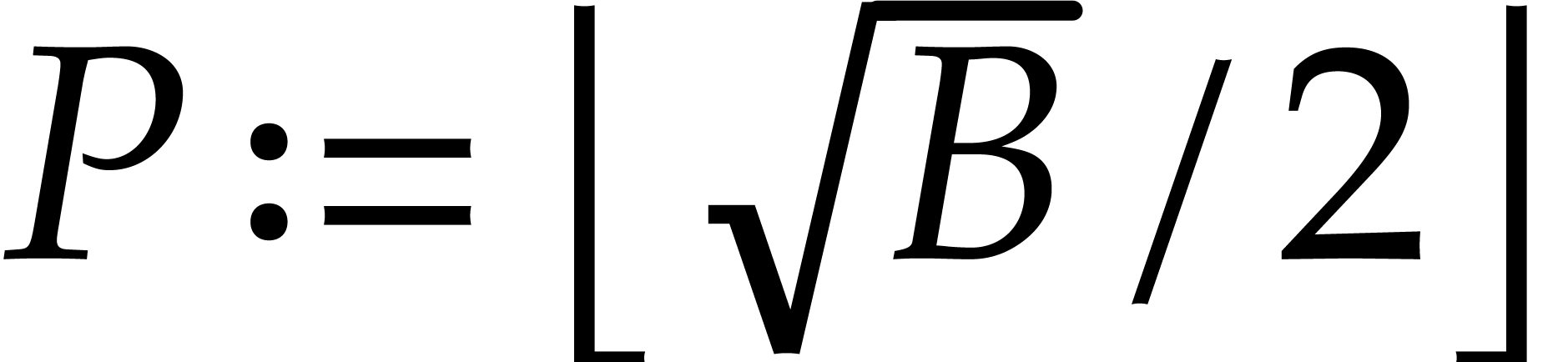 and
and 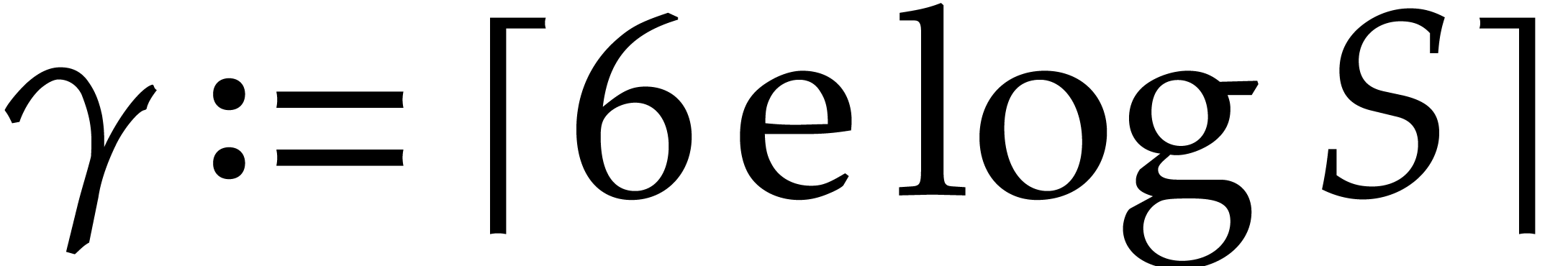 .
Since is odd, the inequalities
.
Since is odd, the inequalities  and
and 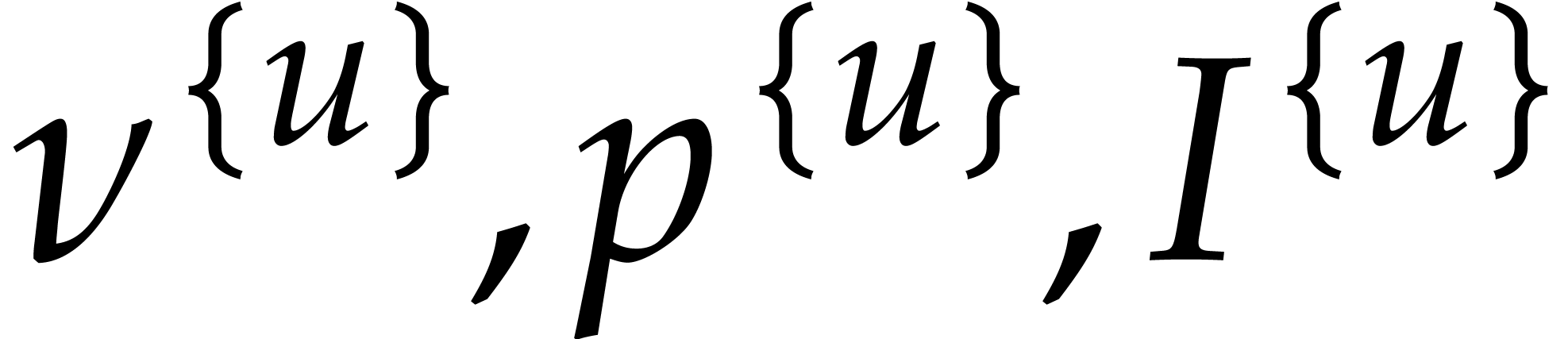 for as in section 3.3.
for as in section 3.3.
For ,  , and ,
let
, and ,
let
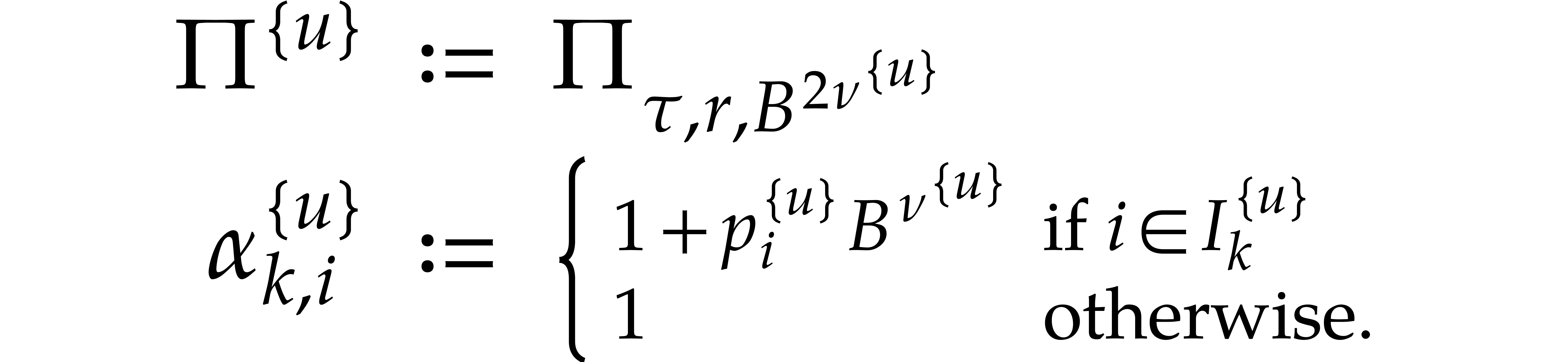
For any term with  and
, note that
and
, note that
since

Whenever 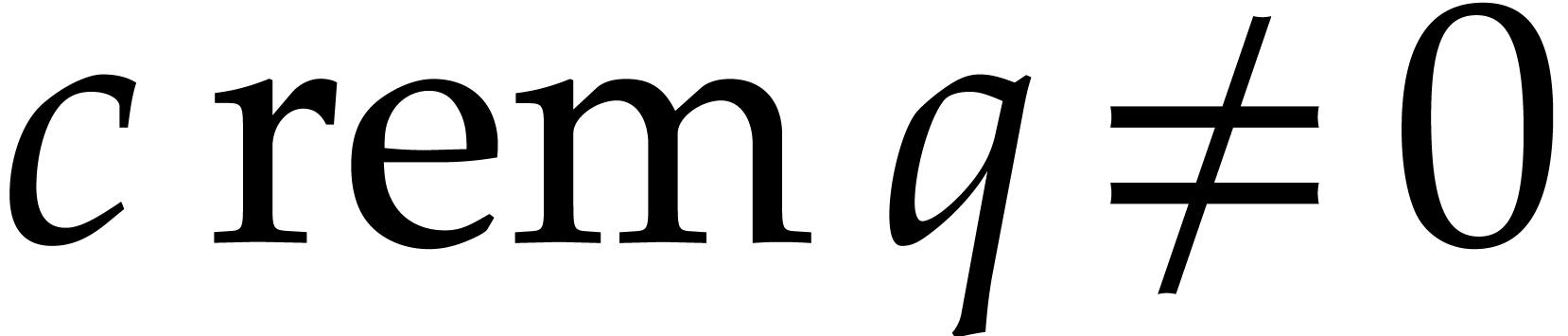 , it follows that
, it follows that
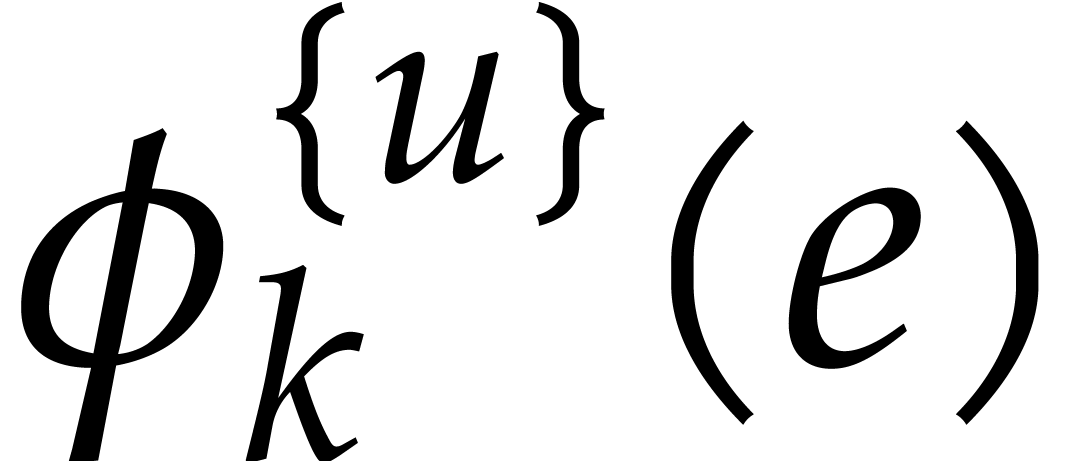 can be read off modulo
can be read off modulo 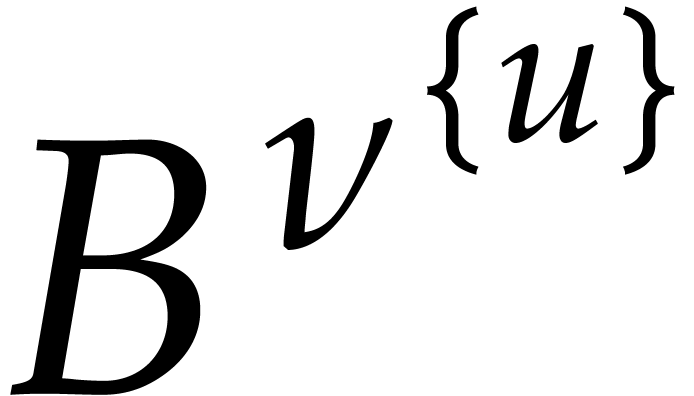 from the quotient of
from the quotient of  and
and 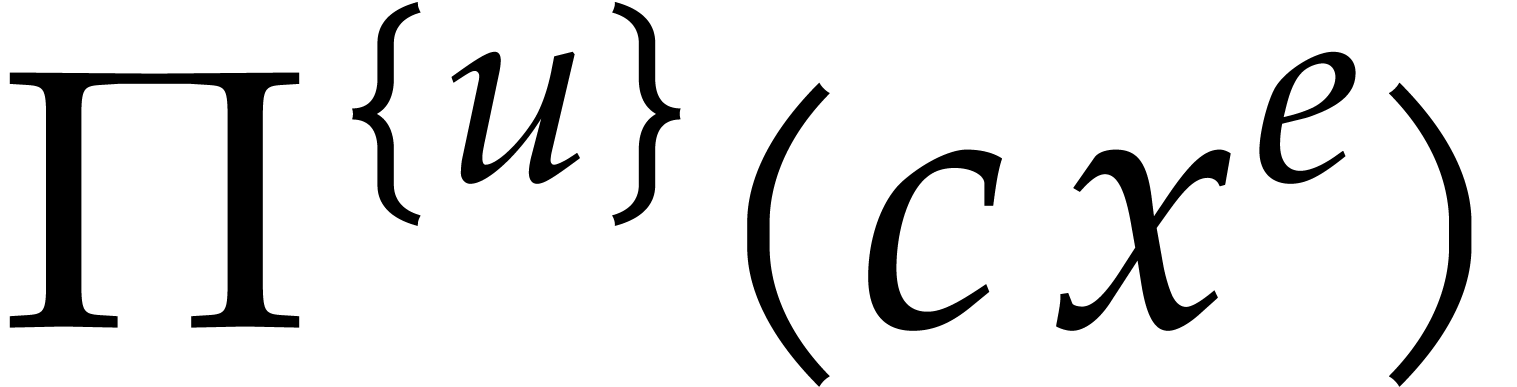 .
.
,  ,
,  ,
,
,
,  be as in be as in
Theorem 2.5. Then we can compute the random parameters
be as in be as in
Theorem 2.5. Then we can compute the random parameters
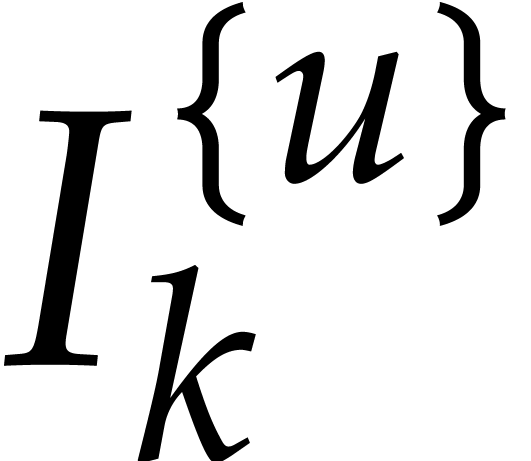 ,
(for and )
and in time
,
(for and )
and in time 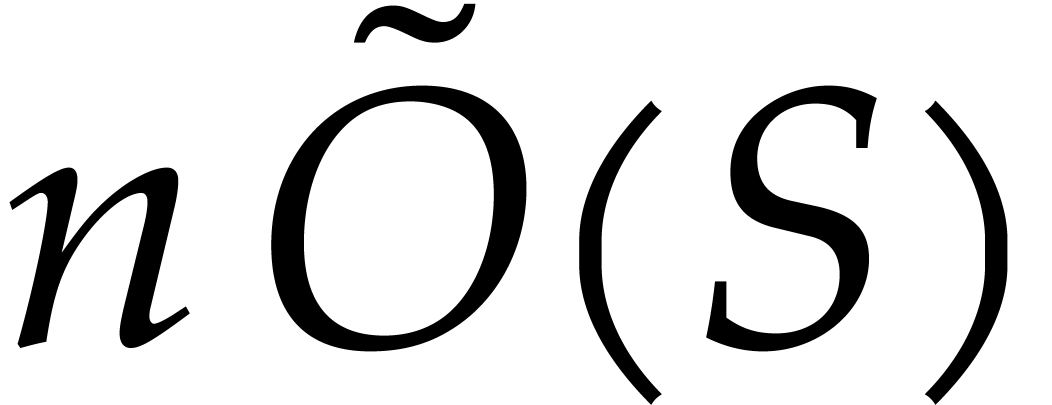 and with a
probability of success
and with a
probability of success 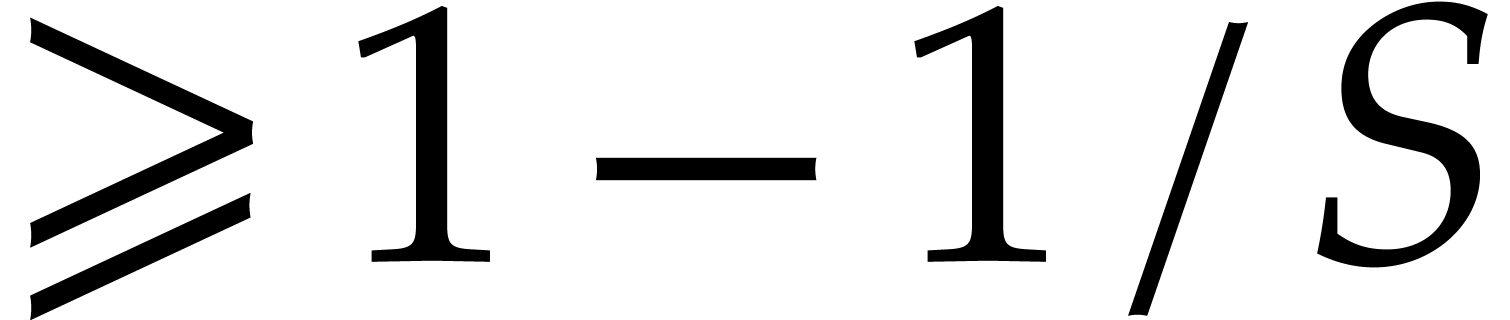 .
.
Proof. The cost to generate
random elements in is

since we assumed 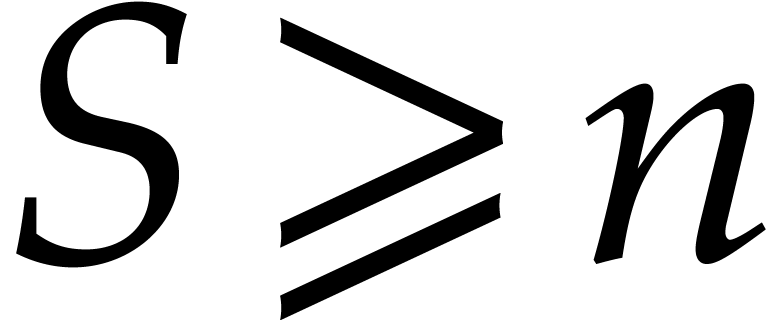 . The
generation of
. The
generation of 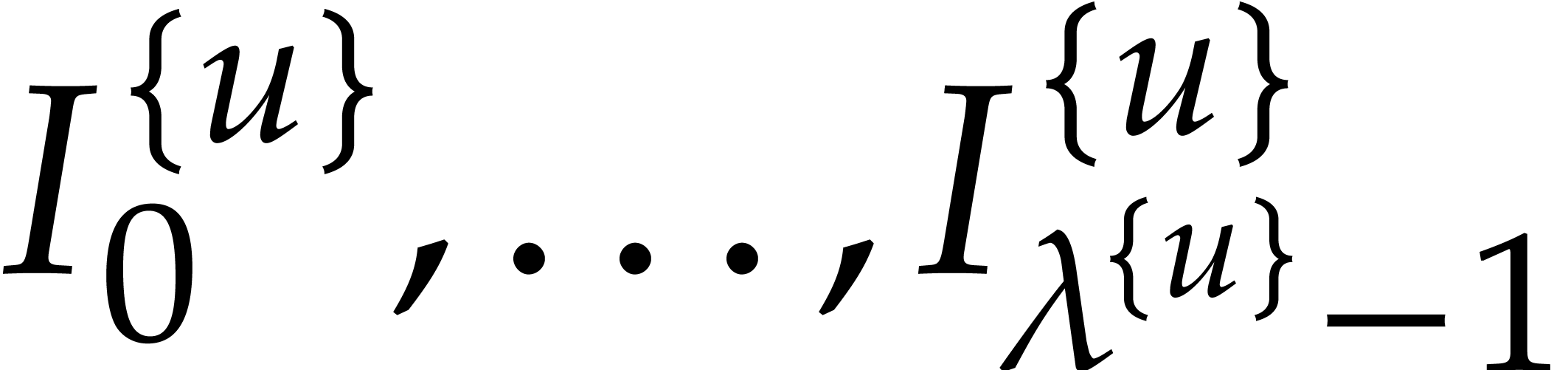 can be done in time
can be done in time
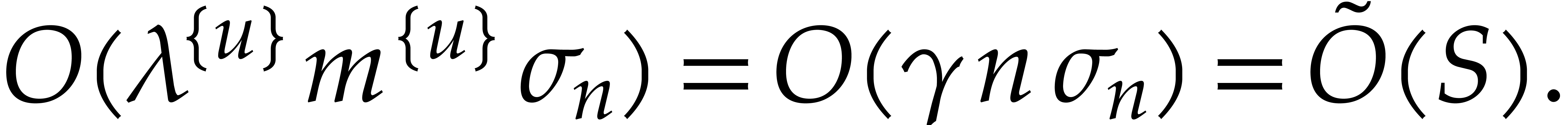
For , we compute using Lemma 2.6 with 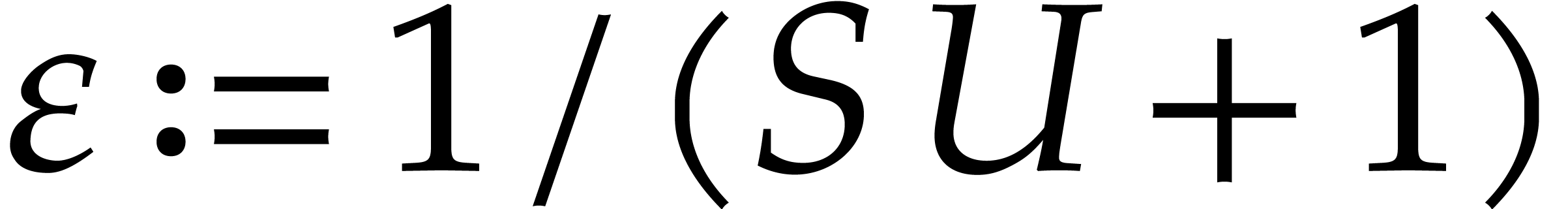 . The computation of a single
takes time
. The computation of a single
takes time
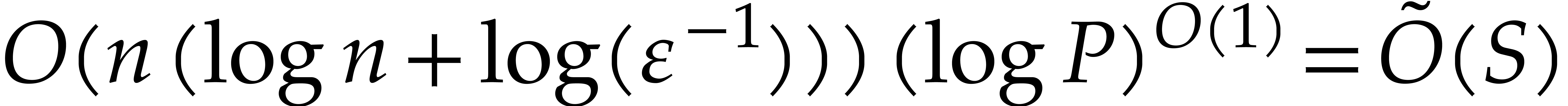
and succeeds with probability at least .
The probability of success for all is at least
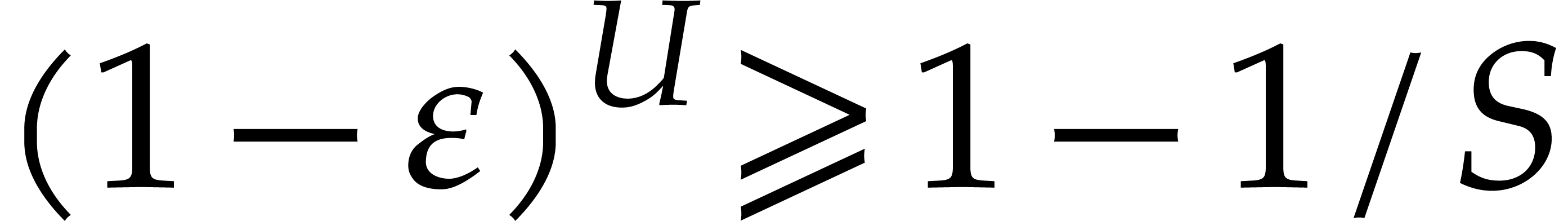 , because
, because
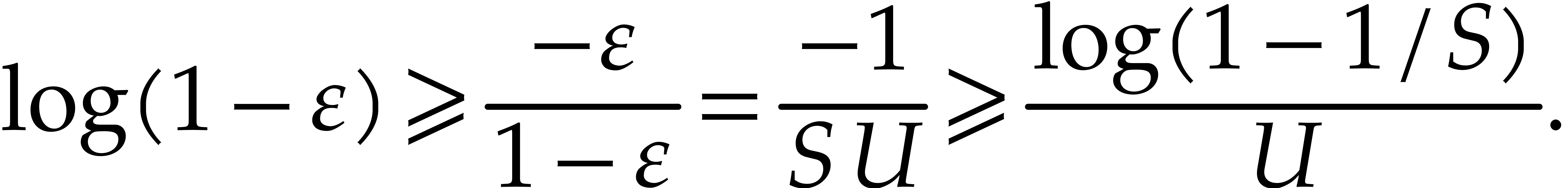
We conclude with the observation that 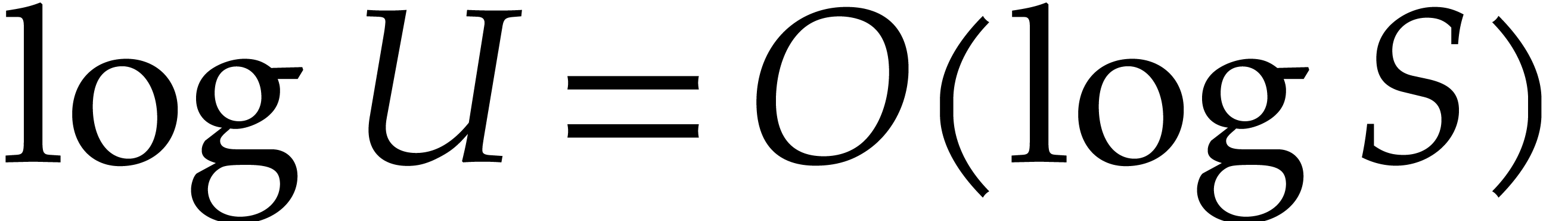 .
.
is -faithful and that is
known. Let . Then we can
compute 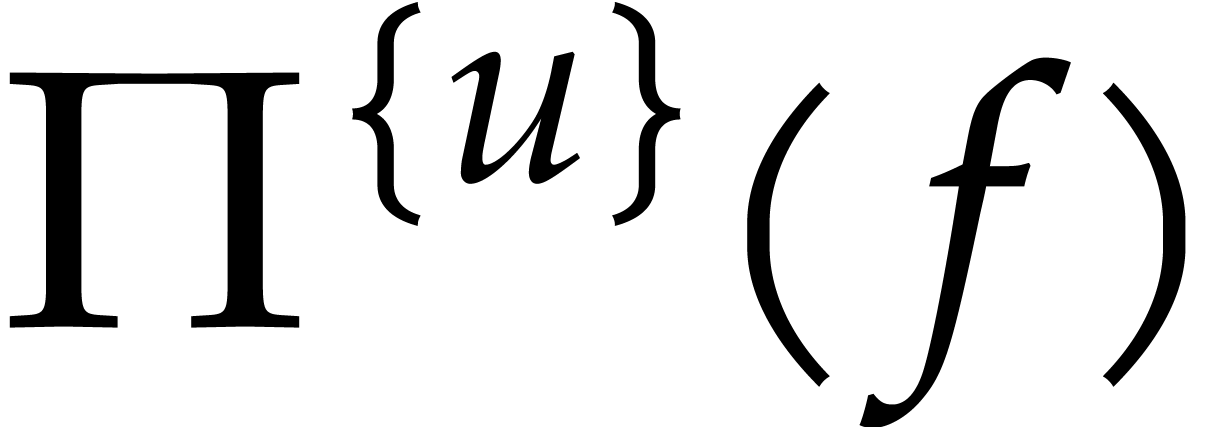 and
and 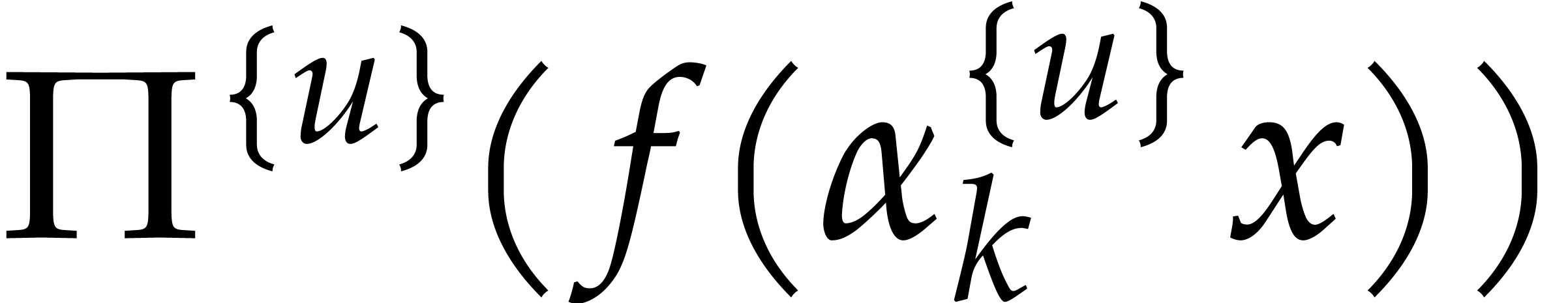 for all
for all
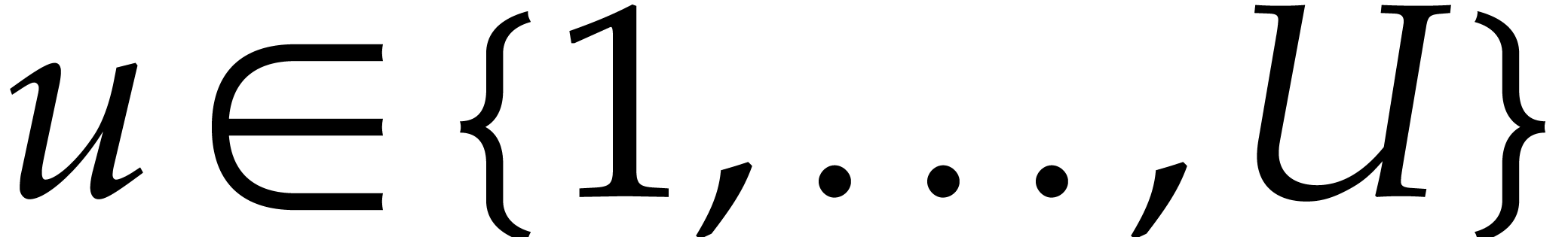 and in time
and in time
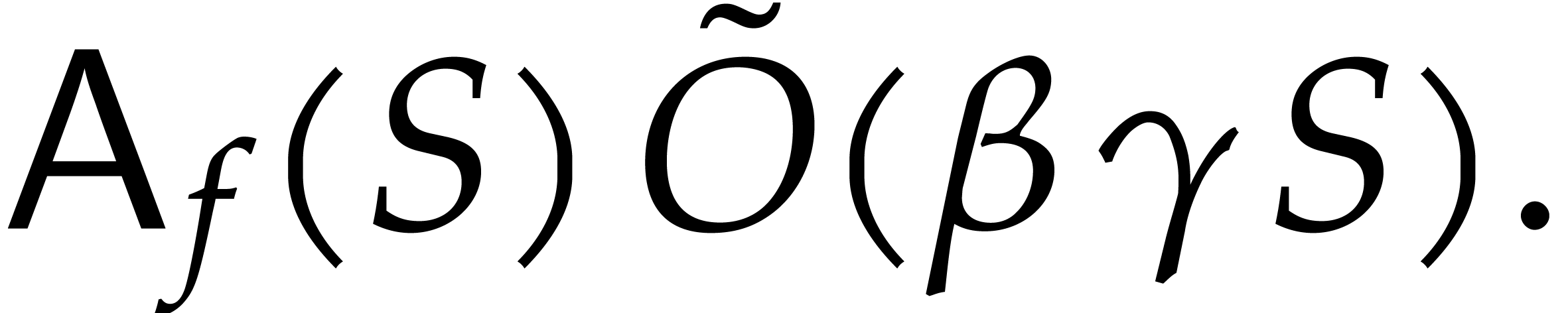
Proof. For a fixed ,
we can compute and for
all in time
by Lemma 4.3. From Lemma 3.9 and
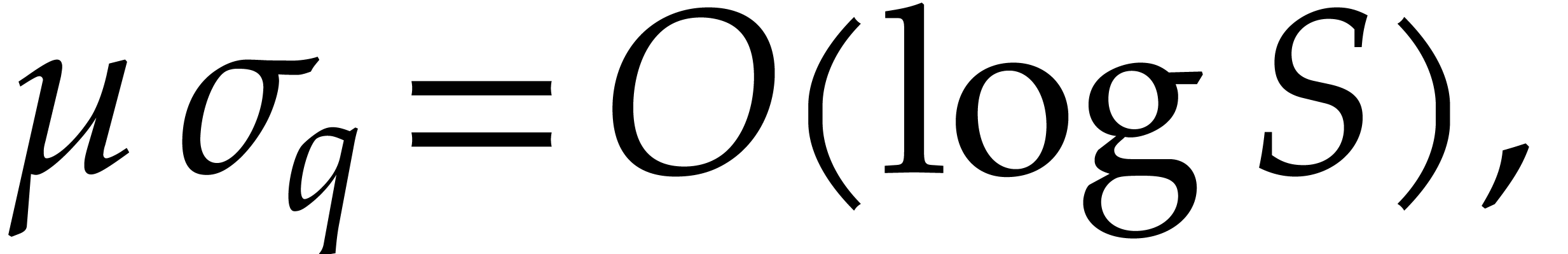 |
(4.8) |
we get
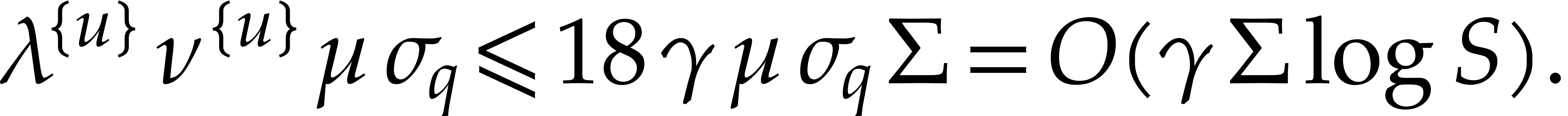
By definition of and , we have 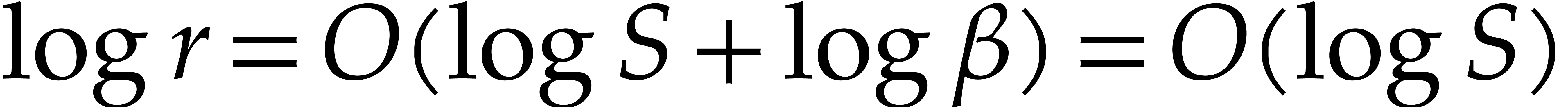 .
By
.
By 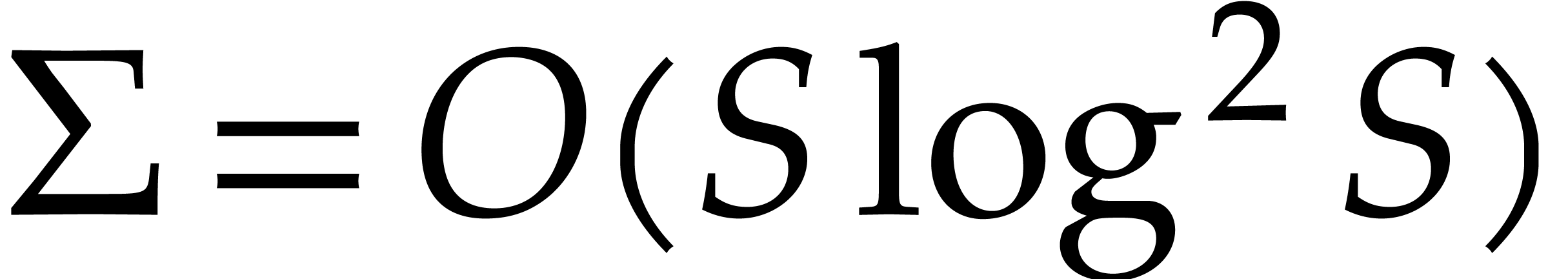 . Hence the cost for computing
and simplifies to
. Hence the cost for computing
and simplifies to
Since 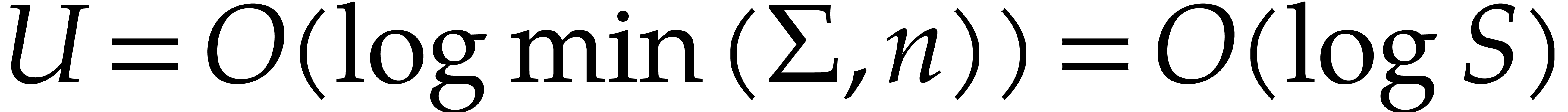 , the total computation
time for is also bounded by
, the total computation
time for is also bounded by 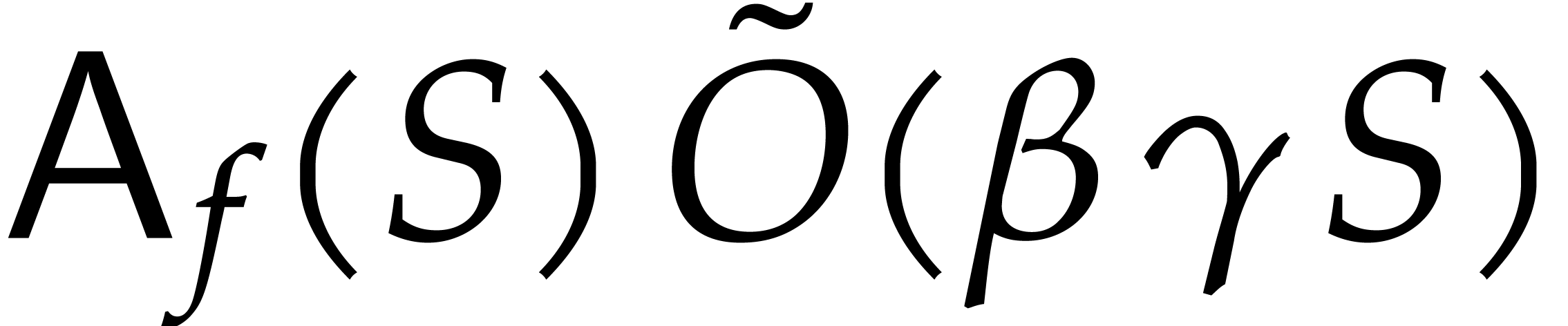 .
.
Consider a family of numbers 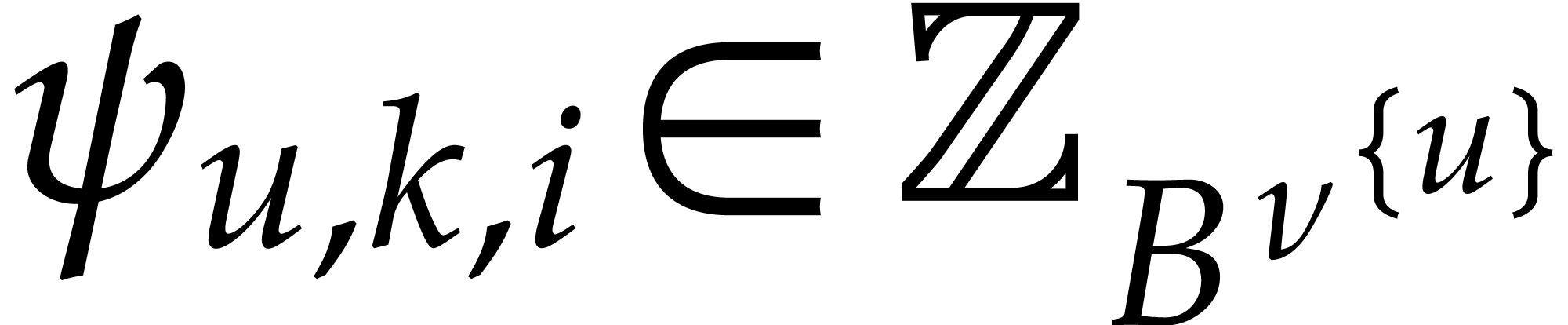 ,
where , , and
,
where , , and  .
We say that the family
.
