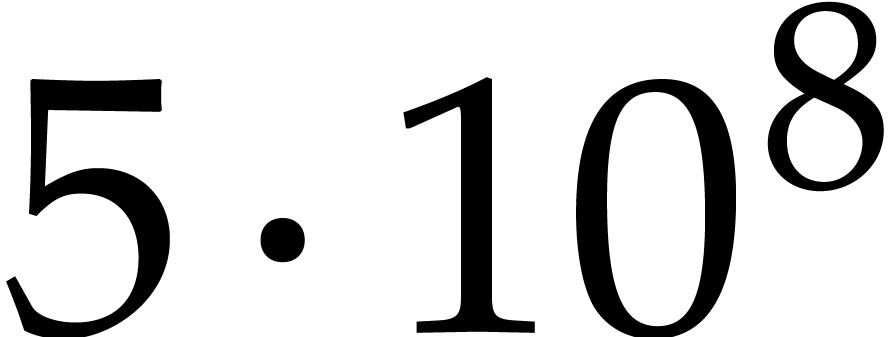| Computing one billion roots using the tangent Graeffe method   |
|
| July 18, 2020 |
|
 . This paper is
part of a project that has received funding from the French
“Agence de l'innovation de défense”.
. This paper is
part of a project that has received funding from the French
“Agence de l'innovation de défense”.
 . This article has
been written using GNU TeXmacs [28].
. This article has
been written using GNU TeXmacs [28].
Let
We used the tangent Graeffe root finding algorithm from [19,
27] which is a factor of
In this article we discuss the steps of the tangent Graeffe
algorithm, the sub-algorithms that we used, how we parallelized
them, and how we organized the memory so we could factor a
polynomial of degree Polynomial root finding over smooth finite fields is a key ingredient for algorithms for sparse polynomial interpolation that are based on geometric sequences. This application was also one of our main motivations for the present work. |
Consider a polynomial function  over a field
over a field  given through a black box capable of evaluating
given through a black box capable of evaluating  at points in
at points in  .
The problem of sparse interpolation is to recover the
representation of
.
The problem of sparse interpolation is to recover the
representation of  in its usual form, as a linear
combination
in its usual form, as a linear
combination
 |
(1) |
of monomials  . One popular
approach to sparse interpolation is to evaluate
at points in a geometric progression. This approach goes back to work of
Prony in the eighteen's century [41] and became well known
after Ben-Or and Tiwari's seminal paper [2]. It has widely
been used in computer algebra, both in theory [7, 30,
32–35, 39] and in practice
[11, 14, 24, 25, 29, 31]; see [43] for a nice survey.
. One popular
approach to sparse interpolation is to evaluate
at points in a geometric progression. This approach goes back to work of
Prony in the eighteen's century [41] and became well known
after Ben-Or and Tiwari's seminal paper [2]. It has widely
been used in computer algebra, both in theory [7, 30,
32–35, 39] and in practice
[11, 14, 24, 25, 29, 31]; see [43] for a nice survey.
More precisely, if a bound  for the number of
terms
for the number of
terms  is known, then we first evaluate at
is known, then we first evaluate at  pairwise distinct points
pairwise distinct points  , where
, where  and
and
 for all
for all  .
The generating function of the evaluations at
.
The generating function of the evaluations at  satisfies the identity
satisfies the identity

where  and
and  is of degree
is of degree
 . The rational function
. The rational function  can be recovered from
can be recovered from  using
fast Padé approximation [6, 37]. For
well chosen points
using
fast Padé approximation [6, 37]. For
well chosen points  , it is
often possible to recover the exponents
, it is
often possible to recover the exponents  from the
values
from the
values  . If the exponents
are known, then the coefficients
. If the exponents
are known, then the coefficients  can also be recovered using a transposed version of fast
multipoint interpolation [5, 7]. This leaves
us with the question how to compute the roots
can also be recovered using a transposed version of fast
multipoint interpolation [5, 7]. This leaves
us with the question how to compute the roots  of
of
 in an efficient way.
in an efficient way.
For practical applications in computer algebra, we usually have  , in which case it is most
efficient to use a multi-modular strategy. This means that we rather
work with coefficients in a finite field
, in which case it is most
efficient to use a multi-modular strategy. This means that we rather
work with coefficients in a finite field  ,
where
,
where  is a prime number that we are free to
choose. It is well known that polynomial arithmetic over
is a prime number that we are free to
choose. It is well known that polynomial arithmetic over  can be implemented most efficiently using FFTs when the
order
can be implemented most efficiently using FFTs when the
order  of the multiplicative group is smooth. In
practice, this prompts us to choose of the form
of the multiplicative group is smooth. In
practice, this prompts us to choose of the form
 for some small
for some small  and such
that fits into a machine word.
and such
that fits into a machine word.
The traditional way to compute roots of polynomials over finite fields
is using Cantor and Zassenhaus' method [8]. In [19,
20], alternative algorithms were proposed for our case of
interest when is smooth. The fastest algorithm
was based on the tangent Graeffe transform and it gains a
factor  with respect to Cantor–Zassenhaus'
method. The aim of the present paper is to report on a parallel
implementation of this new algorithm and on a few improvements that
allow for a further constant speed-up. A preliminary version of this
paper was published at ICMS 2020 [27]. The new
contributions in this paper include the theoretical contributions in
sections 3.4, 3.5, 3.6 and 3.7, the implementation details in section 4 and
the (parallel) timing results in section 5.
with respect to Cantor–Zassenhaus'
method. The aim of the present paper is to report on a parallel
implementation of this new algorithm and on a few improvements that
allow for a further constant speed-up. A preliminary version of this
paper was published at ICMS 2020 [27]. The new
contributions in this paper include the theoretical contributions in
sections 3.4, 3.5, 3.6 and 3.7, the implementation details in section 4 and
the (parallel) timing results in section 5.
In section 2, we start by recalling generalities about the Graeffe transform and the heuristic root finding method based on the tangent Graeffe transform from [19]. In section 3, we present the main new theoretical improvements, which all rely on optimizations in the FFT-model for fast polynomial arithmetic. Our contributions are threefold:
In the FFT-model, one backward transform out of four can be saved for Graeffe transforms of order two (see section 3.2).
When composing a large number of Graeffe transforms of order two,
“FFT caching” [3] can be used to gain
another factor of  (see section 3.3).
(see section 3.3).
All optimizations still apply in the TFT model, which can save a factor between one and two, depending on the number of roots (see section 3.5).
In section 3.4 we also indicate how to generalize our
methods to Graeffe transforms of general orders. In section 3.7
we determine how much faster the tangent Graeffe algorithm is than the
Cantor–Zassenhaus algorithm. To do this, we determine the constant
factors in the complexities of both algorithms, under the assumption
that arithmetic in  is done using FFT-based
algorithms.
is done using FFT-based
algorithms.
We first implemented a sequential version of the tangent Graeffe method
in C, with the optimizations from sections 3.2 and 3.3;
see [27]. Section 4 is devoted to a more
elaborate parallel implementation in Cilk C. We detail how we
parallelized the different steps of the algorithm, and how we organized
the memory so we could factor a polynomial of degree  over , for
over , for  . We believe we are the first to factor such
large polynomials. Our code is available here
. We believe we are the first to factor such
large polynomials. Our code is available here
In the last section 5, we give timings. We used a
multi-core computer with two 10 core Intel Xeon E5 2680 v2 CPUs and 128
gigabytes of RAM. The above factorization of a polynomial of degree then takes just under 4,000 seconds on 10 cores and
uses 121 gigabytes of RAM.
Let be an effective field. Throughout the paper,
time complexities count arithmetic operations in the field and space complexities are for elements of . We use  to denote the
time for multiplying two polynomials in
to denote the
time for multiplying two polynomials in  of
degree
of
degree  . We make the
customary assumption that
. We make the
customary assumption that  is a non-decreasing
function that tends to infinity.
is a non-decreasing
function that tends to infinity.
We will chiefly be interested in the case when , where is a prime of the
form  with
with  small. We call
primes of this form smooth Fourier primes. Some examples that
we use and their bit lengths are as follows:
small. We call
primes of this form smooth Fourier primes. Some examples that
we use and their bit lengths are as follows:

For and of this form and
 , we have
, we have  , by using FFT-multiplication.
, by using FFT-multiplication.
Let  be a polynomial of degree
be a polynomial of degree  in
in  which has distinct
roots in . The tangent
Graeffe algorithm computes the roots of .
The cost of the algorithm depends on a parameter
which has distinct
roots in . The tangent
Graeffe algorithm computes the roots of .
The cost of the algorithm depends on a parameter  with
with  . The parameter determines what proportion of the roots are found in
each iteration of the algorithm. The space complexity of the algorithm
is
. The parameter determines what proportion of the roots are found in
each iteration of the algorithm. The space complexity of the algorithm
is  and the average time complexity is
and the average time complexity is

Theoretically, choosing  yields the best time
complexity. However, because we want to factor polynomials with very
large , our implementation
chooses a smaller in the interval
yields the best time
complexity. However, because we want to factor polynomials with very
large , our implementation
chooses a smaller in the interval  to save space. For
to save space. For  the time
complexity is
the time
complexity is

In this section, we recall the tangent Graeffe algorithm from [19]. In the next section, we will analyze its complexity in the FFT-model and present several improvements.
Let be a general field. The traditional
Graeffe transform of a monic polynomial  of degree is the unique polynomial
of degree is the unique polynomial  of degree such that
of degree such that
 |
(2) |
If  is monic, then so is
is monic, then so is  . If splits over into linear factors
. If splits over into linear factors  ,
then one has
,
then one has

More generally, given  , we
define the Graeffe transform of order
, we
define the Graeffe transform of order  to be the polynomial
to be the polynomial  of degree
given by
of degree
given by

If , then

If  is a primitive -th
root of unity in , then we
also have
is a primitive -th
root of unity in , then we
also have
 |
(3) |
If  , then we finally have
, then we finally have
 |
(4) |
Let  be a formal indeterminate with
be a formal indeterminate with  . Elements in
. Elements in  are
called tangent numbers. They are of the form
are
called tangent numbers. They are of the form  with
with  and basic arithmetic operations go as
follows:
and basic arithmetic operations go as
follows:

Now let be a monic polynomial of degree that splits over :

where  are pairwise distinct. Then the
tangent deformation
are pairwise distinct. Then the
tangent deformation  satisfies
satisfies

The definitions from the previous subsection readily extend to
coefficients in  instead of . Given ,
we call
instead of . Given ,
we call  the tangent Graeffe transform
of of order .
We have
the tangent Graeffe transform
of of order .
We have

where

Now assume that we have an efficient way to determine the roots  of
of  . For
some polynomial
. For
some polynomial  , we may
decompose
, we may
decompose

For any root  of ,
we then have
of ,
we then have

Whenever happens to be a single root of , it follows that

If  , this finally allows us
to recover
, this finally allows us
to recover  as
as

Assume now that is a finite field, where is a prime number of the form  for some small . Assume also
that
for some small . Assume also
that  is a primitive element of order for the multiplicative group of .
is a primitive element of order for the multiplicative group of .
Let  be as in the previous subsection. The
tangent Graeffe method can be used to efficiently compute those of for which
is a single root of . In
order to guarantee that there are a sufficient number of such roots, we
first replace
be as in the previous subsection. The
tangent Graeffe method can be used to efficiently compute those of for which
is a single root of . In
order to guarantee that there are a sufficient number of such roots, we
first replace  by
by  for a
random shift
for a
random shift  , and use the
following heuristic:
, and use the
following heuristic:
For any subset  of cardinality and any
of cardinality and any  ,
there exist at least
,
there exist at least  elements such that
elements such that  contains at least
contains at least
 elements.
elements.
For a random shift and any , the assumption ensures with probability at
least  that
that  has at least
has at least
 single roots.
single roots.
Now take to be the largest power of two such
that and let  .
By construction, note that
.
By construction, note that  .
The roots of are all
-th roots of unity in the set
.
The roots of are all
-th roots of unity in the set
 , where
, where  . We may thus determine them by evaluating at
. We may thus determine them by evaluating at  for
for  . Since ,
this can be done efficiently using a discrete Fourier transform.
Combined with the tangent Graeffe method from the previous subsection,
this leads to the following probabilistic algorithm for root finding:
. Since ,
this can be done efficiently using a discrete Fourier transform.
Combined with the tangent Graeffe method from the previous subsection,
this leads to the following probabilistic algorithm for root finding:
Algorithm
|
||||||
Remark  we may use
we may use  ,
which requires three polynomial multiplications in
,
which requires three polynomial multiplications in  of degree
of degree  . In total, step 5
therefore performs
. In total, step 5
therefore performs  such multiplications. We
discuss how to perform step 5 efficiently in the FFT model
in section 3.
such multiplications. We
discuss how to perform step 5 efficiently in the FFT model
in section 3.
Remark for
 and the resulting threshold
and the resulting threshold  for
for  . For larger values of
, the computations of the
DFTs in step 6 get more expensive, but the proportion of
single roots goes up, so more roots are determined at each iteration.
From an asymptotic complexity perspective, it would be best to take
. In practice, we actually
preferred to take the lower threshold
. For larger values of
, the computations of the
DFTs in step 6 get more expensive, but the proportion of
single roots goes up, so more roots are determined at each iteration.
From an asymptotic complexity perspective, it would be best to take
. In practice, we actually
preferred to take the lower threshold  , because the constant factor of our implementation
of step 6 (based on Bluestein's algorithm [4])
is significant with respect to our highly optimized implementation of
the tangent Graeffe method. A second reason we prefer
of size
, because the constant factor of our implementation
of step 6 (based on Bluestein's algorithm [4])
is significant with respect to our highly optimized implementation of
the tangent Graeffe method. A second reason we prefer
of size  instead of
instead of  is
that the total space used by the algorithm is linear in .
is
that the total space used by the algorithm is linear in .
Remark  terms, the idea is to take
terms, the idea is to take  and
and  of order
of order  instead of for
some constant
instead of for
some constant  with
with  .
This reduces
.
This reduces  (and the cost of the top-level
iteration) by a factor of
(and the cost of the top-level
iteration) by a factor of  .
For the recursive calls, we still need to work with a primitive root of
unity
.
For the recursive calls, we still need to work with a primitive root of
unity  of order
of order  and
random shifts.
and
random shifts.
Assume that  is invertible in
and let
is invertible in
and let  be a primitive
be a primitive  -th root of unity. Consider a polynomial
-th root of unity. Consider a polynomial  . Then the discrete Fourier
transform (DFT) of order of the sequence
. Then the discrete Fourier
transform (DFT) of order of the sequence  is defined by
is defined by

We will write  for the cost of one discrete
Fourier transform in terms of the number of operations in . We assume that
for the cost of one discrete
Fourier transform in terms of the number of operations in . We assume that  .
For any
.
For any  , we have
, we have
 |
(5) |
If is invertible in , then it follows that  .
The costs of direct and inverse transforms therefore coincide up to a
factor
.
The costs of direct and inverse transforms therefore coincide up to a
factor  .
.
If  is composite,
is composite,  ,
and
,
and  , then we have
, then we have
This shows that a DFT of length reduces to  transforms of length
transforms of length  plus
transforms of length
plus multiplications in :
plus
transforms of length
plus multiplications in :

In particular, if  , then
, then
 .
.
It is sometimes convenient to apply DFTs directly to polynomials as
well; for this reason, we also define  .
Given two polynomials
.
Given two polynomials  with
with  , we may then compute the product
, we may then compute the product  using
using

In particular, we obtain  ,
where we recall that
,
where we recall that  stands for the cost of
multiplying two polynomials of degree
stands for the cost of
multiplying two polynomials of degree  .
.
Remark .
Since is a power of two, this length is of the
form  for some
for some  .
In view of (6), we may therefore reduce step 6
to
.
In view of (6), we may therefore reduce step 6
to  DFTs of length
DFTs of length  plus
plus
 DFTs of length
DFTs of length  .
If is very small, then we may use a naive
implementation for DFTs of length .
In general, one may use Bluestein's algorithm [4] to reduce
the computation of a DFT of length into the
computation of a product in
.
If is very small, then we may use a naive
implementation for DFTs of length .
In general, one may use Bluestein's algorithm [4] to reduce
the computation of a DFT of length into the
computation of a product in  ,
which can in turn be computed using FFT-multiplication and three DFTs of
length a larger power of two.
,
which can in turn be computed using FFT-multiplication and three DFTs of
length a larger power of two.
Let be a field with a primitive  -th root of unity .
Let be a polynomial of degree
-th root of unity .
Let be a polynomial of degree  . Then the relation (2) yields
. Then the relation (2) yields
 |
(7) |
For any  , we further note
that
, we further note
that
 |
(8) |
so  can be obtained from
can be obtained from  using transpositions of elements in . Concerning the inverse transform, we also
note that
using transpositions of elements in . Concerning the inverse transform, we also
note that

for  . Plugging this into (7), we conclude that
. Plugging this into (7), we conclude that