We say that the family 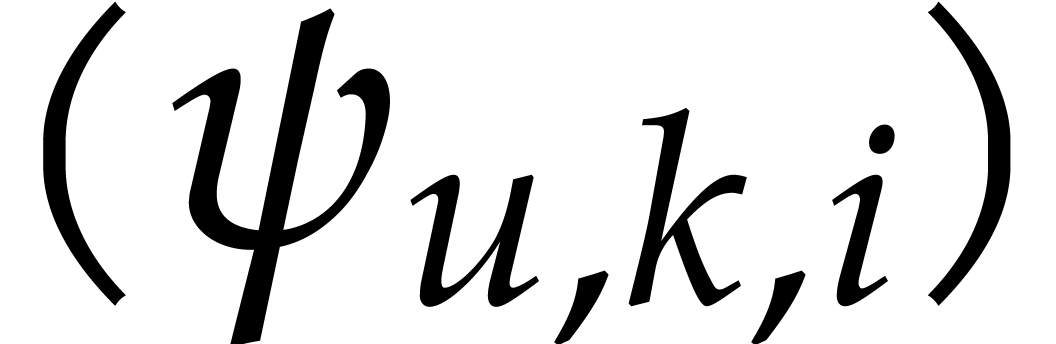 is a faithful
exponent encoding for if we have
is a faithful
exponent encoding for if we have 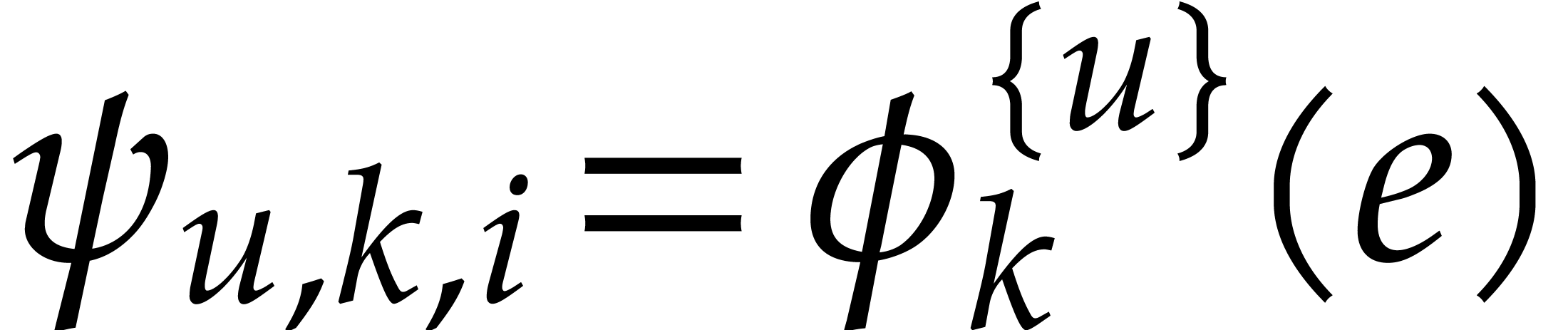 whenever is a
whenever is a 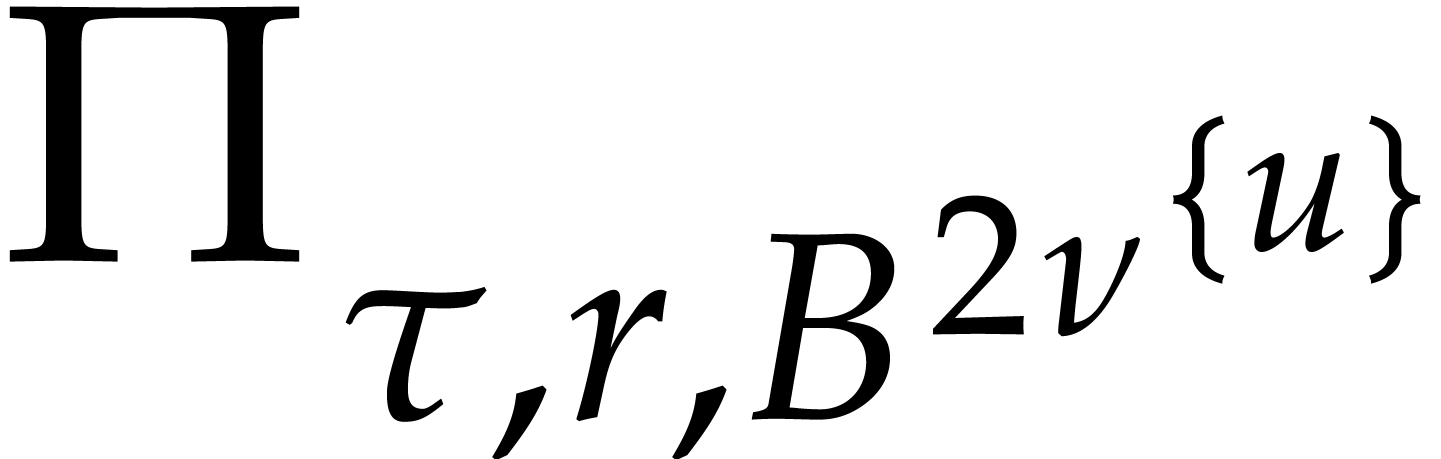 -faithful exponent of
with
-faithful exponent of
with 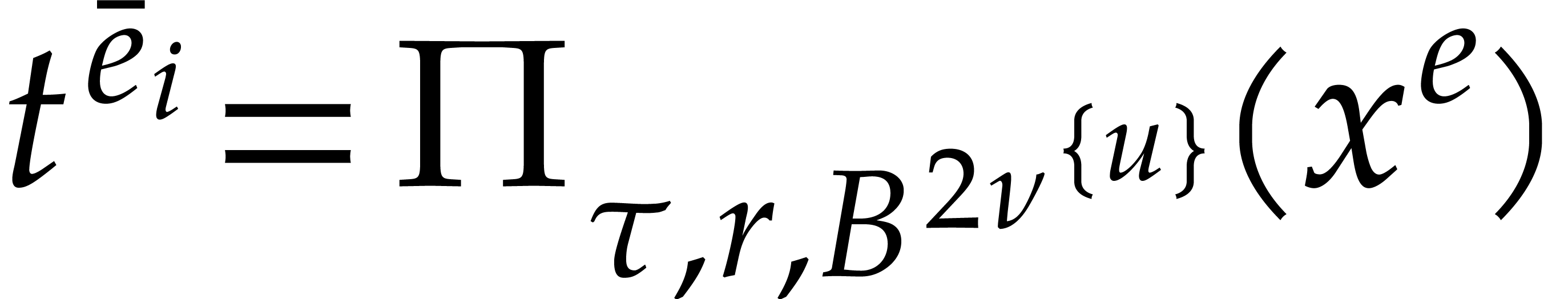 . We require nothing for
the remaining numbers
. We require nothing for
the remaining numbers 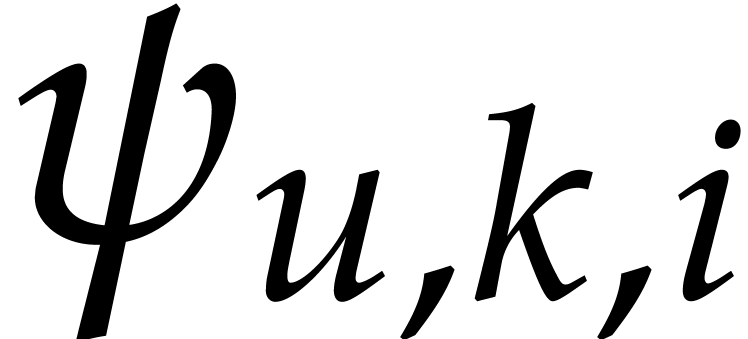 , which
should be considered as garbage.
, which
should be considered as garbage.
is -faithful and that is known. Then we may compute a faithful exponent
encoding for in time .
Proof. We compute all
and using Lemma 4.6. Let 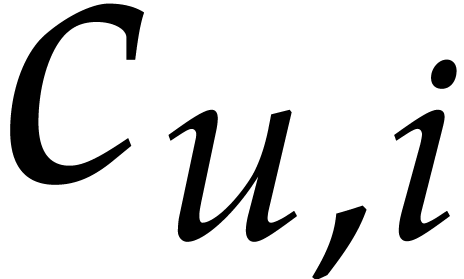 and
and 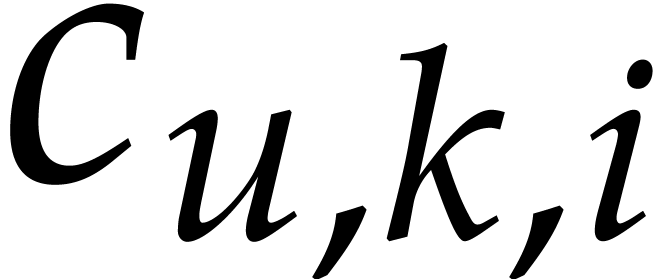 be the coefficients of
be the coefficients of  in and . Then we take
in and . Then we take  if is divisible by and
if is divisible by and  if not. For a fixed all these
divisions take
if not. For a fixed all these
divisions take  bit-operations, using a similar
reasoning as in the proof of Lemma 4.6. Since
bit-operations, using a similar
reasoning as in the proof of Lemma 4.6. Since  , the result follows.
, the result follows.
Let . We say that 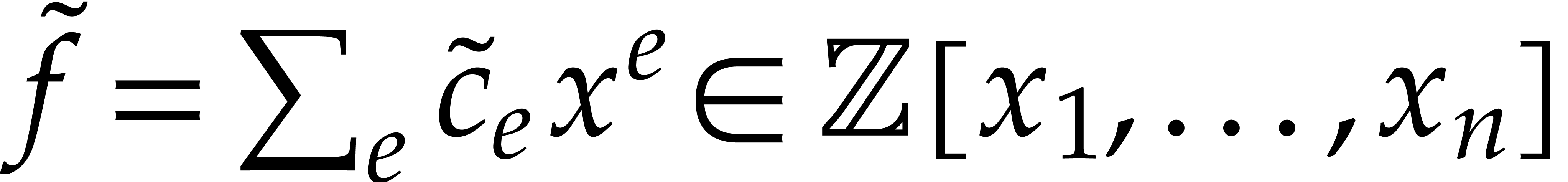 is a -approximation
of if
is a -approximation
of if 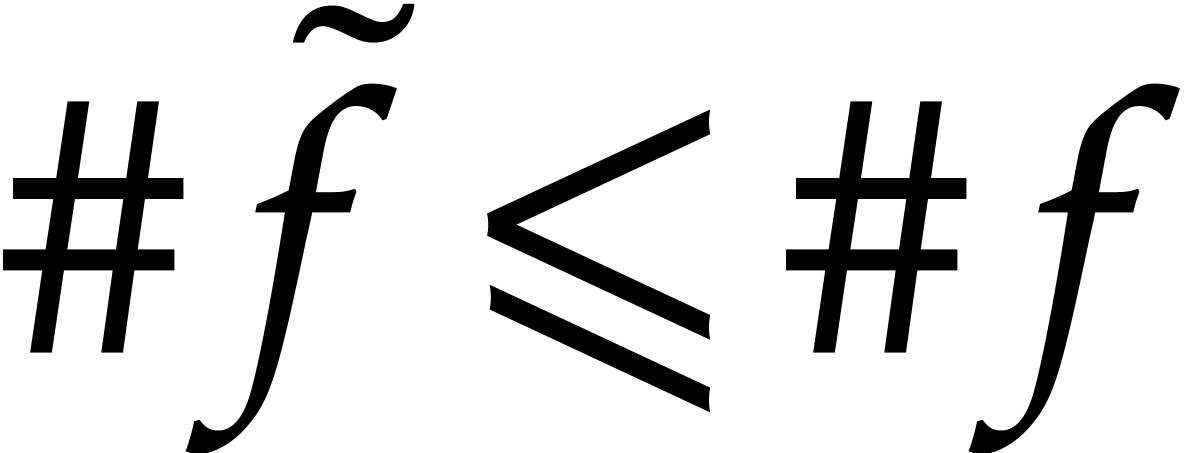 and
and 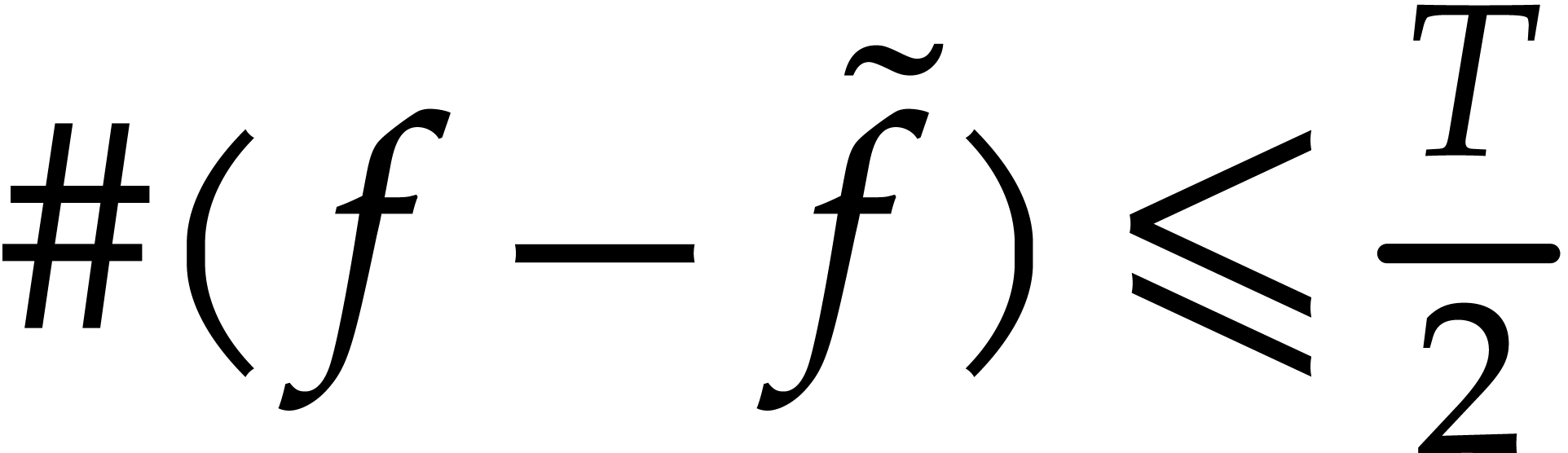 .
.
be as in Theorem 2.5,
with as in -approximation of in
time and which succeeds with probability at
least  .
.
Proof. We first compute the required random
parameters as in Lemma 4.5. This takes time and succeeds with probability at least 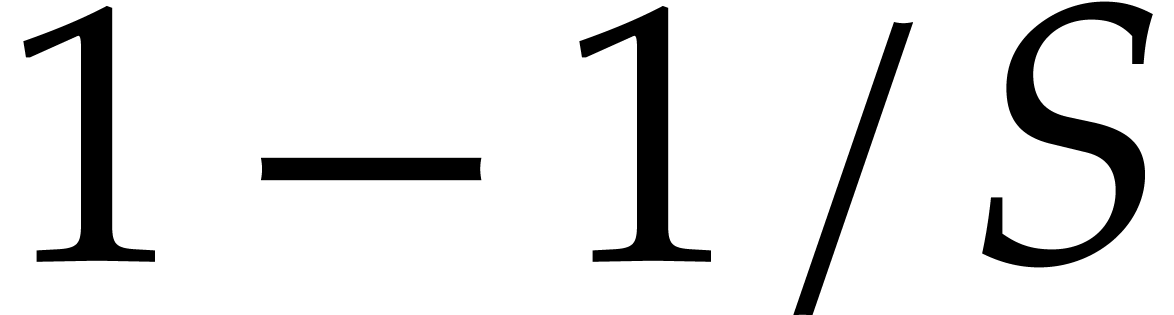 . We next compute using
Lemma 4.2, which can be done in time
. We next compute using
Lemma 4.2, which can be done in time
We next apply Corollary 4.7 and compute a faithful exponent
encoding for , in time . By Lemma 4.4, this
computation fails with probability at most 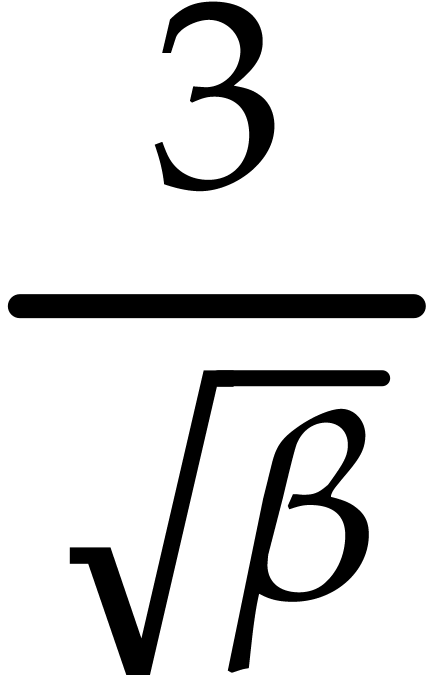 .
Moreover, in case of success, we have
.
Moreover, in case of success, we have 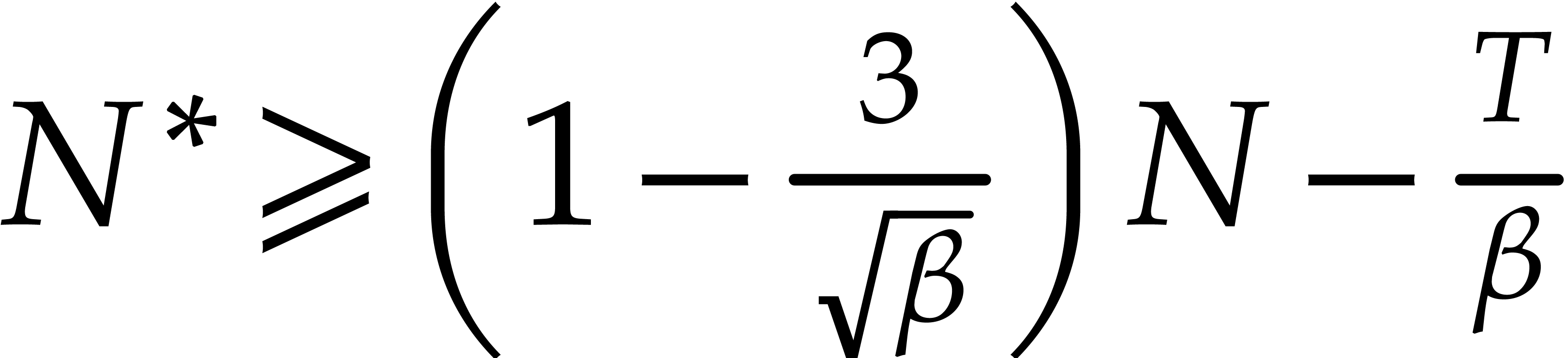 ,
still with the notation of Lemma 4.4.
,
still with the notation of Lemma 4.4.
From (4.1) and 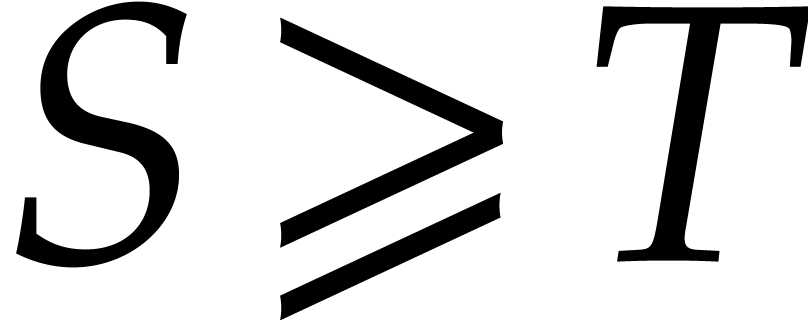 ,
we get
,
we get 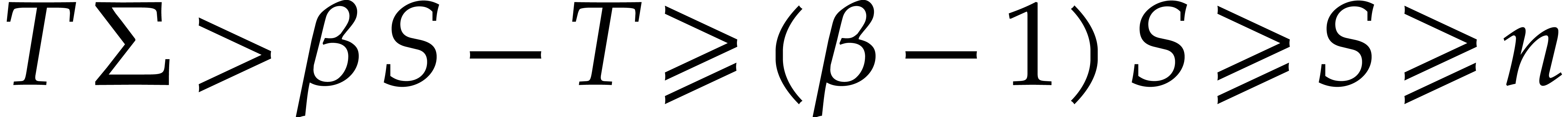 . This allows us to
apply Theorem 3.10 to the faithful exponent encoding for
. Let
. This allows us to
apply Theorem 3.10 to the faithful exponent encoding for
. Let  be the exponents of .
Consider such that there exists a -faithful term of with
be the exponents of .
Consider such that there exists a -faithful term of with 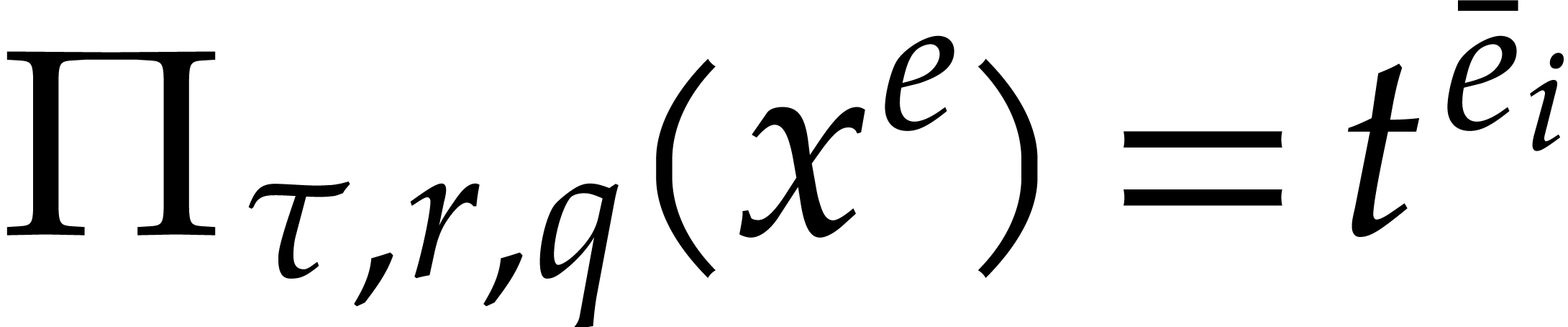 and
and 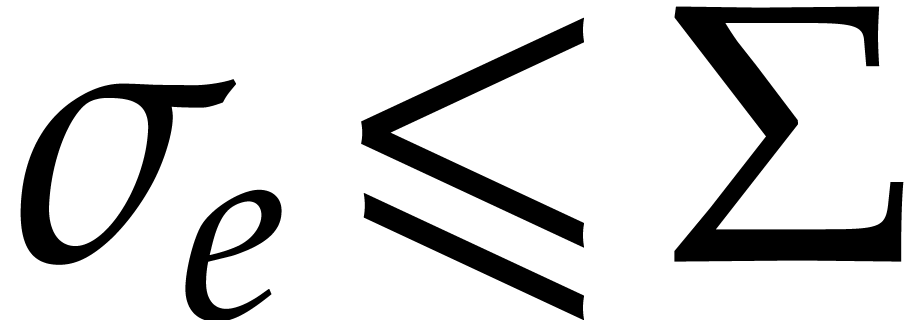 . Theorem 3.10 produces a guess
for for every such
. Theorem 3.10 produces a guess
for for every such  .
With probability at least
.
With probability at least
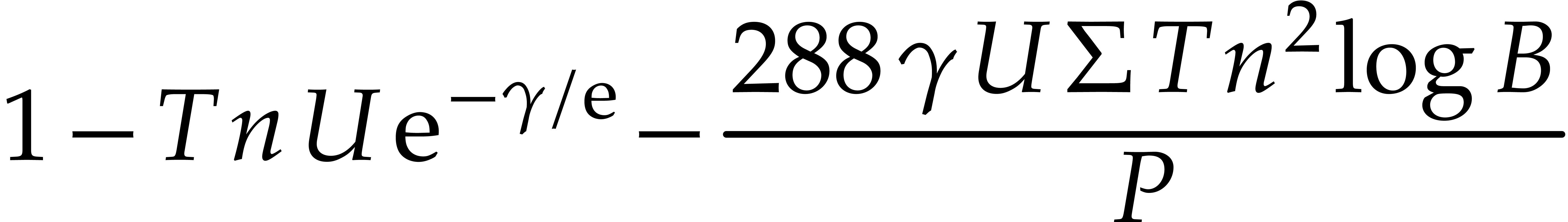
these guesses are all correct. The running time of this step is bounded by
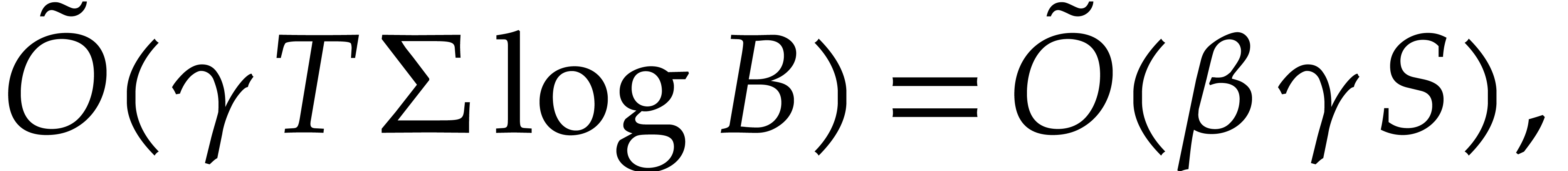
since  , , and
, , and 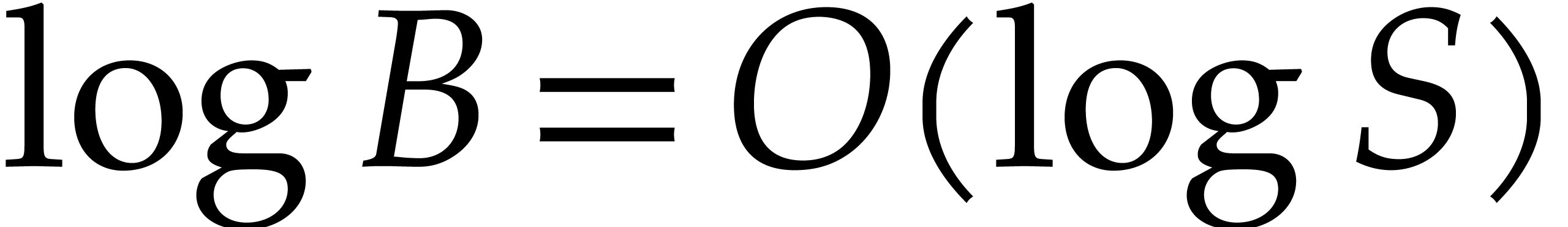 .
.
Below we will show that
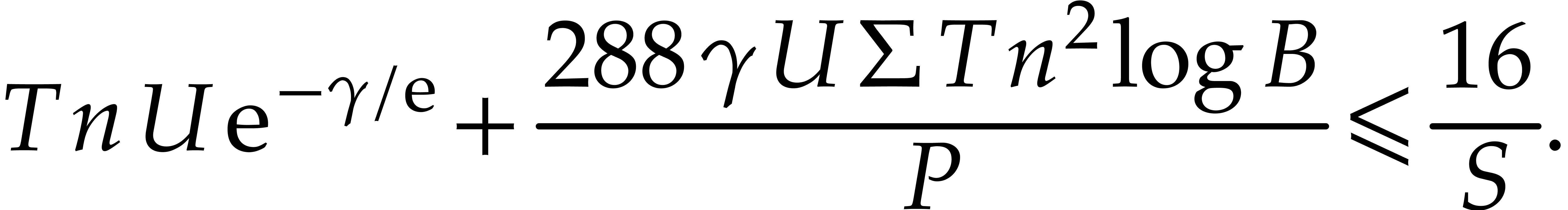 |
(4.9) |
Let 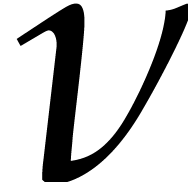 be the smallest integer such that
be the smallest integer such that 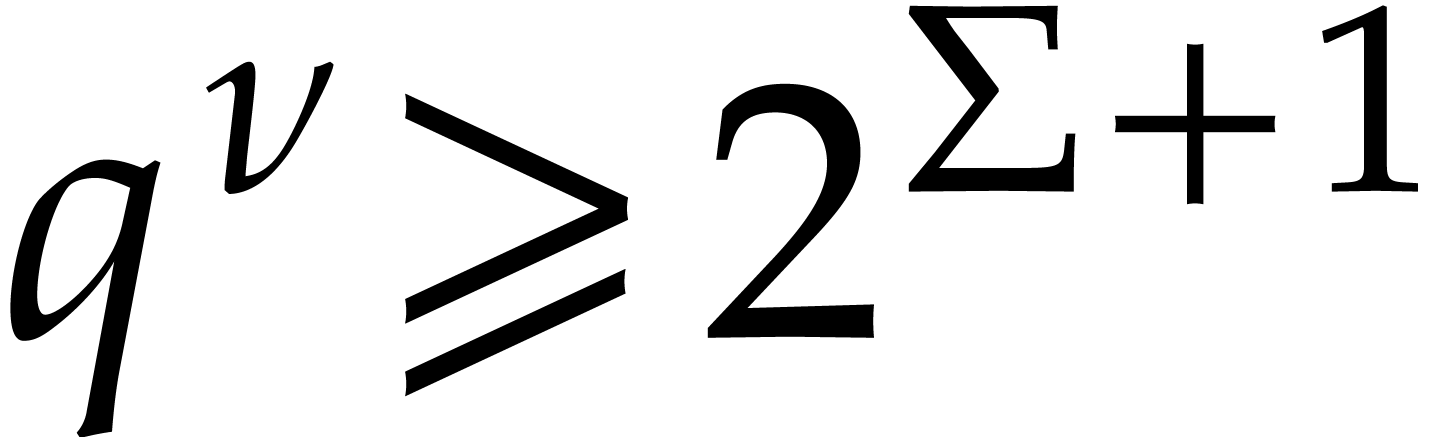 . We finally compute using Lemma 4.3, which can be done in time
. We finally compute using Lemma 4.3, which can be done in time
Let 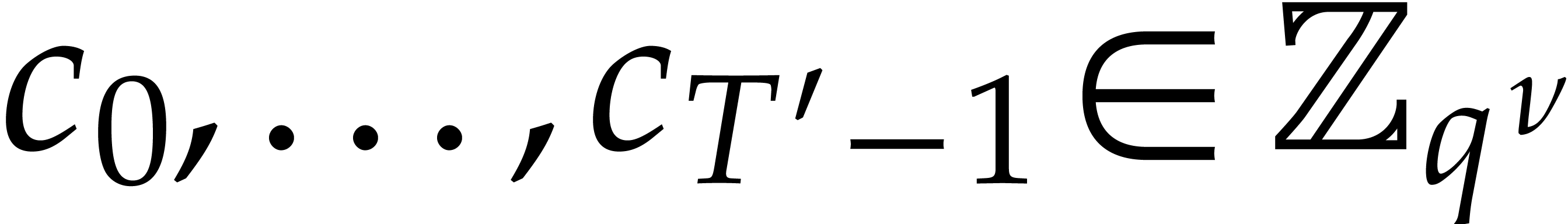 be such that
be such that

For every -faithful term of with
and  , we have
, we have
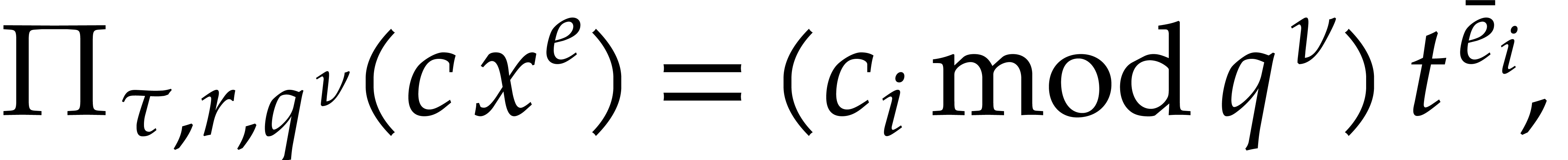
so we can recover 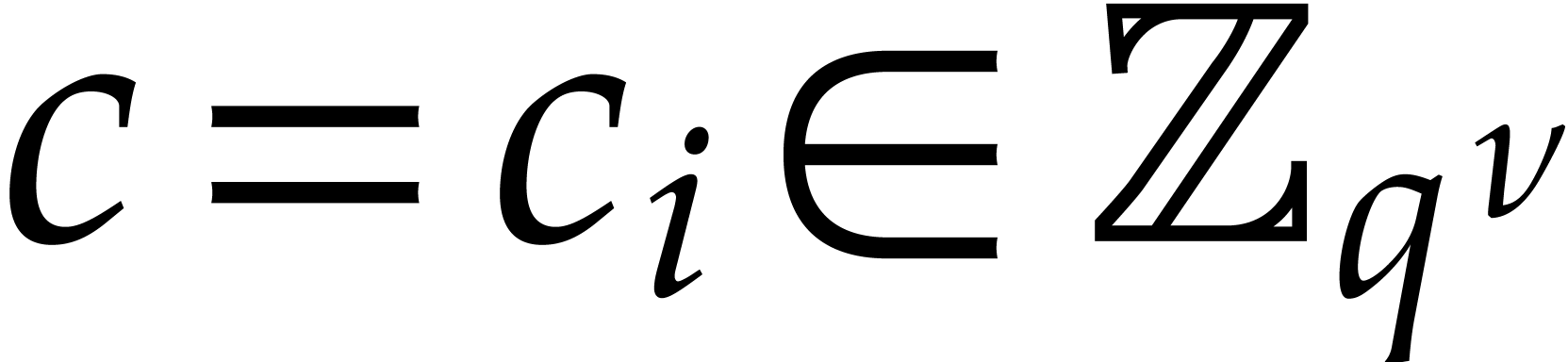 from .
from .
With a probability at least ,
all the above steps succeed. In that case, we clearly have 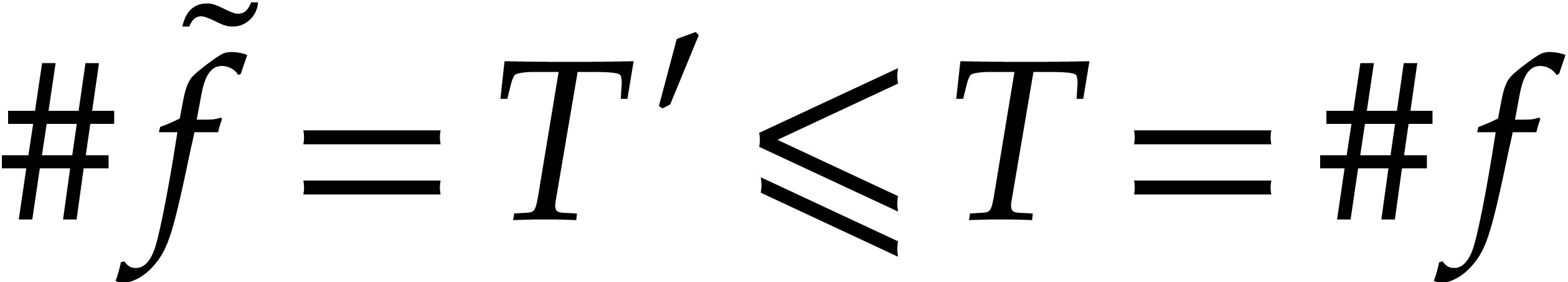 . Let
. Let 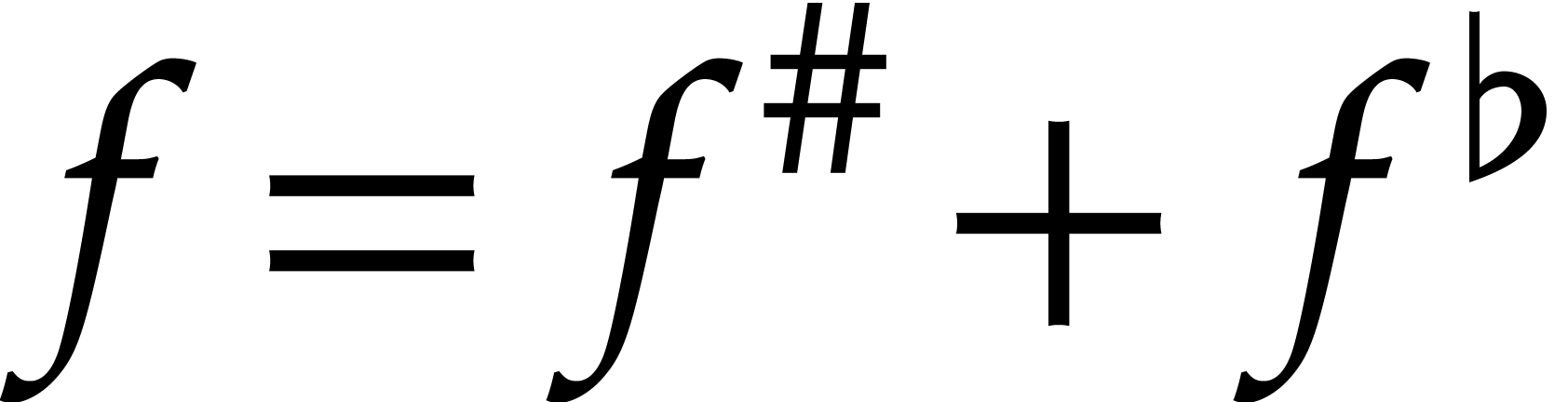 ,
where
,
where  (resp.
(resp.  ) is the sum of the terms of bit-size
) is the sum of the terms of bit-size  (resp. ),
so that
(resp. ),
so that 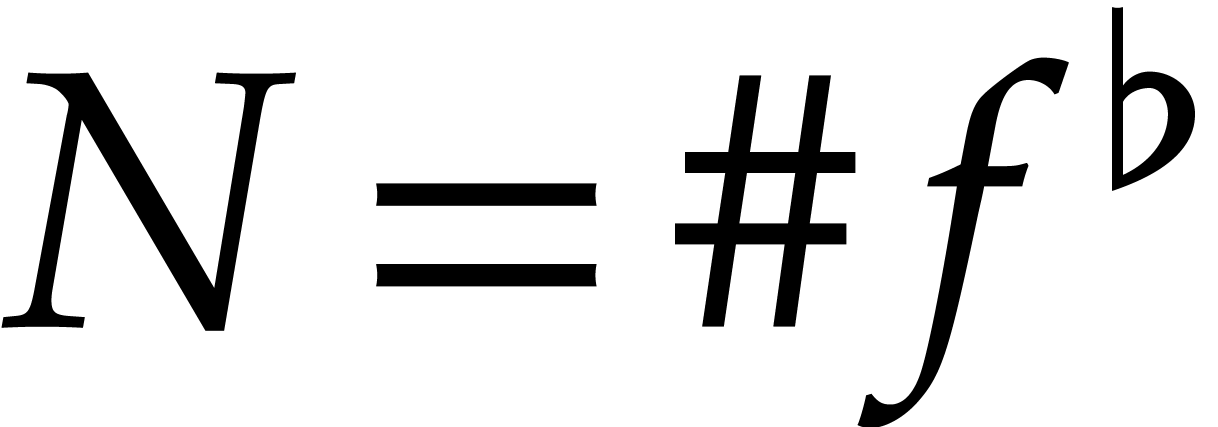 . Then the definition
of implies that
. Then the definition
of implies that 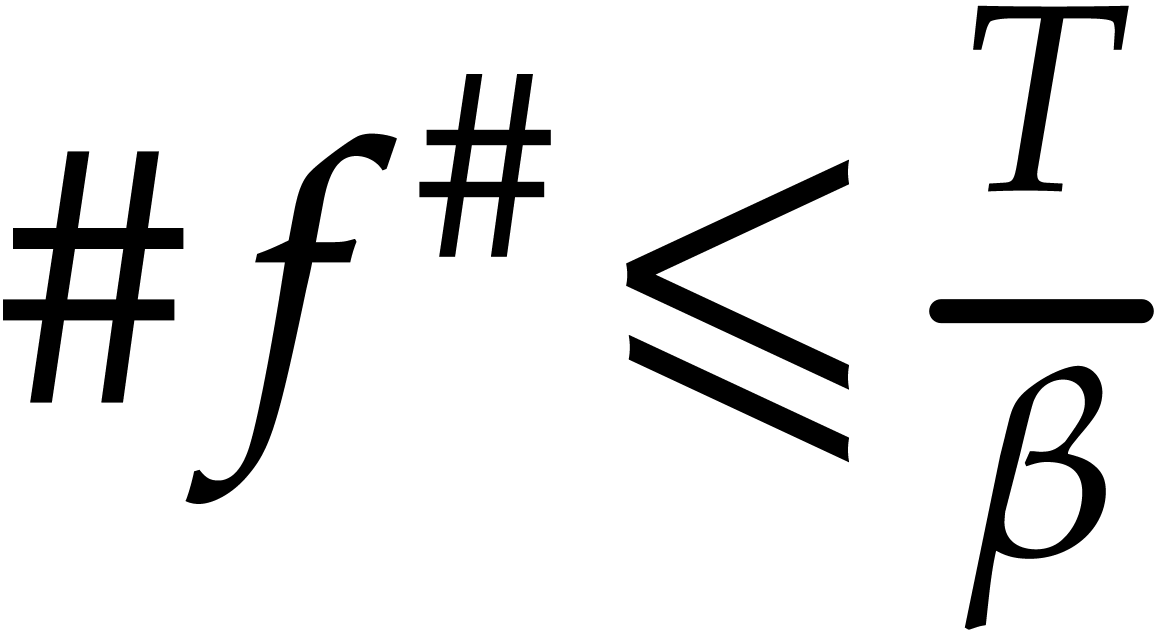 and
and
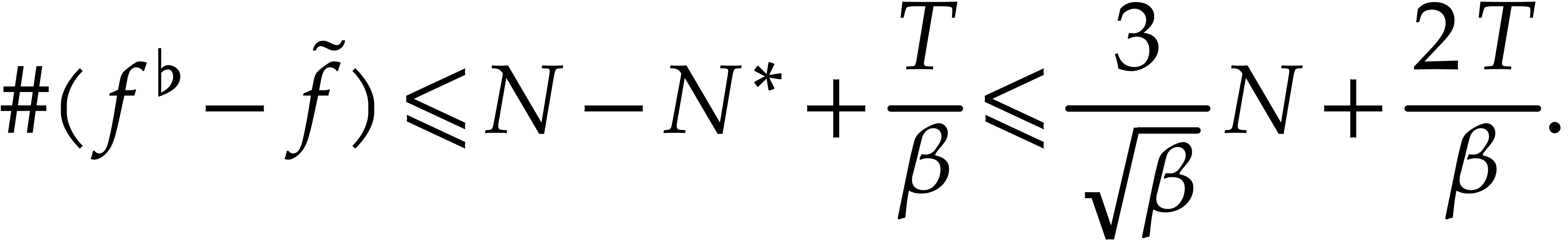
Consequently,
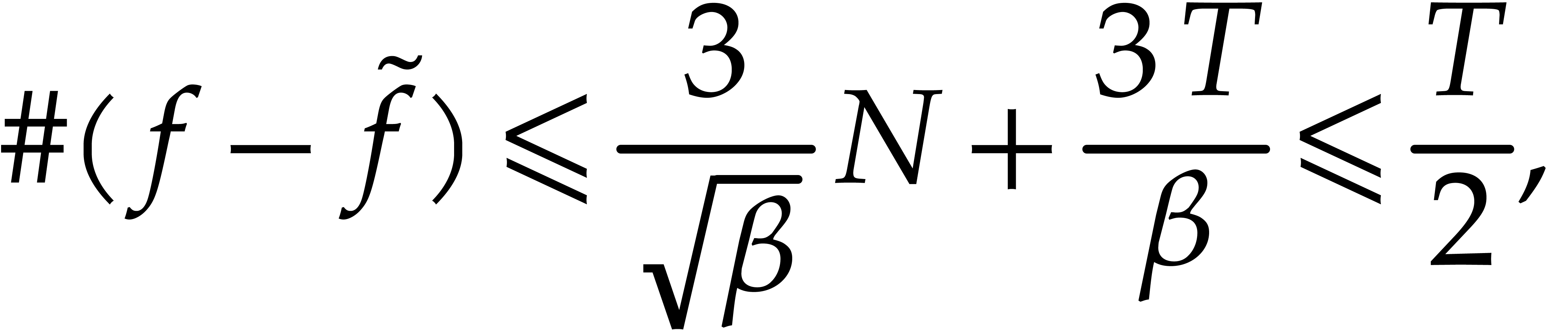 |
(4.10) |
which means that 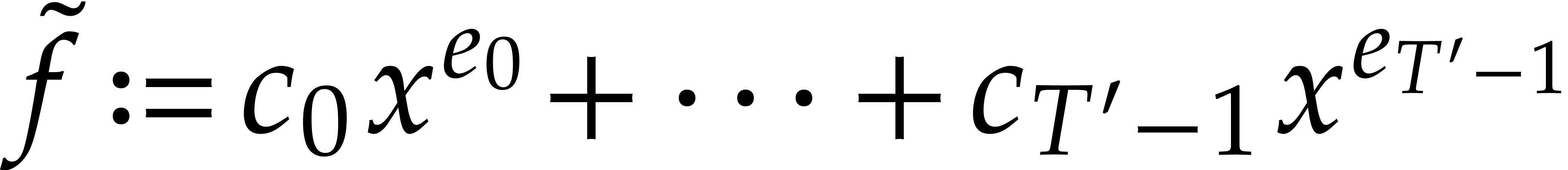 is a -approximation of .
is a -approximation of .
In order to conclude, it remains to prove the claimed inequality  and the inequalities
and the inequalities  ,
,
 ,
, 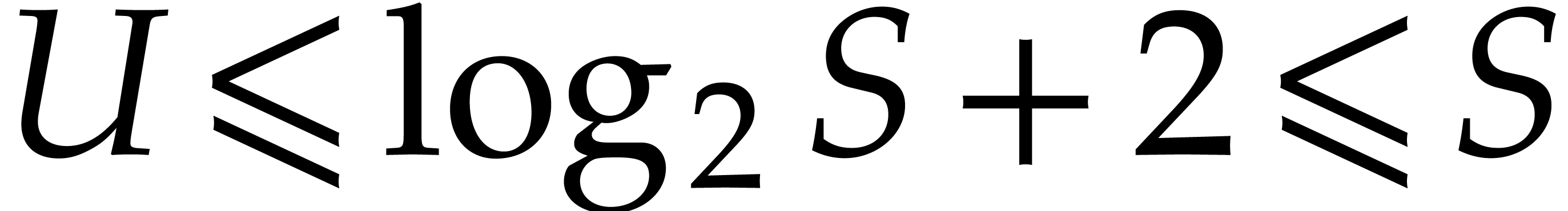 , we have
, we have
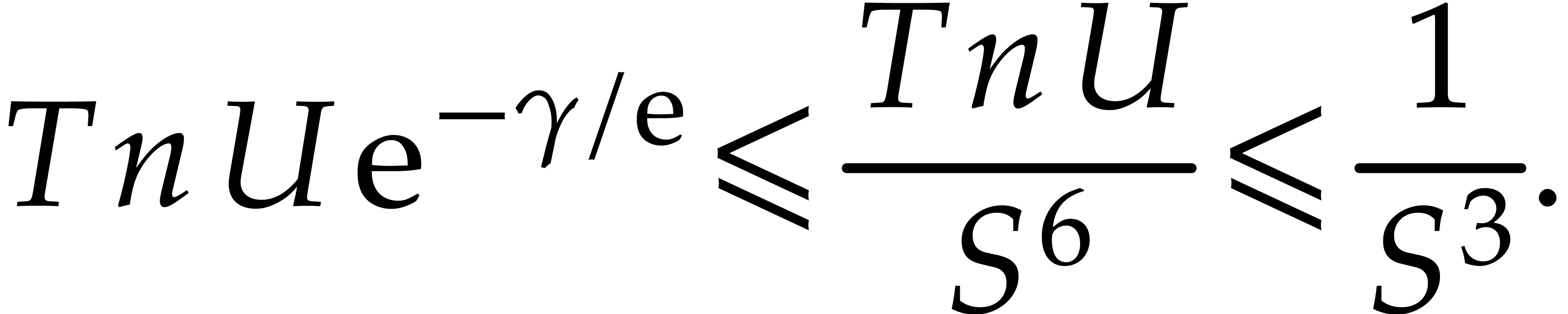 |
(4.11) |
From 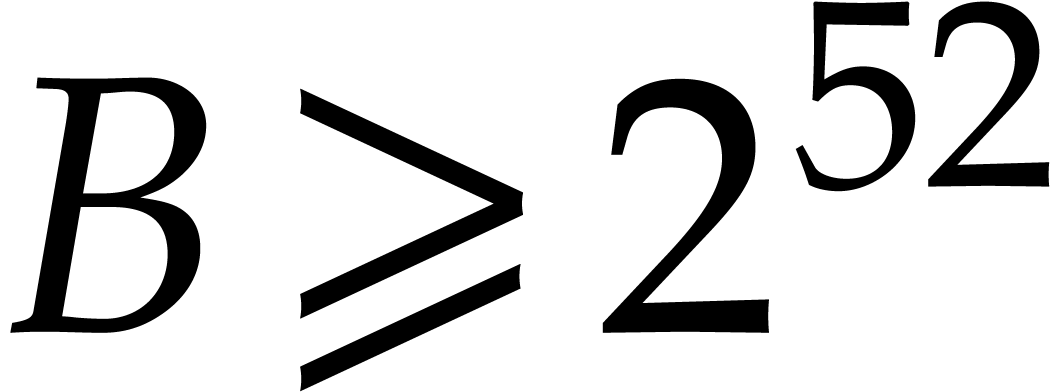 and therefore
and therefore 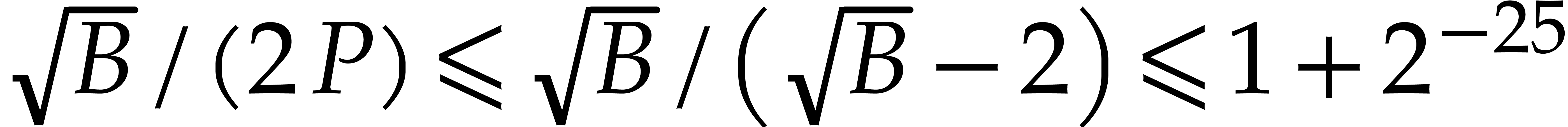 . So the
inequality
. So the
inequality 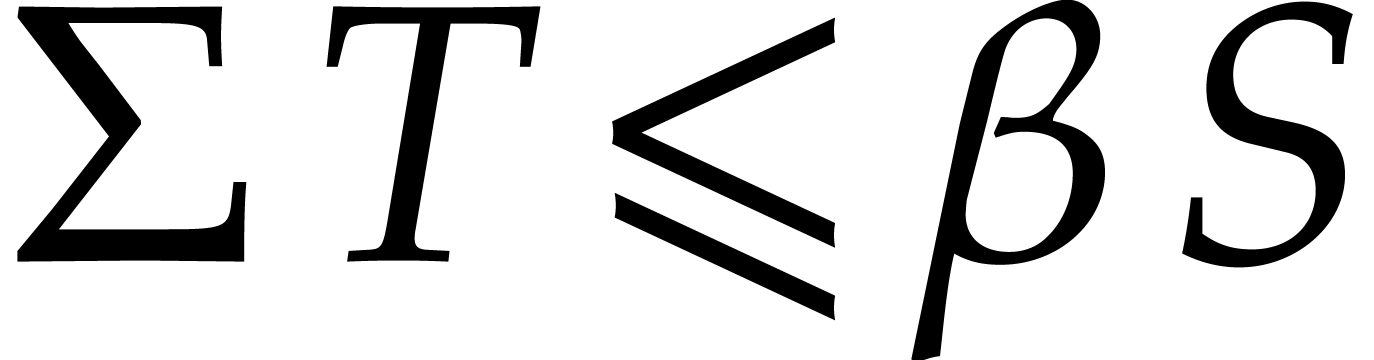 yields
yields
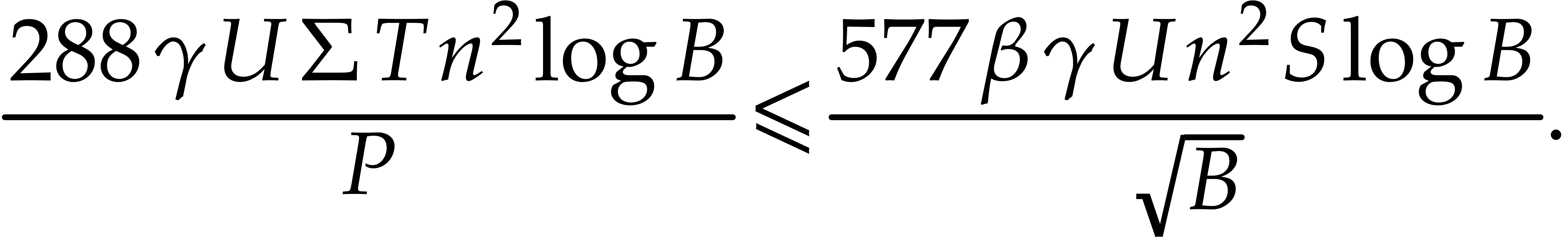 |
(4.12) |
Let us analyze the right-hand side of . First of all, we have
It follows that
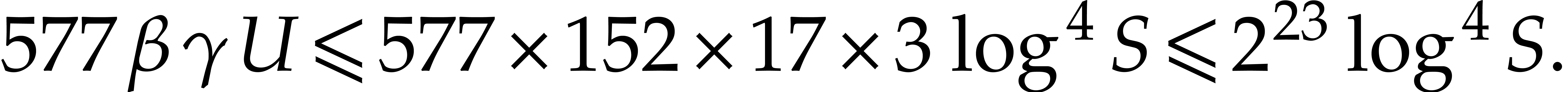 |
(4.13) |
Now the function 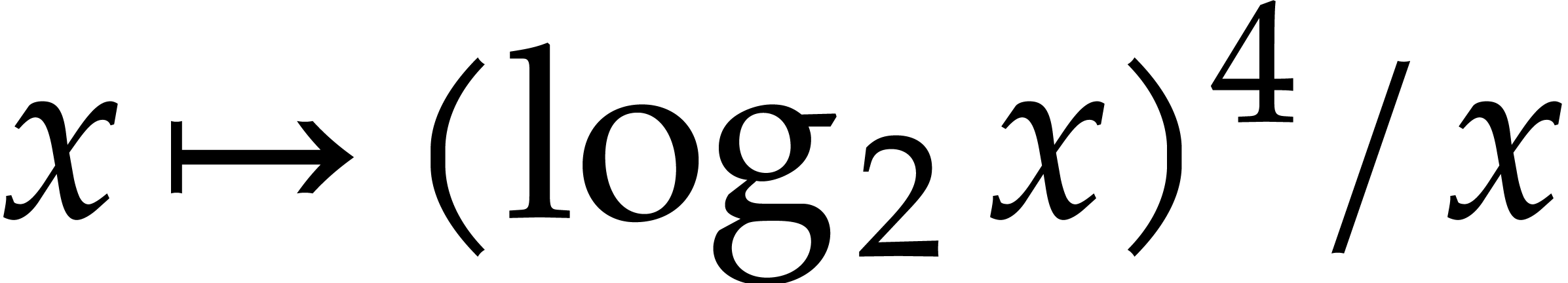 is decreasing for
is decreasing for 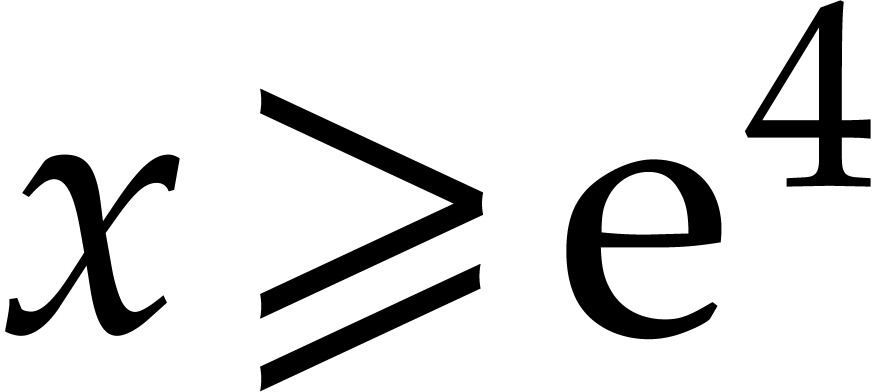 . Consequently,
. Consequently,
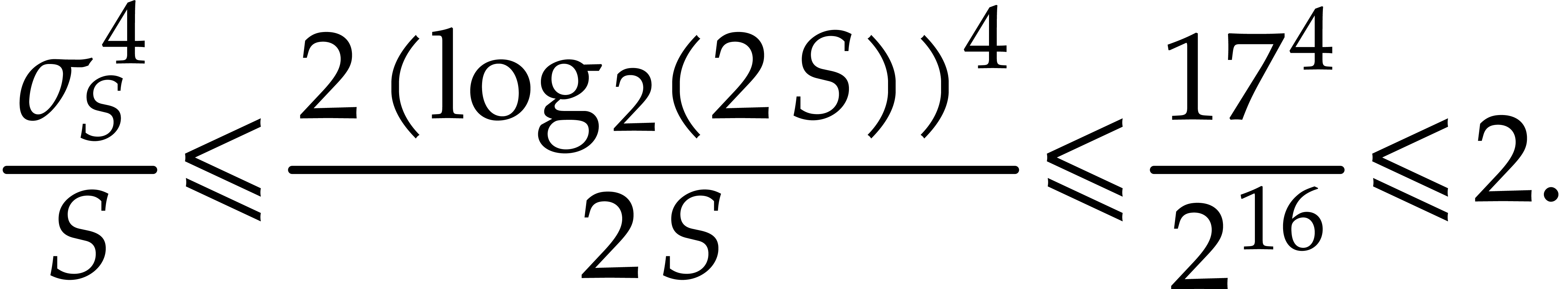
Similarly, 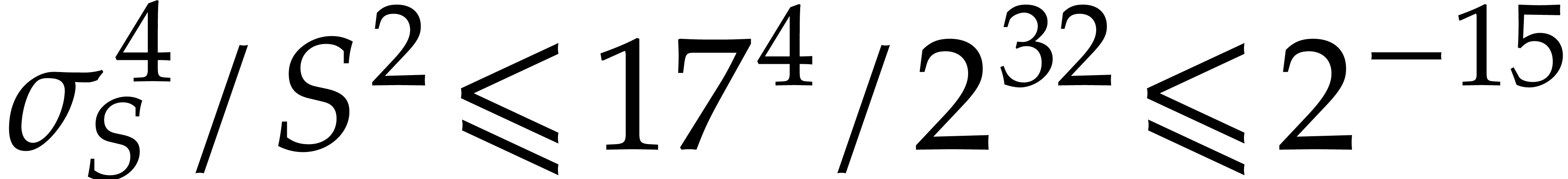 . Hence,
. Hence,
 |
|
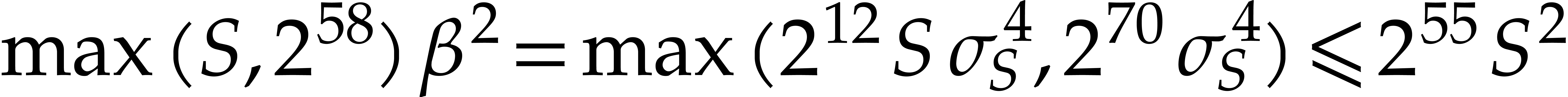 |
|
 |
|
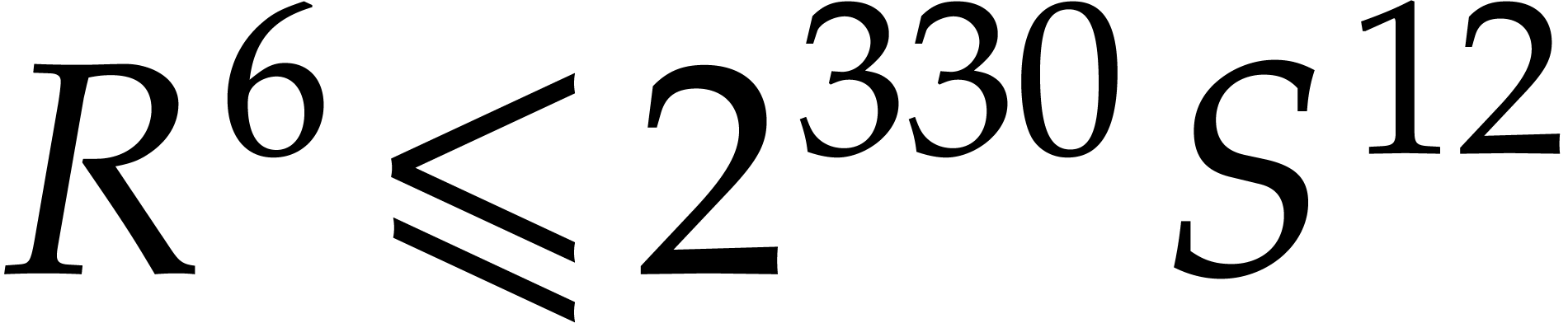 |
|
 |
|
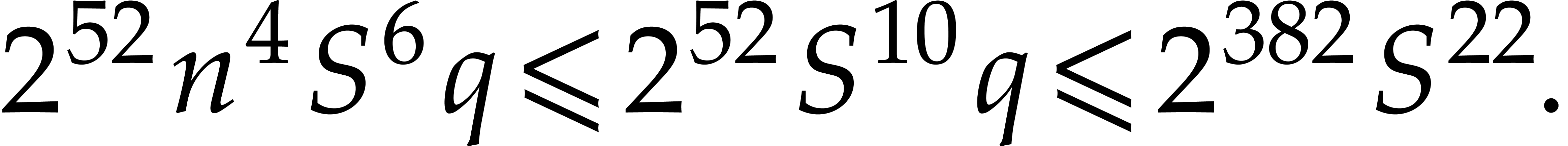 |
(by (4.7)) |
This yields
 |
(4.14) |
Combining
 |
(4.15) |
The inequalities
Instead of just half of the coefficients, it is possible to compute any
constant portion of the terms with the same complexity. More precisely,
given , we say that is a 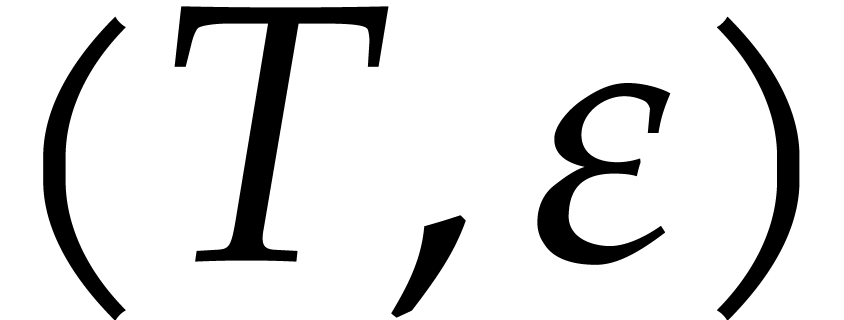 -approximation
of if and
-approximation
of if and 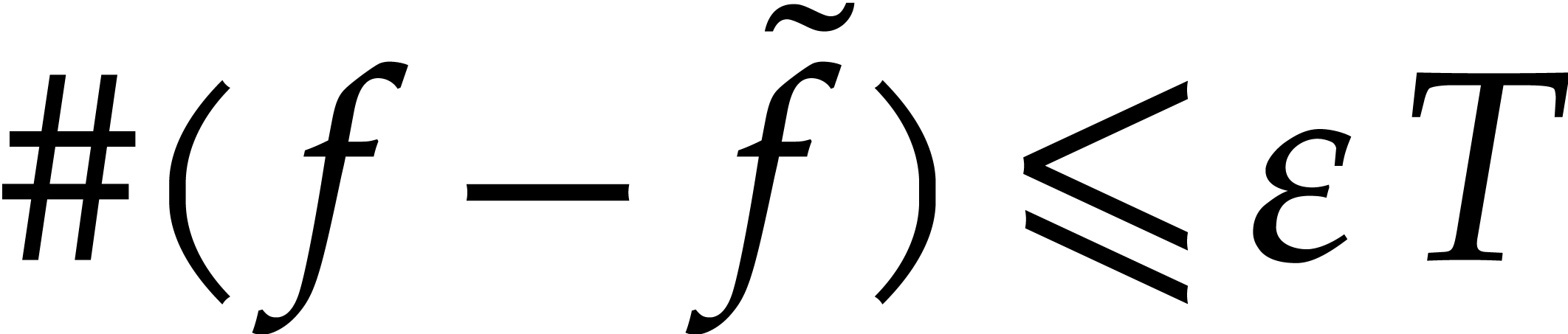 .
.
be as in Theorem 2.5,
with as in , there is a Monte
Carlo algorithm that computes a 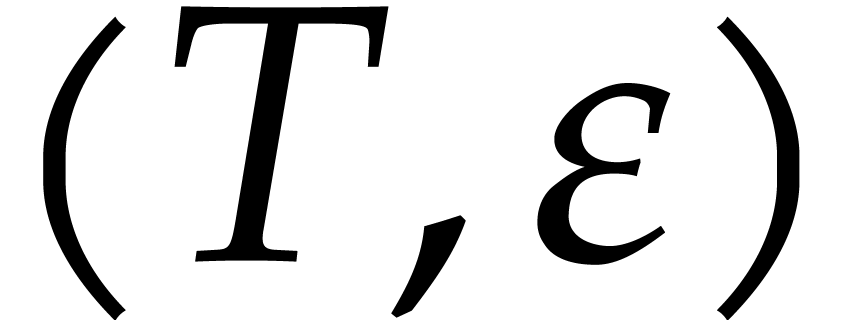 -approximation
of in time
-approximation
of in time 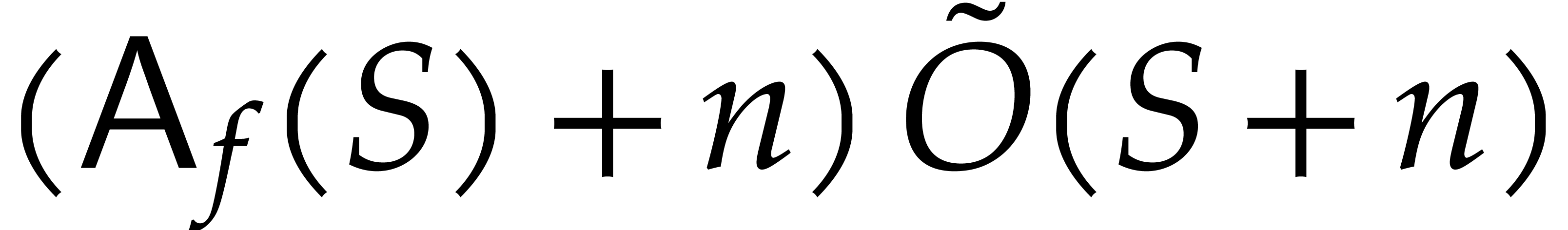 and which
succeeds with probability at least .
and which
succeeds with probability at least .
Proof. When 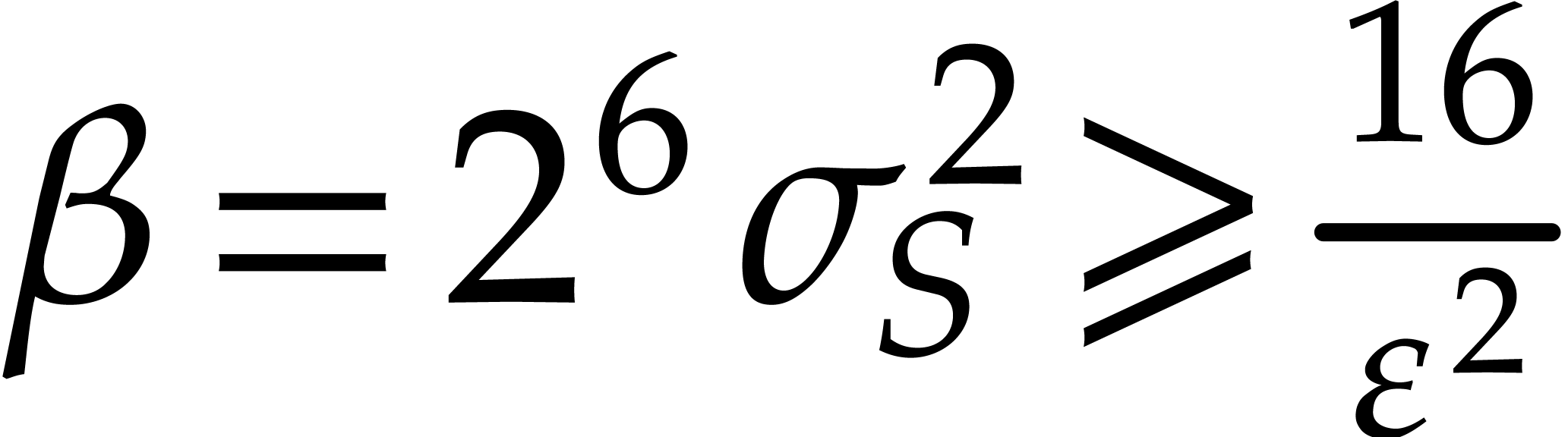 we have
we have
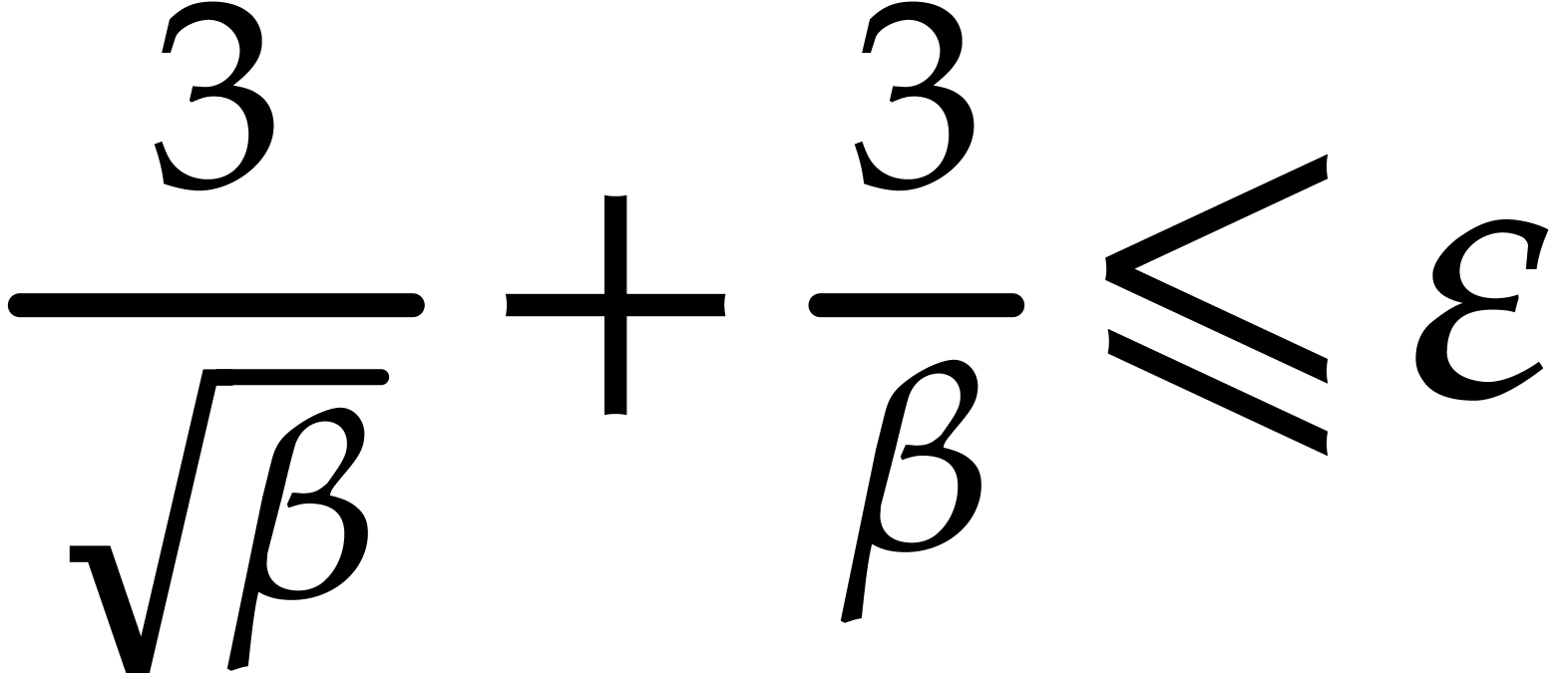 , so (4.10)
becomes
, so (4.10)
becomes 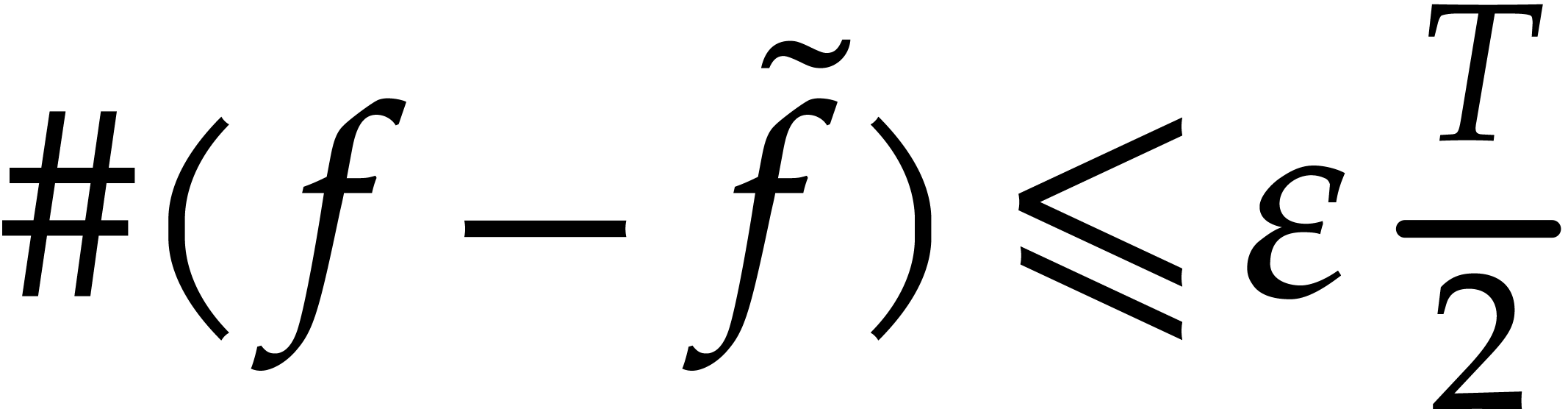 . In addition, we
have
. In addition, we
have 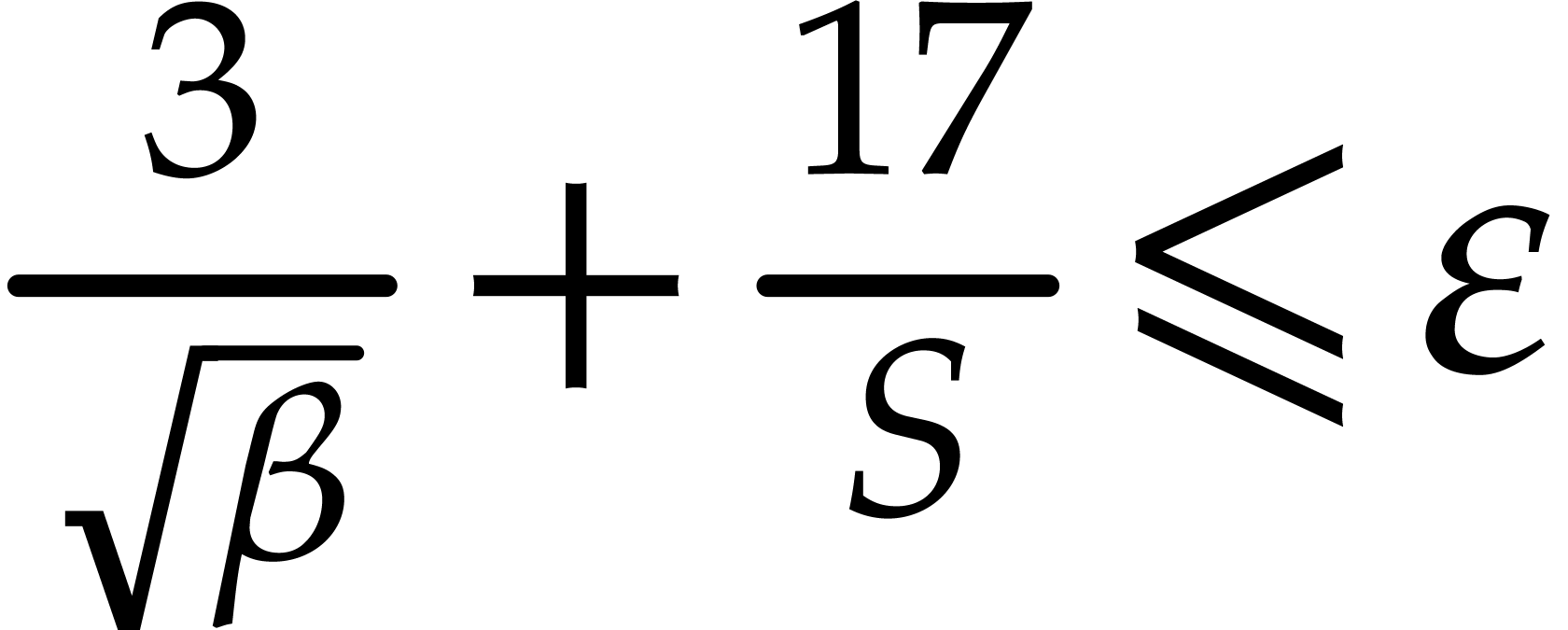 , whenever
, whenever 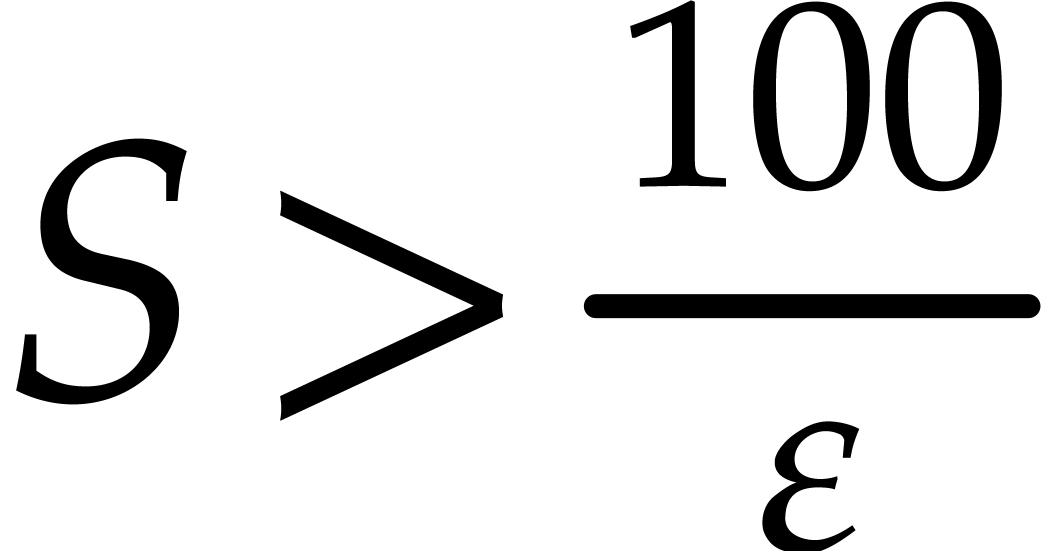 . In other words, if is
sufficiently large, then the proof of Lemma 4.8 actually
yields a -approximation of
. We finally note that
. In other words, if is
sufficiently large, then the proof of Lemma 4.8 actually
yields a -approximation of
. We finally note that 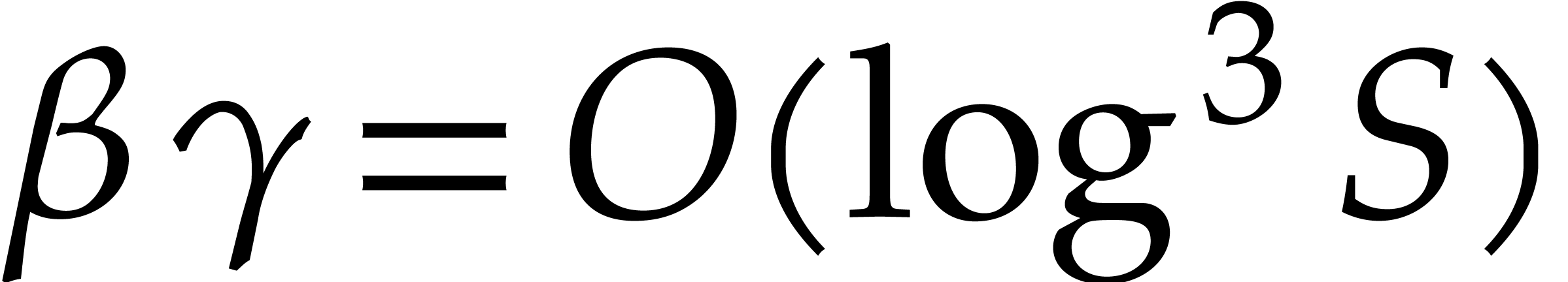 .
.
Once an approximation of the sparse
interpolation of is known, we wish to obtain
better approximations by applying the same algorithm with in the role of .
This requires an efficient algorithm to evaluate . In fact, we only need to compute projections of
as in Lemma 4.2 and to evaluate
at geometric sequences as in Lemma 4.3.
Building a blackbox for turns out to be
suboptimal for these tasks. Instead, it is better to use the following
lemma.

where 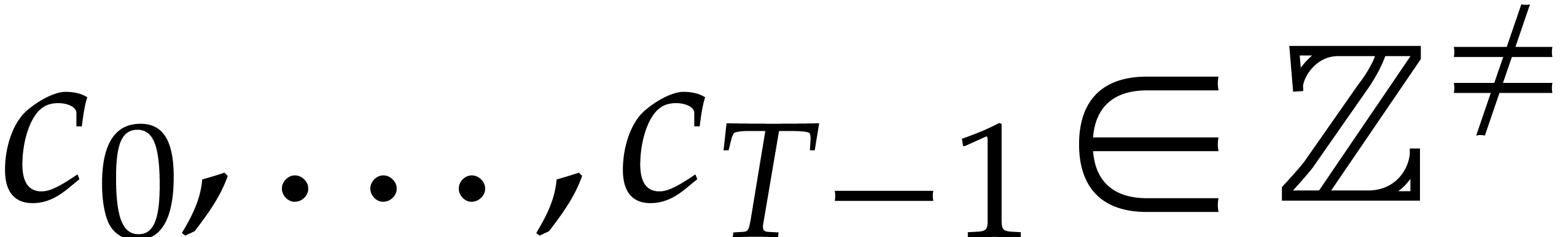 and ,
let
and ,
let  , let
be as in Theorem 2.5, and let be
in .
, let
be as in Theorem 2.5, and let be
in .
We can compute 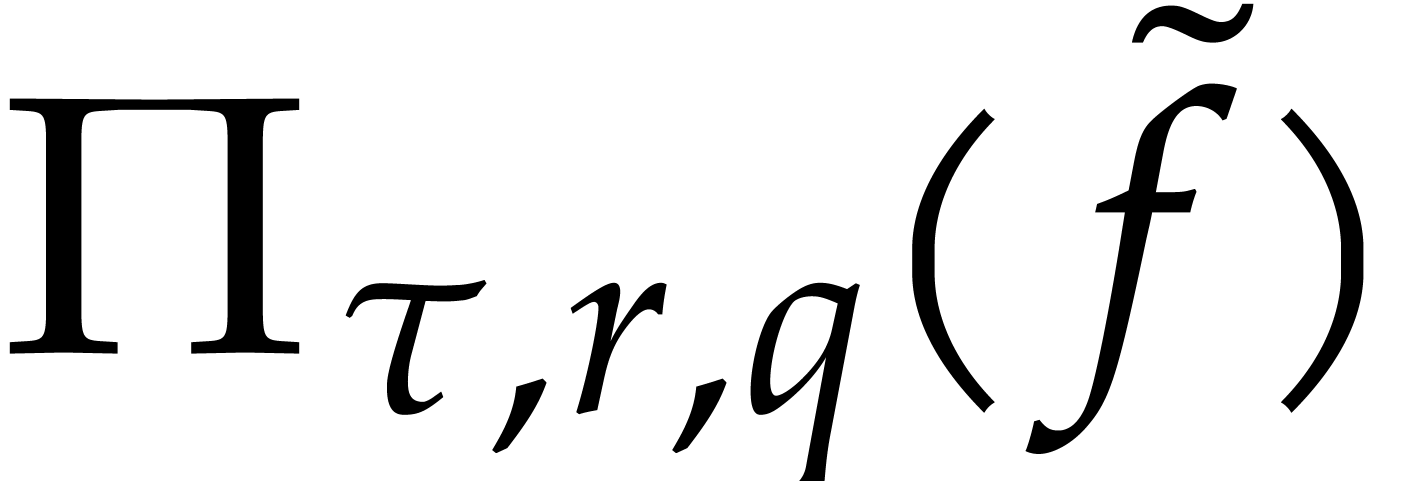 in time
in time
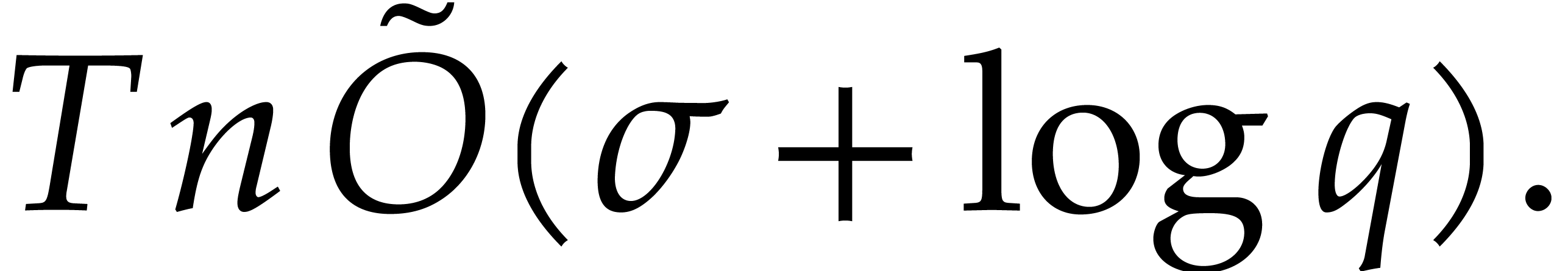
Given 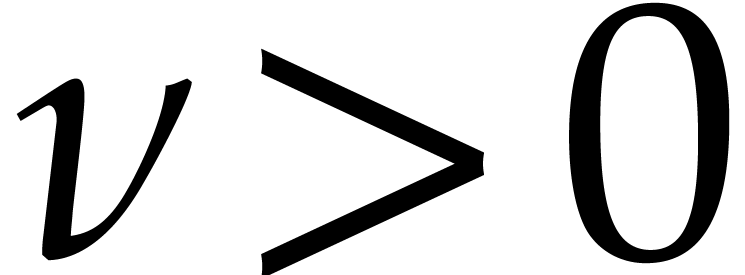 ,
,  , an element
, an element  of
order , and , we can compute
of
order , and , we can compute 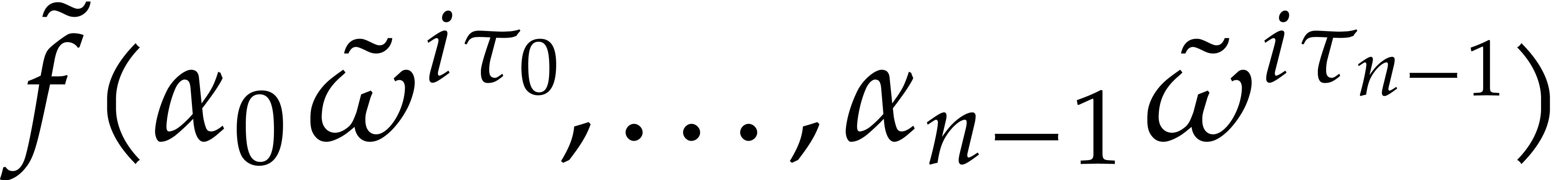 for in time
for in time
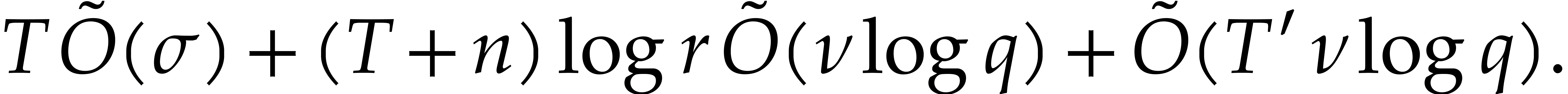
Proof. Given ,
the projections 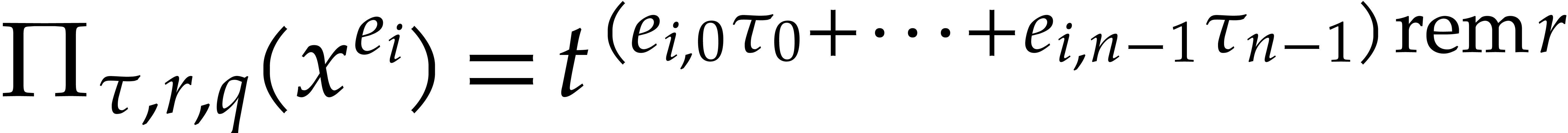 can be computed in time
can be computed in time 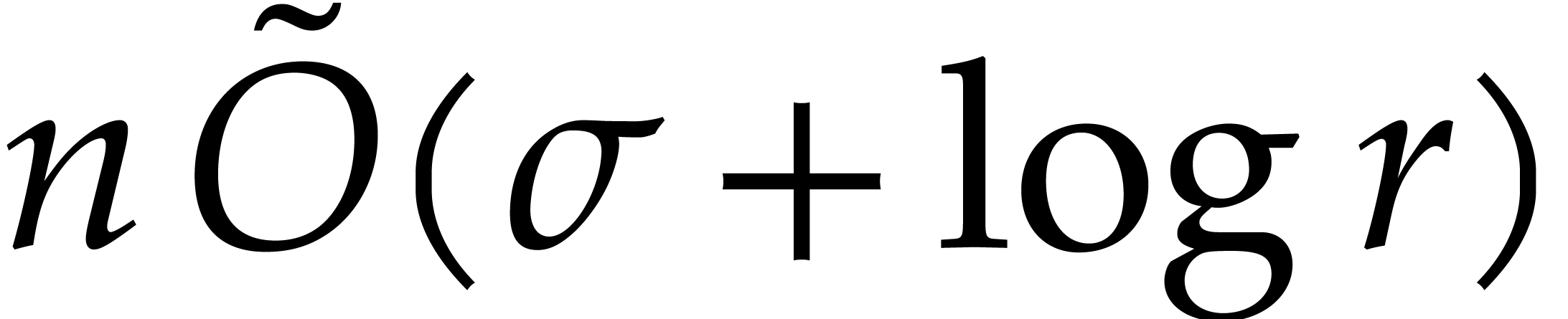 . The projections
. The projections 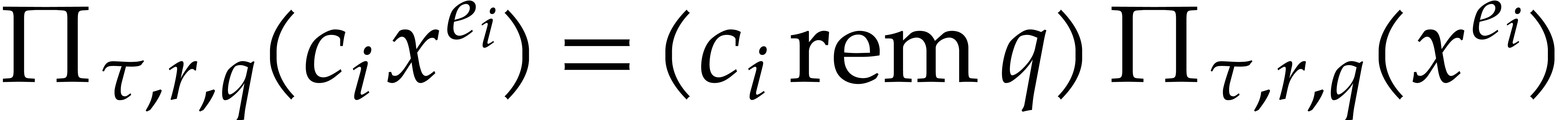 can be obtained using
can be obtained using  further operations. Adding
up these projections for
further operations. Adding
up these projections for  takes
takes 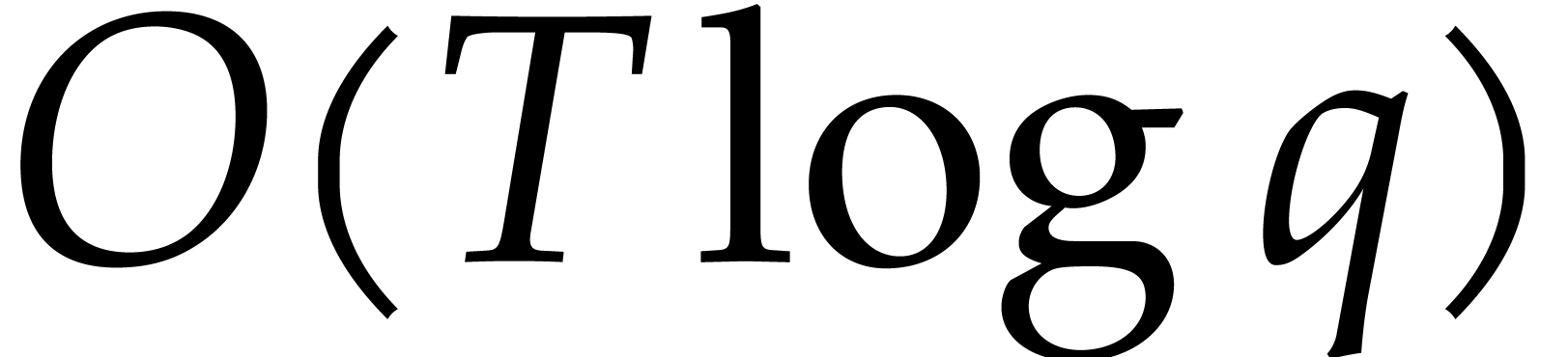 operations. Altogether, this yields (i).
operations. Altogether, this yields (i).