This leads to the following algorithm for the computation of :
 be a primitive
be a primitive  -th root of unity in
-th root of unity in  and assume that
and assume that  is invertible in . Given a monic polynomial
with
is invertible in . Given a monic polynomial
with  , we can compute in time
, we can compute in time

Proof. We have already explained the correctness
of Algorithm 2. Step 1 requires one forward DFT of length
 and cost
and cost  .
Step 2 can be done in linear time .
Step 3 requires one inverse DFT of length
.
Step 2 can be done in linear time .
Step 3 requires one inverse DFT of length  and
cost
and
cost  . The total cost of
Algorithm 2 is therefore
. The total cost of
Algorithm 2 is therefore  .
.
Remark  This
gives a
This
gives a  improvement over the previously best
known bound
improvement over the previously best
known bound  that was used in [19].
Note that the best known algorithm for computing squares of polynomials
of degree
that was used in [19].
Note that the best known algorithm for computing squares of polynomials
of degree  is
is  .
It would be interesting to know whether squares can also be computed in
time
.
It would be interesting to know whether squares can also be computed in
time  .
.
In view of (4), Graeffe transforms of power of two orders
 can be computed using
can be computed using
 |
(9) |
Now assume that we computed the first Graeffe transform
using Algorithm 2 and that we wish to apply a second
Graeffe transform to the result. Then we note that
 |
(10) |
is already known for . We can
use this to accelerate step 1 of the second application of Algorithm 2. Indeed, in view of (6) for  and
and  , we have
, we have
 |
(11) |
for . In order to exploit
this idea in a recursive fashion, it is useful to modify Algorithm 2 so as to include  in the input and
in the input and
 in the output. This leads to the following
algorithm:
in the output. This leads to the following
algorithm:
Algorithm
|
||||||
|
be a primitive -th root of unity in and assume that is invertible in
. Given a monic polynomial
with and  , we can compute
, we can compute  in
time
in
time

Proof. It suffices to compute
and then to apply Algorithm 3 recursively,  times. Every application of Algorithm 3 now takes
times. Every application of Algorithm 3 now takes  operations in ,
whence the claimed complexity bound.
operations in ,
whence the claimed complexity bound.
Remark were directly
computed using the formula (9), using  operations in . The new
algorithm is twice as fast for large .
operations in . The new
algorithm is twice as fast for large .
The algorithms from subsections 3.2 and 3.3
readily generalize to Graeffe transforms of order  for arbitrary , provided that
we have an
for arbitrary , provided that
we have an  -th root of unity
. For convenience of the
reader, we specified the generalization of Algorithm 3
below, together with the resulting complexity bounds.
-th root of unity
. For convenience of the
reader, we specified the generalization of Algorithm 3
below, together with the resulting complexity bounds.
Algorithm
|
||||||
|
be a primitive  -th root of unity in , where
-th root of unity in , where  is invertible in
. Given a monic polynomial
with and , we can compute
is invertible in
. Given a monic polynomial
with and , we can compute  in
time
in
time

Proof. Straightforward generalization of
Proposition 7.
be a primitive  -th root of unity in , where
-th root of unity in , where  are invertible in
. Given a monic polynomial
with and
are invertible in
. Given a monic polynomial
with and  , we can compute
, we can compute  in
time
in
time

Proof. Direct consequence of (4).
Remark . In terms of the size  of
, it is instructive to
observe that the “average cost”
of
, it is instructive to
observe that the “average cost”

is minimal for  . This
suggests that it might be interesting to use Graeffe transforms of order
three whenever possible. In the application of Algorithm 1,
this would lead us to take primes of the form
. This
suggests that it might be interesting to use Graeffe transforms of order
three whenever possible. In the application of Algorithm 1,
this would lead us to take primes of the form  , with small and
, with small and  close to . This
still allows us to use radix 2 FFTs, while at the same time benefitting
from radix 3 Graeffe transforms.
close to . This
still allows us to use radix 2 FFTs, while at the same time benefitting
from radix 3 Graeffe transforms.
If  is a fixed finite field, then DFTs are most
efficient for sizes that divide
is a fixed finite field, then DFTs are most
efficient for sizes that divide  . For our root finding application, it is often
convenient to take
. For our root finding application, it is often
convenient to take  , in which
case should be a power of two or three times a
power of two. The truncated Fourier transform was developed for the
multiplication of polynomials such that the degree of the product does
not have a nice size of this type. It turns out
that we may also use it for the efficient computation of Graeffe
transforms of polynomials of arbitrary degrees. Moreover, the
optimizations from the previous subsections still apply.
, in which
case should be a power of two or three times a
power of two. The truncated Fourier transform was developed for the
multiplication of polynomials such that the degree of the product does
not have a nice size of this type. It turns out
that we may also use it for the efficient computation of Graeffe
transforms of polynomials of arbitrary degrees. Moreover, the
optimizations from the previous subsections still apply.
Let us briefly describe how the truncated Fourier transform can be used
for the computation of Graeffe transforms of power of two orders. With
the notations from subsections 3.2 and 3.3, we
assume that  is a power of two as well and that
we wish to compute the Graeffe transform of a polynomial of degree
is a power of two as well and that
we wish to compute the Graeffe transform of a polynomial of degree  with
with  . Let
. Let  denote the
reversal of a binary number
denote the
reversal of a binary number  of
of  bits. For instance,
bits. For instance,  and
and  . Then the truncated Fourier of
at order
. Then the truncated Fourier of
at order  is defined by
is defined by

It has been shown in [22] that  and
and
 can both be computed in time
can both be computed in time  . More generally, for direct transforms, one
may compute
. More generally, for direct transforms, one
may compute

in time , whenever  . For generalizations to arbitrary
radices, we refer to [36].
. For generalizations to arbitrary
radices, we refer to [36].
Taking  , we note that
, we note that

for  . This provides us with
the required counterpart of (8) for retrieving
. This provides us with
the required counterpart of (8) for retrieving  efficiently from
efficiently from  .
The relation (10) also has a natural counterpart:
.
The relation (10) also has a natural counterpart:

for . This leads to the
following refinement of Algorithm 3:
Algorithm
|
||||||
|
be a primitive -th root of unity in , where ,
and assume that is invertible in . Given a monic polynomial
with  and ,
we can compute in time
and ,
we can compute in time