As for part (ii) we follow the proof of Lemma 4.3.
We first compute 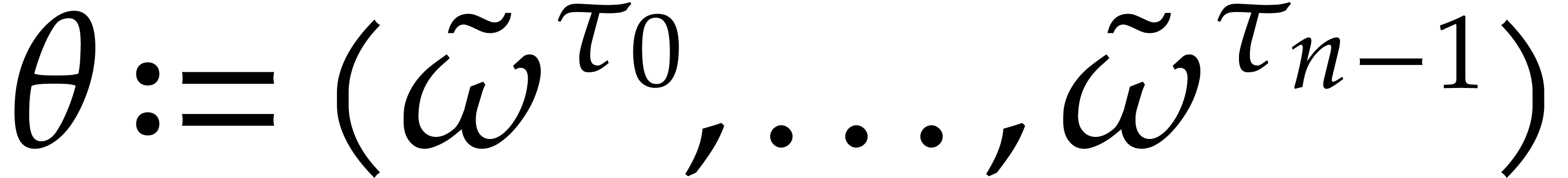 with by
binary powering. The reductions
with by
binary powering. The reductions  of exponents are
obtained in time
of exponents are
obtained in time 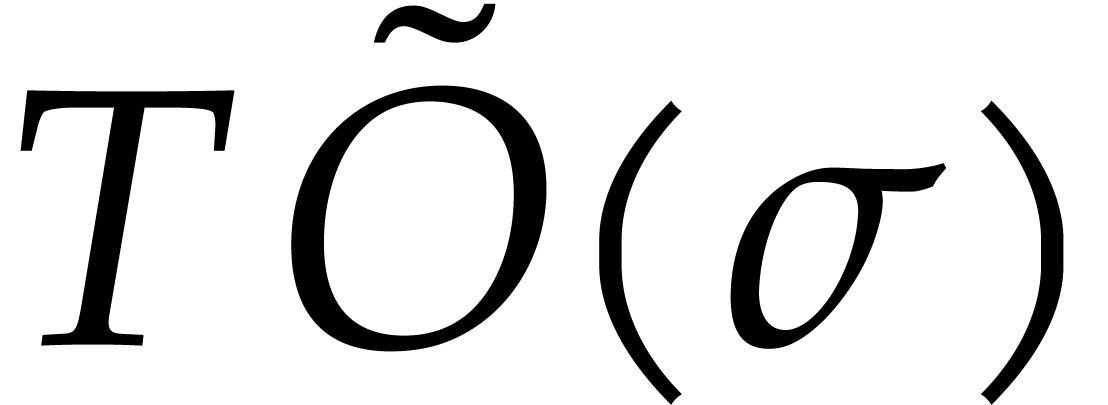 . Then, the
powers
. Then, the
powers  and
and  can be
deduced in time
can be
deduced in time 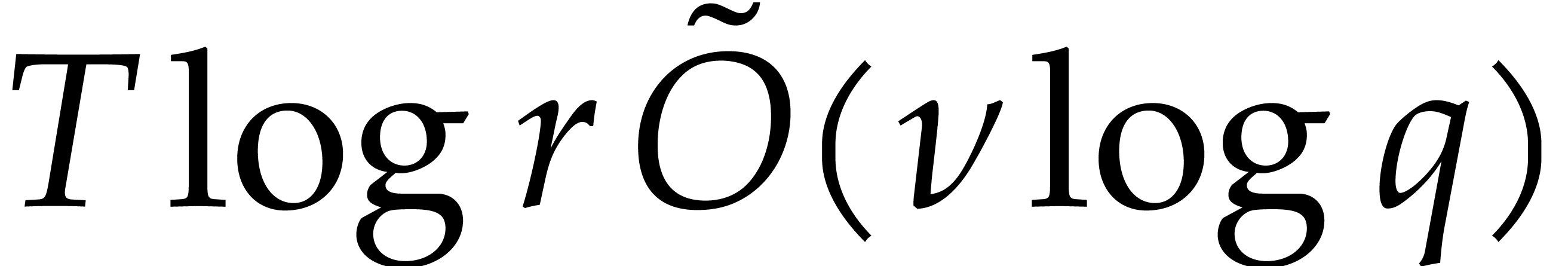 .
.
Let 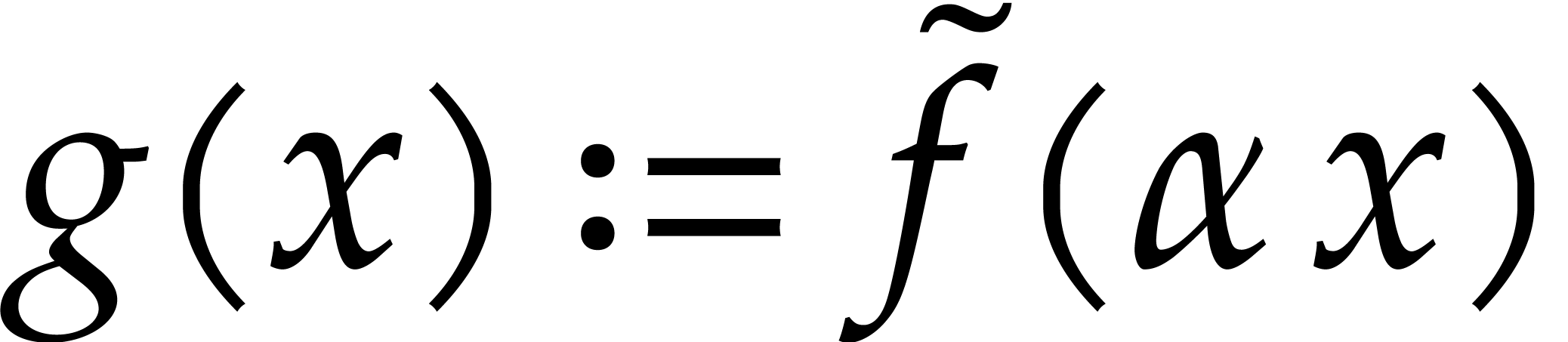 . Then we have
. Then we have
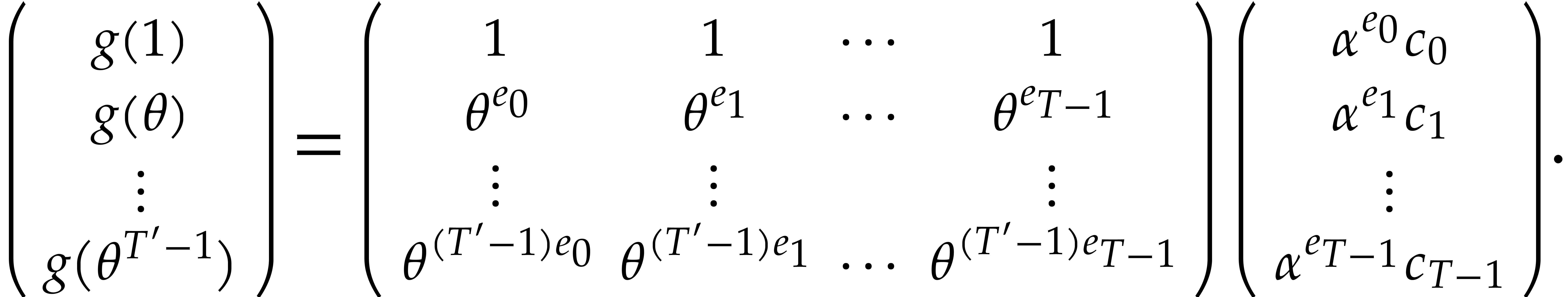
By the transposition principle, this matrix-vector product can be
computed with the same cost as multi-point evaluation of a univariate
polynomial. We conclude that 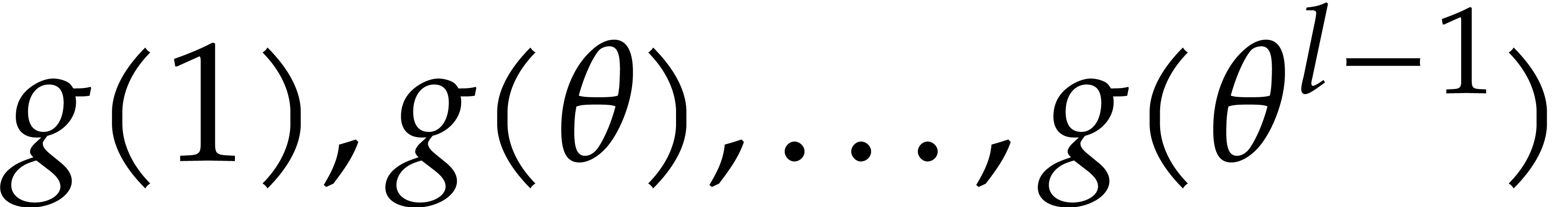 can be computed in
time
can be computed in
time 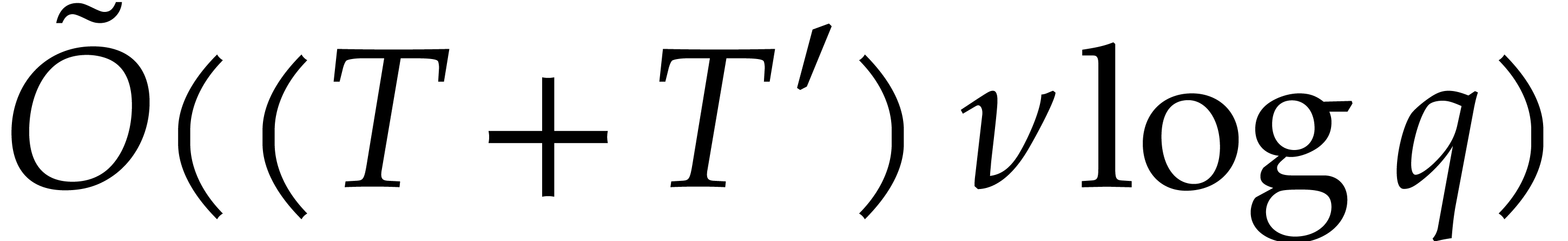 .
.
We are now ready to complete the proof of our main result.
Proof of Theorem 1.1. We set  and take ,
as in in time
and take ,
as in in time 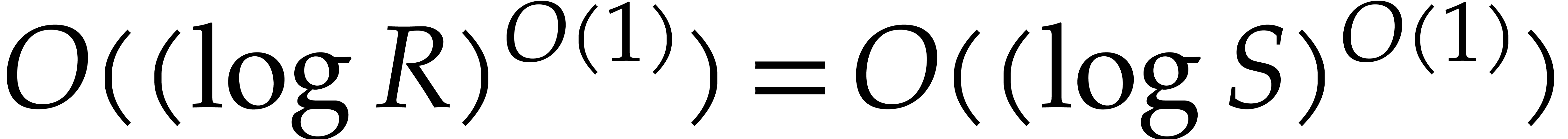 ,
with probability of success at least ,
where .
,
with probability of success at least ,
where .
Let 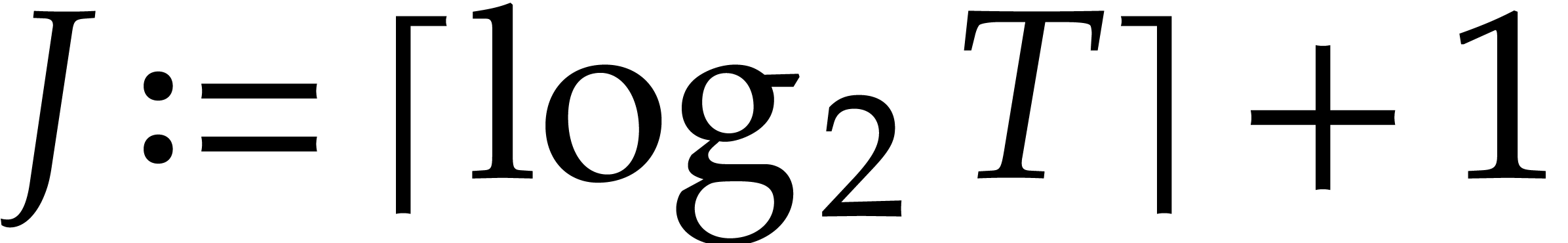 . Let
. Let 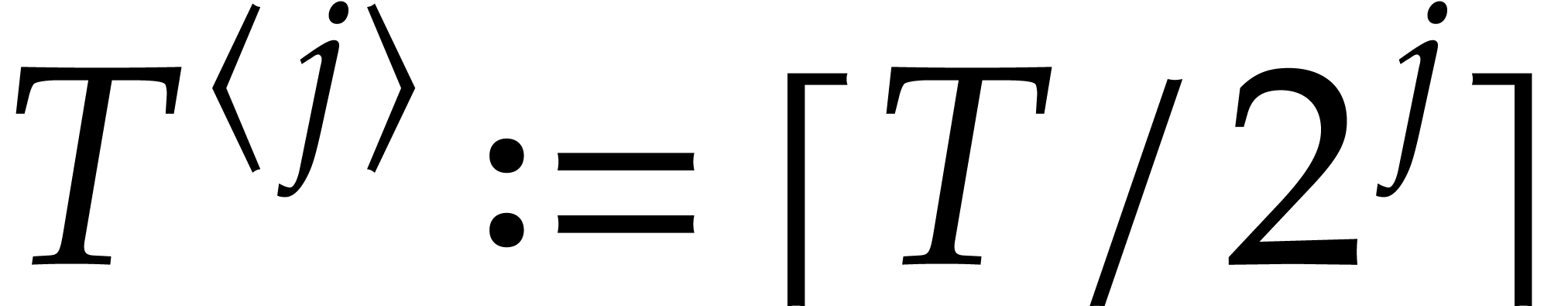 and
and 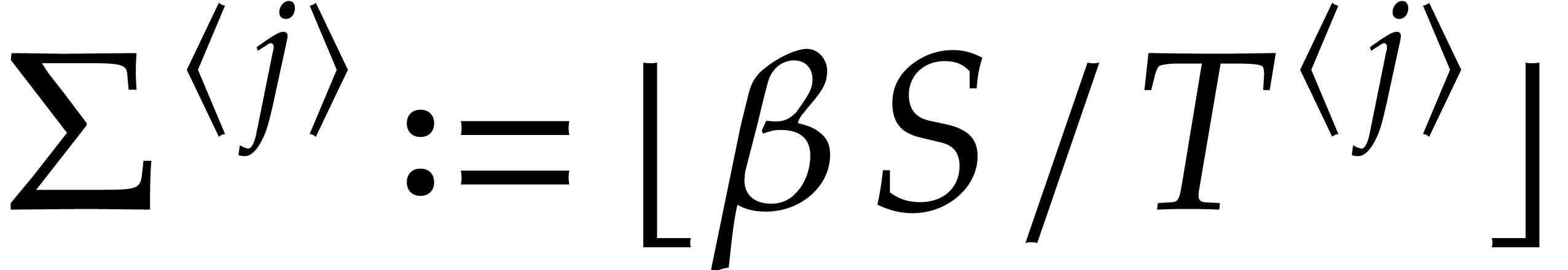 for
for 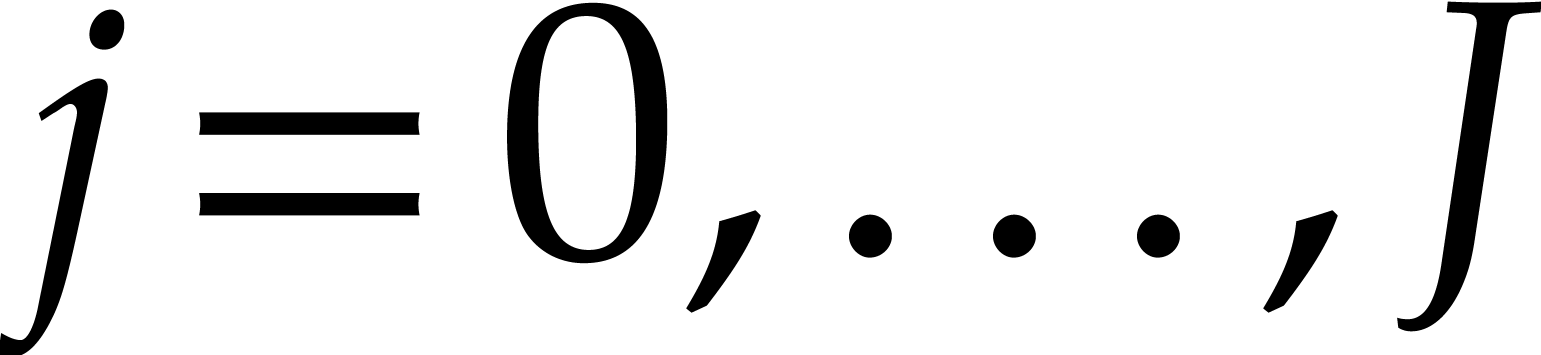 .
Starting with
.
Starting with 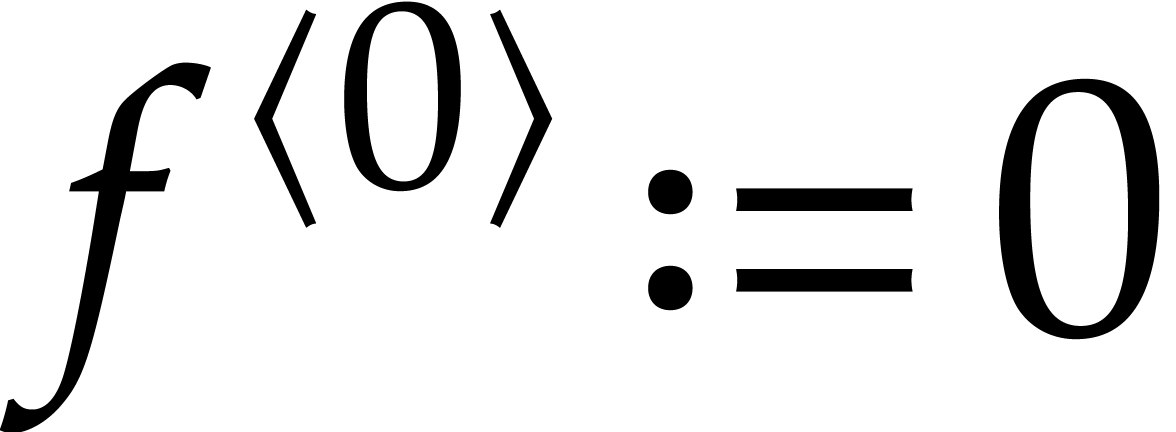 , we compute a
sequence
, we compute a
sequence 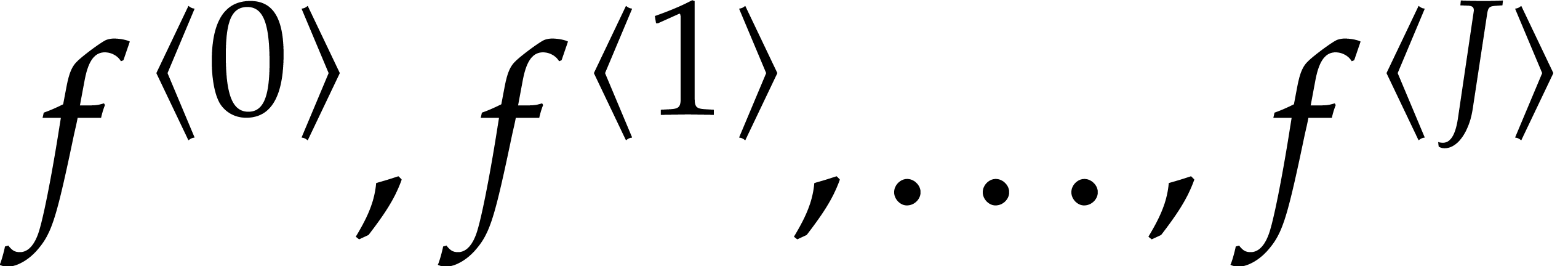 of successive approximations of as follows. Assuming that
of successive approximations of as follows. Assuming that 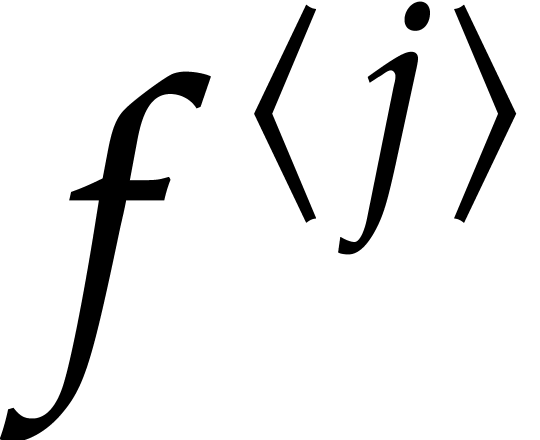 is
known for some
is
known for some  , we apply
Lemma 4.8 with
, we apply
Lemma 4.8 with 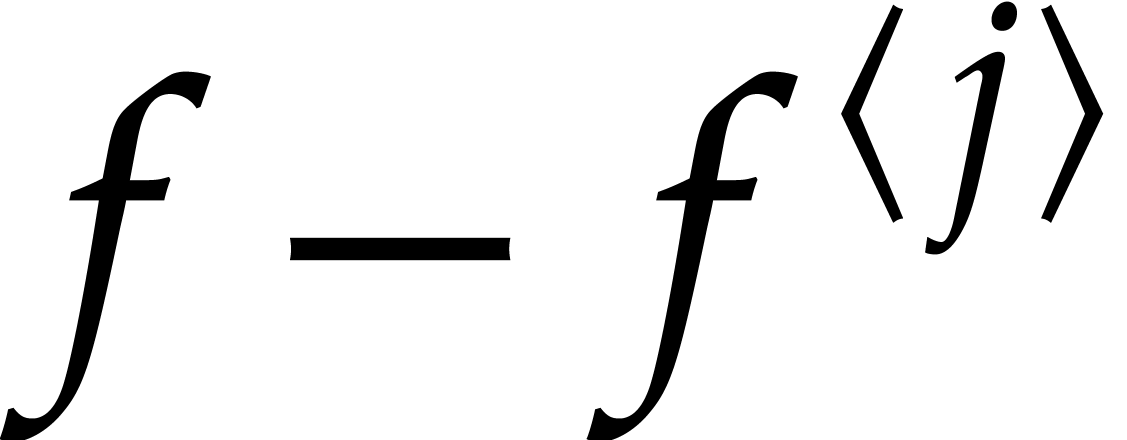 and
and 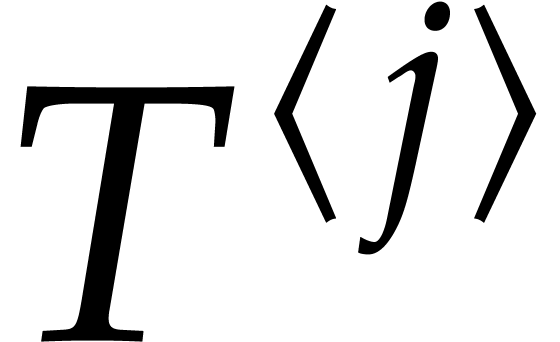 in the roles of and . With high probability, this yields a -approximation
in the roles of and . With high probability, this yields a -approximation 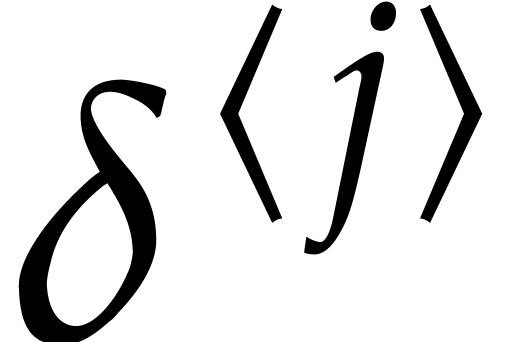 of and we set
of and we set 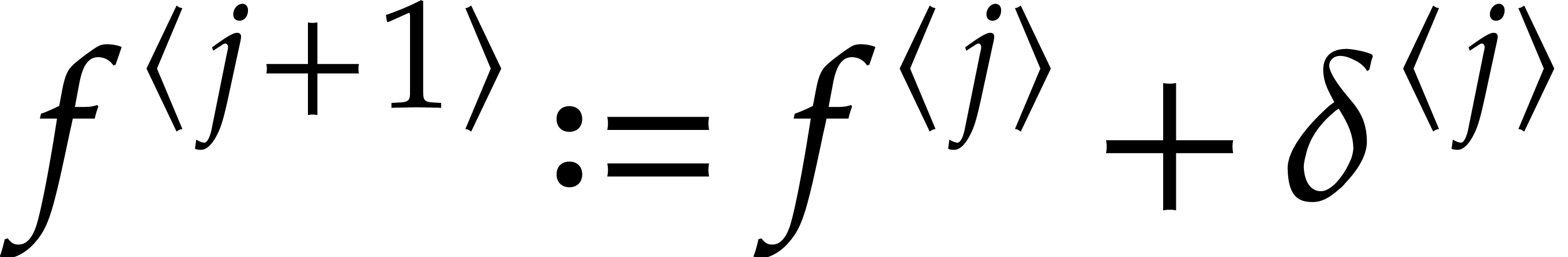 .
Taking into account in Lemma 4.8
requires the following changes in the complexity analysis:
.
Taking into account in Lemma 4.8
requires the following changes in the complexity analysis:
Since has  terms of
size , the contribution
of the evaluation of for the complexity
bound of Lemma 4.2 is
terms of
size , the contribution
of the evaluation of for the complexity
bound of Lemma 4.2 is 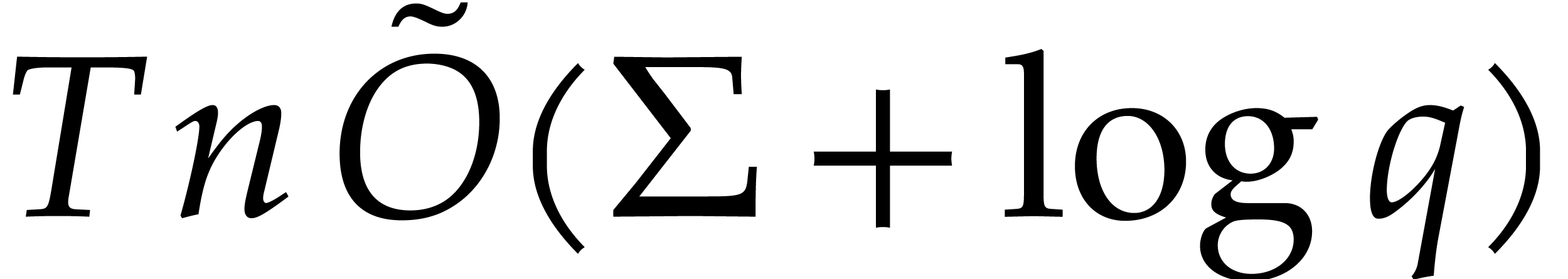 ,
thanks to part (i) of Lemma 4.10. Therefore,
the complexity bound of Lemma 4.2 with
in the role of becomes
,
thanks to part (i) of Lemma 4.10. Therefore,
the complexity bound of Lemma 4.2 with
in the role of becomes
The contribution of the evaluation of for
the complexity bound of Lemma 4.3 is
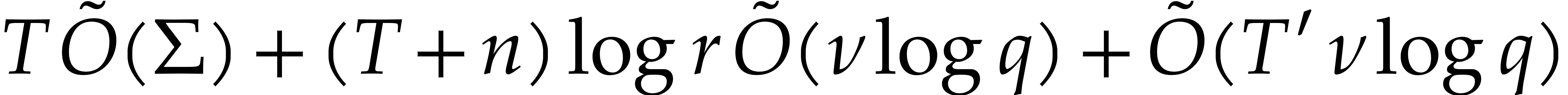
thanks to part (ii) of Lemma 4.10. Therefore,
the complexity bound of Lemma 4.3 with
in the role of becomes
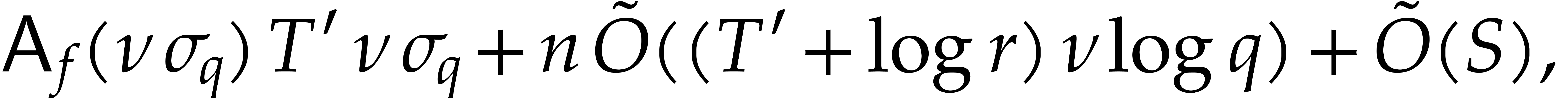
whenever  .
.
It follows that the complexity bounds of Lemmas 4.6, 4.8, and Corollary 4.7 remain unchanged when
replacing by .
The total running time for computing the sequence
is therefore bounded by
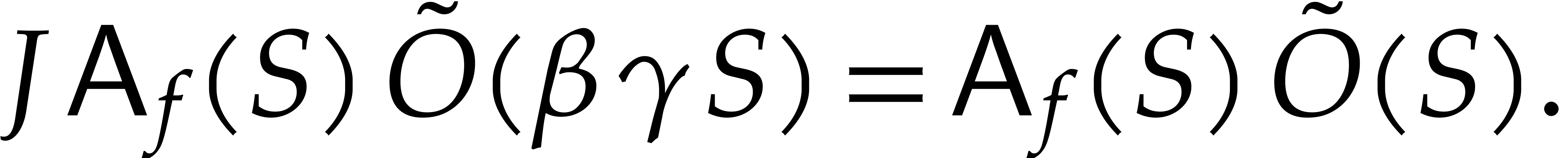
Using the inequalities 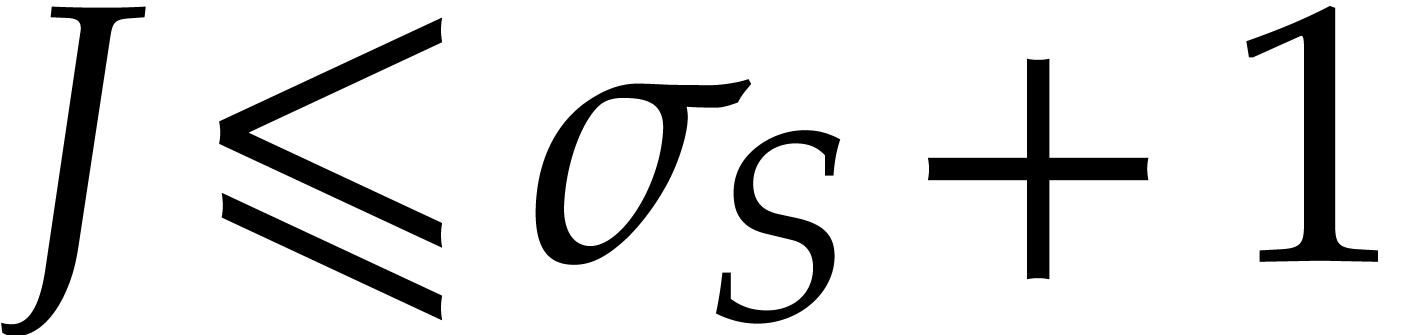 and , the probability of failure is bounded by
and , the probability of failure is bounded by
If none of the steps fail, then 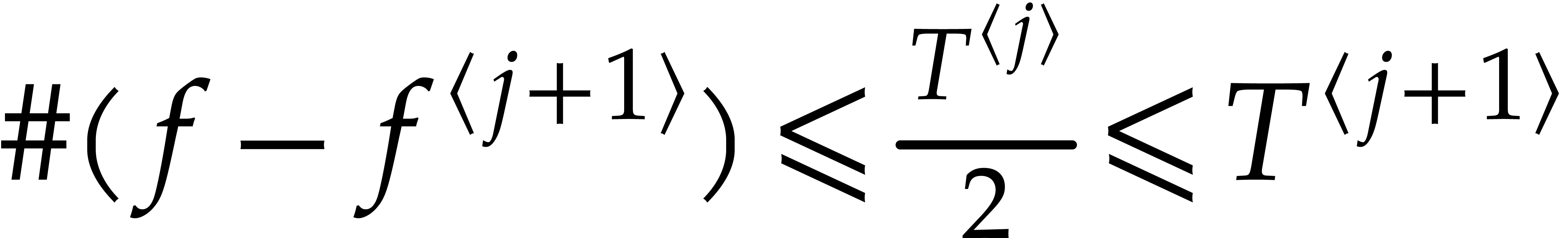 for
for  , by induction. In particular,
, by induction. In particular, 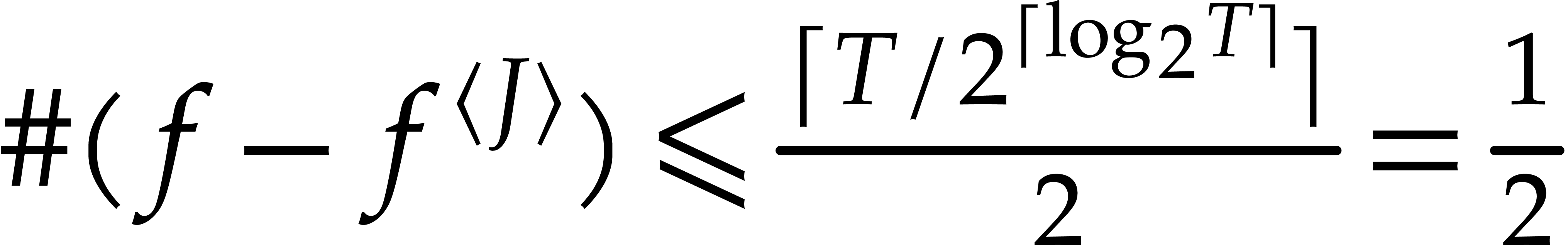 , so
, so 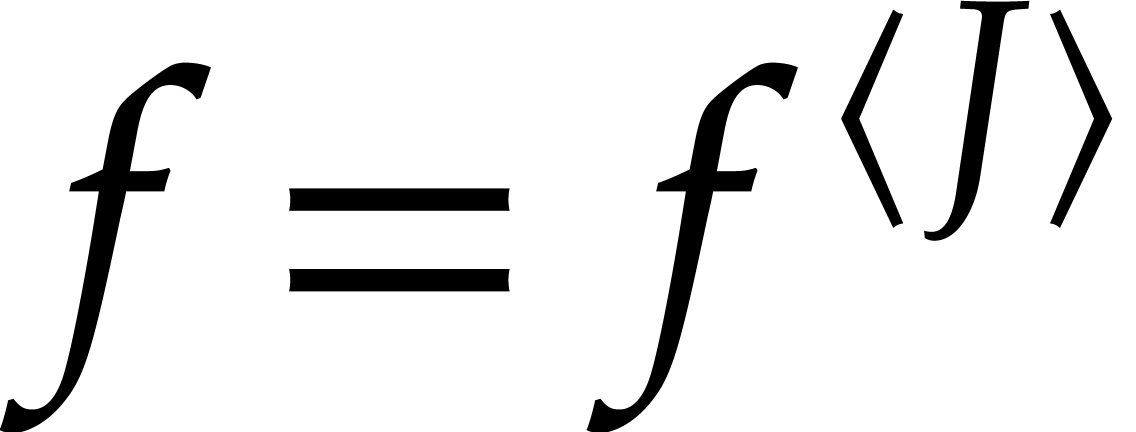 .
.
Remark  ,
where is a given bound on the bit-size of . This was erroneously asserted in
a prior version of this paper [27] and such a bound would
be more efficient in cases where the sizes of the coefficients and
exponents of vary widely. Here, the first
difficulty appears when a first approximation
,
where is a given bound on the bit-size of . This was erroneously asserted in
a prior version of this paper [27] and such a bound would
be more efficient in cases where the sizes of the coefficients and
exponents of vary widely. Here, the first
difficulty appears when a first approximation  of
has
of
has  terms with small
coefficients and has just a few terms but huge
coefficients of bit-size :
the evaluation cost of in part (ii) of
Lemma 4.10 would need to remain in
terms with small
coefficients and has just a few terms but huge
coefficients of bit-size :
the evaluation cost of in part (ii) of
Lemma 4.10 would need to remain in 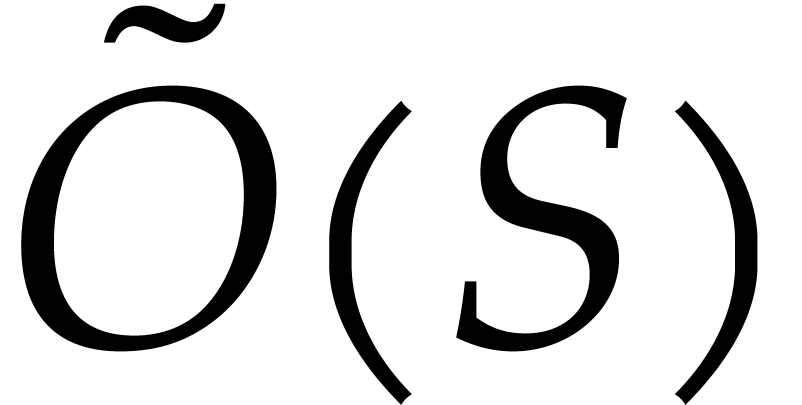 . Recent advances in this problem can be found in
[18] for the univariate case. Note that the bound is still achieved in the approximate version (Theorem 4.9) of our main theorem.
. Recent advances in this problem can be found in
[18] for the univariate case. Note that the bound is still achieved in the approximate version (Theorem 4.9) of our main theorem.
For practical purposes, the choice of 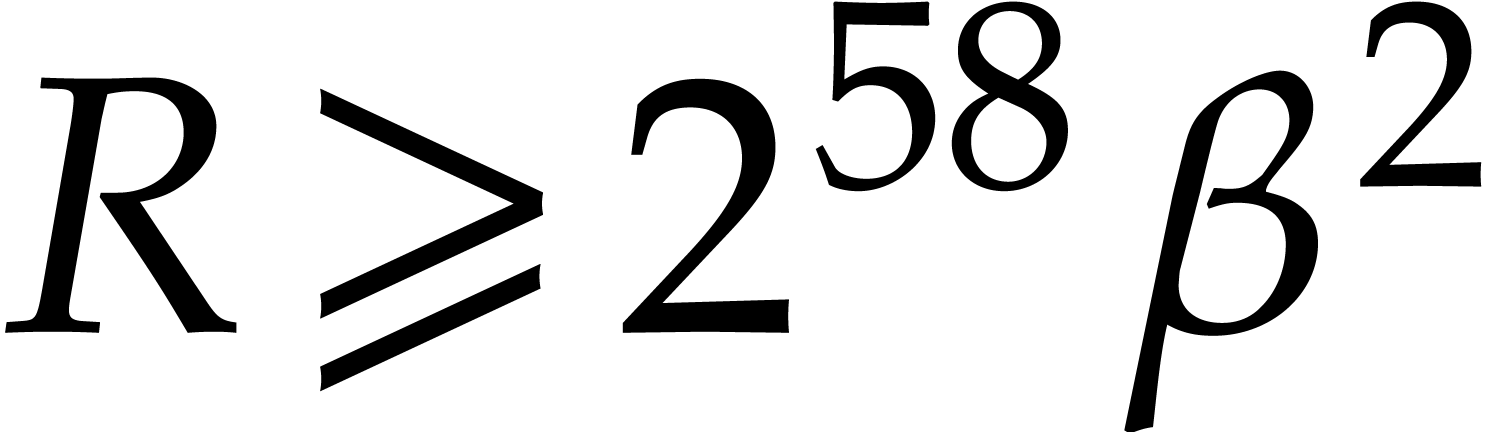 is not
realistic. The high constant
is not
realistic. The high constant 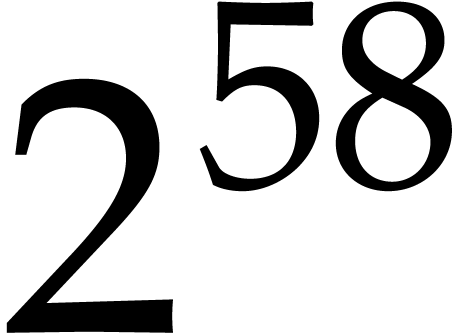 is due to the fact
that we rely on [44] for unconditional proofs for the
existence of prime numbers with the desirable properties from Theorem 2.5. Such unconditional number theoretic proofs are typically
very hard and lead to pessimistic constants. Numerical evidence shows
that a much smaller constant would do in practice: see [16,
section 4] and [40, section 2.2.2]. For the univariate case
the complexity of the sparse interpolation algorithm in [40]
is made precise in term of the logarithmic factors.
is due to the fact
that we rely on [44] for unconditional proofs for the
existence of prime numbers with the desirable properties from Theorem 2.5. Such unconditional number theoretic proofs are typically
very hard and lead to pessimistic constants. Numerical evidence shows
that a much smaller constant would do in practice: see [16,
section 4] and [40, section 2.2.2]. For the univariate case
the complexity of the sparse interpolation algorithm in [40]
is made precise in term of the logarithmic factors.
The exposition so far has also been optimized for simplicity of
presentation rather than practical efficiency: some of the other
constant factors might be sharpened further and some of the logarithmic
factors in the complexity bounds might be removed. In practical
implementations, one may simply squeeze all thresholds until the error
rate becomes unacceptably high. Here one may exploit the
“auto-correcting” properties of the algorithm. For instance,
although the -approximation
from the proof of Theorem 1.1 may
contain incorrect terms, most of these terms will be removed at the next
iteration.
Our exposition so far has also been optimized for full generality. For
applications, a high number of, say 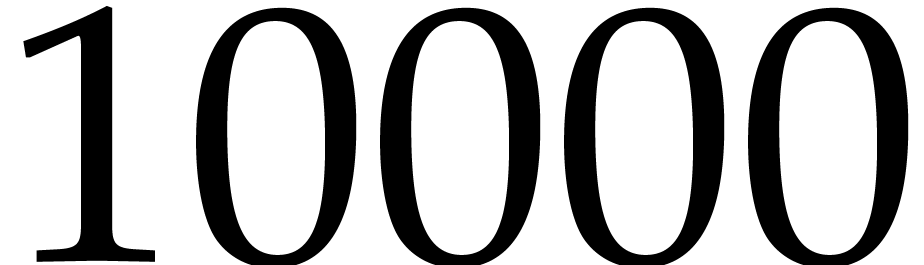 ,
variables may be useful, but the bit-size of individual exponents rarely
exceeds the machine precision. In fact, most multivariate polynomials
of practical interest are of low or moderately
large total degree. A lot of the technical difficulties from the
previous sections disappear in that case. In this section we will
describe some practical variants of our sparse interpolation algorithm,
with a main focus on this special case.
,
variables may be useful, but the bit-size of individual exponents rarely
exceeds the machine precision. In fact, most multivariate polynomials
of practical interest are of low or moderately
large total degree. A lot of the technical difficulties from the
previous sections disappear in that case. In this section we will
describe some practical variants of our sparse interpolation algorithm,
with a main focus on this special case.
In practice, the evaluation of our modular blackbox polynomial is
typically an order of magnitude faster if the modulus fits into a double
precision number (e.g. 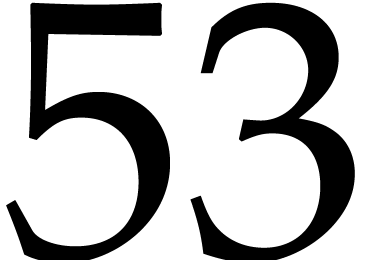 bits if we
rely on floating point arithmetic and
bits if we
rely on floating point arithmetic and  bits when
using integer arithmetic). In this subsection, we describe some
techniques that can be used to minimize the use of multiple precision
arithmetic.
bits when
using integer arithmetic). In this subsection, we describe some
techniques that can be used to minimize the use of multiple precision
arithmetic.
are small, but
its coefficients are allowed to be large, then it is classical to
proceed in two phases. We first determine the exponents using double
precision arithmetic only. Knowing these exponents, we next determine
the coefficients using modular arithmetic and the Chinese remainder
theorem: modulo any small prime ,
we may efficiently compute  using only evaluations of modulo on a geometric progression, followed by [25,
section 5.1]. Doing this for enough small primes, we may then
reconstruct the coefficients of using Chinese
remaindering. Only the Chinese remaindering step involves a limited
but unavoidable amount of multi-precision arithmetic. By determining
only the coefficients of size ,
where is repeatedly doubled until we reach
, the whole second phase
can be accomplished in time
using only evaluations of modulo on a geometric progression, followed by [25,
section 5.1]. Doing this for enough small primes, we may then
reconstruct the coefficients of using Chinese
remaindering. Only the Chinese remaindering step involves a limited
but unavoidable amount of multi-precision arithmetic. By determining
only the coefficients of size ,
where is repeatedly doubled until we reach
, the whole second phase
can be accomplished in time 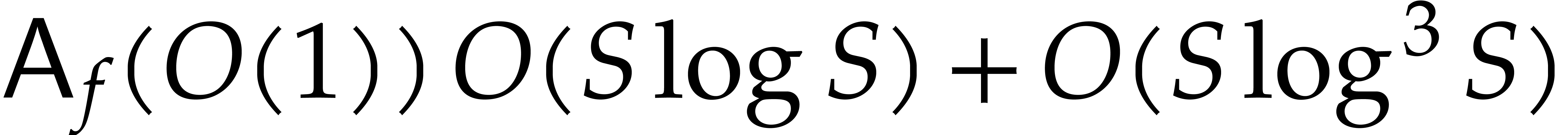 .
.
inside an integer 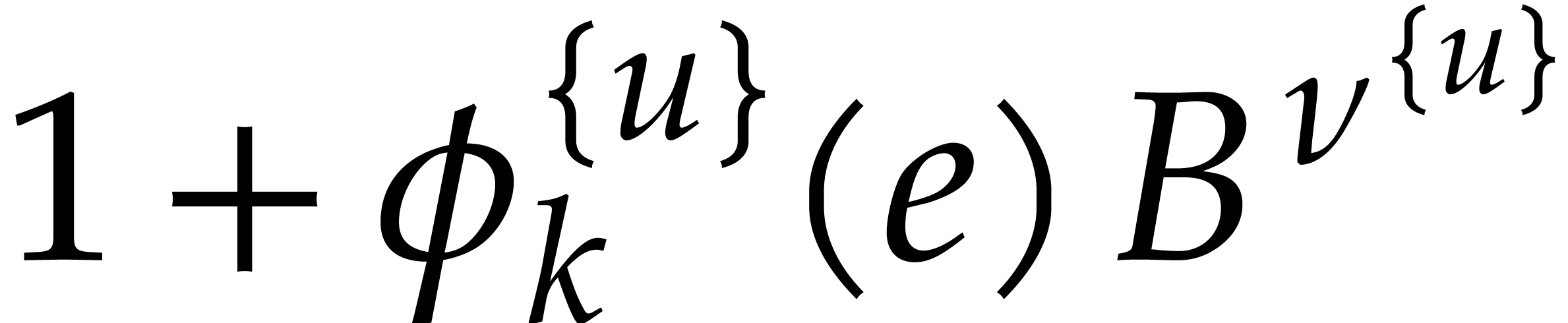 modulo
modulo 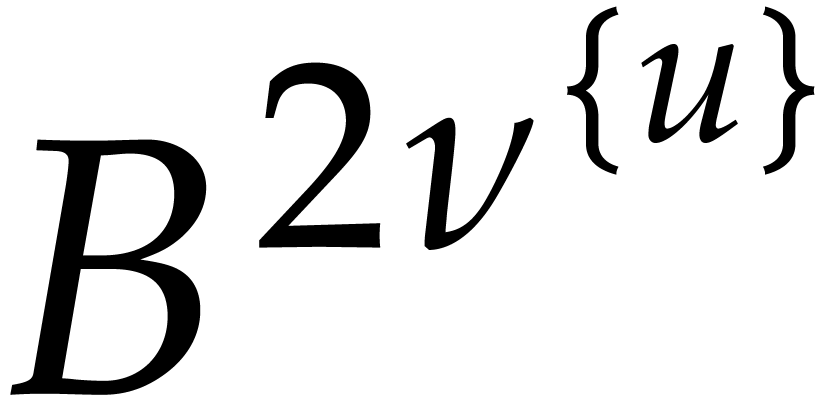 of doubled precision
of doubled precision 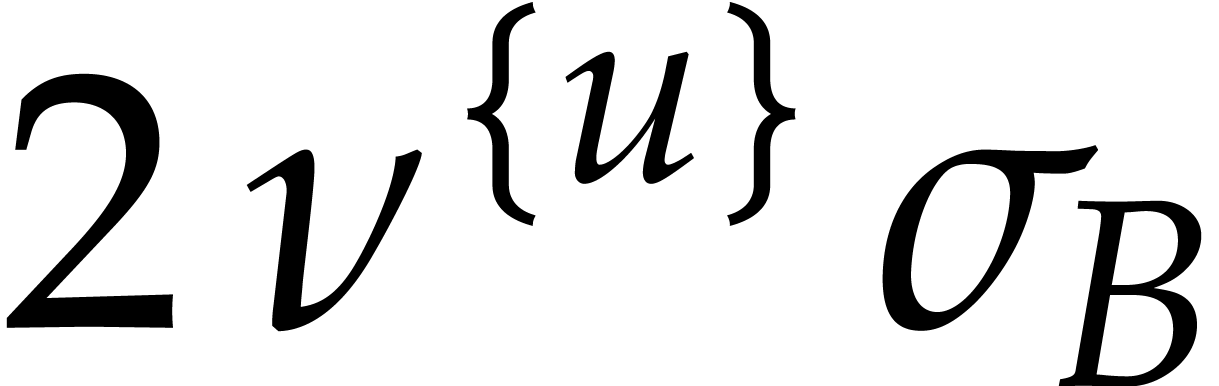 instead of
instead of 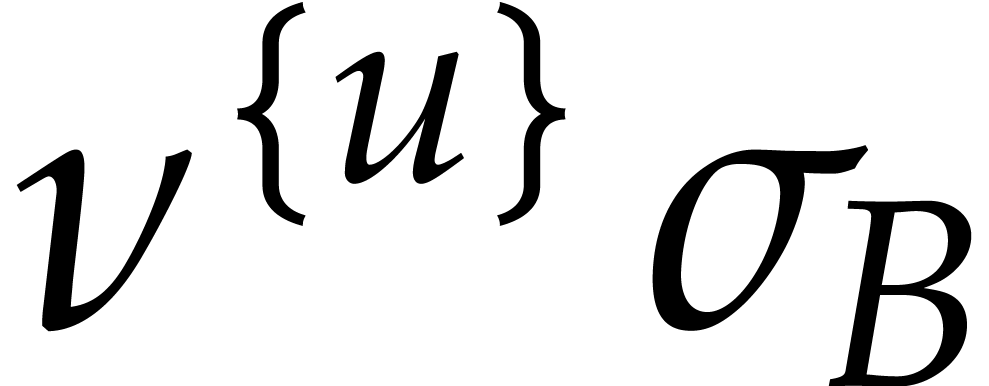 . In practice,
this often leads us to exceed the machine precision. An alternative
approach (which is reminiscent of the ones from [19, 32]) is to work with tangent numbers: let us now take
. In practice,
this often leads us to exceed the machine precision. An alternative
approach (which is reminiscent of the ones from [19, 32]) is to work with tangent numbers: let us now take
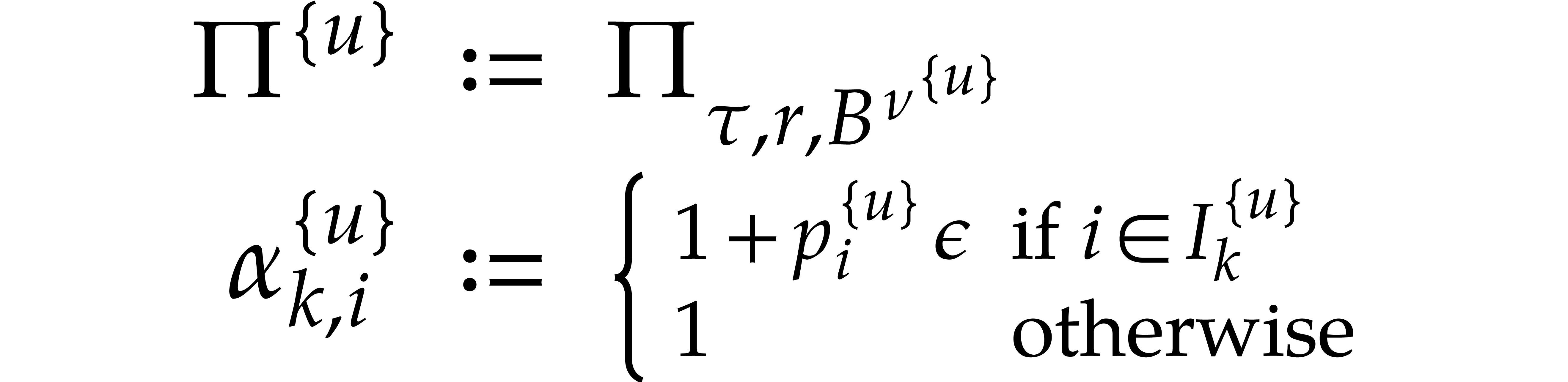
where  is extended to
is extended to 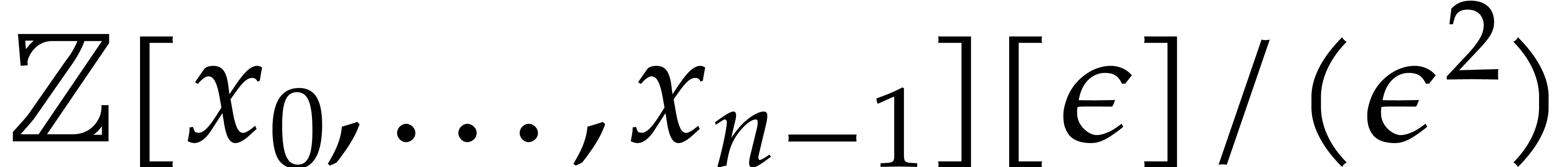 and
where
and
where 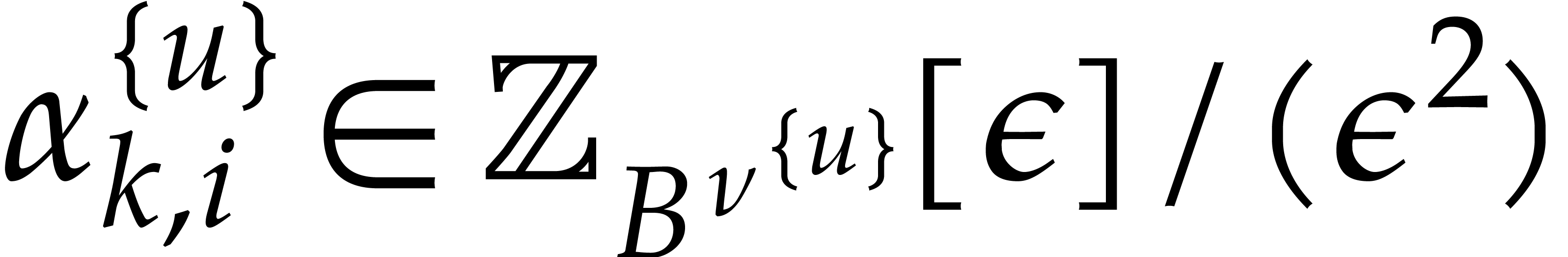 . Then, for any term
, we have
. Then, for any term
, we have
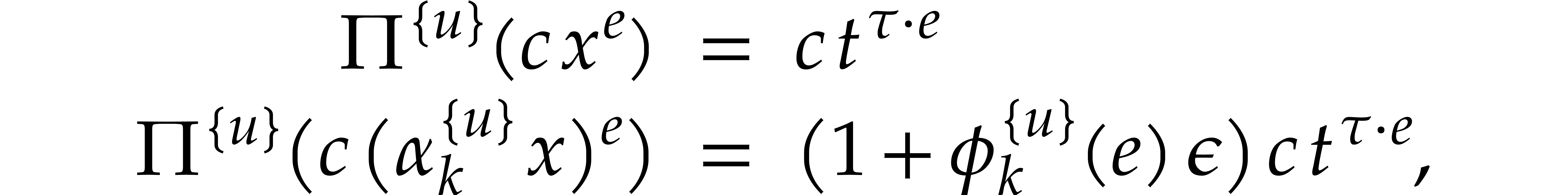
so we may again obtain from
and using one division. Of course, this requires
our ability to evaluate at elements of 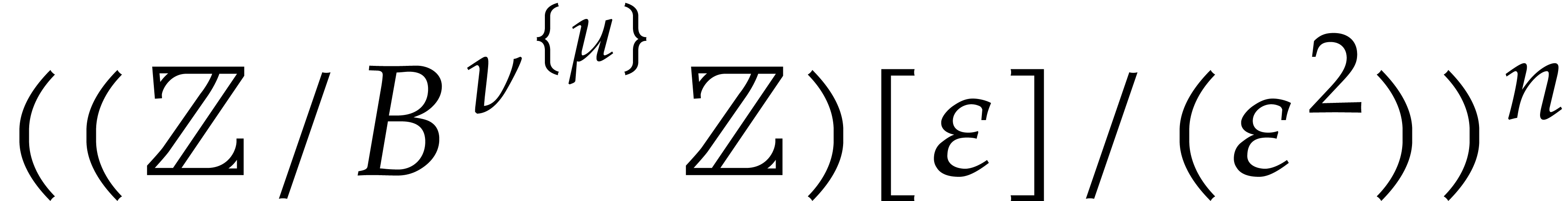 , which is indeed the case if is given by an SLP. Note that arithmetic in
, which is indeed the case if is given by an SLP. Note that arithmetic in 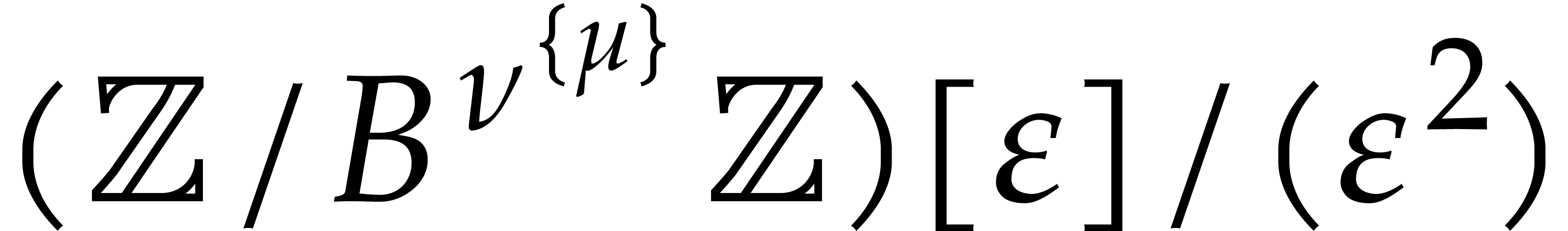 is about three times as expensive as arithmetic in
is about three times as expensive as arithmetic in 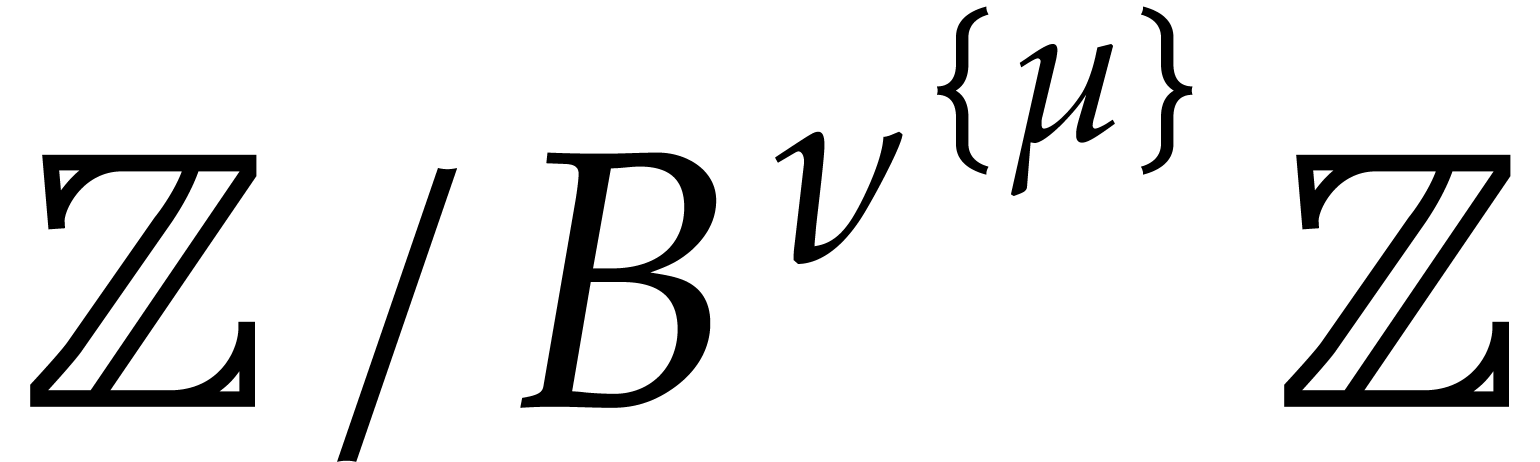 .
.
from section 2.4
is asymptotically efficient, it relies heavily on multiple precision
arithmetic. If all and  fit within machine numbers and
fit within machine numbers and  is not too
large, then we expect it to be more efficient to simply compute all
remainders
is not too
large, then we expect it to be more efficient to simply compute all
remainders  . After the
computation of pre-inverses for ,
such remainders can be computed using only a few hardware
instructions, and these computations can easily be vectorized [29]. As a consequence, we only expect the asymptotically
faster algorithm to become interesting for
very large sizes like
. After the
computation of pre-inverses for ,
such remainders can be computed using only a few hardware
instructions, and these computations can easily be vectorized [29]. As a consequence, we only expect the asymptotically
faster algorithm to become interesting for
very large sizes like 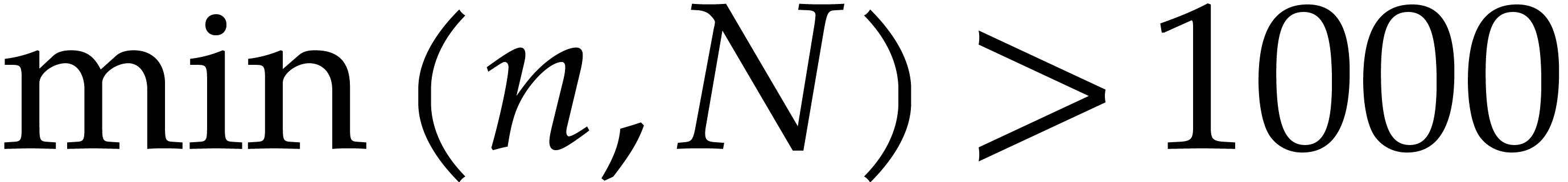 . Of
course, we may easily modify to fall back on
the naive algorithm below a certain threshold (recursive calls
included); vectorization can still be beneficial even for moderate
sizes [12].
. Of
course, we may easily modify to fall back on
the naive algorithm below a certain threshold (recursive calls
included); vectorization can still be beneficial even for moderate
sizes [12].
has only small
exponents, then multiple precision arithmetic is only needed during
the Chinese remaindering step that recovers the coefficients from
modular projections. If actually does contain
some exponents that exceed machine precision, is it still possible to
avoid most of the multiple precision arithmetic?
Let be a triple as in Theorem 2.5.
In order to avoid evaluations of modulo large
integers of the form , we
wish to use Chinese remaindering. Let  be triples as in Theorem 2.5 with
be triples as in Theorem 2.5 with 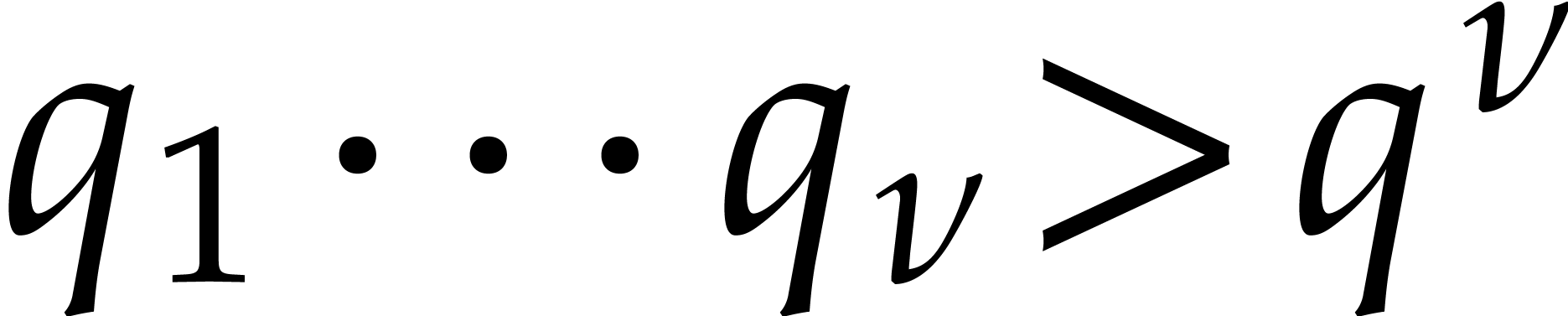 , the
, the 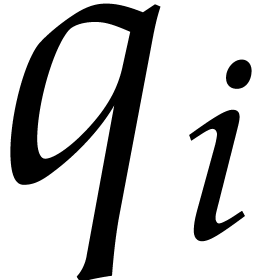 pairwise distinct, and where is shared by all
triples. Since there are many primes for which
pairwise distinct, and where is shared by all
triples. Since there are many primes for which
 contains at least
primes, such triples can still be found with high probability. In
practice,
contains at least
primes, such triples can still be found with high probability. In
practice, 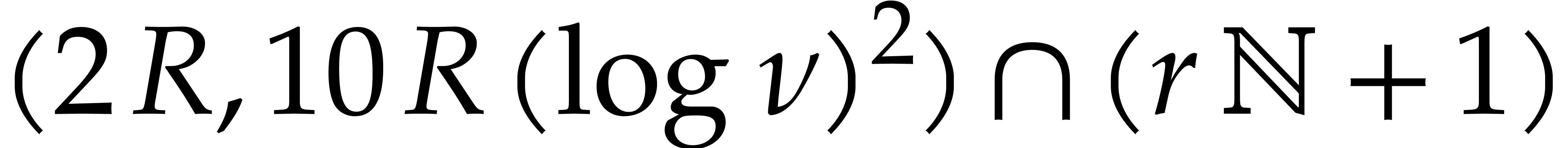 already contains enough prime numbers.
already contains enough prime numbers.
Evaluations of modulo
are now replaced by separate evaluations modulo  after which we can reconstruct evaluations modulo
after which we can reconstruct evaluations modulo  using Chinese remaindering. However, one crucial additional idea that we
used in Lemma 4.3 is that is
automatically -faithful as
soon as it is -faithful. In
the multi-modular setting, if is
using Chinese remaindering. However, one crucial additional idea that we
used in Lemma 4.3 is that is
automatically -faithful as
soon as it is -faithful. In
the multi-modular setting, if is 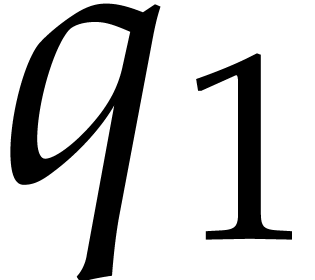 -faithful, then it is still true that the
exponents of
-faithful, then it is still true that the
exponents of  are contained in the exponents of
are contained in the exponents of
 for
for 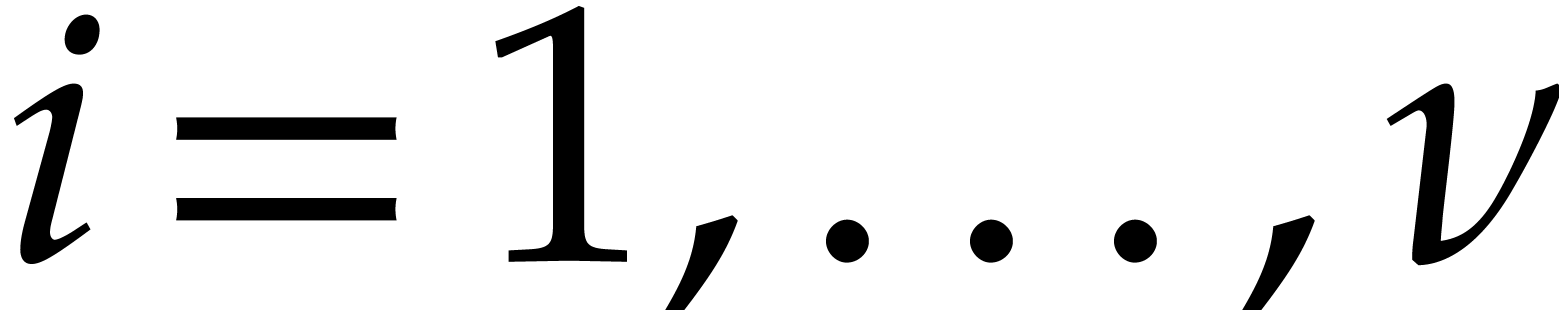 .
This is sufficient for Lemma 4.3 to generalize.
.
This is sufficient for Lemma 4.3 to generalize.
Let  be bounds for the degree of
in , let
be bounds for the degree of
in , let  be a bound for the maximal number of variables that can occur in a term
of , and let
the prime numbers from section 3.1.
be a bound for the maximal number of variables that can occur in a term
of , and let
the prime numbers from section 3.1.
Assume that our polynomial has only nonnegative
“moderately large exponents” in the sense that  fits into a machine number. Then we may simplify the setup
from section 3.1 by taking
fits into a machine number. Then we may simplify the setup
from section 3.1 by taking
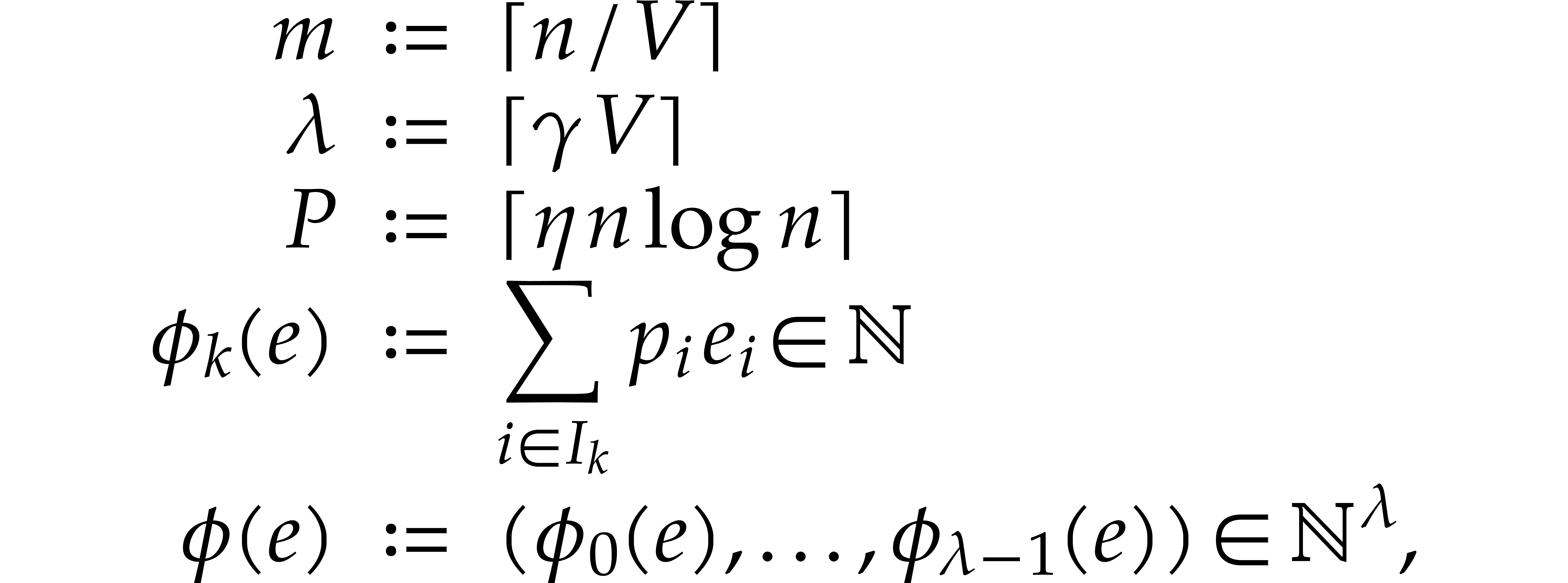
where  and
and  are small
constants and where we forget about and . For any
are small
constants and where we forget about and . For any 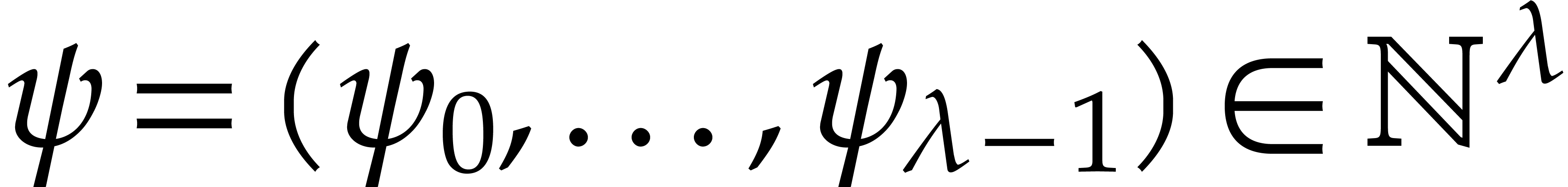 , let
, let  .
In this simplified setup, one may use the following algorithm to
retrieve from :
.
In this simplified setup, one may use the following algorithm to
retrieve from :
Algorithm
Output: with 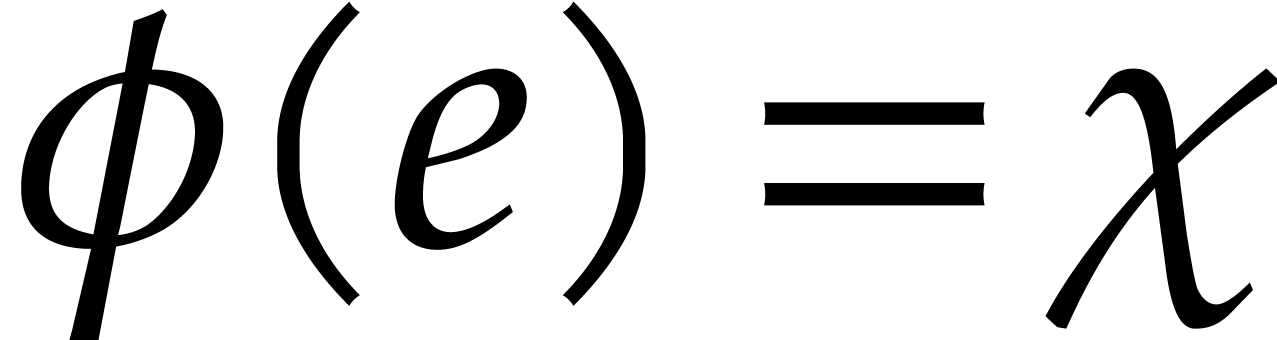 or
or  .
.
Let 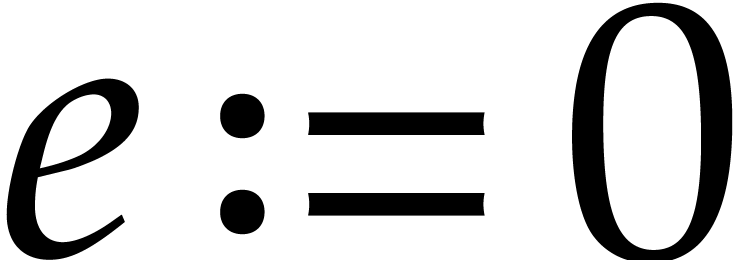 ,
, 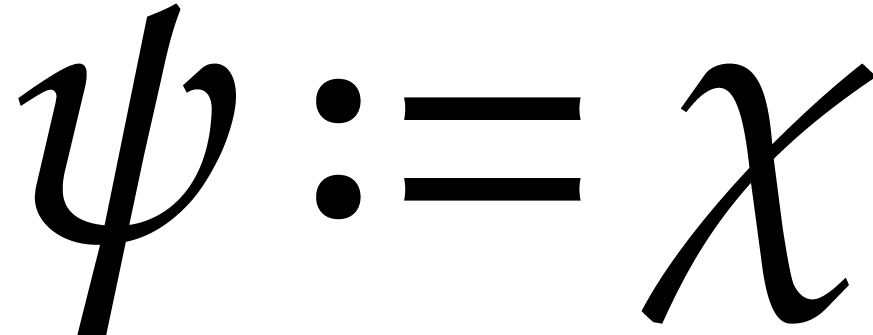 , and
, and  .
.
While there exist and
with 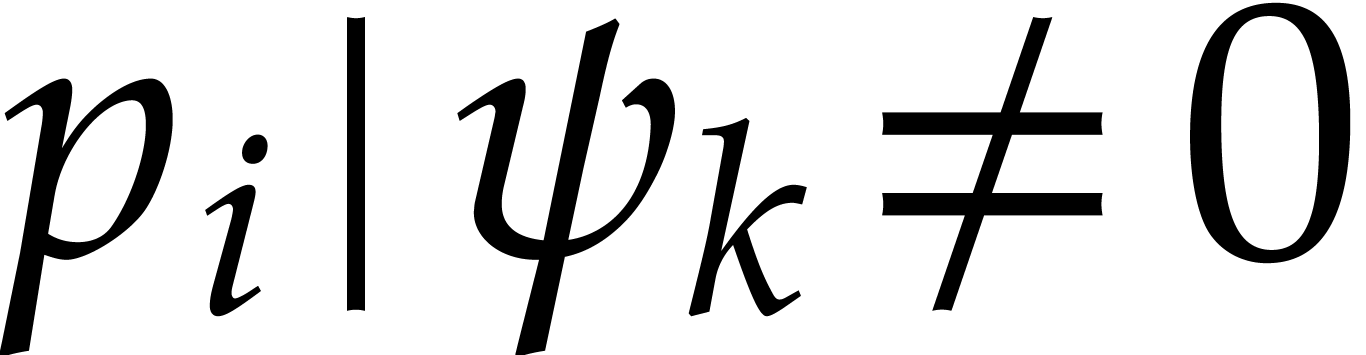 and
and 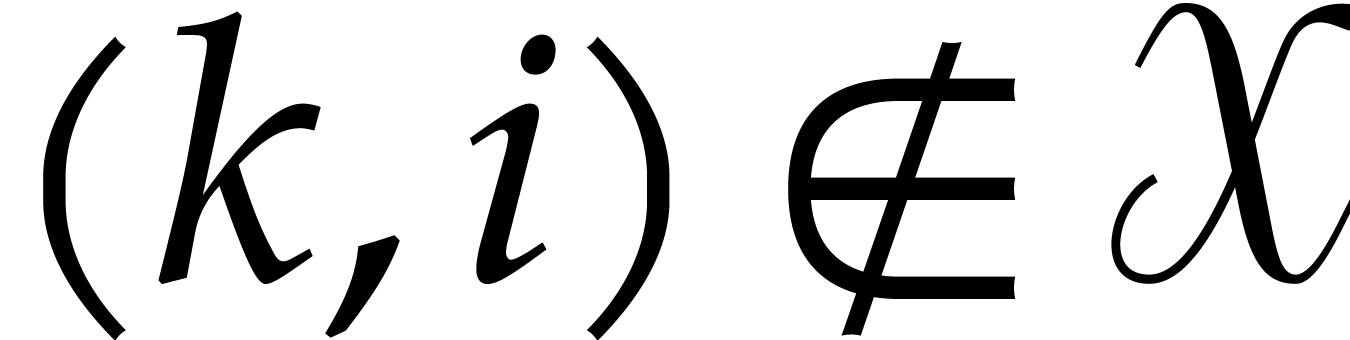 do:
do:
Let 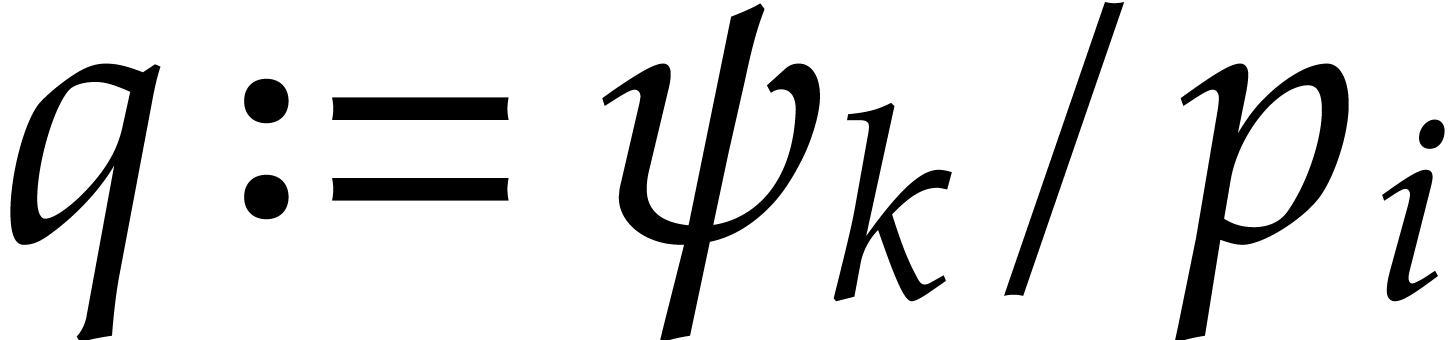 .
.
Let 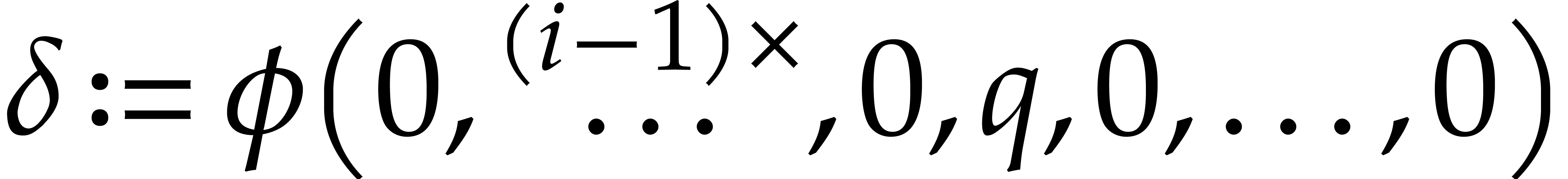 .
.