Proof. Straightforward adaptation of the proof
of Proposition 7, while using [22].
In step 3 of Algorithm 1, we still need an
algorithm to compute the Taylor shift .
If the characteristic of exceeds , then it is (not so) well known [1,
Lemma 3] that this can be done in time  ,
using the following reduction to a single polynomial multiplication of
degree :
,
using the following reduction to a single polynomial multiplication of
degree :
It is interesting to observe that Taylor shifts can still be computed in
time  in small characteristic, as follows:
in small characteristic, as follows:
We give a theoretical comparison of Algorithm 1 with the
Cantor–Zassenhaus algorithm [8], where both
algorithms have been optimized in the “FFT model” [44].
For this comparison, it is convenient to replace the “worst
case” heuristic H by a more empirical assumption.
More precisely, if we take  for
for  , then the expected proportion of single roots
is
, then the expected proportion of single roots
is  (see e.g. [23]).
This expected proportion is indeed observed in practice: see Table 3. In Algorithm 1, we took
(see e.g. [23]).
This expected proportion is indeed observed in practice: see Table 3. In Algorithm 1, we took  .
.
 instead of for some fixed
instead of for some fixed  .
Then the expected cost of Algorithm 1 is bounded by
.
Then the expected cost of Algorithm 1 is bounded by
 |
(12) |
Proof. We first analyze the cost of step 9. Let  be the cost of the polynomial
multiplications in the product tree algorithm, where
be the cost of the polynomial
multiplications in the product tree algorithm, where  is the size of
is the size of  . Exercise
10.3 of [17] shows that
. Exercise
10.3 of [17] shows that  .
The recurrence for is
.
The recurrence for is  for
for  and
and  .
Solving this recurrence while using the assumption that
.
Solving this recurrence while using the assumption that  is non-decreasing yields
is non-decreasing yields  .
Now let
.
Now let  be the successive sizes of for the recursive calls of the algorithm, so that
be the successive sizes of for the recursive calls of the algorithm, so that  . Thus the cost of all executions
of step 9 is
. Thus the cost of all executions
of step 9 is  .
Using again that
.
Using again that  is non-decreasing, we have
is non-decreasing, we have
 .
.
Let us next analyze the cost of the other steps until step 10
inclusive, but without the recursive calls in step 11. Set
 .
.
Step 4 takes  to compute
to compute  .
.
Altogether, the cost of these steps is  .
.
We now need to account for the cost of the recursive calls in step 11. For the tangent Graeffe algorithm
will, under our hypothesis, on average, obtain at least
of the roots in each recursive call, leaving slightly less than  of them to be found. Since
of them to be found. Since  and
and  is non-decreasing, the total cost of
Algorithm 1 is therefore as claimed.
is non-decreasing, the total cost of
Algorithm 1 is therefore as claimed.
Remark  ,
the bound (12) reduces to
,
the bound (12) reduces to  .
Since we may pick
.
Since we may pick  as large as we want, the
complexity of Algorithm 1 is then bounded by
as large as we want, the
complexity of Algorithm 1 is then bounded by  for any
for any  .
.
Assume from now on that we are in the asymptotic region where . Then Remark 14 shows
that the cost of the tangent Graeffe method is  for any
for any  . The bottleneck of
Cantor–Zassenhaus' algorithm in this region is modular
exponentiation, which accounts for a total cost of
. The bottleneck of
Cantor–Zassenhaus' algorithm in this region is modular
exponentiation, which accounts for a total cost of  [17]. We wish to determine the constant factor in order to
give an accurate comparison between the two algorithms. Given
polynomials
[17]. We wish to determine the constant factor in order to
give an accurate comparison between the two algorithms. Given
polynomials  with
with  ,
one modular exponentiation does
,
one modular exponentiation does  modular
squarings
modular
squarings

in a loop. However, in the first few iterations, the degree of  is less then so no division is
needed. The number of steps with divisions is
is less then so no division is
needed. The number of steps with divisions is  . Using fast division [17], the
remainder
. Using fast division [17], the
remainder  can be computed with two
multiplications of size assuming the required
inverse of
can be computed with two
multiplications of size assuming the required
inverse of  , the reciprocal
of , is precomputed. In the
FFT model, one forward transform of
, the reciprocal
of , is precomputed. In the
FFT model, one forward transform of  may be saved
and the forward transform of the inverse of may
be cached [44]. This costs
may be saved
and the forward transform of the inverse of may
be cached [44]. This costs  ,
i.e. at least
,
i.e. at least  ,
since
,
since  . The cost of the
top-level modular exponentiation is therefore equivalent to
. The cost of the
top-level modular exponentiation is therefore equivalent to  . Using a similar recursion as for
. Using a similar recursion as for  in the proof of Proposition 13, the total
cost of all modular compositions in CZ is equivalent to
in the proof of Proposition 13, the total
cost of all modular compositions in CZ is equivalent to  (strictly speaking, this is really an upper bound; but we indeed obtain
an equivalence for common values of
(strictly speaking, this is really an upper bound; but we indeed obtain
an equivalence for common values of  ,
such as
,
such as  or
or  ).
Altogether, this means that the tangent Graeffe algorithm is about
).
Altogether, this means that the tangent Graeffe algorithm is about  times faster than Cantor–Zassenhaus.
times faster than Cantor–Zassenhaus.
Remark  , and the
complexity of Cantor–Zassenhaus also involves another
, and the
complexity of Cantor–Zassenhaus also involves another  term due to gcd computations. The corresponding constant
factor is fairly high, which makes the tangent Graeffe algorithm even
more favorable in this asymptotic region.
term due to gcd computations. The corresponding constant
factor is fairly high, which makes the tangent Graeffe algorithm even
more favorable in this asymptotic region.
For our implementation, we have been pursuing three goals. We first
wanted to reimplement the tangent Graeffe algorithm from scratch using
FFT-based polynomial arithmetic and compare it with a good
implementation of the Cantor–Zassenhaus algorithm. Second, we
wanted to factor a polynomial of degree .
For this, it is important to consider space efficiency. Third, we wanted
to parallelize the tangent Graeffe algorithm for a multi-core computer.
Unlike the Cantor–Zassenhaus algorithm, the tangent Graeffe
algorithm is gcd-free which makes it easier to parallelize. We first
tried parallelizing only the FFTs that appear in steps 3,
5, 6, 9, and 10 of
Algorithm 1 to see if this alone is sufficient to obtain
good parallel speedup. It isn't.
Our main practical challenge is, however, space, not time. For a 64 bit
prime , and an input
polynomial of degree , the
input polynomial and output roots alone need 16 gigabytes of storage.
Our first implementation exceeded the virtual memory of our machine
which has 128 gigabytes of RAM plus 240 gigabytes of SSD swap space.
To reduce space we use in-place algorithms. In-place algorithms do not allocate new space (memory). They work in the input and output space and we allow them to be given additional working space. To parallelize a recursive in-place algorithm, we must partition the input, output and the temporary memory (if any) for recursive parallel calls. Our design is such that the space used does not increase with more cores. We refer the reader to Giorgi, Grene and Roche [18] for examples of in-place serial algorithms in computer algebra and a bibliography.
Number theoretic FFTs over were first introduced
by Pollard [40]. Let us first explain how we parallelized
such FFTs using Cilk C. The strategy is classical, but it is convenient
to detail it here, since we use the same strategy for parallelizing the
other steps in Algorithm 1. Cilk [16] was
designed to support the parallelization of recursive divide and conquer
algorithms like the FFT for multi-core computers. To parallelize
recursive algorithms using Cilk we first modify the code so that the
memory locations that are updated in the recursive calls do not overlap.
Figure 1 shows our sequential C code for two radix 2 FFTs that we use. In the vernacular fft1 is known as the “decimation-in-time” FFT and fft2 as the “decimation-in-frequency” FFT. We refer the reader to Chu and George [9] for a discussion of the two FFTs. We note that Geddes, Czapor, and Labahn present only fft1 in their book on computer algebra [10], whereas von zur Gathen and Gerhard present only fft2 [17].
In the code in Figure 1, LONG is a macro
for long long int, a 64 bit signed integer. The C
functions addmod, submod, mulmod
implement  in
respectively for
in
respectively for  . For
multiplication in we use Roman Pearce's
implementation of Möller and Granlund [38]. The input
array
. For
multiplication in we use Roman Pearce's
implementation of Möller and Granlund [38]. The input
array  of size is the
main input to and output from the FFT. The input
of size is the
main input to and output from the FFT. The input  is an array of size containing powers of , a primitive -th root of unity in . We precompute
is an array of size containing powers of , a primitive -th root of unity in . We precompute