If 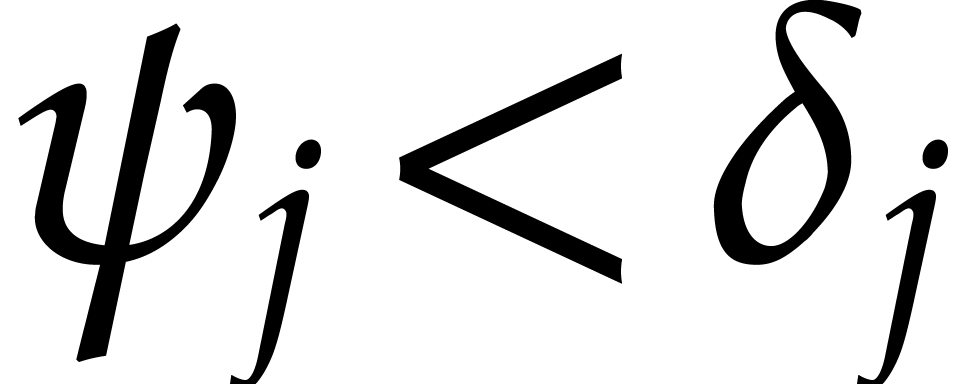 for some
for some 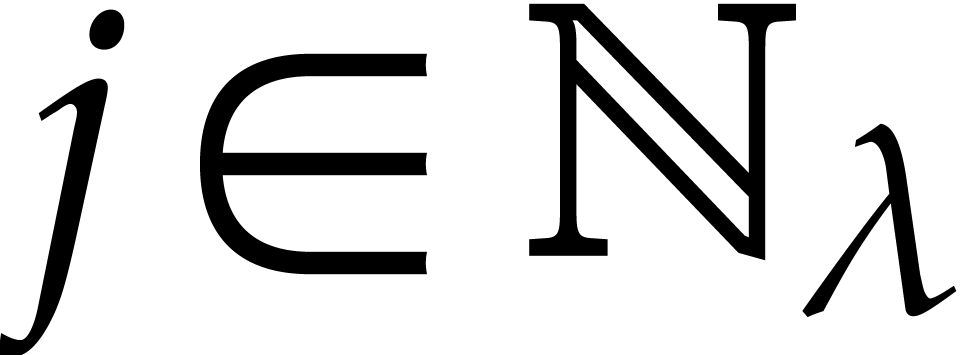 or
or 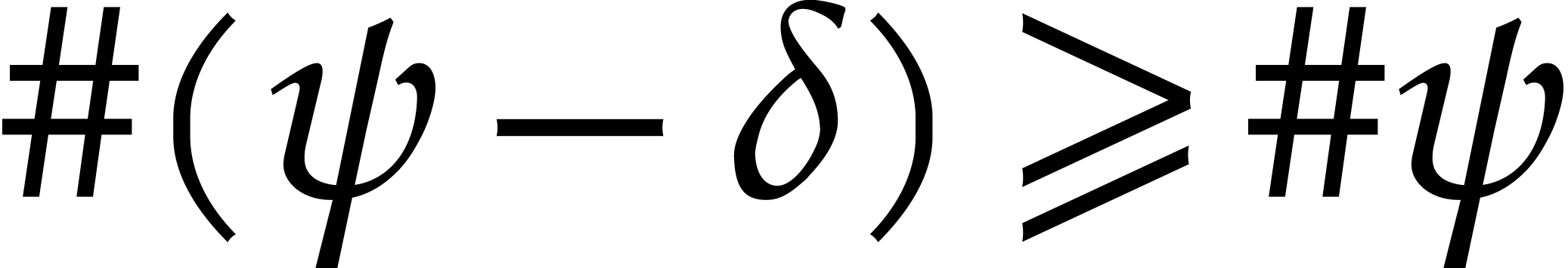 , then let
, then let  .
.
Otherwise, update 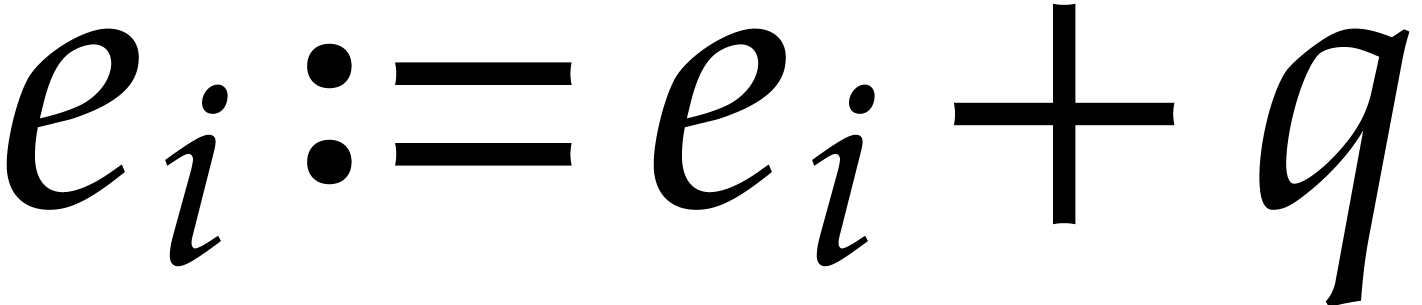 ,
, 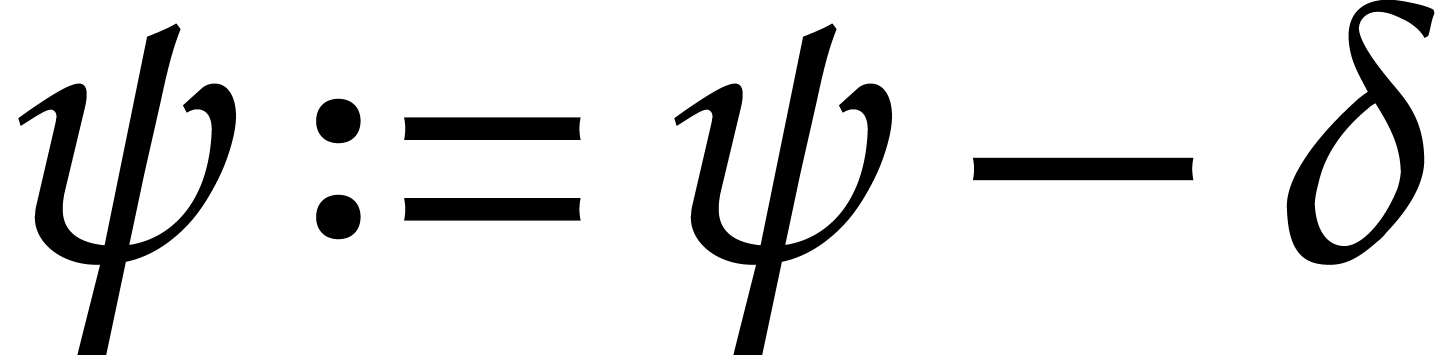 , and .
, and .
If 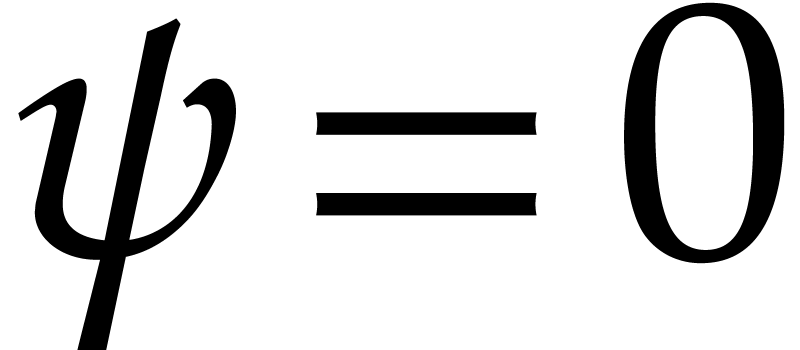 , then return .
, then return .
Otherwise, return .
The probability of success is non-trivial to analyze due to the
interplay of the choices of and the updates of
. For this reason, we
consider the algorithm to be heuristic. Nevertheless, returned values
are always correct:
Proof. By construction, we have the loop
invariant that 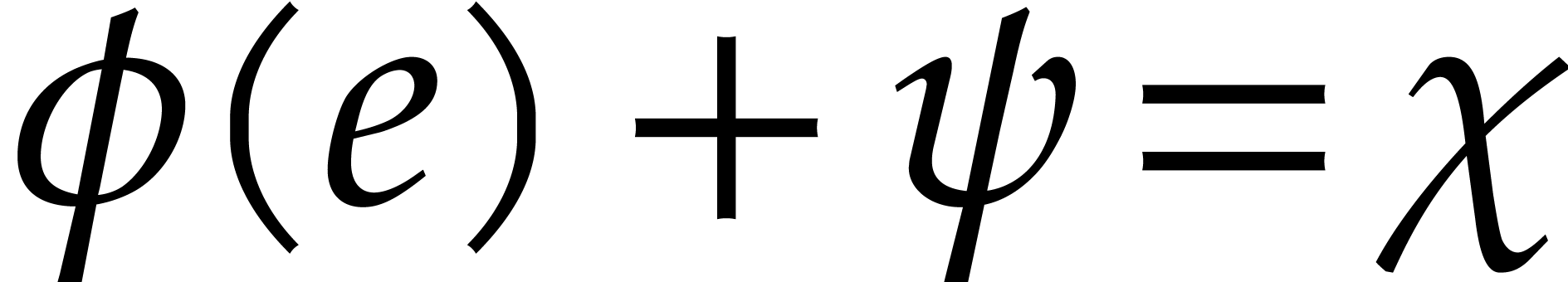 , so the
answer is clearly correct in case of success. The set of
“problematic pairs” was introduced
in order to guarantee progress and avoid infinite loops. Indeed,
, so the
answer is clearly correct in case of success. The set of
“problematic pairs” was introduced
in order to guarantee progress and avoid infinite loops. Indeed,  strictly decreases at every update of
strictly decreases at every update of  . For definiteness, we also ensured that remains in
. For definiteness, we also ensured that remains in  throughout the
algorithm. (One may actually release this restriction, since incorrect
decisions may be corrected later during the execution.)
throughout the
algorithm. (One may actually release this restriction, since incorrect
decisions may be corrected later during the execution.)
Remark leads to a simplification of , which diminishes the number of collisions
(i.e. entries  such that the sum
contains at least two non-zero terms). This allows the algorithm to
discover more coefficients
such that the sum
contains at least two non-zero terms). This allows the algorithm to
discover more coefficients  that might have been
missed without the updates of .
As a result, the algorithm may succeed for lower values of and
that might have been
missed without the updates of .
As a result, the algorithm may succeed for lower values of and  ,
e.g. for a more compressed encoding of .
,
e.g. for a more compressed encoding of .
Remark so as to make the updates
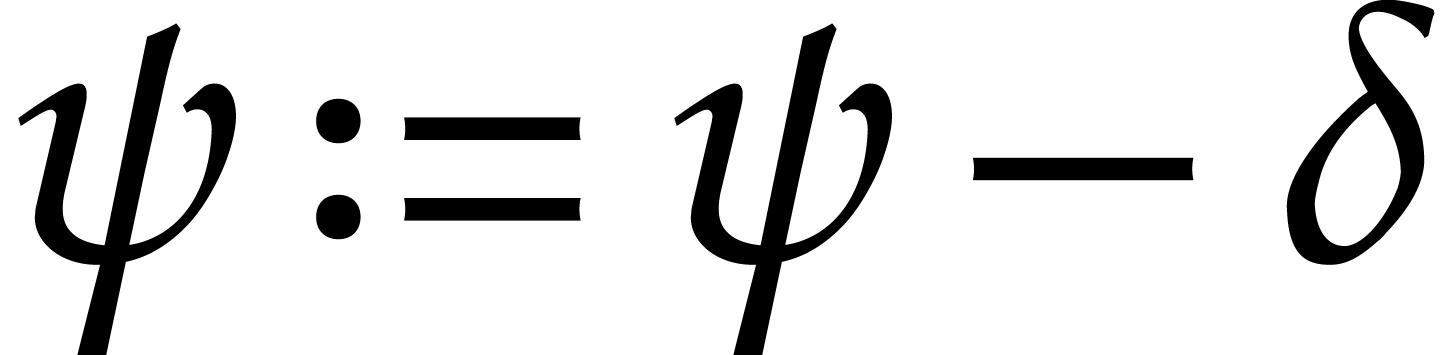 efficient. Secondly, from a theoretical point of
view, it is better to collect pairs
efficient. Secondly, from a theoretical point of
view, it is better to collect pairs 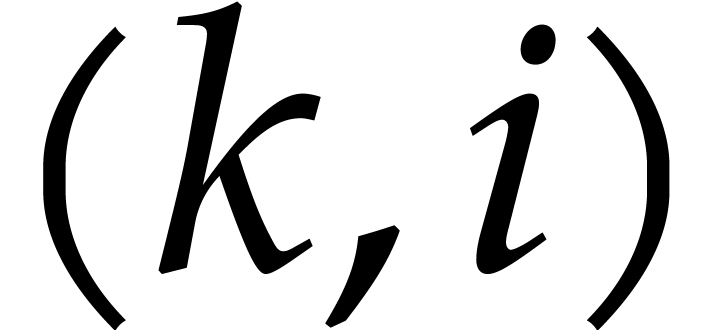 with in one big pass (thereby benefiting from Lemma 2.7) and perform the updates during a second pass. However,
this second “optimization” is only useful in practice when
becomes very large (i.e.
with in one big pass (thereby benefiting from Lemma 2.7) and perform the updates during a second pass. However,
this second “optimization” is only useful in practice when
becomes very large (i.e. 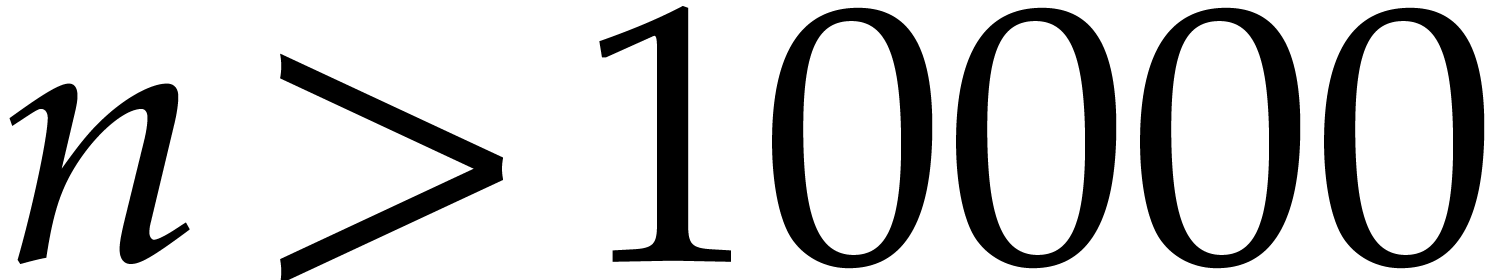 ), as explained in the previous
subsection.
), as explained in the previous
subsection.
Algorithm 5.1 is very similar to the mystery ball game
algorithm from [23]. This analogy suggests to choose the
random sets in a slightly different way: let
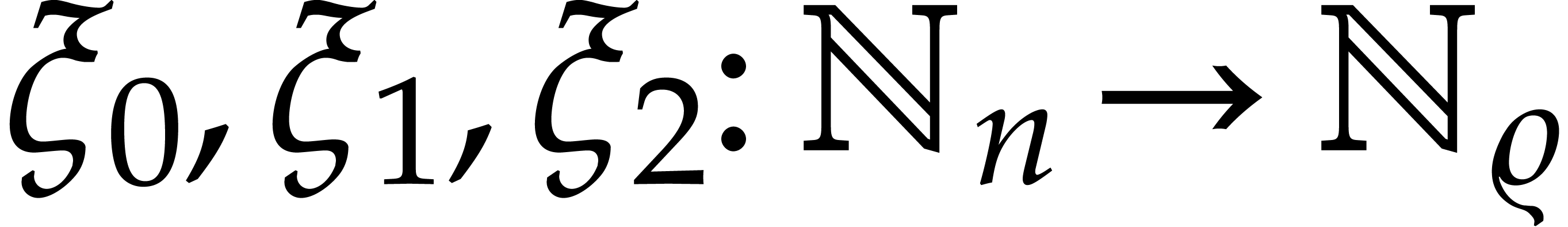 be random maps, where
be random maps, where 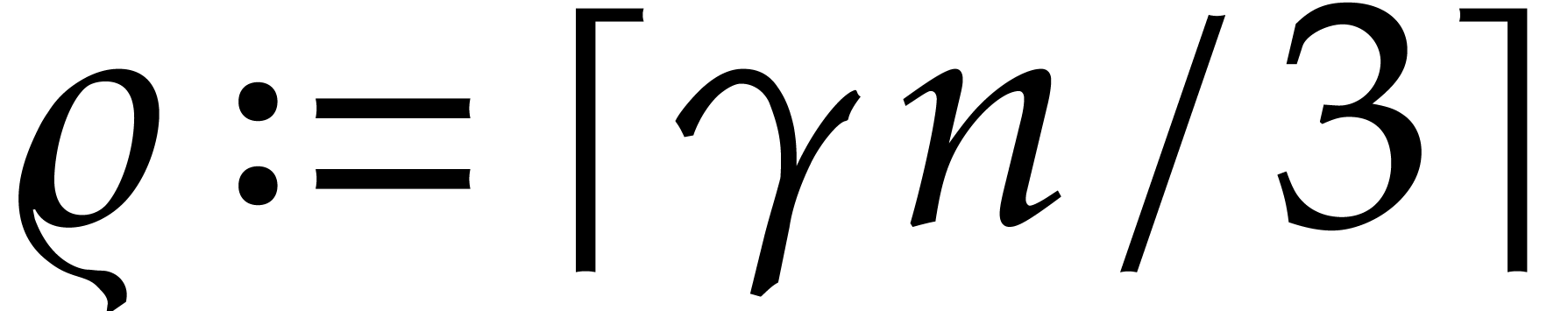 and
and 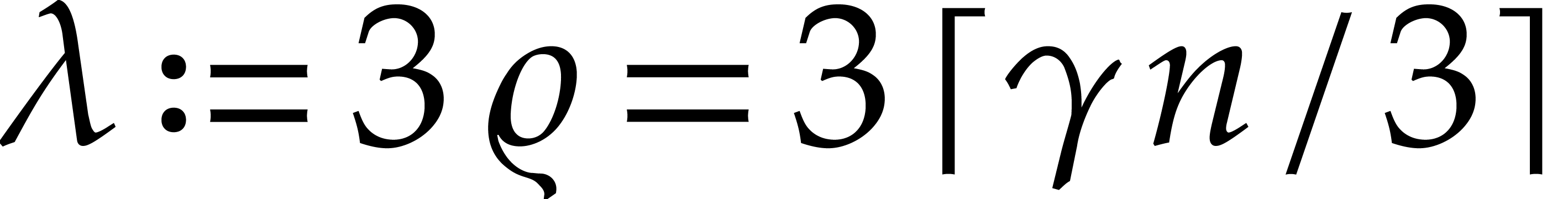 , and take
, and take

Assuming for simplicity that 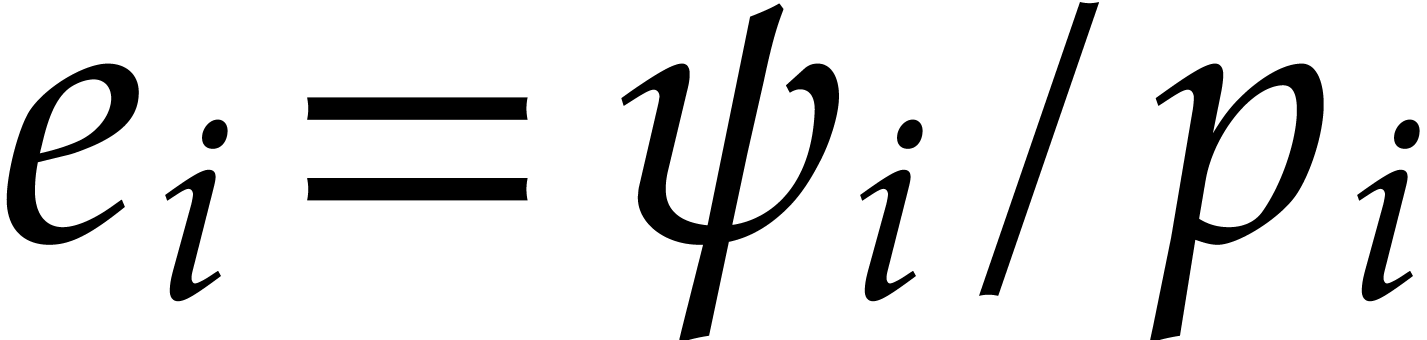 whenever
whenever  in our algorithm, the probability of success was analyzed
in [23]. It turns out that there is a phase change around
in our algorithm, the probability of success was analyzed
in [23]. It turns out that there is a phase change around
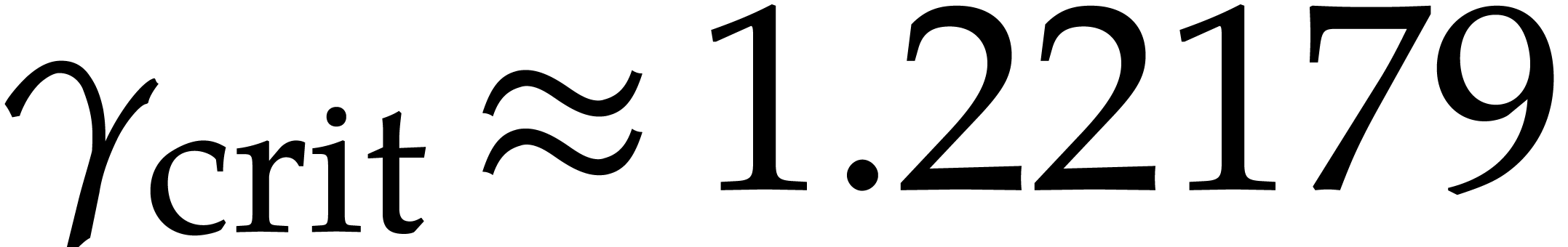 (and
(and  ).
For any
).
For any  and ,
numeric evidence suggests that the probability of success exceeds
and ,
numeric evidence suggests that the probability of success exceeds  for sufficiently large .
for sufficiently large .
This should be compared with our original choice of the , for which the mere probability that a given
index belongs to none of the
is roughly  . We clearly will
not be able to determine whenever this happens.
Moreover, the probability that this does not happen for any is roughly
. We clearly will
not be able to determine whenever this happens.
Moreover, the probability that this does not happen for any is roughly  . In
order to ensure that
. In
order to ensure that 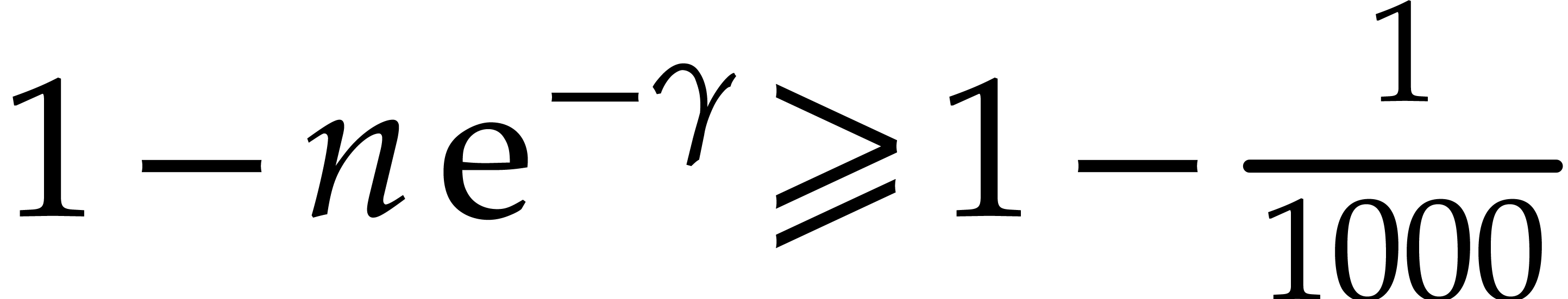 , say,
this requires us to take
, say,
this requires us to take 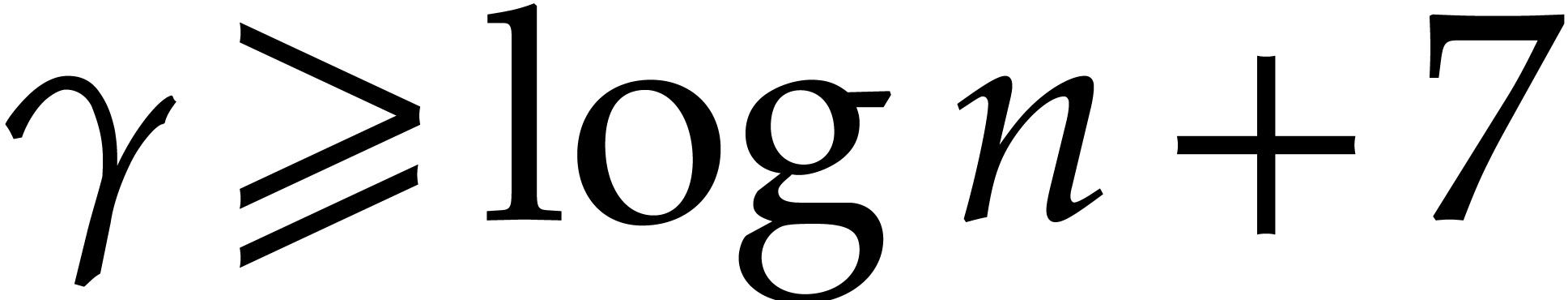 .
.
Ben-Or and Tiwari's seminal algorithm for sparse interpolation [6]
contained another way to encode multivariate exponents, based on the
prime factorization of integers: given pairwise
distinct prime numbers , we
encode an exponent as 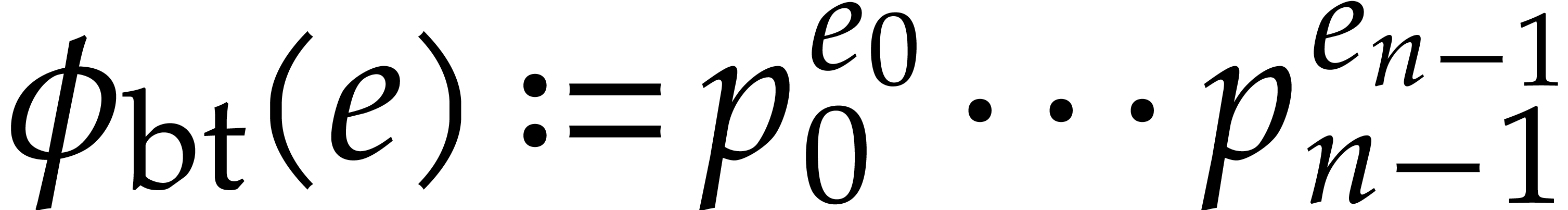 . Ben-Or and Tiwari simply chose
to be the
. Ben-Or and Tiwari simply chose
to be the  -th prime number.
For our purposes, it is better to pick pairwise
distinct small random primes
-th prime number.
For our purposes, it is better to pick pairwise
distinct small random primes 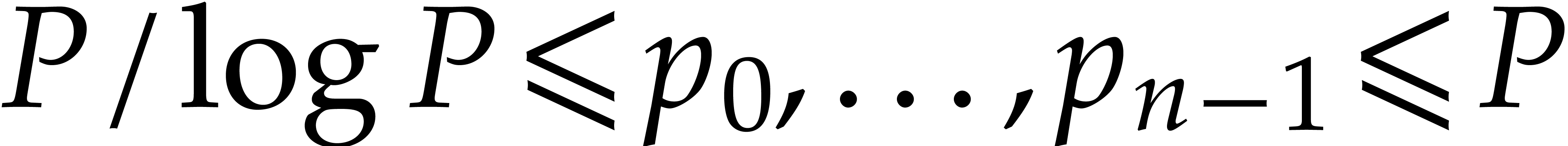 with
with 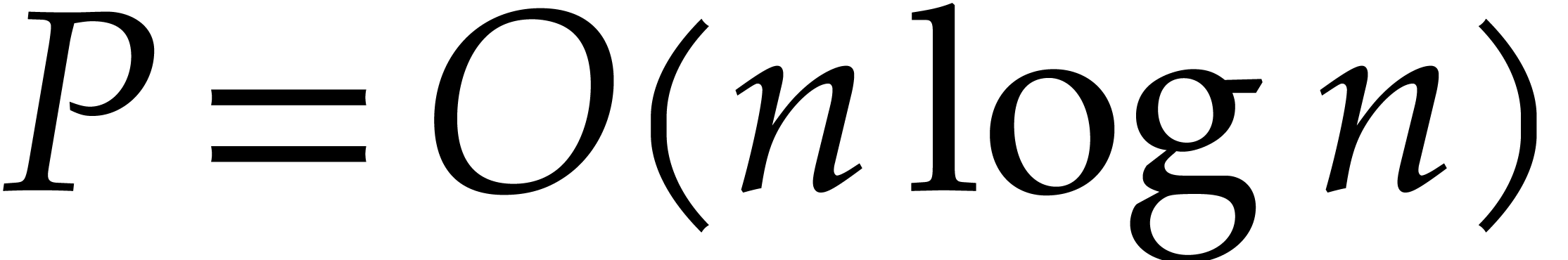 . Using (a further extension of) Lemma 2.7,
we may efficiently bulk retrieve from
. Using (a further extension of) Lemma 2.7,
we may efficiently bulk retrieve from  for large sets of exponents .
for large sets of exponents .
The Ben-Or–Tiwari encoding can also be used in combination with
the ideas from section 4.3. The idea is to compute both
and  with
with  . For monomials ,
we have
. For monomials ,
we have
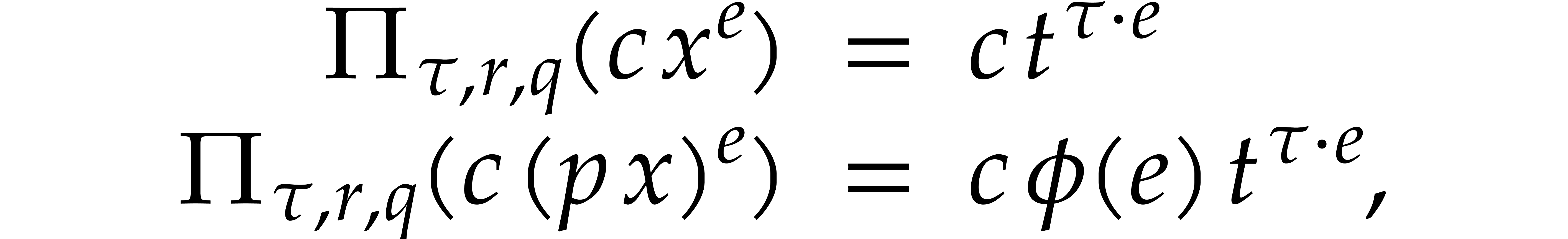
so we can again compute as the quotient of 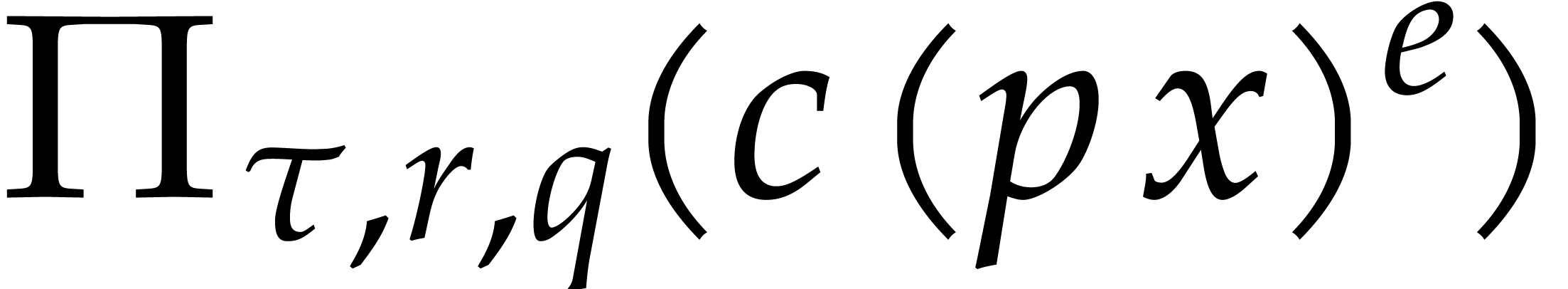 and
and 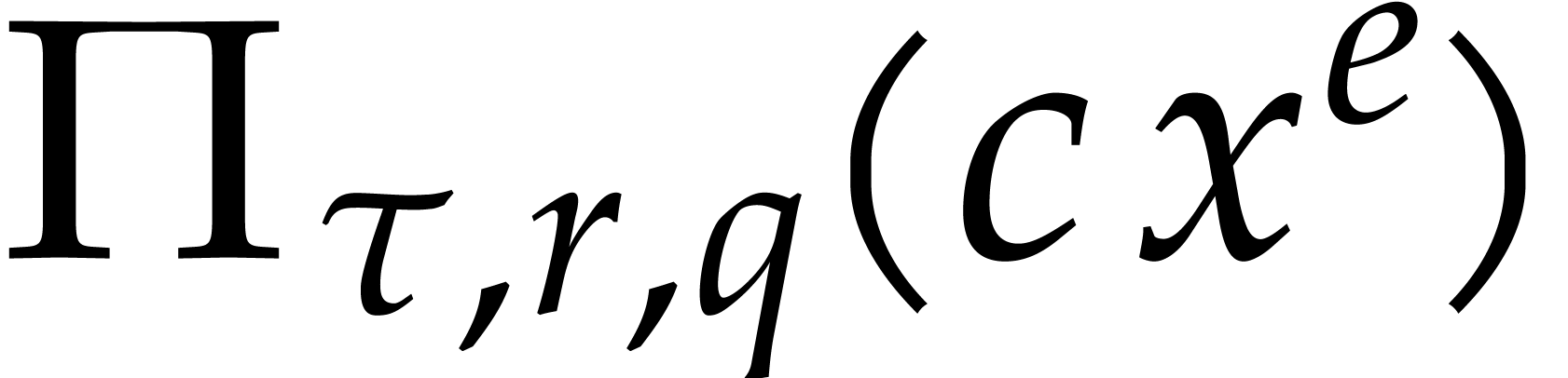 .
.
If the total degree of is bounded by a small
number  , then the
Ben-Or–Tiwari encoding is very compact. In that case, all
exponents of indeed
satisfy
, then the
Ben-Or–Tiwari encoding is very compact. In that case, all
exponents of indeed
satisfy 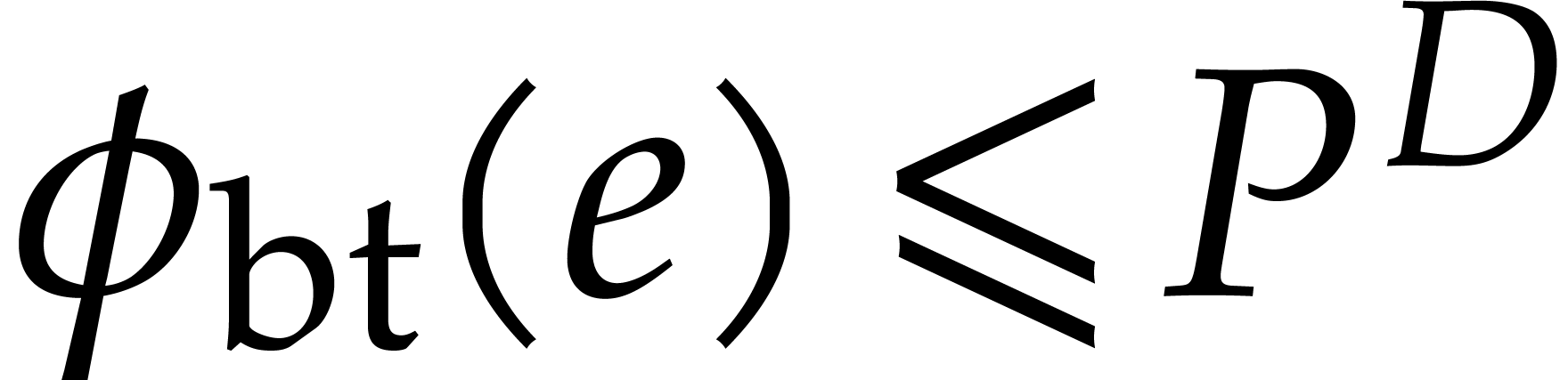 , whence
, whence  . However, if is a bit
larger (say
. However, if is a bit
larger (say  and
and  ),
then
),
then  might not fit into a machine integer and
there is no obvious way to break the encoding up
in smaller parts that would fit into machine integers.
might not fit into a machine integer and
there is no obvious way to break the encoding up
in smaller parts that would fit into machine integers.
By contrast, the encoding from the previous
subsection uses a vector of numbers that do fit into machine integers,
under mild conditions. Another difference is that 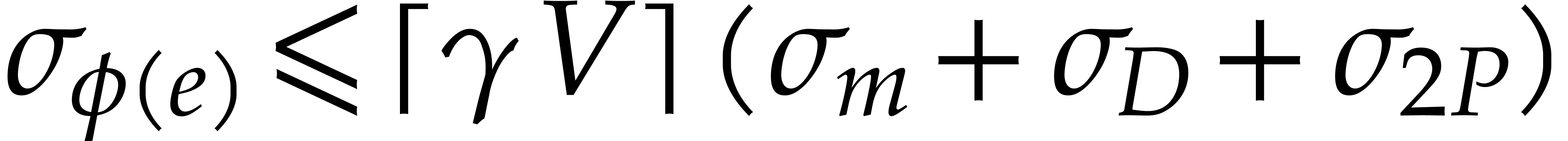 only grows linearly with instead of , and only logarithmically with . As soon as is large
and not very small, this encoding should
therefore be more efficient for practical purposes.
only grows linearly with instead of , and only logarithmically with . As soon as is large
and not very small, this encoding should
therefore be more efficient for practical purposes.
M. Agrawal, N. Kayal, and N. Saxena. PRIMES is in P. Ann. Math., 160(2):781–793, 2004.
A. Arnold, M. Giesbrecht, and D. S. Roche. Sparse interpolation over finite fields via low-order roots of unity. In ISSAC '14: Proceedings of the 39th International Symposium on Symbolic and Algebraic Computation, pages 27–34. New York, NY, USA, 2014. ACM Press.
A. Arnold, M. Giesbrecht, and D. S. Roche. Faster sparse multivariate polynomial interpolation of straight-line programs. J. Symb. Comput., 75:4–24, 2016.
A. Arnold and D. S. Roche. Multivariate sparse interpolation using randomized Kronecker substitutions. In ISSAC '14: Proceedings of the 39th International Symposium on Symbolic and Algebraic Computation, pages 35–42. New York, NY, USA, 2014. ACM Press.
M. Asadi, A. Brandt, R. Moir, and M. Moreno Maza. Sparse polynomial arithmetic with the BPAS library. In V. Gerdt, W. Koepf, W. Seiler, and E. Vorozhtsov, editors, Computer Algebra in Scientific Computing. CASC 2018, volume 11077 of Lect. Notes Comput. Sci., pages 32–50. Springer, Cham, 2018.
M. Ben-Or and P. Tiwari. A deterministic algorithm for sparse multivariate polynomial interpolation. In STOC '88: Proceedings of the twentieth annual ACM symposium on Theory of computing, pages 301–309. ACM Press, 1988.
L. I. Bluestein. A linear filtering approach to the computation of discrete Fourier transform. IEEE Transactions on Audio and Electroacoustics, 18(4):451–455, 1970.
A. Bostan, G. Lecerf, and É. Schost. Tellegen's principle into practice. In J. R. Sendra, editor, Proceedings of the 2003 International Symposium on Symbolic and Algebraic Computation, ISSAC '03, pages 37–44. New York, NY, USA, 2003. ACM Press.
R. P. Brent and P. Zimmermann. Modern Computer Arithmetic. Cambridge University Press, 2010.
P. Bürgisser, M. Clausen, and M. A. Shokrollahi. Algebraic complexity theory. Springer-Verlag, Berlin, 1997.
J. Canny, E. Kaltofen, and Y. Lakshman. Solving systems of non-linear polynomial equations faster. In Proceedings of the ACM-SIGSAM 1989 International Symposium on Symbolic and Algebraic Computation, pages 121–128. New York, NY, USA, 1989. ACM Press.
J. Doliskani, P. Giorgi, R. Lebreton, and É. Schost. Simultaneous conversions with the residue number system using linear algebra. ACM Trans. Math. Softw., 44(3), 2018.
T. S. Freeman, G. M. Imirzian, E. Kaltofen, and Y. Lakshman. DAGWOOD: a system for manipulating polynomials given by straight-line programs. ACM Trans. Math. Software, 14:218–240, 1988.
S. Garg and É. Schost. Interpolation of polynomials given by straight-line programs. Theor. Comput. Sci., 410(27-29):2659–2662, 2009.
J. von zur Gathen and J. Gerhard. Modern computer algebra. Cambridge University Press, New York, 3rd edition, 2013.
P. Giorgi, B. Grenet, A. Perret Du Cray, and D. S. Roche. Random primes in arithmetic progressions. Technical Report https://arxiv.org/abs/2202.05955, Arxiv, 2022.
P. Giorgi, B. Grenet, A. Perret du Cray, and D. S. Roche. Sparse polynomial interpolation and division in soft-linear time. In Proceedings of the 2022 International Symposium on Symbolic and Algebraic Computation, ISSAC '22, pages 459–468. New York, NY, USA, 2022. ACM Press.
P. Giorgi, B. Grenet, A. Perret du Cray, and D. S. Roche. Fast interpolation and multiplication of unbalanced polynomials. In J. Hauenstein, W. Lee, and S. Chen, editors, Proceedings of the 2024 International Symposium on Symbolic and Algebraic Computation, ISSAC '24, pages 437–446. New York, NY, USA, 2024. ACM Press.
B. Grenet, J. van der Hoeven, and G. Lecerf. Randomized root finding over finite fields using tangent Graeffe transforms. In ISSAC '15: Proceedings of the 2015 ACM on International Symposium on Symbolic and Algebraic Computation, pages 197–204. New York, NY, USA, 2015. ACM Press.
D. Y. Grigoriev, M. Karpinski, and M. F. Singer. Fast parallel algorithms for sparse multivariate polynomial interpolation over finite fields. SIAM J. Comput., 19(6):1059–1063, 1990.
A. W. Groves and D. S. Roche. Sparse polynomials in FLINT. ACM Commun. Comput. Algebra., 50(3):105–108, 2016.
D. Harvey and J. van der Hoeven. Integer
multiplication in time .
Ann. Math., 193(2):563–617, 2021.
J. van der Hoeven. Probably faster multiplication of sparse polynomials. Technical Report, HAL, 2020. https://hal.archives-ouvertes.fr/hal-02473830.
J. van der Hoeven. The Jolly Writer. Your Guide to GNU TeXmacs. Scypress, 2020.
J. van der Hoeven and G. Lecerf. On the bit-complexity of sparse polynomial multiplication. J. Symbolic Comput., 50:227–254, 2013.
J. van der Hoeven and G. Lecerf. Sparse polynomial interpolation in practice. ACM Commun. Comput. Algebra, 48(3/4):187–191, 2015.
J. van der Hoeven and G. Lecerf. Fast interpolation of sparse multivariate polynomials. Technical Report, HAL, 2023. https://hal.science/hal-04366836v1.
J. van der Hoeven and G. Lecerf. Sparse polynomial interpolation: faster strategies over finite fields. Appl. Algebra Eng. Commun. Comput., 2024. https://doi.org/10.1007/s00200-024-00655-5.
J. van der Hoeven, G. Lecerf, and G. Quintin. Modular SIMD arithmetic in Mathemagix. ACM Trans. Math. Softw., 43(1):5–1, 2016.
J. Hu and M. B. Monagan. A fast parallel sparse polynomial GCD algorithm. In S. A. Abramov, E. V. Zima, and X.-S. Gao, editors, ISSAC '16: Proceedings of the ACM on International Symposium on Symbolic and Algebraic Computation, pages 271–278. New York, NY, USA, 2016. ACM Press.