Precomputing
saves asymptotically half of the multiplications in the FFT. For
 ,
fft1
and
fft2
both do
,
fft1
and
fft2
both do
 multiplications. Duplicating of powers of
means all recursive calls in
fft1
and
fft2
access
sequentially.
multiplications. Duplicating of powers of
means all recursive calls in
fft1
and
fft2
access
sequentially.
|
||||||||||||||||||||||||||||||||||||||||||
Codes like these where the recursive calls update separate parts of the
array
are easy to parallelize using Cilk. To parallelize
fft1
in Cilk C we first make a new subroutine
fft1cilk
which executes the two recursive calls in parallel. In Figure
2
the two Cilk
spawn
directives do this. For small
we do not want to start two new processes because of the cost of
process management overhead. Thus for
 ,
fft1cilk
calls
fft1
which runs sequentially.
,
fft1cilk
calls
fft1
which runs sequentially.
cilk void block1( LONG n2, LONG *A, LONG b, LONG W, LONG p ) {
LONG i,s,t;
for( i=0; i<b; i++ ) {
s = A[i];
t = mulmod(W[i],A[n2+i],p);
A[ i] = addmod(s,t,p);
A[n2+i] = submod(s,t,p);
}
return;
}
#define B 65536
#define FFTCUTOFF 32768
cilk void fft1cilk( LONG *A, LONG n, LONG *W, LONG p ) {
LONG q,r,i;
if( n<=FFTCUTOFF ) { fft1(A,n,W,p); return; }
spawn fft1cilk( A, n2, W+n2, p );
spawn fft1cilk( A+n2, n2, W+n2, p );
sync; // wait for the two fft1cilk calls to finish
n2 = n/2; q = n2/B; r = n2-q*B;
for( i=0; i<q; i++ ) spawn block1( n2, A+i*B, B, W+i*B, p );
if( r>0 ) spawn block1( n2, A+q*B, r, W+q*B, p );
sync; // wait for all blocks to complete
return;
} |
To obtain good parallel speedup we also need to parallelize the for loop
in fft1 because it does  multiplications out of a total of
multiplications. We do this by executing large contiguous blocks of the
loop in parallel. We could use Cilk's parallel for loop construct cilk_for and let Cilk determine what block size to use but
this does not allow us to tune the block size for best performance.
Instead we choose a blocksize B and parallelize the loop
explicitly as shown in Figure 2. To get best performance,
we reduced B until the Cilk process overhead takes more
than 1% say of the total time for the FFT. This yields good parallel
speedup for many cores when is large.
multiplications out of a total of
multiplications. We do this by executing large contiguous blocks of the
loop in parallel. We could use Cilk's parallel for loop construct cilk_for and let Cilk determine what block size to use but
this does not allow us to tune the block size for best performance.
Instead we choose a blocksize B and parallelize the loop
explicitly as shown in Figure 2. To get best performance,
we reduced B until the Cilk process overhead takes more
than 1% say of the total time for the FFT. This yields good parallel
speedup for many cores when is large.
An alternative way to parallelize an FFT is to use a recursive FFT for
creating parallel tasks for large as we have but
use a non-recursive FFT for smaller .
These and other strategies for parallelizing the FFT for multi-core
computers are discussed in [9, 13].
Steps 1, 2, 3, 5, and 6 of Algorithm 6 require time. Steps 3 and 6 involve  inverses in which, because they require many
divisions, are relatively very expensive. All the inverses can be
replaced with multiplications as follows. After computing ! in step 1, we compute the inverse
inverses in which, because they require many
divisions, are relatively very expensive. All the inverses can be
replaced with multiplications as follows. After computing ! in step 1, we compute the inverse  . For steps 3 and 6, we run the
loop backwards and multiply by
. For steps 3 and 6, we run the
loop backwards and multiply by  to get the next
inverse as follows.
to get the next
inverse as follows.
for( i=d; i>1; i-- ) { Pi[i] = mulmod(Pi[i],finv,p); finv = mulmod(finv,i,p); }
We parallelized only the polynomial multiplication  in step 4. To multiply two polynomials of degree at most our FFT multiplication needs three arrays ,
in step 4. To multiply two polynomials of degree at most our FFT multiplication needs three arrays ,  ,
and of size where satisfies
,
and of size where satisfies  .
.
The data in Table 4 shows that the best parallel speedup
for step 3 is 4.12. A factor of 4.12 on 10 cores is not very good and
due to the fact that we did not paralellize steps 1, 3 and 6 which
involve  ,
,  and multiplications in , respectively. We did not do this because computing
and multiplications in , respectively. We did not do this because computing
 is not a bottleneck of Algorithm 1.
is not a bottleneck of Algorithm 1.
Of course, it is possible to paralellize steps 1, 3 and 6. For  blocks of size we would need to
compute the factorials
blocks of size we would need to
compute the factorials  in parallel. We could do
this by first computing partial products
in parallel. We could do
this by first computing partial products  in parallel and then compute
in parallel and then compute  . Now we can execute step 1 in
blocks in parallel. Next we would compute the inverses of so we can execute steps 3 and 6 in parallel.
. Now we can execute step 1 in
blocks in parallel. Next we would compute the inverses of so we can execute steps 3 and 6 in parallel.
Step 5 of Algorithm 1 is the main computation
in Algorithm 1. It has complexity  . We successfully parallelized the FFTs and all loops in blocks except the following data movement:
. We successfully parallelized the FFTs and all loops in blocks except the following data movement:
for( i=0; i<n/2; i++ ) A[i] = A[2*i]; // compress for( i=0; i<n/2; i++ ) A[n/2+i] = A[i]; // duplicate
We tried parallelizing the above code by moving the even entries of into a temporary array ,
in blocks, in parallel, then copying them back to , twice, in blocks, in parallel. On 6 cores, the
parallel code is slower than the serial code so we have left this pure
data movement not parallelized.
Each of the three evaluations  ,
,
 and
and  for
for  in step 6 of Algorithm 1 can be done using the
Bluestein transform [4] in
in step 6 of Algorithm 1 can be done using the
Bluestein transform [4] in  time.
Although step 6 does not dominate the time complexity it
needs the most space. We need at least
time.
Although step 6 does not dominate the time complexity it
needs the most space. We need at least  units of
storage to store the values of ,
and .
For
units of
storage to store the values of ,
and .
For  and
and  ,
the requirement
,
the requirement  implies
implies  . This is
. This is  gigabytes. We
chose to save half of this by choosing
gigabytes. We
chose to save half of this by choosing  instead.
This increases the time a little (see Table 3) because we
obtain a smaller portion of the roots at each recursive call of
Algorithm 1.
instead.
This increases the time a little (see Table 3) because we
obtain a smaller portion of the roots at each recursive call of
Algorithm 1.
The Bluestein transform does one multiplication of two polynomials of
degree plus  work. For a
multiplication of degree we need an FFT of size
work. For a
multiplication of degree we need an FFT of size
 and our FFT uses
and our FFT uses  units
of temporary storage. For ,
and
units
of temporary storage. For ,
and  we have
we have  so we need 192 gigabytes. We do not evaluate of
so we need 192 gigabytes. We do not evaluate of  ,
,  and
and  in parallel as that would triple the 192 gigabytes to
576 gigabytes.
in parallel as that would triple the 192 gigabytes to
576 gigabytes.
For  with small, because
with small, because
 for some
for some  ,
we can save time and space by applying (6). We do
,
we can save time and space by applying (6). We do  DFTs of size ,
in blocks, in parallel, then multiplications by
powers of , in blocks in
parallel, followed by FFTs of size
DFTs of size ,
in blocks, in parallel, then multiplications by
powers of , in blocks in
parallel, followed by FFTs of size  which we do in parallel. This reduces the time for an
evaluation by a factor between 6 and 12 since we replace 3 FFTs of size
where
which we do in parallel. This reduces the time for an
evaluation by a factor between 6 and 12 since we replace 3 FFTs of size
where  by FFTs of size which is equivalent
to one FFT of size .
by FFTs of size which is equivalent
to one FFT of size .
We need an additional units of storage for
storing the inputs of size
for the FFTs and an additional
units for the required array. Thus applying (6) reduces the temporary storage needed from
units to  units. For and
, with , this is
units. For and
, with , this is  gigabytes of
temporary storage instead of 192 gigabytes.
gigabytes of
temporary storage instead of 192 gigabytes.
We can now state the total storage needed by our implementation of
Algorithm 1. We need to store the input
of degree and an array of size
for the output roots . We
need space for three temporary polynomials of degree . Including the memory for step 6,
our implementation uses  units, which, for
units, which, for  , and is 121 gigabytes.
, and is 121 gigabytes.
In step 9 we need to expand the polynomial  . Let
. Let  and suppose is stored in an array of size
and
and suppose is stored in an array of size
and  in an array of size
in an array of size  . We can compute in
. We can compute in  using fast multiplication and divide and conquer. The
obvious way to do this is to split the roots in
into two equal size groups, of size
using fast multiplication and divide and conquer. The
obvious way to do this is to split the roots in
into two equal size groups, of size  and
and  , then recursively compute
, then recursively compute

and finally multiply  by
by  using fast multiplication for large .
In the literature this approach is called the product tree
multiplication algorithm; see [17, Algorithm 10.3]. In
Appendix A, the function mult implements the product
tree algorithm in Magma. We use it to create the input polynomial to get Magma timings. However, mult
is inefficient because all recursive calls allocate new memory for the
inputs and products in the product tree.
using fast multiplication for large .
In the literature this approach is called the product tree
multiplication algorithm; see [17, Algorithm 10.3]. In
Appendix A, the function mult implements the product
tree algorithm in Magma. We use it to create the input polynomial to get Magma timings. However, mult
is inefficient because all recursive calls allocate new memory for the
inputs and products in the product tree.
For large products we use our FFT based polynomial multiplication FFTpolmul64s which needs a temporary array
of size  units of storage where
units of storage where  . We do not want to allocate space for in each recursive call. Fortunately,
. We do not want to allocate space for in each recursive call. Fortunately,  is a power of 2 so we can divide into two halves
and execute the two recursive calls in parallel using the two halves of
. But the size of plus is
is a power of 2 so we can divide into two halves
and execute the two recursive calls in parallel using the two halves of
. But the size of plus is  . They don't fit in .
The remedy is to note that
. They don't fit in .
The remedy is to note that  and
and  are both monic, so we do not need to store their leading coefficients.
are both monic, so we do not need to store their leading coefficients.
Figure 3 presents C code for an in-place product tree
algorithm which uses the input space of size
, the output space of size and a temporary array of size for all polynomial
multiplications in the product tree. Our solution splits asymmetrically into a “large” set of size  where
where  and a
“small” set of size .
For example, for
and a
“small” set of size .
For example, for  we use
we use  and
and  . To multiply
. To multiply  we first recursively compute
we first recursively compute  in
in
 and
and  in
in  . We copy the contents of
to the input array and we compute the product
. We copy the contents of
to the input array and we compute the product
 in
in  .
For small , we use polmul64s
an in-place multiplication with quadratic complexity. Then we add
.
For small , we use polmul64s
an in-place multiplication with quadratic complexity. Then we add  and
and  to
so that contains
to
so that contains  .
Thus we have the following result.
.
Thus we have the following result.
 of size
and
of size
and  be an array of size
be an array of size  and
and  an array of size
an array of size  where
where  and
and  .
Assuming
.
Assuming  , Algorithm treemul computes
, Algorithm treemul computes  in arithmetic operations in using
only the memory of
in arithmetic operations in using
only the memory of  and .
and .
In Figure
3
, because the memory for
,
and
in the two recursive calls is separated, we may execute the two
recursive calls to
treemul
in parallel. This also holds recursively, so we can keep executing
recursive calls in parallel, which is ideal for Cilk. In our parallel
implementation of
treemul
we parallelize the two recursive calls if
 .
We also parallelize
FFTmul64s
and the FFTs (both the subalgorithms and their calls inside
treemul
). We do not parallelize the two polynomial additions.
.
We also parallelize
FFTmul64s
and the FFTs (both the subalgorithms and their calls inside
treemul
). We do not parallelize the two polynomial additions.
#include <stdlib.h>
#define LONG long long int
// Input polynomials a and b mod p of degree da and db respectively.
// Output array c is space for the sum a + b mod p (product a b mod p)
LONG poladd64s( LONG *a, LONG *b, LONG *c, LONG da, LONG db, LONG p );
LONG polmul64s( LONG *a, LONG *b, LONG *c, LONG da, LONG db, LONG p );
LONG FFTmul64s( LONG *a, LONG *b, LONG *c, LONG da, LONG db, LONG *T, LONG p );
void treemul( LONG *S, LONG n, LONG *Q, LONG *T, LONG p ) {
LONG i,m,d;
if( n==1 ) { Q[0] = submodp(0,S[0],p); return; }
for( m=1; 2*m<n; m=2*m );
d = n-m;
treemul(S,m,Q,T,p); // compute a(x)-x^m in Q[0..m-1] using S[0..m-1] and T[0..3m-1]
treemul(S+m,d,Q+m,T+3*m,p); // and b(x)-x^d in Q[m..n-1] using S[m..n-1] and T[3m..]
for( i=0; i<n; i++ ) S[i] = Q[i]; // S = [a0,a1,…,am-1,b0,b1,…,bd-1]
if( d<10 ) polmul64s(S,S+m,Q,m-1,d-1,p); // in-place classical multiplication
else FFTmul64s(S,S+m,Q,m-1,d-1,T,p); // FFT multiplication using T[0..6m-1]
Q[n-1] = 0;
poladd64s(Q+d,S,Q+d,m-1,m-1,p); // add x^m (b-x^d) to Q[d..n-1]
poladd64s(Q+m,S+m,Q+m,d-1,d-1,p); // add x^d (a-x^m) to Q[m..n-1]
// Q[n] = 1; is okay for this sequential code but not for a parallel code
return;
}
LONG *array64s(LONG n); // return an array of size n
void treeproduct( LONG *S, LONG n, LONG *Q, LONG p ) {
// S is an array of size n and Q of size n+1
LONG N,*T;
for( N=1; N<n; N=2*N );
T = array64s(3*N);
treemul(S,n,Q,T,p);
free(T);
Q[n] = 1;
return;
} |
Figure 3. C code for computing
|
Remark asymmetrically so that the FFTs are fully
utilized, we gain upto a factor of 2 in speed when
is much smaller then . Thus
we get the benefit of using a truncated FFT [22] for the
polynomial multiplications without using it.
Remark
We want to compare our new tangent Graeffe implementation with an
implementation of the Cantor–Zassenhaus algorithm [8]
which uses fast polynomial arithmetic. One of the best implementations
that we know of is Magma's Factorize command. Magma uses an
implementation of Shoup's work [44] by Allan Steel [45]. For  of degree
with distinct roots in , Magma uses the Cantor–Zassenhaus algorithm
which has time complexity
of degree
with distinct roots in , Magma uses the Cantor–Zassenhaus algorithm
which has time complexity  .
.
The timings in Tables 1 and 2 were obtained on
an 8 core Intel Xeon E5-2660 CPU which runs at at 2.2 GHz base and 3.0
GHz turbo. The input polynomials in Tables 1 and 2 of degree were
created with random distinct roots in . Table 1 is for the
28.8 bit prime  and Table 2 is for
the 62.4 bit prime
and Table 2 is for
the 62.4 bit prime  .
.
The timings in column NewTG are for our C implementation of Algorithm 1 with the parameter chosen in . The timings in column Magma are
for the Factorize command for Magma version V2.25-5. Magma code
for creating and factoring it is given in
Appendix A. We note that older versions of Magma have a
quadratic sub-algorithm; this problem was fixed by Steel for version
V2.25-5. We also note that Magma has faster arithmetic for primes 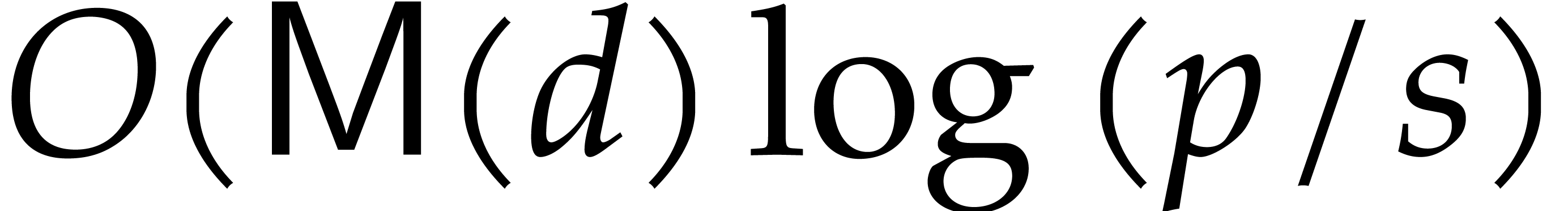 .
.
The columns in Tables
1
and
2
labeled Step5, Step6, Step9, and
 report the time spent in steps
5
,
6
,
9
, and
10
, respectively, in the top level call of Algorithm
1
. They show that initially step
5
, which costs
report the time spent in steps
5
,
6
,
9
, and
10
, respectively, in the top level call of Algorithm
1
. They show that initially step
5
, which costs
 ,
dominates the cost of steps
6
and
9
which cost
,
dominates the cost of steps
6
and
9
which cost
 and
and
 respectively. As
increases, so does
,
and the number of iterations
of step
5
in Algorithm
1
drops; ultimately, the computation of the product
in step
9
dominates.
respectively. As
increases, so does
,
and the number of iterations
of step
5
in Algorithm
1
drops; ultimately, the computation of the product
in step
9
dominates.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The column labeled %roots reports the percentage of the roots found in
the first tangent Graeffe application. Column is
the value of in step 5. Step 5 does  FFTs of size
FFTs of size  . Column FFT reports the time for one of those
FFTs. For example, in Table 2, for
. Column FFT reports the time for one of those
FFTs. For example, in Table 2, for  , 13.9 seconds was spent in step 5. The
code did
, 13.9 seconds was spent in step 5. The
code did  FFTs of size
FFTs of size  which took
which took  seconds.
seconds.
The timings in Table 1 show that the tangent Graeffe method
is 100 times faster than Magma's implementation of
Cantor–Zassenhaus at degree  .
For the larger prime in Table 2 the tangent Graeffe method
is 166 times faster at degree .
.
For the larger prime in Table 2 the tangent Graeffe method
is 166 times faster at degree .
Table 3 shows the effect of different choices for the
parameter in Algorithm 1. If the
roots of under the Graeffe transform  are uniformly distributed among the -th roots of unity, then the proportion of them that
remain distinct is
are uniformly distributed among the -th roots of unity, then the proportion of them that
remain distinct is  . Thus
doubling increases the proportion of roots found
at each recursive level of Algorithm 1, which saves time,
but it also doubles the cost of the evaluations in step 6.
Recall that the theoretically optimal performance is obtained by taking
. Thus
doubling increases the proportion of roots found
at each recursive level of Algorithm 1, which saves time,
but it also doubles the cost of the evaluations in step 6.
Recall that the theoretically optimal performance is obtained by taking
 , where we note that
, where we note that  and
and  for
for  .
.
Column
gives the expected proportion of roots that will be found. Column
%roots is the actual percentage of roots found by Algorithm
1
. Columns Step5, Step6, and Total are the time in step
5
, step
6
, and the total time. The data in Table
3
suggests choosing
to minimize time. For
the algorithm is expected to obtain between
 and
and
 of the roots. Our actual choice of
increases the time by about 10% but saves a factor of 2 in space.
of the roots. Our actual choice of
increases the time by about 10% but saves a factor of 2 in space.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Table
4
shows the results for our parallel implementation including timings for
of degree
.
The timings in Table
4
were obtained on a server with a 10 core Intel E5 2680 v2 CPU with 128
gigabytes of RAM running at 3.0GHz base, 3.6GHz turbo. The input
polynomial
is created as before by choosing
random distinct values from
with
.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Timings in column are for computing the input
polynomial using our in-place parallel product
tree multiplication from section 3.4. The total time for computing the
roots of is in column Total. Roughly speaking,
our software takes 10 times longer to compute the roots of (less for larger )
than it does to create !
Timings in columns Step4, Step5, Step6, Step9, and
are the times for those steps for the top-level call of Algorithm 1. Speedups are given for each computation. The reader can see
that the parallel speedup is not as good for Step4 and the division
. This is because we have
only parallelized the FFTs in them; none of steps of linear cost are
parallelized.
The motivation for our work is the problem of sparse polynomial
interpolation where one seeks to recover the coefficients and monomials
of a polynomial  with