M. A. Huang and A. J. Rao. Interpolation of sparse multivariate polynomials over large finite fields with applications. In SODA '96: Proceedings of the seventh annual ACM-SIAM symposium on Discrete algorithms, pages 508–517. Philadelphia, PA, USA, 1996. Society for Industrial and Applied Mathematics.
Q.-L. Huang. Sparse polynomial interpolation over fields with large or zero characteristic. In ISSAC '19: Proceedings of the 2019 on International Symposium on Symbolic and Algebraic Computation, pages 219–226. New York, NY, USA, 2019. ACM Press.
M. Javadi and M. Monagan. Parallel sparse polynomial interpolation over finite fields. In M. Moreno Maza and J.-L. Roch, editors, PASCO '10: Proceedings of the 4th International Workshop on Parallel and Symbolic Computation, pages 160–168. New York, NY, USA, 2010. ACM Press.
E. Kaltofen, Y. N. Lakshman, and J.-M. Wiley. Modular rational sparse multivariate polynomial interpolation. In ISSAC '90: Proceedings of the International Symposium on Symbolic and Algebraic Computation, pages 135–139. New York, NY, USA, 1990. ACM Press.
E. Kaltofen and L. Yagati. Improved sparse multivariate polynomial interpolation algorithms. In P. M. Gianni, editor, ISSAC '88: Proceedings of the International Symposium on Symbolic and Algebraic Computation, volume 358 of Lect. Notes Comput. Sci., pages 467–474. Springer-Verlag, Berlin, Heidelberg, 1988.
M. Monagan and B. Tuncer. Using sparse interpolation to solve multivariate diophantine equations. ACM Comm. Computer Algebra, 49(3):94–97, 2015.
M. Monagan and B. Tuncer. Sparse multivariate Hensel lifting: a high-performance design and implementation. In J. Davenport, M. Kauers, G. Labahn, and J. Urban, editors, Mathematical Software – ICMS 2018, volume 10931 of Lect. Notes Comput. Sci., pages 359–368. Springer, Cham, 2018.
H. Murao and T. Fujise. Modular algorithm for sparse multivariate polynomial interpolation and its parallel implementation. J. Symb. Comput., 21:377–396, 1996.
J.-L. Nicolas and G. Robin. Majorations explicites
pour le nombre de diviseurs de .
Canad. Math. Bull., 26:485–492, 1983.
A. Perret du Cray. Algorithmes pour les polynômes creux : interpolation, arithmétique, test d'identité. PhD thesis, Université de Montpellier (France), 2023.
R. Prony. Essai expérimental et analytique sur les lois de la dilatabilité des fluides élastiques et sur celles de la force expansive de la vapeur de l'eau et de la vapeur de l'alkool, à différentes températures. J. de l'École Polytechnique Floréal et Plairial, an III, 1(cahier 22):24–76, 1795.
D. S. Roche. What can (and can't) we do with sparse polynomials? In C. Arreche, editor, Proceedings of the 2018 ACM International Symposium on Symbolic and Algebraic Computation, ISSAC '18, pages 25–30. New York, NY, USA, 2018. ACM Press.