terms from values of . The
popular approach by Prony and Ben-Or–Tiwari needs only
with
terms from values of . The
popular approach by Prony and Ben-Or–Tiwari needs only  values of but it needs to factor a
polynomial
values of but it needs to factor a
polynomial  of degree
which has distinct roots in . Using the Cantor–Zassenhaus (CZ)
algorithm, computing the roots of
of degree
which has distinct roots in . Using the Cantor–Zassenhaus (CZ)
algorithm, computing the roots of  takes
takes  time. Because this is the most expensive step in
Ben-Or/Tiwari sparse interpolation, and because CZ does gcd computations
which are difficult to parallelize, research in sparse interpolation has
tried different approaches that do not require root finding.
time. Because this is the most expensive step in
Ben-Or/Tiwari sparse interpolation, and because CZ does gcd computations
which are difficult to parallelize, research in sparse interpolation has
tried different approaches that do not require root finding.
If we choose the prime of the form with small, the new tangent
Graeffe (TG) algorithm factors in  time. This is
time. This is  faster than CZ, but
the constants actually matter in practice. In this work we improved the
main step of TG by a factor of 2 and we showed that for large , TG is faster than CZ by a factor
of . Our new C implementation
of TG is over 100 times faster than Magma's C implementation of CZ for
faster than CZ, but
the constants actually matter in practice. In this work we improved the
main step of TG by a factor of 2 and we showed that for large , TG is faster than CZ by a factor
of . Our new C implementation
of TG is over 100 times faster than Magma's C implementation of CZ for
 on the tests we made. So TG really is a lot
faster than CZ.
on the tests we made. So TG really is a lot
faster than CZ.
Another goal was to see if we could parallelize TG for multi-core
computers. We found that it was not sufficient to only parallelize the
underlying FFT. We also had to parallelize many sub-algorithms to get
good parallel speedup. Here we contributed a new parallel in-place
product tree algorithm. We were also successful in reducing the space
needed so that we could compute the roots of of
degree one billion on a 10 core computer with 128 gigabytes of RAM in
about one hour. It should be possible to reduce the time further by
using vectorization [12, 26]. The sequential
implementation of the FFTs could also be further improved using
techniques from [15, 42] and Harvey's approach
for number theoretic FFTs [21].
p := 3*29*2^56+1;
p := 7*2^26+1;
Fp := FiniteField(p);
R<x> := PolynomialRing(Fp);
mult := function( L )
n := #L;
if n eq 1 then return x-L[1];
else
m := n div 2;
f := $$( L[1..m] ) * $$( L[m+1..n] );
return f;
end if;
end function;
d := 2^12-1;
S := { Random(Fp) : i in [1..d] };
while #S lt d do S := S join { Random(Fp) : i in [1..d-#S] }; end while;
#S;
L := [ x : x in S ];
time f := mult( L );
time g := Factorization(f);
A. V. Aho, K. Steiglitz, and J. D. Ullman. Evaluating polynomials on a fixed set of points. SIAM Journ. of Comp., 4:533–539, 1975.
M. Ben-Or and P. Tiwari. A deterministic algorithm for sparse multivariate polynomial interpolation. In STOC '88: Proceedings of the twentieth annual ACM symposium on Theory of computing, pages 301–309. New York, NY, USA, 1988. ACM Press.
D.J. Bernstein. Fast multiplication and its applications, pages 325–384. Mathematical Sciences Research Institute Publications. Cambridge University Press, United Kingdom, 2008.
Leo I. Bluestein. A linear filtering approach to the computation of discrete Fourier transform. IEEE Transactions on Audio and Electroacoustics, 18(4):451–455, 1970.
A. Bostan, G. Lecerf, and É. Schost. Tellegen's principle into practice. In ISSAC '03: Proceedings of the 2003 International Symposium on Symbolic and Algebraic Computation, pages 37–44. ACM Press, 2003.
R. P. Brent, F. G. Gustavson, and D. Y. Y. Yun. Fast solution of Toeplitz systems of equations and computation of Padé approximants. J. Algorithms, 1(3):259–295, 1980.
J. Canny, E. Kaltofen, and Y. Lakshman. Solving systems of non-linear polynomial equations faster. In Proceedings of the ACM-SIGSAM 1989 International Symposium on Symbolic and Algebraic Computation, pages 121–128. ACM Press, 1989.
D. G. Cantor and H. Zassenhaus. A new algorithm for factoring polynomials over finite fields. Math. Comp., 36(154):587–592, 1981.
E. Chu and A. George. Inside the FFT Black Box. Computational Mathematics Series. CRC Press, 2000.
S. Czapor, K. Geddes, and G. Labahn. Algorithms for Computer Algebra. Kluwer Academic Publishers, 1992.
A. Díaz and E. Kaltofen. FOXFOX: a system for manipulating symbolic objects in black box representation. In ISSAC '98: Proceedings of the 1998 International Symposium on Symbolic and Algebraic Computation, pages 30–37. ACM Press, 1998.
P. Fortin, A. Fleury, F. Lemaire, and M. Monagan. High performance SIMD modular arithmetic for polynomial evaluation. ArXiv:2004.11571, 2020.
F. Franchetti, M. Püschel, Y. Voronenko, S. Chellappa, and J. Moura. Discrete Fourier transform on multicores. IEEE Signal Processing Magazine, 26(6):90–102, 2009.
T. S. Freeman, G. M. Imirzian, E. Kaltofen, and Y. Lakshman. DAGWOOD: a system for manipulating polynomials given by straight-line programs. ACM Trans. Math. Software, 14:218–240, 1988.
M. Frigo and S. G. Johnson. The design and implementation of FFTW3. Proceedings of the IEEE, 93(2):216–231, 2005. Special issue on “Program Generation, Optimization, and Platform Adaptation”.
M. Frigo, C.E. Leisorson, and R.K. Randall. The implementation of the Cilk-5 multithreaded language. In Proceedings of PLDI 1998, pages 212–223. ACM, 1998.
J. von zur Gathen and J. Gerhard. Modern Computer Algebra. Cambridge University Press, New York, NY, USA, 3rd edition, 2013.
P. Giorgi, B. Grenet, and D. S. Roche. Fast in-place algorithms for polynomial operations: division, evaluation, interpolation. Technical Report http://arxiv.org/abs/2002.10304, Arxiv, 2020.
B. Grenet, J. van der Hoeven, and G. Lecerf. Randomized root finding over finite fields using tangent Graeffe transforms. In Proc. ISSAC '15, pages 197–204. New York, NY, USA, 2015. ACM.
B. Grenet, J. van der Hoeven, and G. Lecerf. Deterministic root finding over finite fields using Graeffe transforms. AAECC, 27(3):237–257, 2016.
D. Harvey. Faster arithmetic for number-theoretic transforms. J. Symbolic Comput., 60:113–119, 2014.
J. van der Hoeven. The truncated Fourier transform and applications. In J. Gutierrez, editor, Proc. ISSAC 2004, pages 290–296. Univ. of Cantabria, Santander, Spain, July 4–7 2004.
J. van der Hoeven. Probably faster multiplication of sparse polynomials. Technical Report, HAL, 2020. http://hal.archives-ouvertes.fr/hal-02473830.
J. van der Hoeven and G. Lecerf. On the bit-complexity of sparse polynomial and series multiplication. J. Symbolic Comput., 50:227–254, 2013.
J. van der Hoeven and G. Lecerf. Sparse polynomial interpolation in practice. ACM Commun. Comput. Algebra, 48(3/4):187–191, 2015.
J. van der Hoeven, G. Lecerf, and G. Quintin. Modular SIMD arithmetic in Mathemagix. ACM Trans. Math. Softw., 43(1):5–1, 2016.
J. van der Hoeven and M. Monagan. Implementing the tangent Graeffe root finding method. In A. M. Bigatti, J. Carette, J. H. Davenport, M. Joswig, and T. de Wolff, editors, Mathematical Software – ICMS 2020, pages 482–492. Cham, 2020. Springer International Publishing.
J. van der Hoeven et al. GNU TeXmacs. https://www.texmacs.org, 1998.
J. Hu and M. B. Monagan. A fast parallel sparse polynomial GCD algorithm. In S. A. Abramov, E. V. Zima, and X.-S. Gao, editors, Proc. ISSAC '16, pages 271–278. ACM, 2016.
M. A. Huang and A. J. Rao. Interpolation of sparse multivariate polynomials over large finite fields with applications. In SODA '96: Proceedings of the seventh annual ACM-SIAM symposium on Discrete algorithms, pages 508–517. Philadelphia, PA, USA, 1996. Society for Industrial and Applied Mathematics.
M. Javadi and M. Monagan. Parallel sparse polynomial interpolation over finite fields. In Proceedings of PASCO 2010, pages 160–168. ACM Press, 2010.
E. Kaltofen. Computing with polynomials given by straight-line programs I: greatest common divisors. In STOC '85: Proceedings of the Seventeenth Annual ACM Symposium on Theory of Computing, pages 131–142. ACM Press, 1985.
E. Kaltofen, Y. N. Lakshman, and J.-M. Wiley. Modular rational sparse multivariate polynomial interpolation. In ISSAC '90: Proceedings of the International Symposium on Symbolic and Algebraic Computation, pages 135–139. New York, NY, USA, 1990. ACM Press.
E. Kaltofen and B. M. Trager. Computing with polynomials given by black boxes for their evaluations: greatest common divisors, factorization, separation of numerators and denominators. JSC, 9(3):301–320, 1990.
E. Kaltofen and L. Yagati. Improved sparse multivariate polynomial interpolation algorithms. In ISSAC '88: Proceedings of the International Symposium on Symbolic and Algebraic Computation, pages 467–474. Springer Verlag, 1988.
R. Larrieu. The truncated Fourier transform for mixed radices. In Proc. ISSAC '17, pages 261–268. New York, NY, USA, 2017. ACM.
R. Moenck. Fast computation of GCDs. In Proc. of the 5th ACM Annual Symposium on Theory of Computing, pages 142–171. New York, 1973. ACM Press.
N. Möller and T. Granlund. Improved division by invariant integers. IEEE Transactions on Computers, 60:165–175, 2011.
H. Murao and T. Fujise. Modular algorithm for sparse multivariate polynomial interpolation and its parallel implementation. JSC, 21:377–396, 1996.
J. M. Pollard. The fast Fourier transform in a finite field. Mathematics of Computation, 25(114):365–374, 1971.
R. Prony. Essai expérimental et analytique sur les lois de la dilatabilité des fluides élastiques et sur celles de la force expansive de la vapeur de l'eau et de la vapeur de l'alkool, à différentes températures. J. de l'École Polytechnique Floréal et Plairial, an III, 1(cahier 22):24–76, 1795.
M. Püschel, J. M. F. Moura, J. Johnson, D. Padua, M. Veloso, B. Singer, J. Xiong, F. Franchetti, A. Gacic, Y. Voronenko, K. Chen, R. W. Johnson, and N. Rizzolo. SPIRAL: code generation for DSP transforms. Proceedings of the IEEE, special issue on “Program Generation, Optimization, and Adaptation”, 93(2):232–275, 2005.
D. S. Roche. What can (and can't) we do with sparse polynomials? In Proc. ISSAC '18, pages 25–30. New York, NY, USA, 2018. ACM.
V. Shoup. A new polynomial factorization and its implementation. J. Symbolic Computation, 20(4):363–397, 1995.
 faster than the Cantor–Zassenhaus algorithm. We implemented
the tangent Graeffe algorithm in C using our own library of 64 bit
integer FFT based in-place polynomial algorithms then parallelized
the FFT and main steps using Cilk C.
faster than the Cantor–Zassenhaus algorithm. We implemented
the tangent Graeffe algorithm in C using our own library of 64 bit
integer FFT based in-place polynomial algorithms then parallelized
the FFT and main steps using Cilk C.
 of degree
of degree  of roots of
of roots of  then return
then return 
 be largest such that
be largest such that 



 ,
,

 be of order
be of order 
 ,
, ,
, for
for 
 ,
, ,
,
 do
do
 and
and  ,
,



 of
of 













 ,
,


 ,
,

 and
and  ,
,




 and
and 
 and
and 






 and
and  for
for  where
where 
 with
with  for
for 


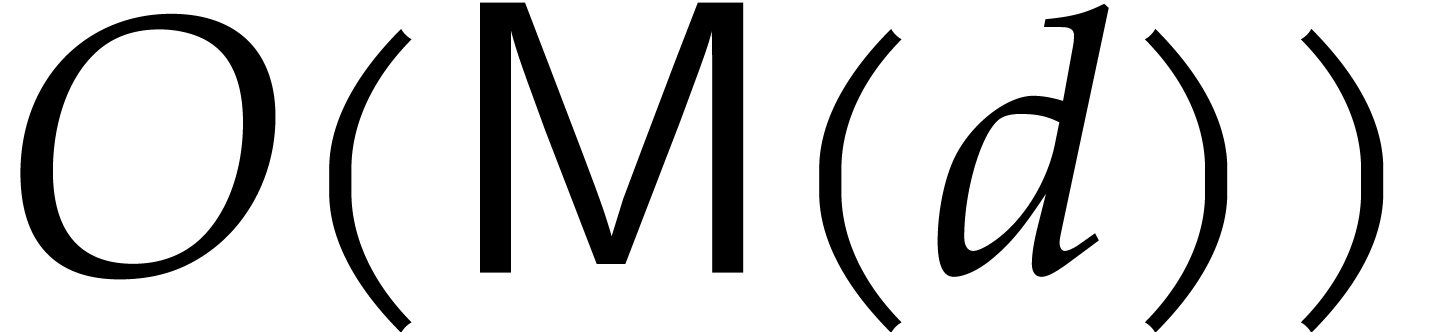 ;
; ,
, .
. in step
in step