J. B. Rosser and L. Schoenfeld. Approximate formulas for some functions of prime numbers. Illinois J. Math., 6(1):64–94, 1962.
A. Sedunova. A partial Bombieri–Vinogradov theorem with explicit constants. Publications mathématiques de Besançon. Algèbre et théorie des nombres, pages 101–110, 2018.
K. Werther. The complexity of sparse polynomial interpolation over finite fields. Appl. Algebra Engrg. Comm. Comput., 5(2):91–103, 1994.
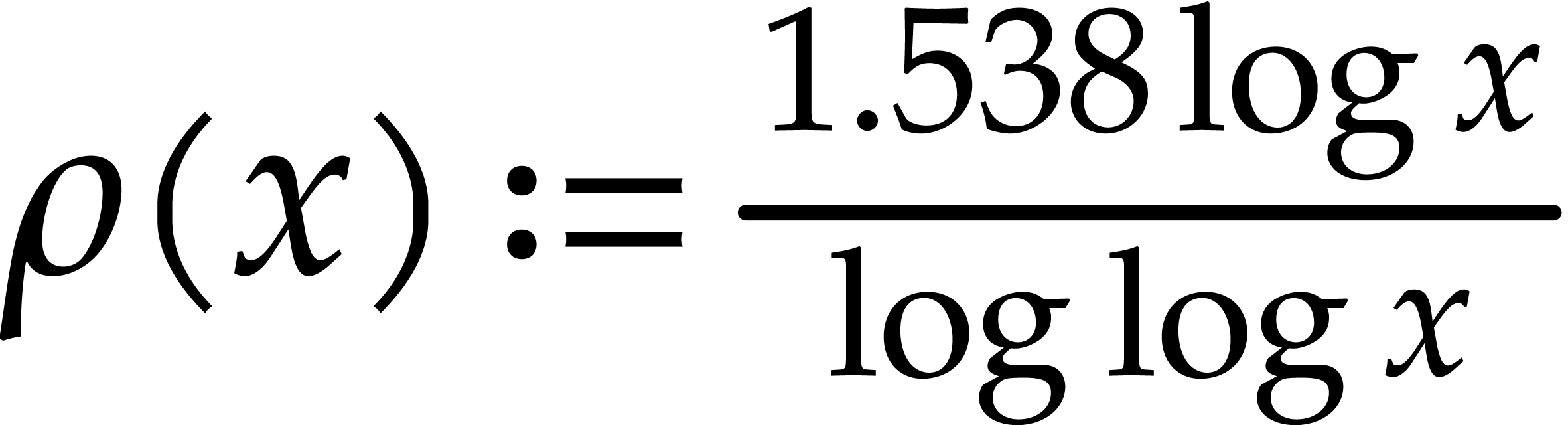 if
if 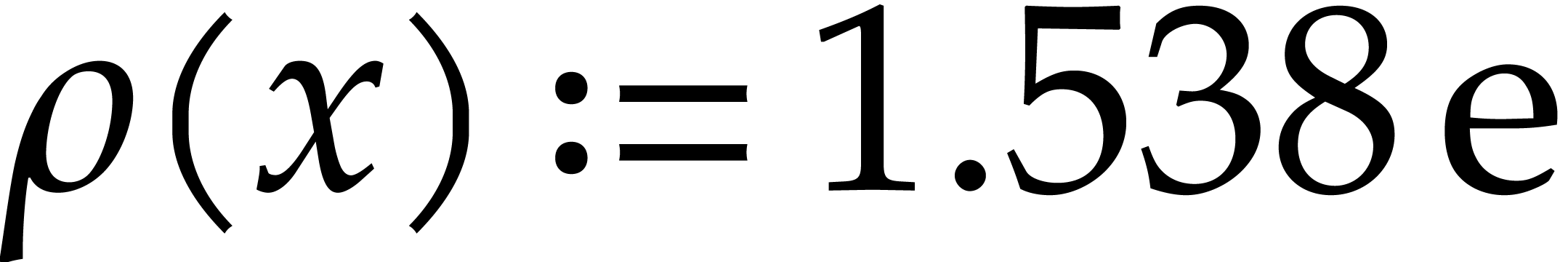 otherwise. For all
otherwise. For all 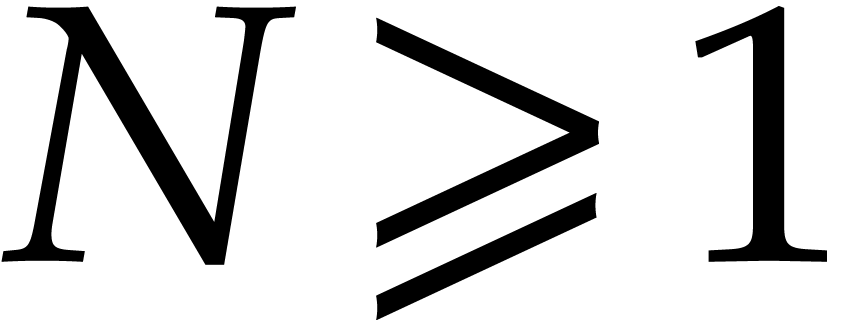 ,
,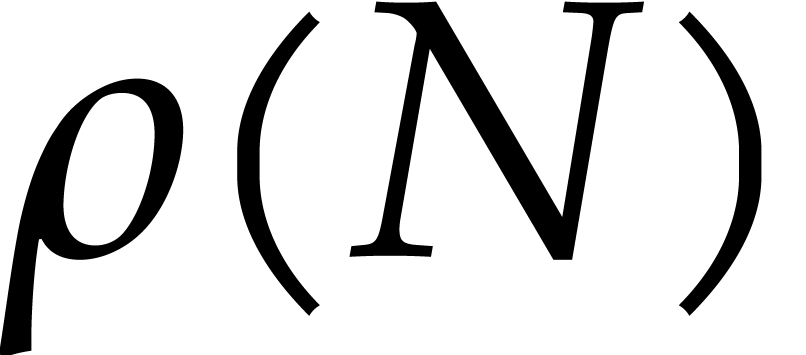 .
. is correct and runs in
time
is correct and runs in
time 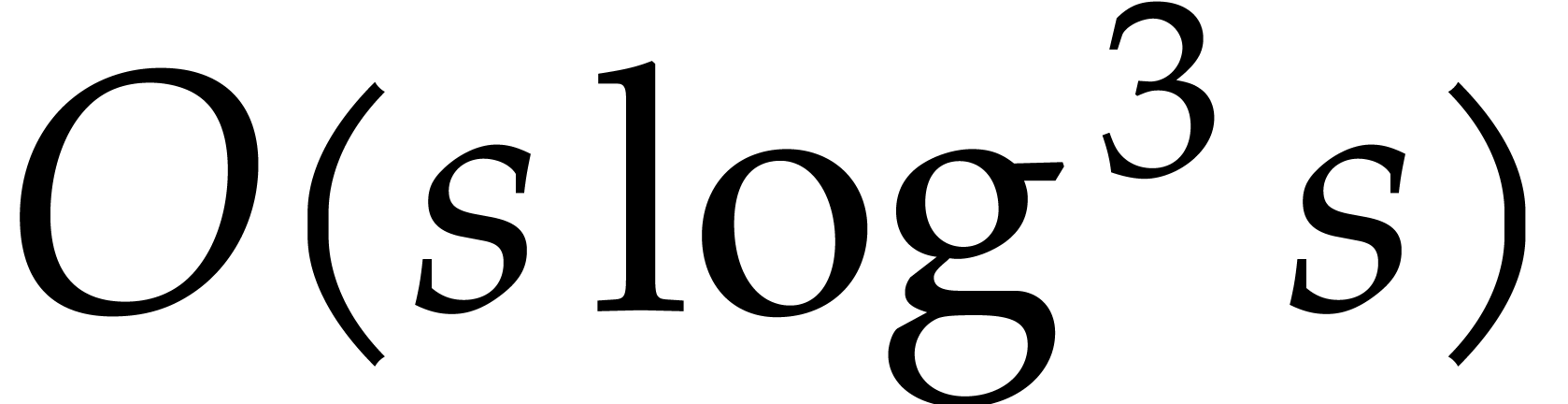 ,
,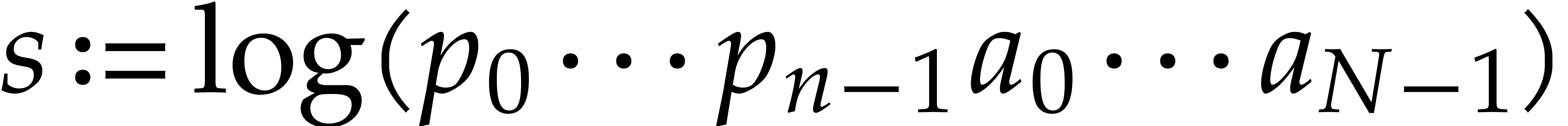 .
.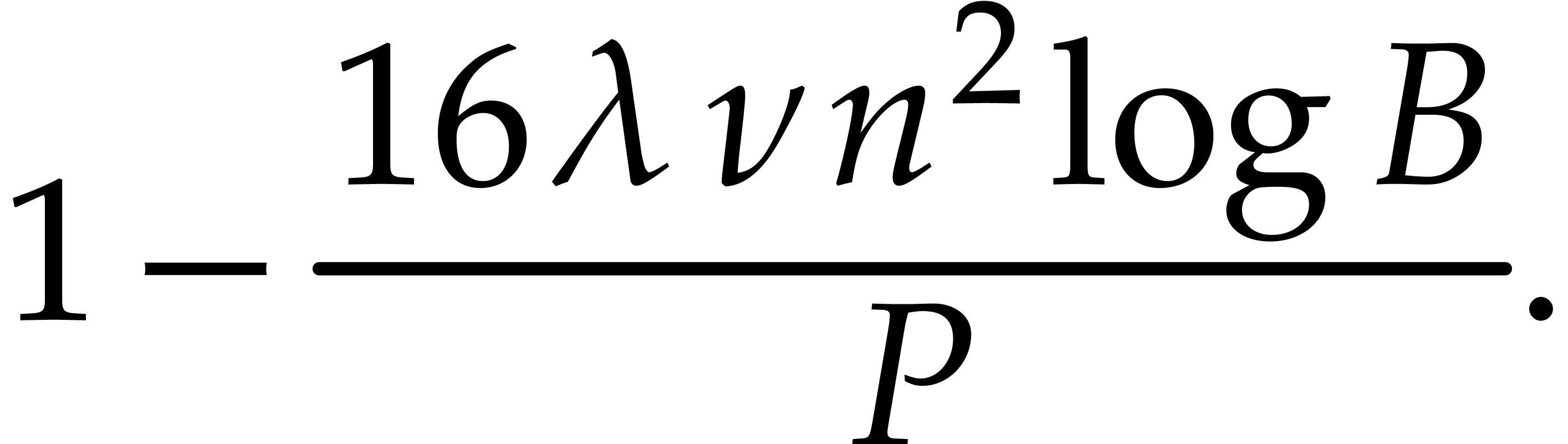
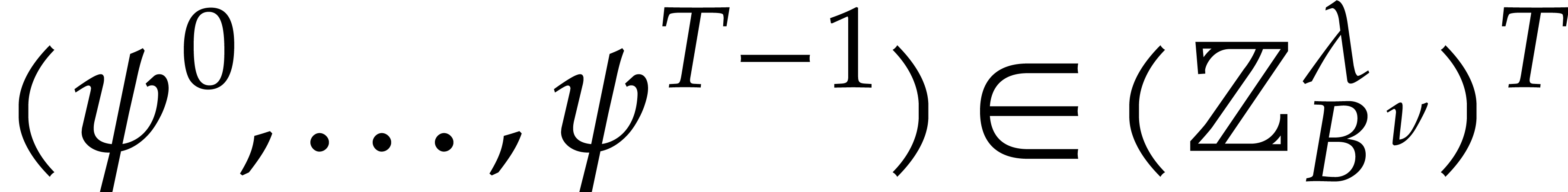 ,
, in time
in time  .
.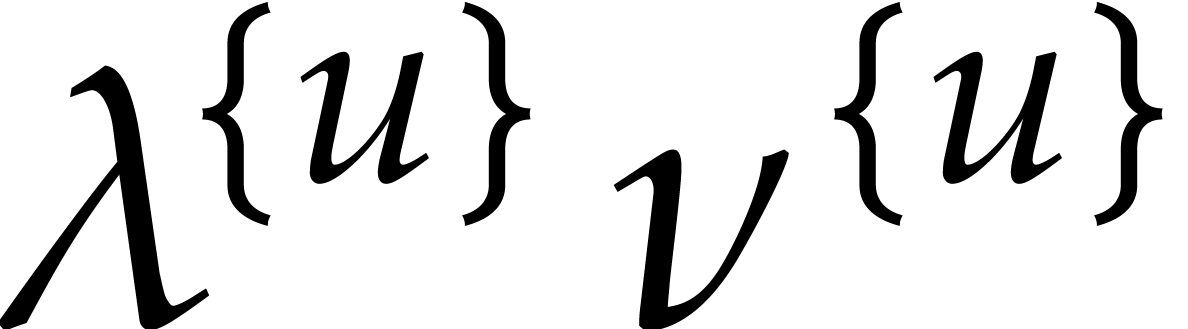

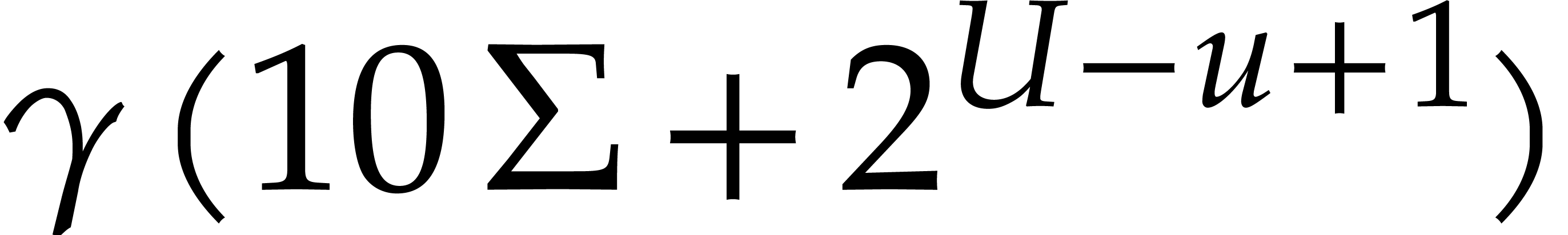
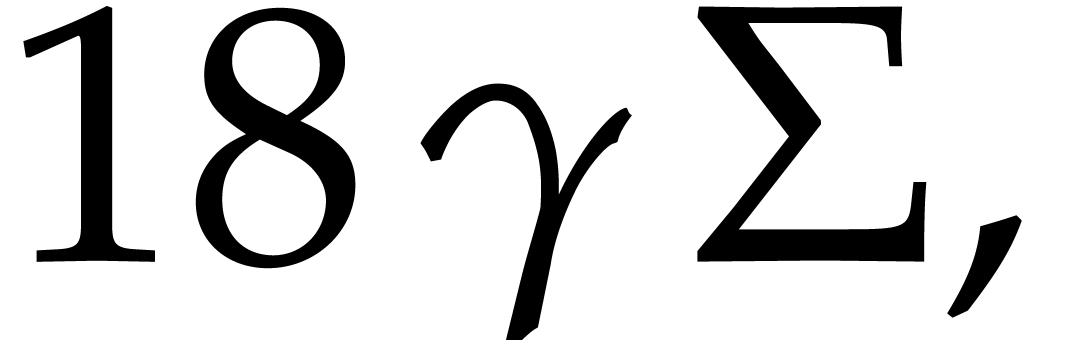
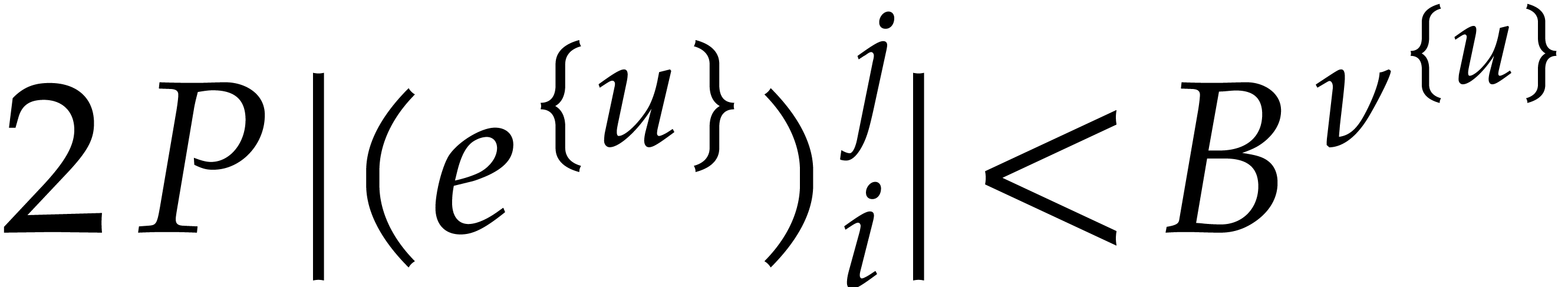 ;
;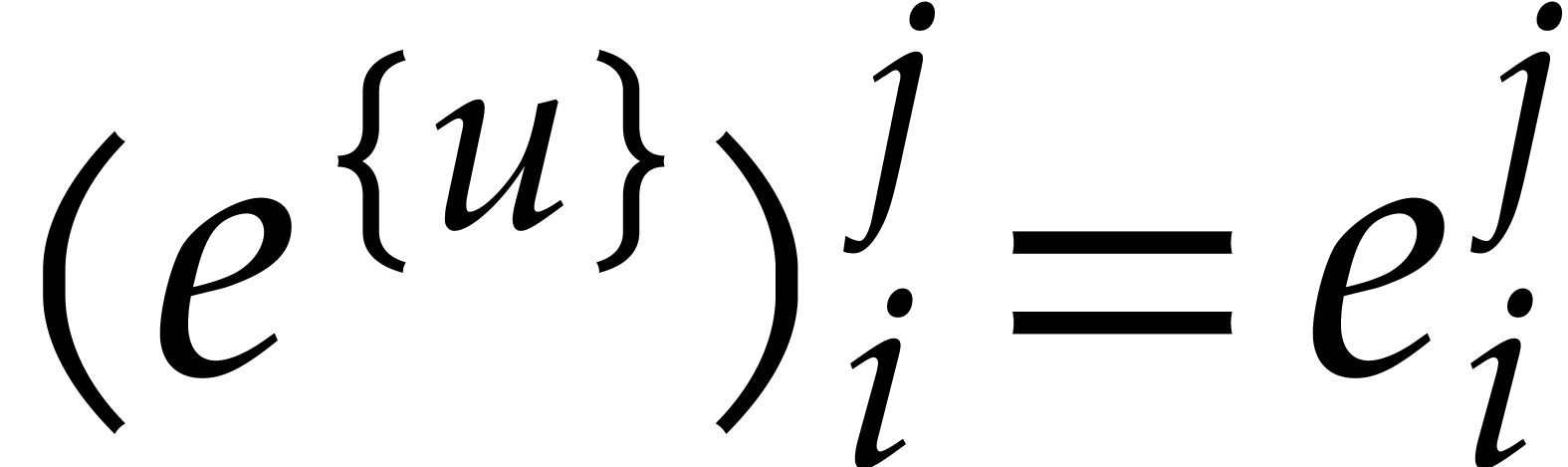 whenever
whenever 
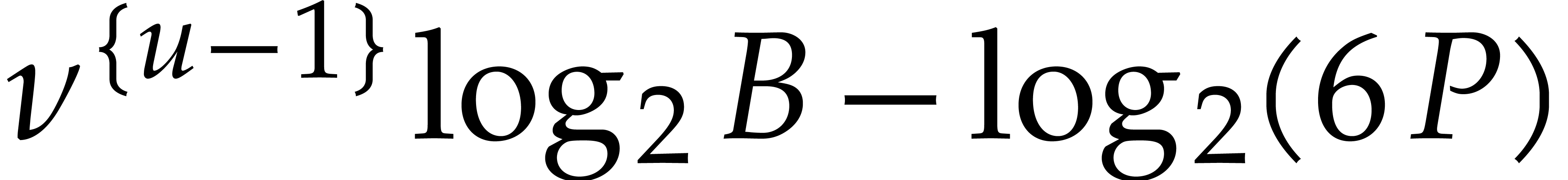
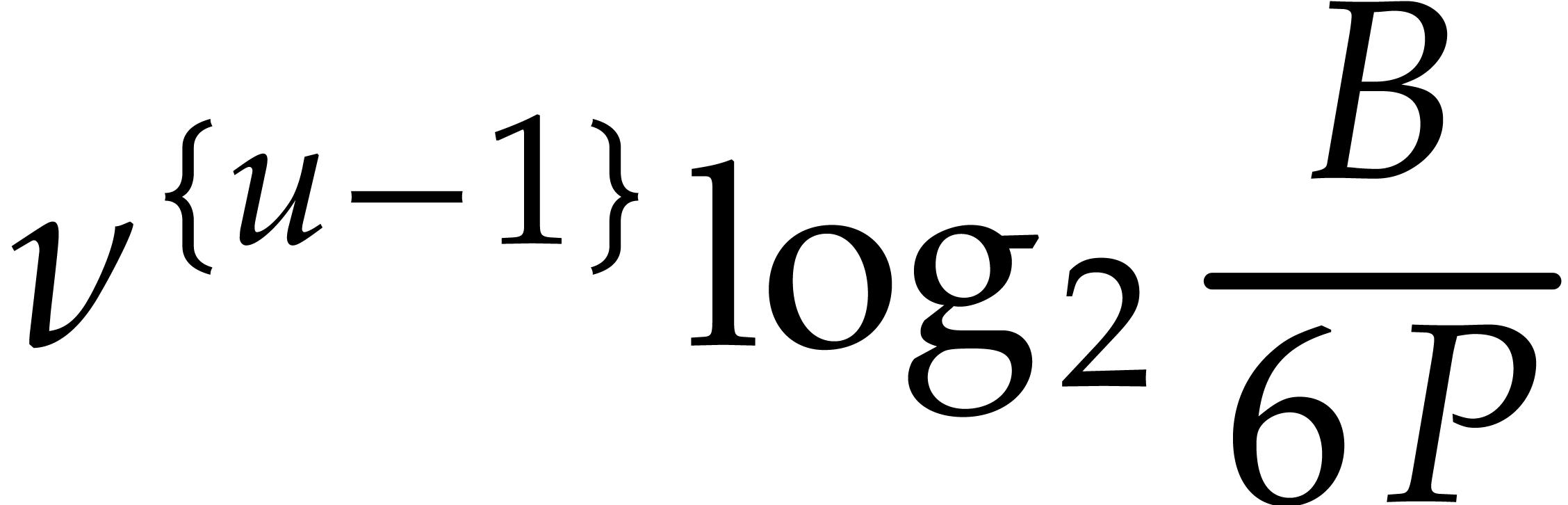
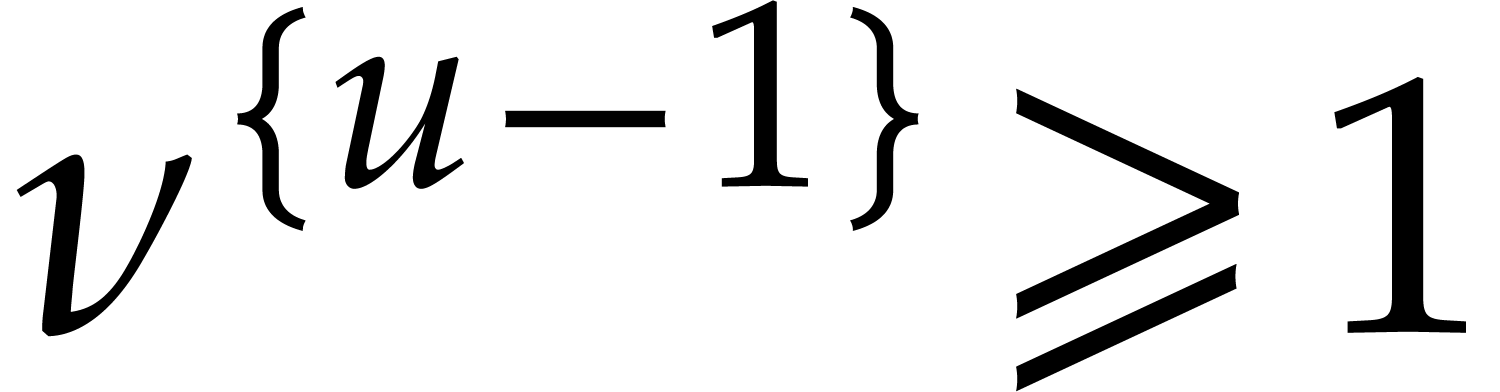 )
)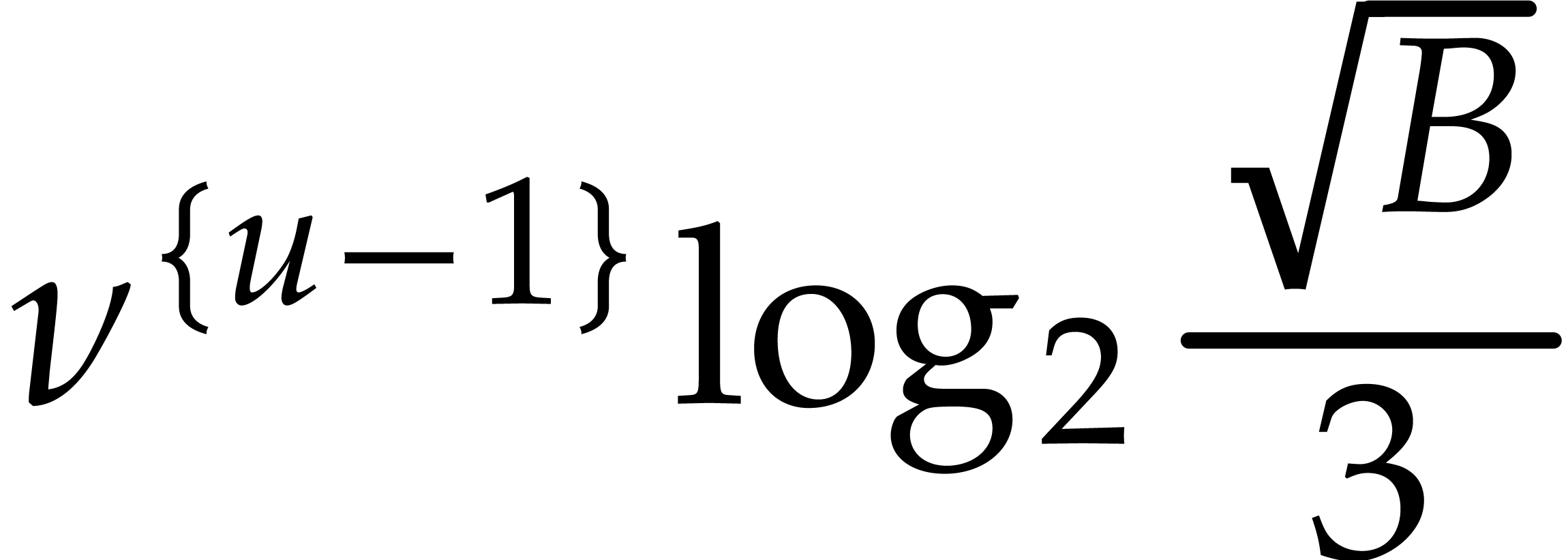
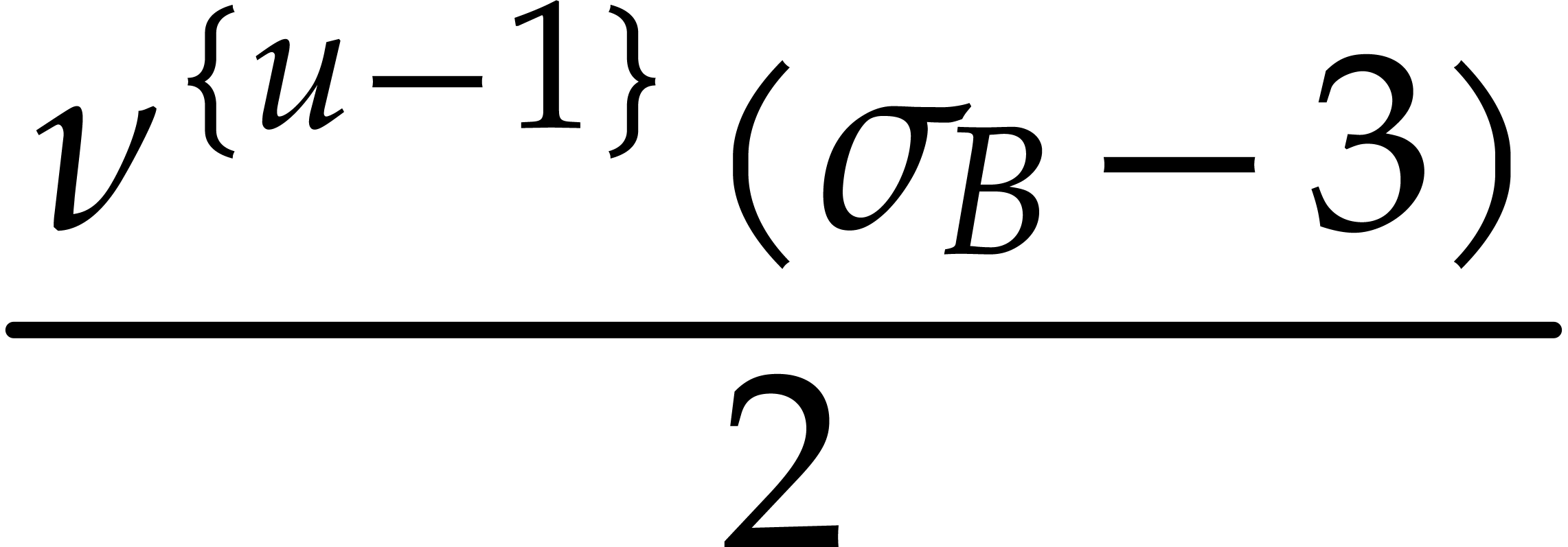
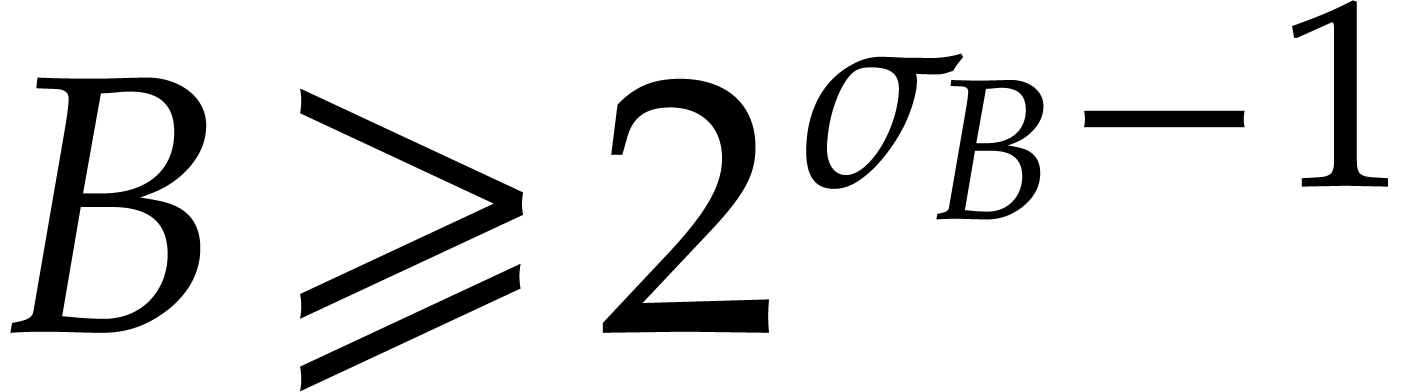 )
)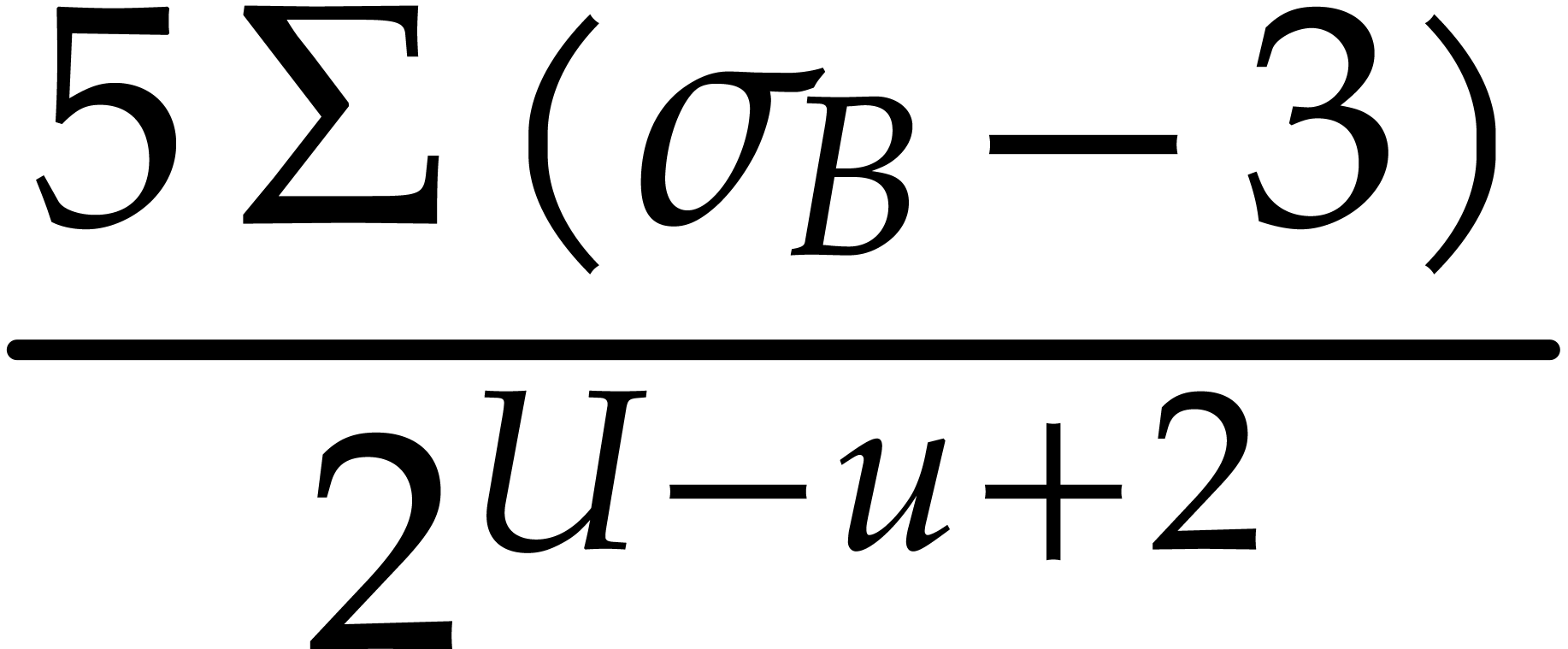
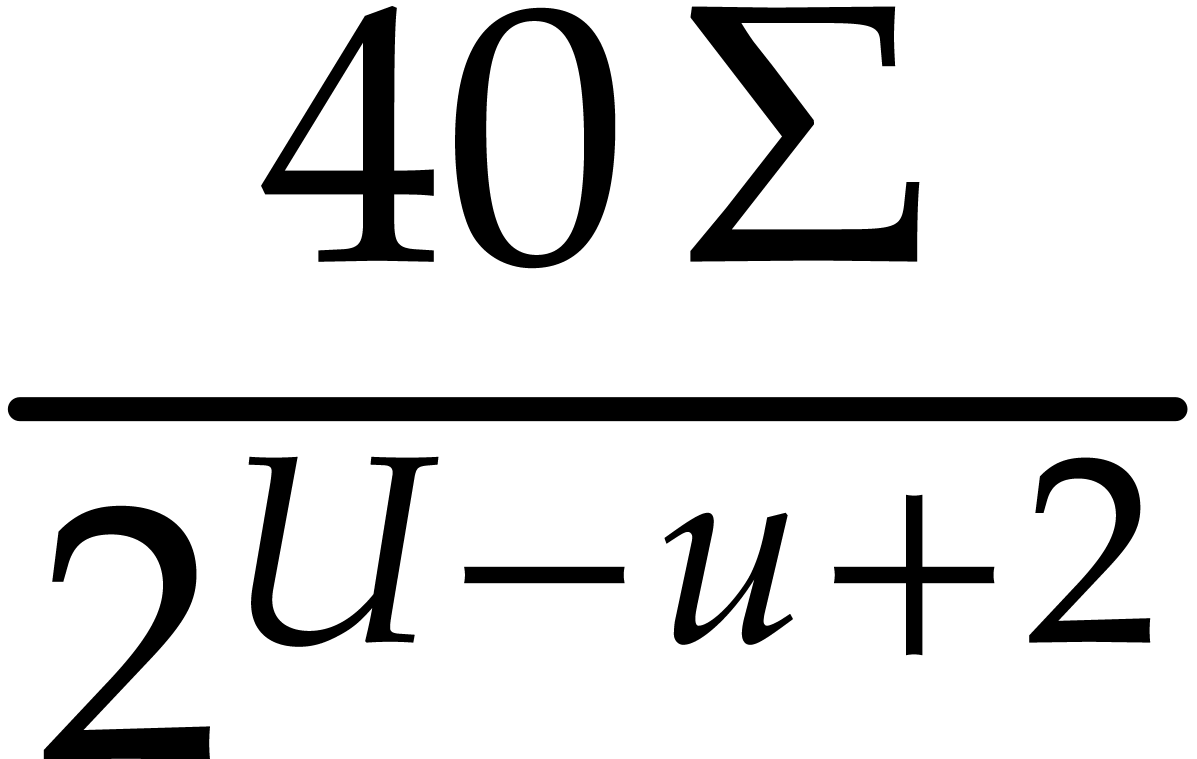
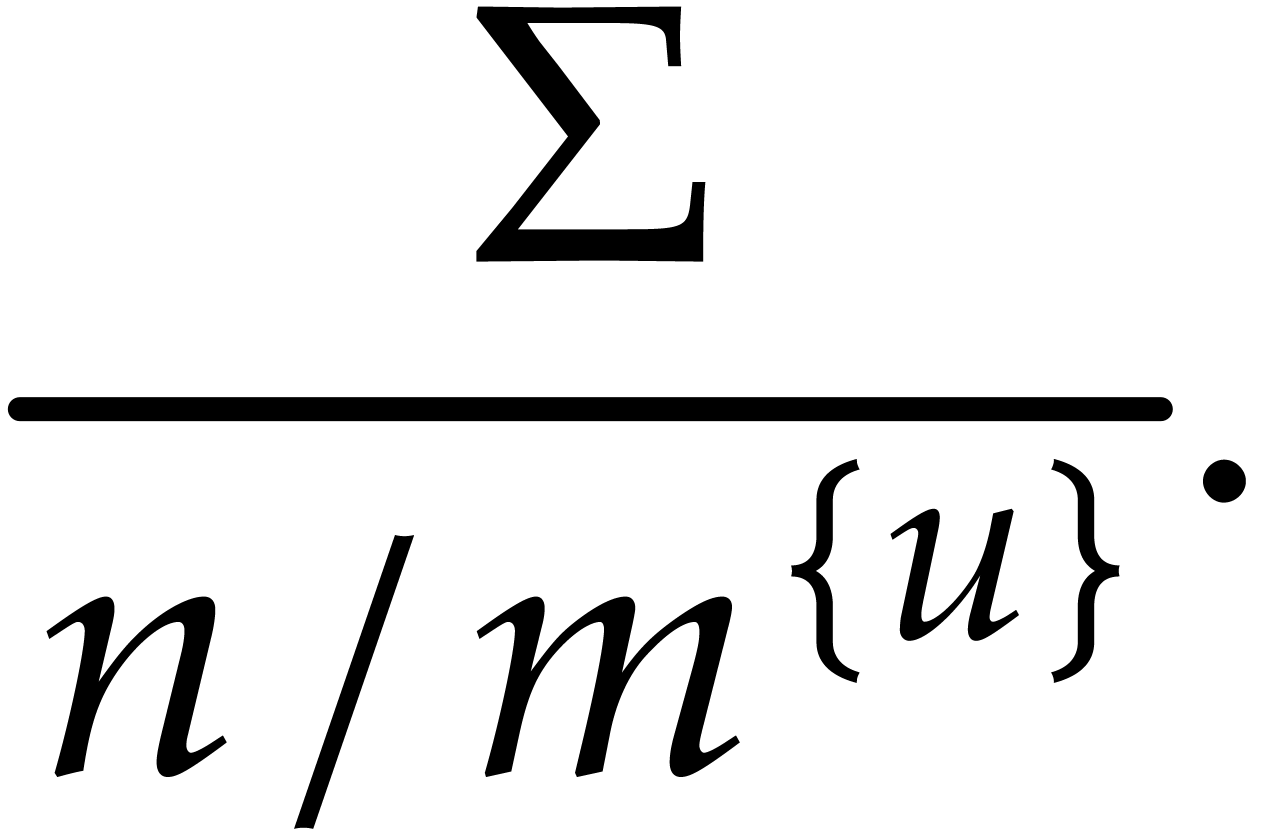
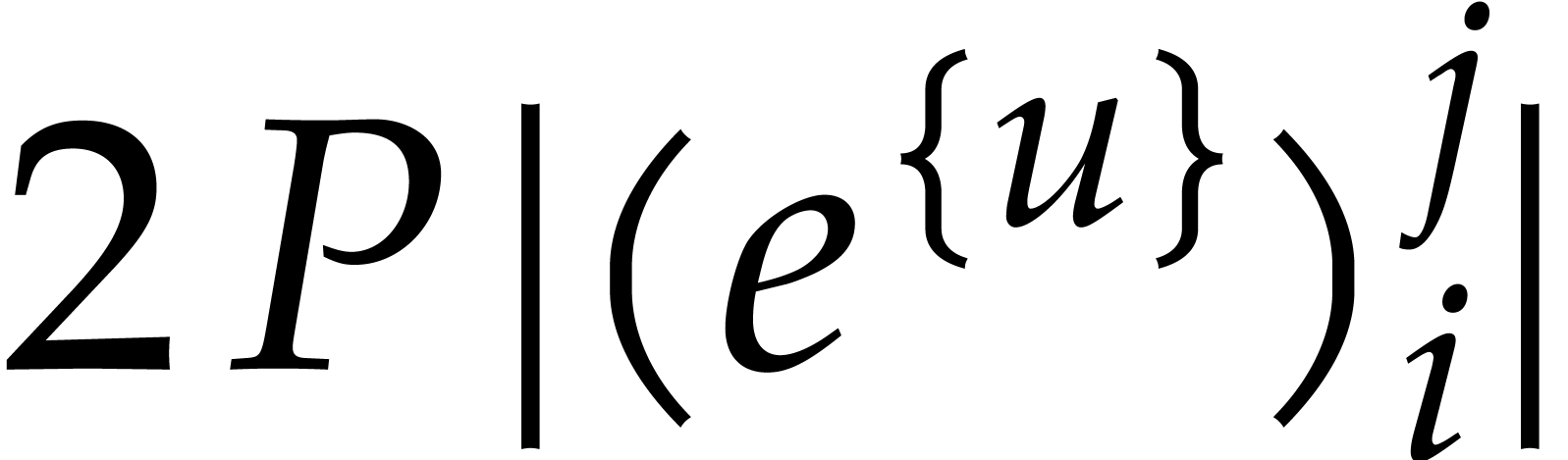
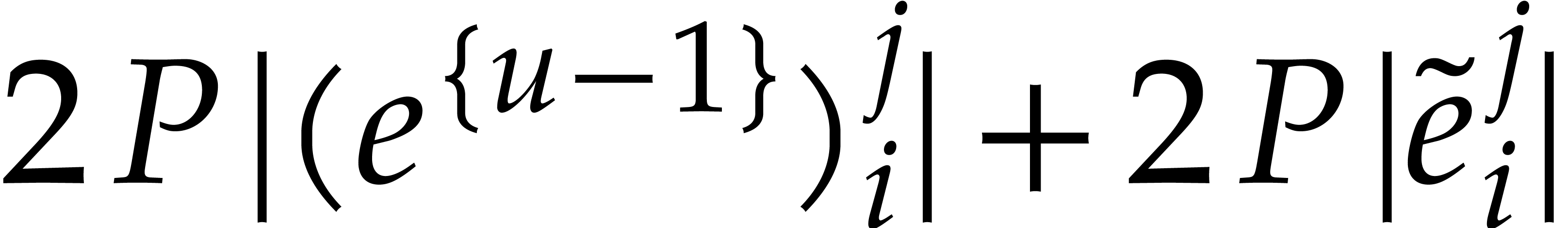
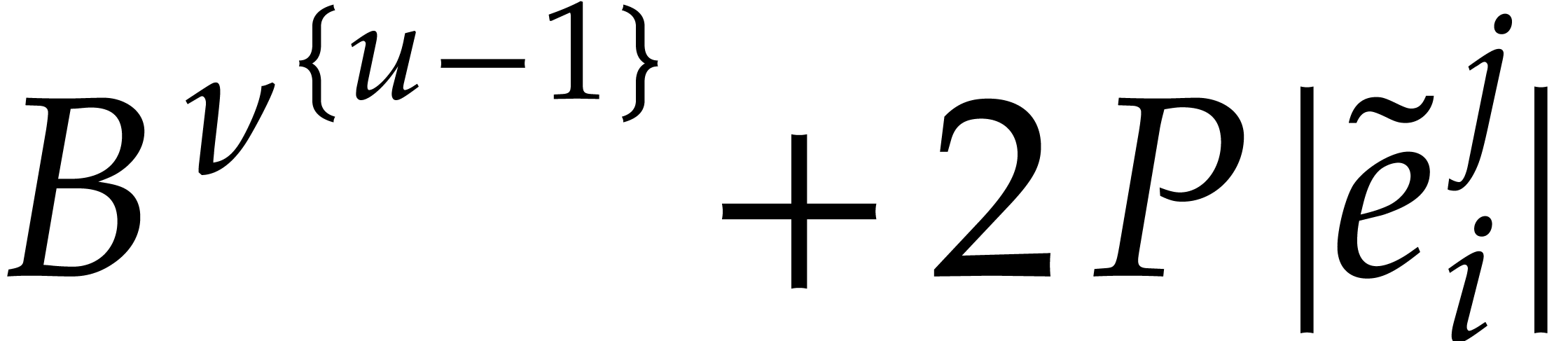
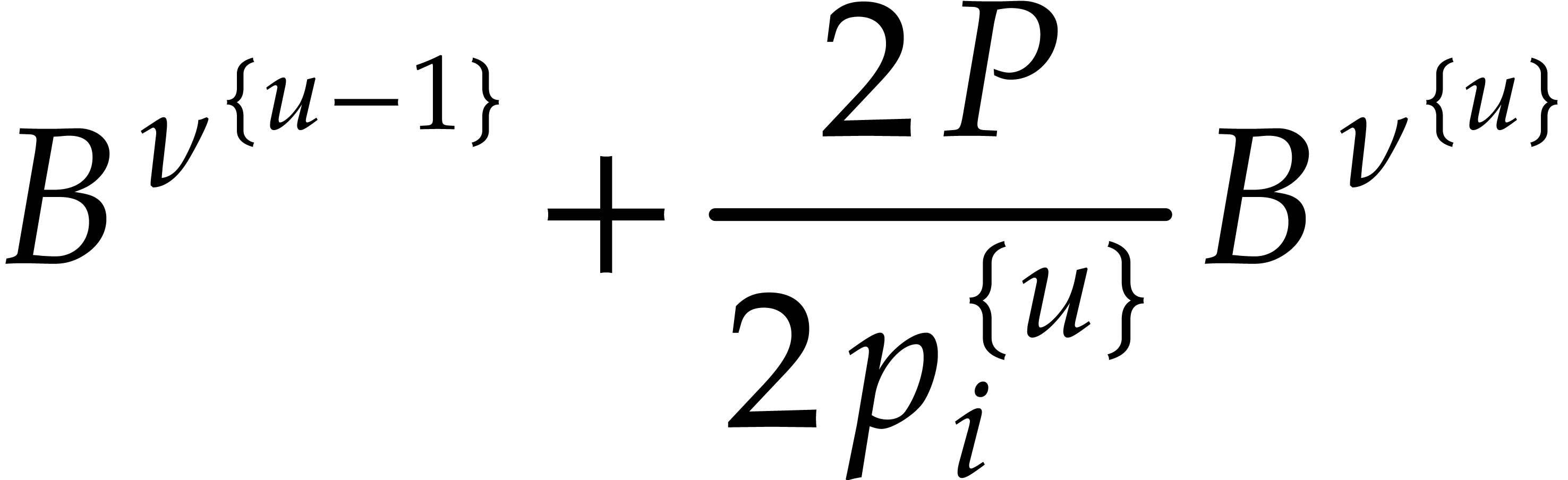
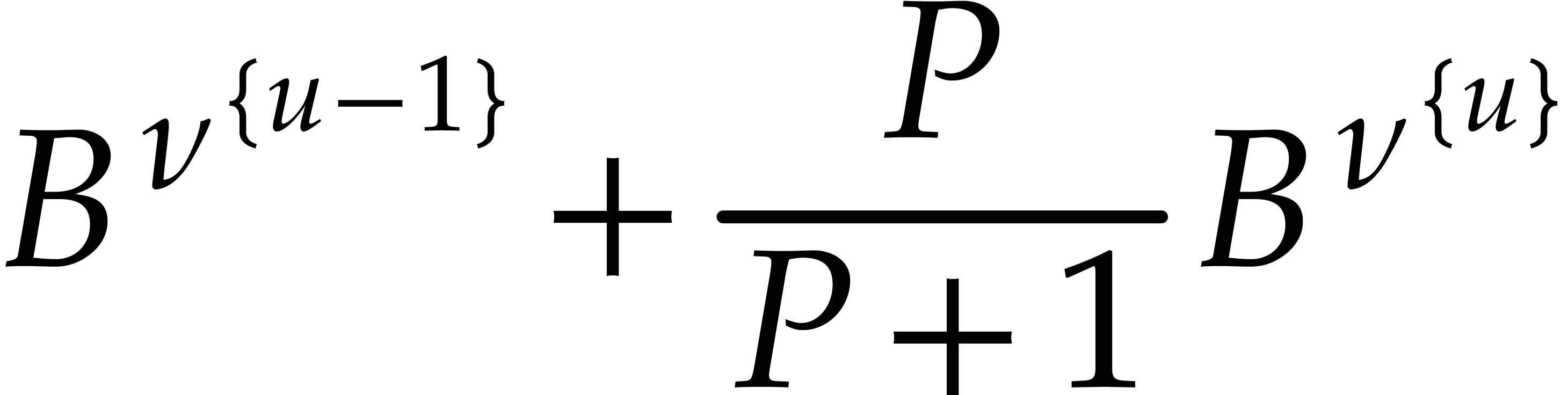
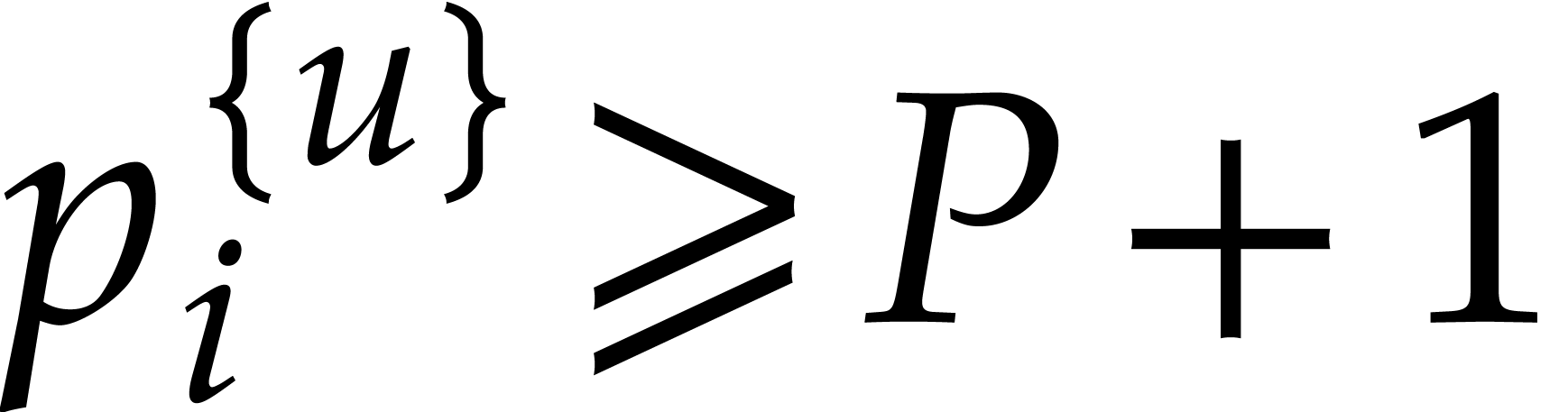 )
)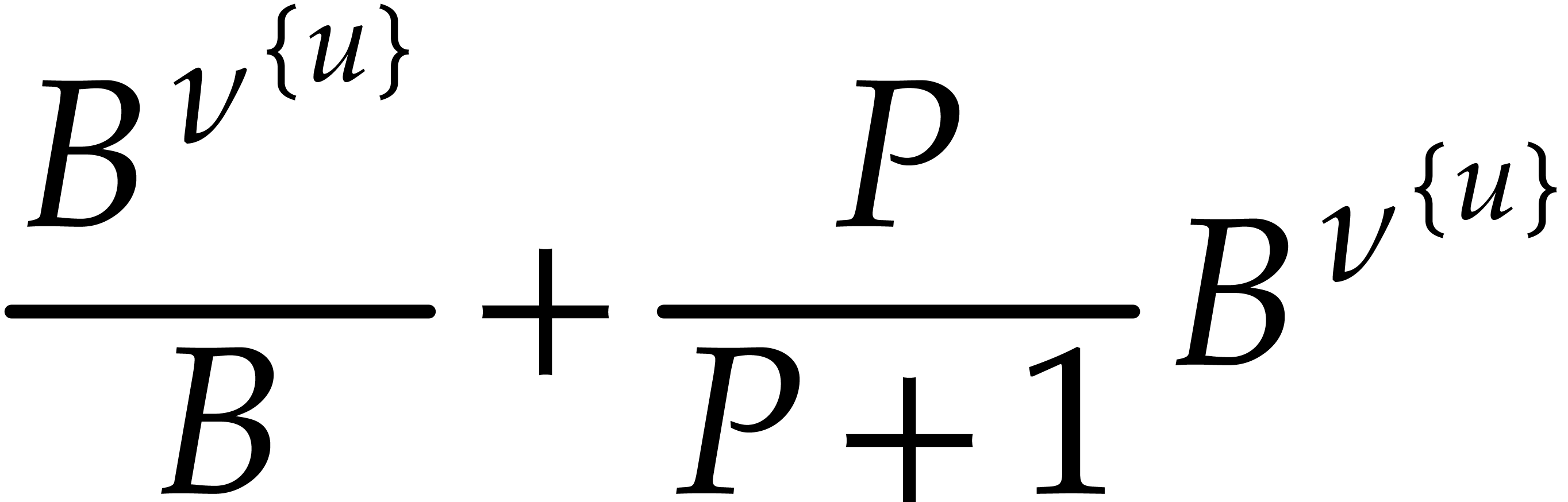
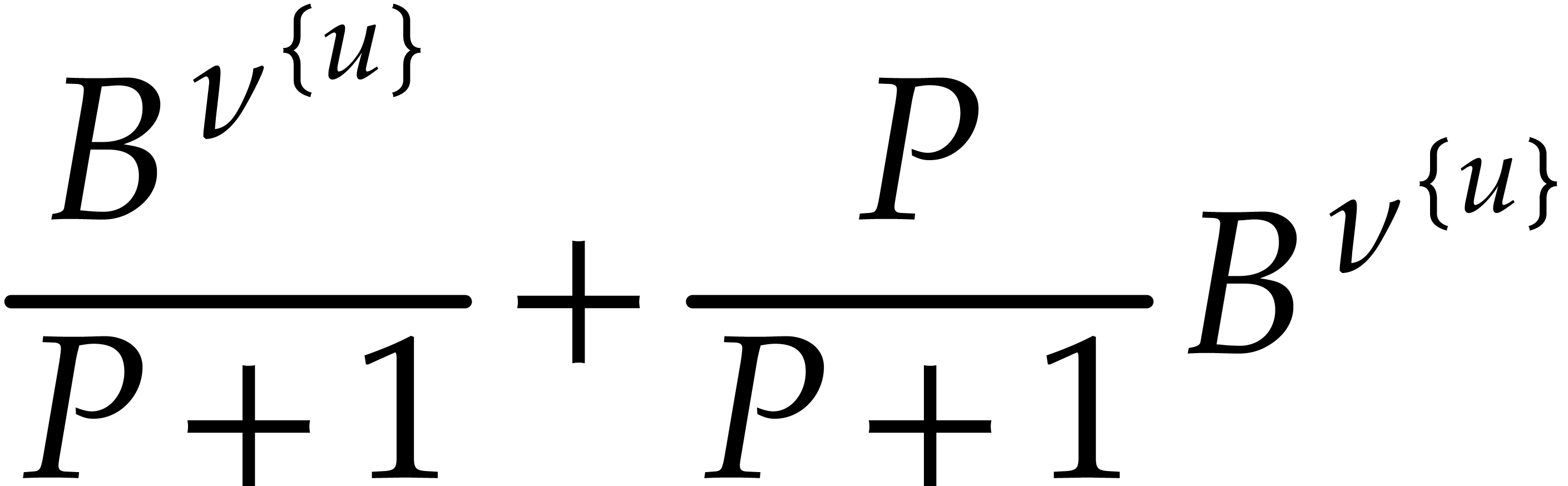
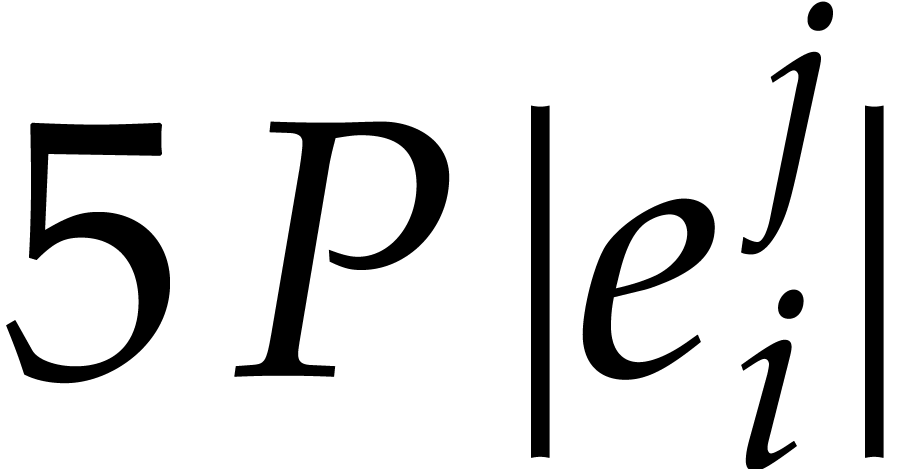
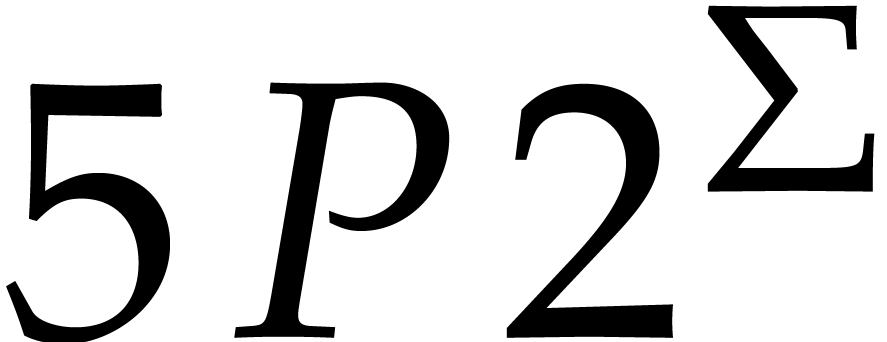

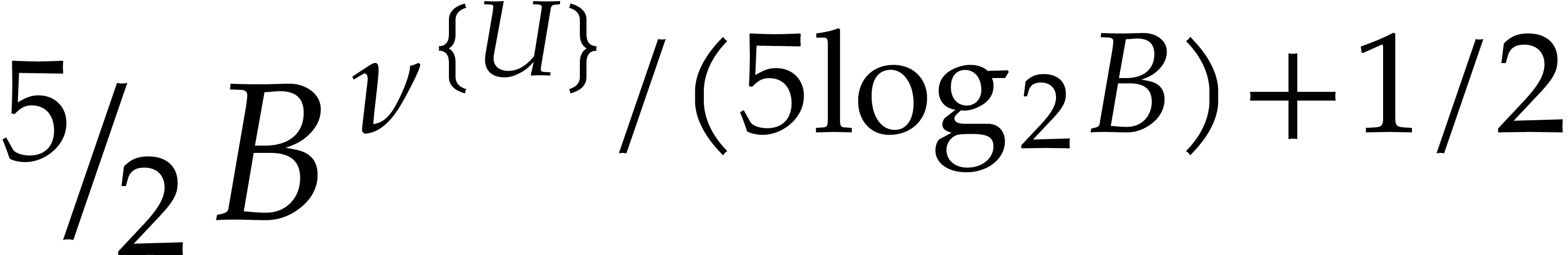
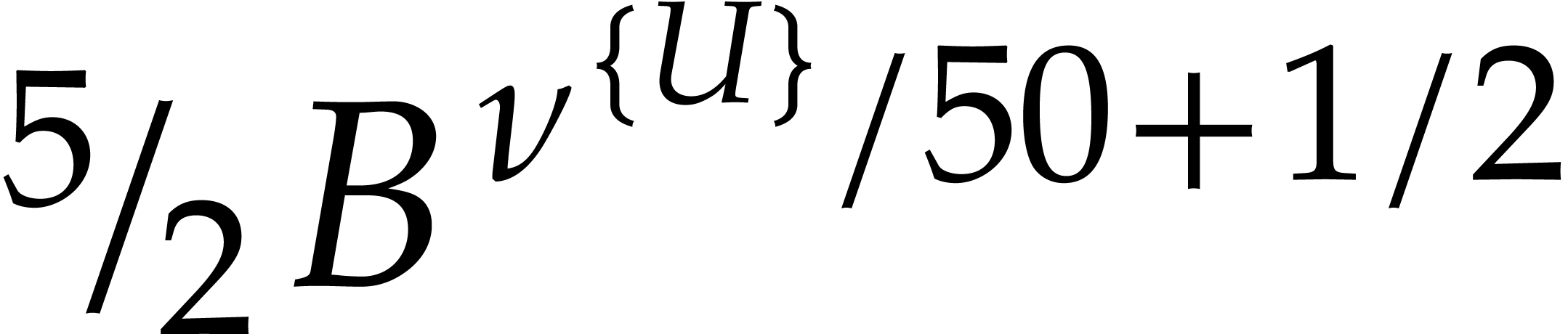
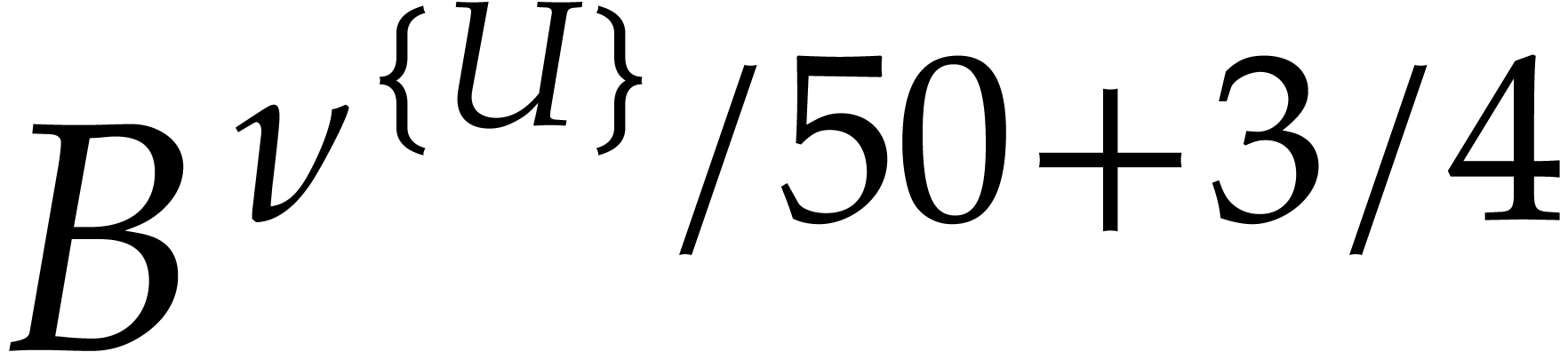
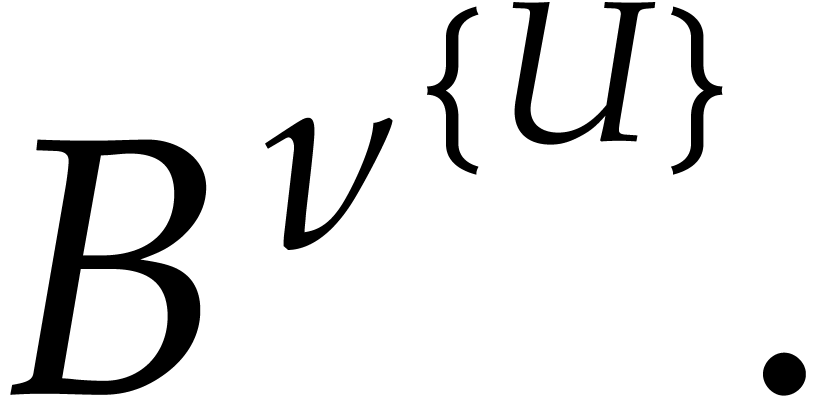
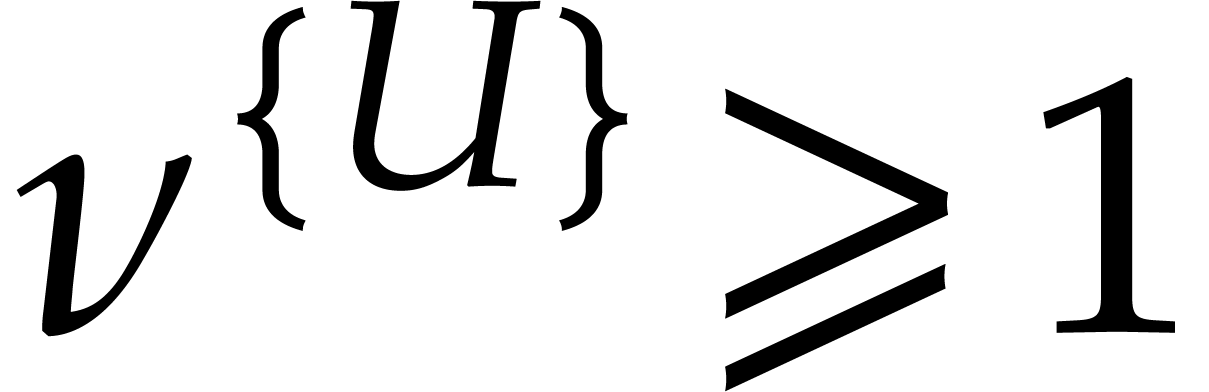 )
)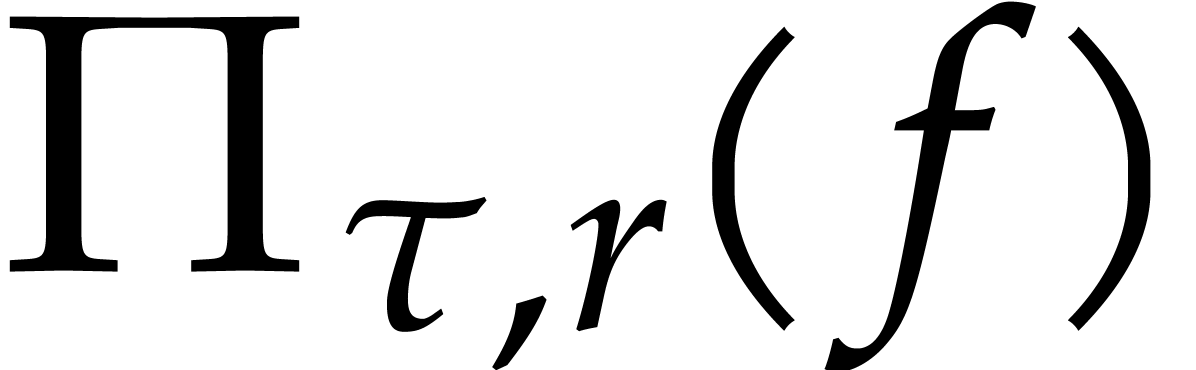 is at most
is at most  .
.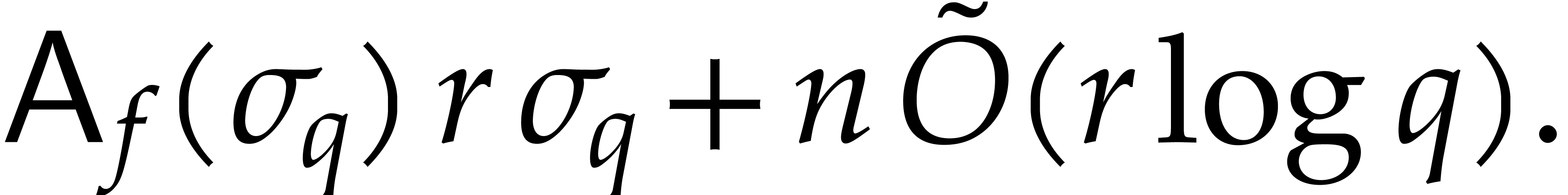
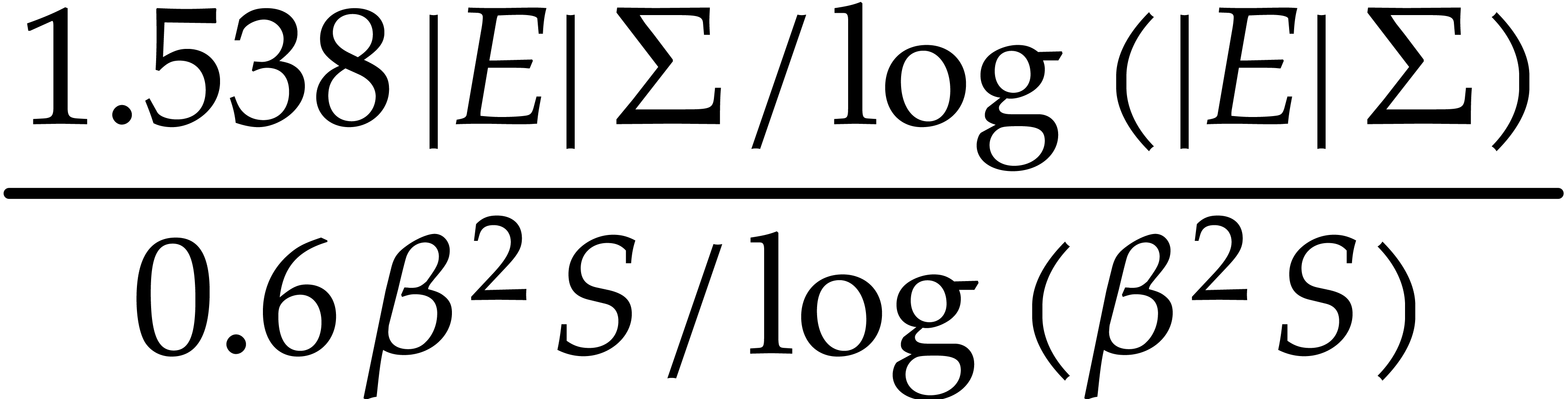
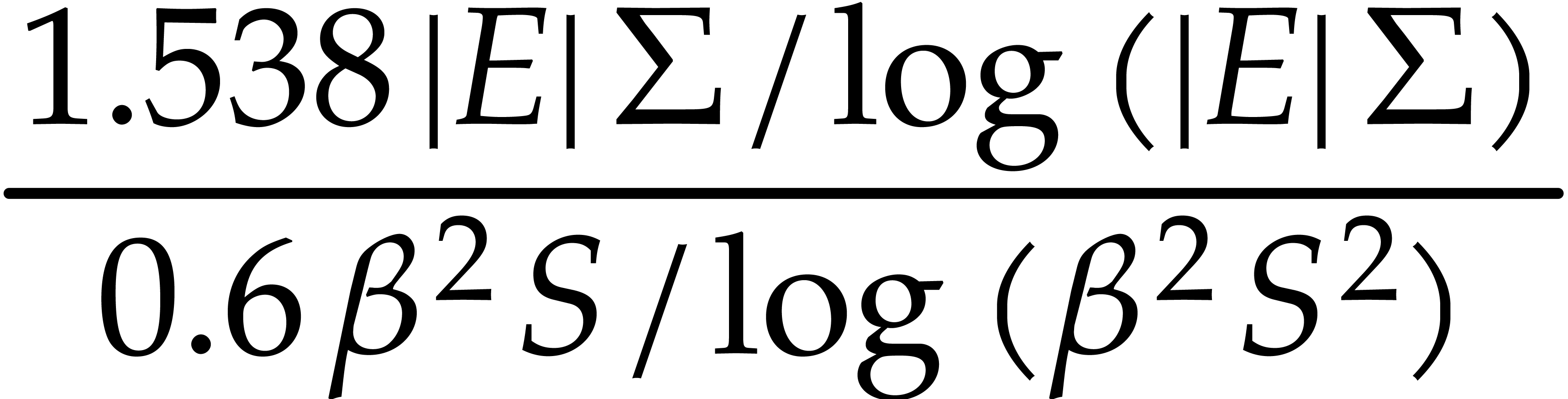
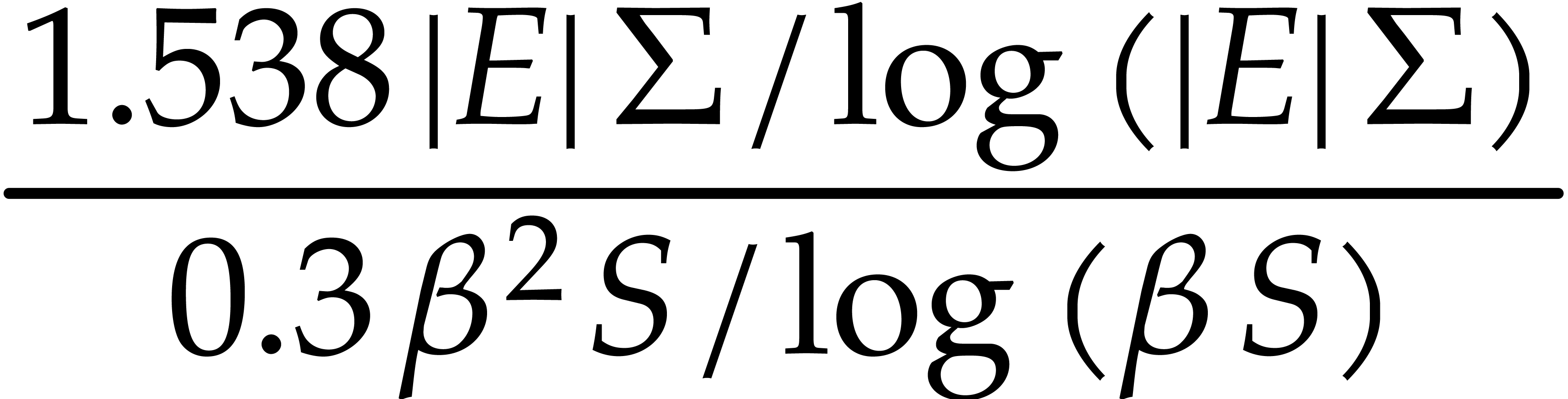
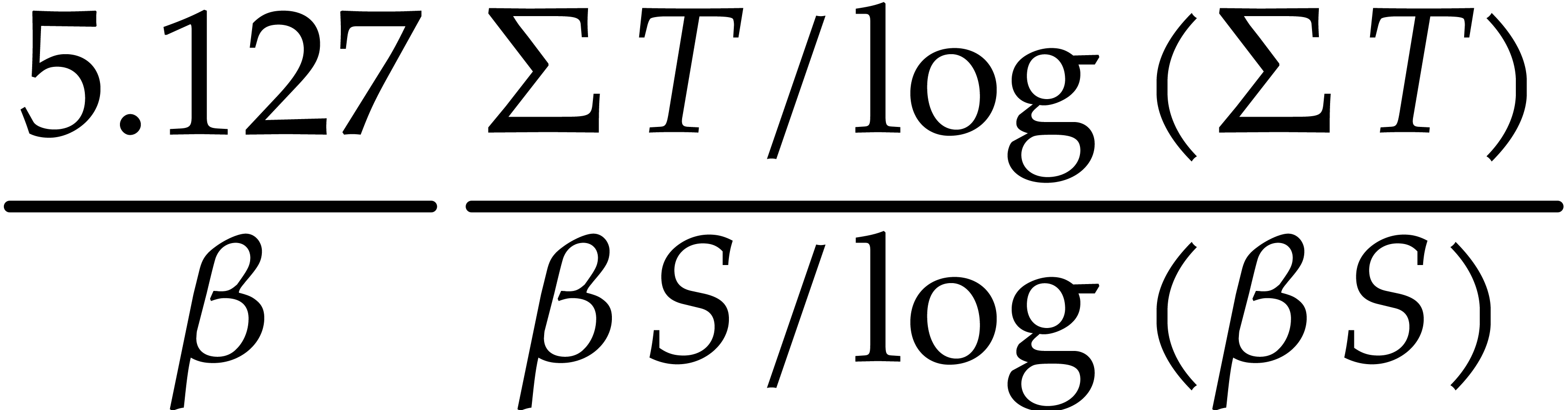
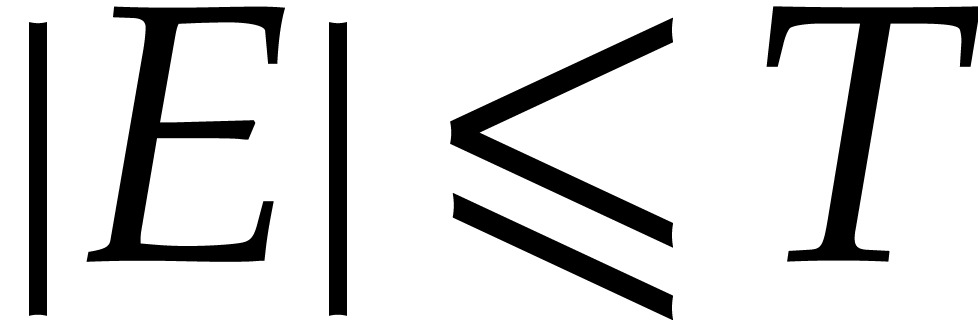 )
)
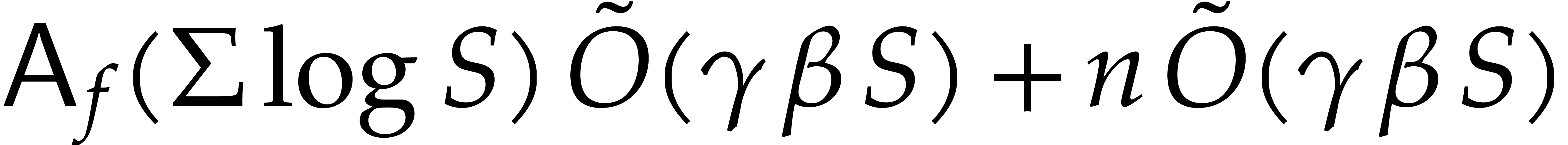
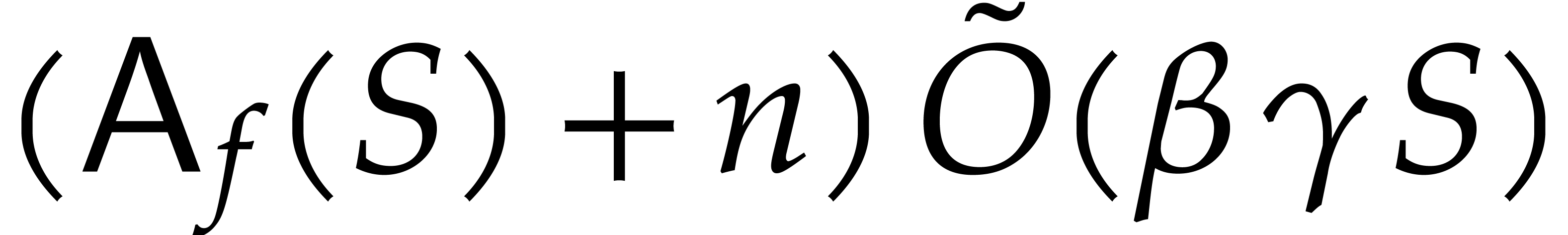

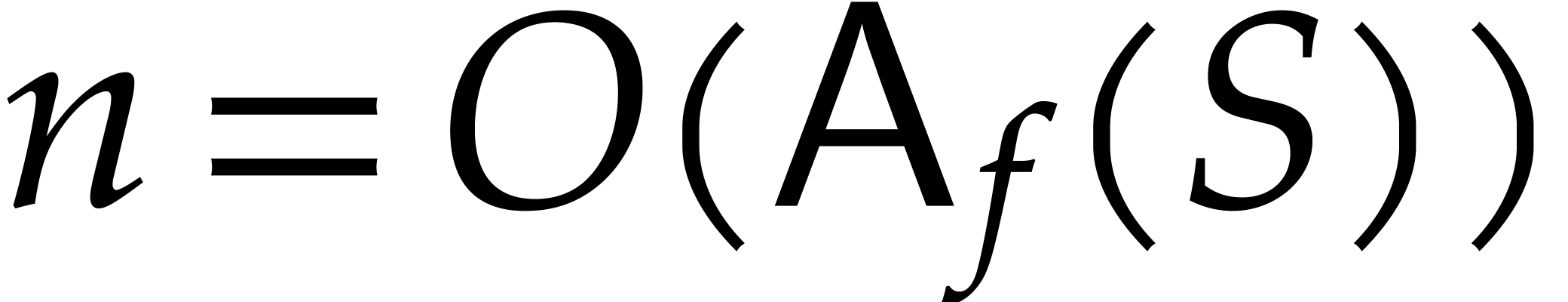 )
)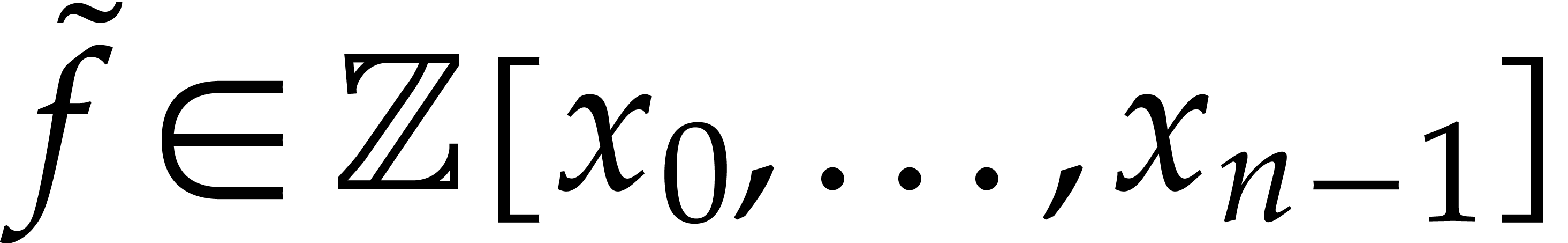 be written
be written
 .
.